https://github.com/oskar-j/medical_classifier
Full stack machine learning - a scikit model in action
https://github.com/oskar-j/medical_classifier
classification data-science machine-learning scikit-model
Last synced: 5 months ago
JSON representation
Full stack machine learning - a scikit model in action
- Host: GitHub
- URL: https://github.com/oskar-j/medical_classifier
- Owner: oskar-j
- Created: 2018-06-11T19:46:20.000Z (about 8 years ago)
- Default Branch: master
- Last Pushed: 2019-09-01T18:27:41.000Z (almost 7 years ago)
- Last Synced: 2025-03-01T09:30:35.777Z (over 1 year ago)
- Topics: classification, data-science, machine-learning, scikit-model
- Language: HTML
- Size: 1.75 MB
- Stars: 1
- Watchers: 2
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Medical classifier
Full stack machine learning - a scikit model in action
# Introduction
# Description
## Data
## Exploratory analysis
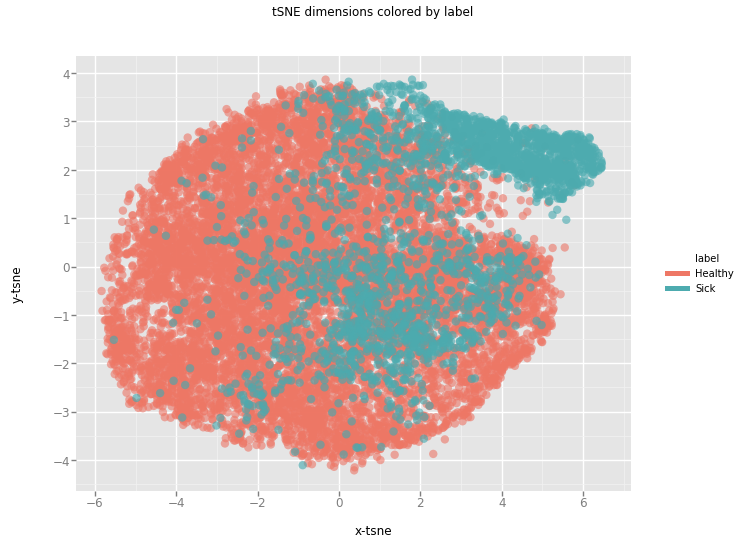
An attempt to cluster the data using t-SNE algorithm (`n_components=3`, `perplexity=50`, `n_iter=300`).
## Solution (model)
### Success metric
It's better to use the Recall metric. Recall (R) is defined as the number of true positives (T_p)
over the number of true positives plus the number of false negatives (F_n) - it makes false
negatives unwanted - which is good.
Thanks to that we'll recognize sick patients (1) even if sometimes it would cause notifying
a healthy patient (0) that he might be potentially sick.
### Best model
### Summary
In short:
1. It's possible to build a model which predicts health with 0.965667 recall and 0.973480 F-1 score
2. Best algorithm of machine learning is the Multi-layer Perceptron classifier
3. It's possible to hyper tune it and get only 0.1% better F-1 score
4. Model is robust, which was proved by cross validation and running on a bigger test sample
5. Dataset needs some feature engineering though
6. We may play around more with dimensionality reduction by using methods alternative to PCA
7. It's not obvious which score function to choose, although a harmonic sum of precision and recall should be enough
8. There may be a slight risk of over-fitting, but I'd need more of your data to verify this