Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/otaviof/ravine
A bridge between synchronous HTTP workload and event-driven landscapes powered by Apache Kafka.
https://github.com/otaviof/ravine
apache-kafka avro restful-api schema-registry service
Last synced: about 1 month ago
JSON representation
A bridge between synchronous HTTP workload and event-driven landscapes powered by Apache Kafka.
- Host: GitHub
- URL: https://github.com/otaviof/ravine
- Owner: otaviof
- License: apache-2.0
- Created: 2019-05-02T10:04:06.000Z (over 5 years ago)
- Default Branch: master
- Last Pushed: 2019-05-25T05:43:03.000Z (over 5 years ago)
- Last Synced: 2023-10-20T22:13:58.229Z (about 1 year ago)
- Topics: apache-kafka, avro, restful-api, schema-registry, service
- Language: Java
- Homepage:
- Size: 1.02 MB
- Stars: 18
- Watchers: 2
- Forks: 1
- Open Issues: 1
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README



# `ravine`
Ravine works as a bridge between synchronous HTTP based workload, and *event-driven* applications
landscape. It acts as a bridge holding HTTP requests while it fires a request message in
[Kafka][kafka] and wait for a response, therefore other applications can rely in this service to
offload HTTP communication, while Ravine rely in [Confluent Schema-Registry][schemaregistry] to
maintain API contracts.
The project goal is empower developers to focus on event-driven eco-systems, and easily plug HTTP
endpoints against existing Kafka based landscapes.
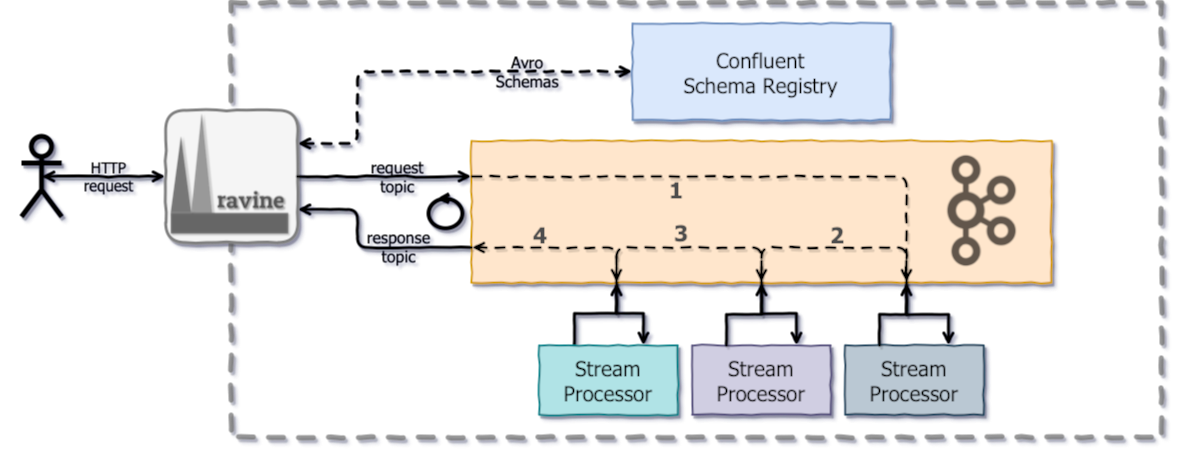
## Usage
Ravine is based on defining HTTP endpoints and mapping request and response topics. On *request
topic*, it will send payload received during HTTP communication, the payload is serialized with
configured [Schema-Registry Subject][schemaregistrysubject] version, and dispatched on *request
topic*. Ravine will wait for configured timeout, to eventually receive a message in *response
topic*, having the same unique key, where the message value is used as response payload for ongoing
HTTP request.
Furthermore, to identify the response event, Ravine will inspect Kafka message header in order to
find unique-ID in there. Therefore, you can conserve the original headers in order to respond events
back to Ravine.
The following diagram represents the high level relationship between Ravine and Kafka topics.

Regarding HTTP request parameters and headers, those are forwarded in the request event as Kafka
headers. To identify request parameters consider the header named `ravine-request-parameter-names`,
and regarding HTTP request headers, consider then `ravine-request-header-names`, where the actual
value of those variable names are actual header entries.
## Endpoints
Based on configuration you can define endpoints that will be tight up with a given Avro Schema, in
Schema-Registry. Therefore Ravine during startup will fetch the *subjects* in specified *versions*
to be able to parse payloads and produce messages.
### Health
This application is using [Spring Boot Actuator][bootactuator] plugin, therefore by querying
`/actuator/health` endpoint path, you can probe application functional status.
```
$ curl --silent http://127.0.0.1:8080/actuator/health |jq
{
"status": "UP",
"details": {
"kafka-consumer--kafka_response_topic": {
"status": "UP"
}
}
}
```
Kafka consumers in use by this application are also subject of main health check endpoint, as the
example shows.
## Configuration
Configuration for Ravine is divided in the following sections: `startup`, `cache`, `kafka` and
`routes`. Those sections are covered on the next topics. Please consider
[`applicaton.yaml`](./src/test/resources/application.yaml) as a concrete example.
### `ravine.startup`
Startup is covering the application boot, taking care of how long to wait before expose the
endpoints. In this configuration section you will find:
- `ravine.startup.timeoutMs`: timeout in milliseconds on waiting for Kafka consumers to report
ready (`RUNNING`);
- `ravine.startup.checkIntervalMs`: internal in milliseconds to check consumers status;
### `ravine.cache`
A common usage scenario is to fan out *response topic* messages to all Ravine instances, and
therefore you want to have tighter control of caching.
- `ravine.cache.maximumSize`: maximum amount of entries in cache;
- `ravine.cache.expireMs`: expiration time in milliseconds, since the record was written in cache;
### `ravine.kafka`
Kafka section covers the settings related to the Kafka ecosystem.
- `ravine.kafka.schemaRegistryUrl`: Confluent Schema-Registry URL;
- `ravine.kafka.brokers`: comma separated list of Kafka bootstrap brokers;
- `ravine.kafka.properties`: key-value pairs of Kafka properties applied to all consumers and
producers;
### `ravine.routes`
Routes are the core of Ravine's configuration, here you specify which endpoint routes are exposed
by Ravine, and what's the expected data flow path. In this section, you will find the following
sub-sections: `endpoint`, `subject`, `request` and `response`. Additionally each route has a `name`,
a simple identification tag used during tracing.
#### `ravine.routes[n].endpoint`
Endpoint defines the HTTP settings covering this route entry.
- `ravine.routes[n].endpoint.path`: route path;
- `ravine.routes[n].endpoint.methods`: HTTP methods accepted in this route, `get`, `post` or `put`;
- `ravine.routes[n].endpoint.response.httpCode`: HTTP status code, by default `200`;
- `ravine.routes[n].endpoint.response.contentType`: response content-type, by default using
`application/json`;
- `ravine.routes[n].endpoint.response.body`: payload to be displayed on a successful request;
When you define `ravine.routes[n].response`, the actual payload
`ravine.routes[n].endpoint.response.body` is not used, since the body of request will be filled by
response message coming from Kafka. Regarding `ravine.routes[n].endpoint.response.httpCode`, this
setting will only take place on a successful request, other error events are applicable here.
#### `ravine.routes[n].subject`
Subject section refers to Schema-Registry, here you define the subject name and version that will be
used to validate HTTP request, and produce a message in request Kafka topic.
- `ravine.routes[n].subject.name`: subject name;
- `ravine.routes[n].subject.version`: subject version, by default `1`;
Subjects are loaded during Ravine boot.
#### `ravine.routes[n].request`
Request defines the Kafka settings to produce a message in the topic used to gather requests for
this specific route. Third party stream consumers would tap on this topic and react on its messages.
- `ravine.routes[n].request.topic`: Kafka topic name;
- `ravine.routes[n].request.valueSerde`: value serializer class, by default:
`io.confluent.kafka.streams.serdes.avro.GenericAvroSerde`;
- `ravine.routes[n].request.timeoutMs`: timeout in milliseconds to produce a message;
- `ravine.routes[n].request.acks`: Kafka producer [`ack`][kafkaproducerdoc] approach, by default
using `all`;
- `ravine.routes[n].request.properties`: kay-value pairs of properties to be informed in producer;
#### `ravine.routes[n].response`
Response defines the Kafka topic on which Ravine wait for a response message for ongoing requests.
- `ravine.routes[n].response.topic`: Kafka topic name;
- `ravine.routes[n].response.valueSerde`: value serializer class, by default:
`io.confluent.kafka.serdes.avro.GenericAvroSerde`;
- `ravine.routes[n].request.properties`: kay-value pairs of properties to be informed in consumer;
- `ravine.routes[n].response.timeoutMs`: timeout in milliseconds to wait for response message;
## Instrumentation
This application is instrumented using [Micrometer][micrometer], which will register and accumulate
application runtime metrics, and expose them via `/actuator/prometheus` endpoint. Metrics in this
endpoint are Prometheus compatible, can be scraped in timely fashion.
```
$ curl --silent 127.0.0.1:8080/actuator/prometheus |head -n 3
# HELP logback_events_total Number of error level events that made it to the logs
# TYPE logback_events_total counter
logback_events_total{level="warn",} 7.0
```
### Jaeger Tracing
In order to trace requests throughout Ravine's runtime and Kafka, this project includes
[OpenTracing][ot] modules for [Spring Boot][otspringboot] and [Kafka Streams][otkafka], and
therefore you can offload tracing spans to Jaeger.
To enable tracing, make sure you set:
``` properties
opentracing.jaeger.enabled=true
```
More configuration can be informed as properties, please consider [upstream plugin][otspringjaeger]
documentation.
## Development
In order to run tests locally, you need to spin up the necessary backend systems, namely
[Apache Kafka][kafka] (which depends on [Apache ZooKeeper][zookeeper]), and
[Confluent Schema-Registry][schemaregistry]. They are wired up using
[Docker-Compose](./docker-compose.yaml) in a way that Ravine can reach requested backend, and using
[`localtest.me`][localtestme] to simulate DNS for Kafka-Streams consumers.
The steps required on your laptop are the same needed during CI, so please consider
[`travis.yml`](./.travis.yml) as documentation.
Source code of this project is formatted using [Google Java Format][googlejavaformat] style, please
make sure your IDE is prepared to format and clean-up the code in that fashion.
### Releasing
To release new versions, execute the following:
``` bash
gradlew release
```
The [release plugin][gradlerelease] will execute a number of steps to release this project, by
tagging and pushing the code, plus prepating a new version. Some steps are interactive.
[bootactuator]: https://docs.spring.io/spring-boot/docs/current/reference/htmlsingle/#production-ready
[googlejavaformat]: https://github.com/google/google-java-format
[gradlerelease]: https://github.com/researchgate/gradle-release
[kafka]: https://kafka.apache.org
[kafkaproducerdoc]: https://docs.confluent.io/current/installation/configuration/producer-configs.html
[localtestme]: http://readme.localtest.me
[micrometer]: http://micrometer.io
[ot]: https://opentracing.io
[otkafka]: https://github.com/opentracing-contrib/java-kafka-client
[otspringboot]: https://github.com/opentracing-contrib/java-spring-cloud
[otspringjaeger]: https://github.com/opentracing-contrib/java-spring-jaeger#configuration-options
[schemaregistry]: https://www.confluent.io/confluent-schema-registry
[schemaregistrysubject]: https://docs.confluent.io/current/schema-registry/index.html#schemas-subjects-and-topics
[zookeeper]: https://zookeeper.apache.org

