https://github.com/overlordgolddragon/keras-adamw
Keras/TF implementation of AdamW, SGDW, NadamW, Warm Restarts, and Learning Rate multipliers
https://github.com/overlordgolddragon/keras-adamw
adamw adamwr keras learning-rate-multipliers nadam optimizers sgd tensorflow warm-restarts
Last synced: 3 months ago
JSON representation
Keras/TF implementation of AdamW, SGDW, NadamW, Warm Restarts, and Learning Rate multipliers
- Host: GitHub
- URL: https://github.com/overlordgolddragon/keras-adamw
- Owner: OverLordGoldDragon
- License: mit
- Created: 2019-09-27T01:28:13.000Z (almost 6 years ago)
- Default Branch: master
- Last Pushed: 2022-01-06T14:01:05.000Z (over 3 years ago)
- Last Synced: 2025-04-02T18:11:21.143Z (3 months ago)
- Topics: adamw, adamwr, keras, learning-rate-multipliers, nadam, optimizers, sgd, tensorflow, warm-restarts
- Language: Python
- Homepage:
- Size: 145 KB
- Stars: 167
- Watchers: 6
- Forks: 25
- Open Issues: 1
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# Keras AdamW
[](https://travis-ci.com/OverLordGoldDragon/keras-adamw)
[](https://coveralls.io/github/OverLordGoldDragon/keras-adamw)
[](https://www.codacy.com?utm_source=github.com&utm_medium=referral&utm_content=OverLordGoldDragon/keras-adamw&utm_campaign=Badge_Grade)
[](https://badge.fury.io/py/keras-adamw)
[](https://doi.org/10.5281/zenodo.5080529)
[](https://opensource.org/licenses/MIT)




Keras/TF implementation of **AdamW**, **SGDW**, **NadamW**, and **Warm Restarts**, based on paper [Decoupled Weight Decay Regularization](https://arxiv.org/abs/1711.05101) - plus **Learning Rate Multipliers**
## Features
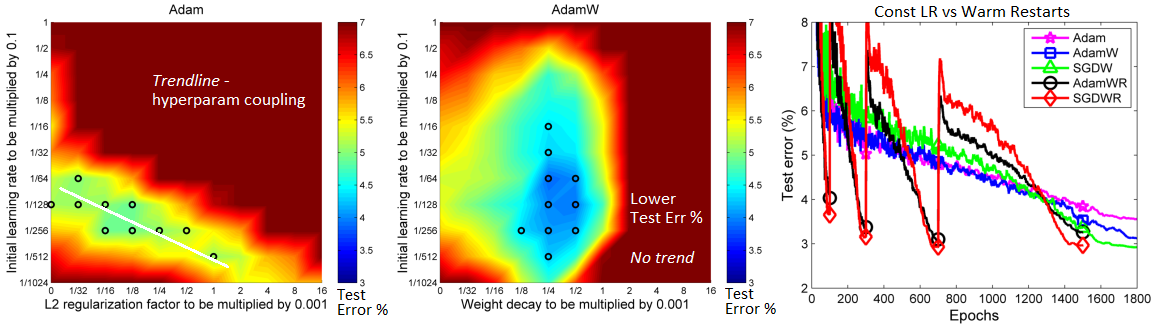
- **Weight decay fix**: decoupling L2 penalty from gradient. _Why use?_
- Weight decay via L2 penalty yields _worse generalization_, due to decay not working properly
- Weight decay via L2 penalty leads to a _hyperparameter coupling_ with `lr`, complicating search
- **Warm restarts (WR)**: cosine annealing learning rate schedule. _Why use?_
- _Better generalization_ and _faster convergence_ was shown by authors for various data and model sizes
- **LR multipliers**: _per-layer_ learning rate multipliers. _Why use?_
- _Pretraining_; if adding new layers to pretrained layers, using a global `lr` is prone to overfitting
## Installation
`pip install keras-adamw`. Or, for latest version (most likely stable):
`pip install git+https://github.com/OverLordGoldDragon/keras-adamw`
## Usage
If using tensorflow.keras imports, set `import os; os.environ["TF_KERAS"]='1'`.
### Weight decay
`AdamW(model=model)`
Three methods to set `weight_decays = {:,}`:
```python
# 1. Automatically
Just pass in `model` (`AdamW(model=model)`), and decays will be automatically extracted.
Loss-based penalties (l1, l2, l1_l2) will be zeroed by default, but can be kept via
`zero_penalties=False` (NOT recommended, see Use guidelines).
```
```python
# 2. Use keras_adamw.utils.py
Dense(.., kernel_regularizer=l2(0)) # set weight decays in layers as usual, but to ZERO
wd_dict = get_weight_decays(model)
# print(wd_dict) to see returned matrix names, note their order
# specify values as (l1, l2) tuples, both for l1_l2 decay
ordered_values = [(0, 1e-3), (1e-4, 2e-4), ..]
weight_decays = fill_dict_in_order(wd_dict, ordered_values)
```
```python
# 3. Fill manually
model.layers[1].kernel.name # get name of kernel weight matrix of layer indexed 1
weight_decays.update({'conv1d_0/kernel:0': (1e-4, 0)}) # example
```
### Warm restarts
`AdamW(.., use_cosine_annealing=True, total_iterations=200)` - refer to _Use guidelines_ below
### LR multipliers
`AdamW(.., lr_multipliers=lr_multipliers)` - to get, `{:,}`:
1. (a) Name every layer to be modified _(recommended)_, e.g. `Dense(.., name='dense_1')` - OR
(b) Get every layer name, note which to modify: `[print(idx,layer.name) for idx,layer in enumerate(model.layers)]`
2. (a) `lr_multipliers = {'conv1d_0':0.1} # target layer by full name` - OR
(b) `lr_multipliers = {'conv1d':0.1} # target all layers w/ name substring 'conv1d'`
## Example
```python
import numpy as np
from keras.layers import Input, Dense, LSTM
from keras.models import Model
from keras.regularizers import l1, l2, l1_l2
from keras_adamw import AdamW
ipt = Input(shape=(120, 4))
x = LSTM(60, activation='relu', name='lstm_1',
kernel_regularizer=l1(1e-4), recurrent_regularizer=l2(2e-4))(ipt)
out = Dense(1, activation='sigmoid', kernel_regularizer=l1_l2(1e-4, 2e-4))(x)
model = Model(ipt, out)
```
```python
lr_multipliers = {'lstm_1': 0.5}
optimizer = AdamW(lr=1e-4, model=model, lr_multipliers=lr_multipliers,
use_cosine_annealing=True, total_iterations=24)
model.compile(optimizer, loss='binary_crossentropy')
```
```python
for epoch in range(3):
for iteration in range(24):
x = np.random.rand(10, 120, 4) # dummy data
y = np.random.randint(0, 2, (10, 1)) # dummy labels
loss = model.train_on_batch(x, y)
print("Iter {} loss: {}".format(iteration + 1, "%.3f" % loss))
print("EPOCH {} COMPLETED\n".format(epoch + 1))
```
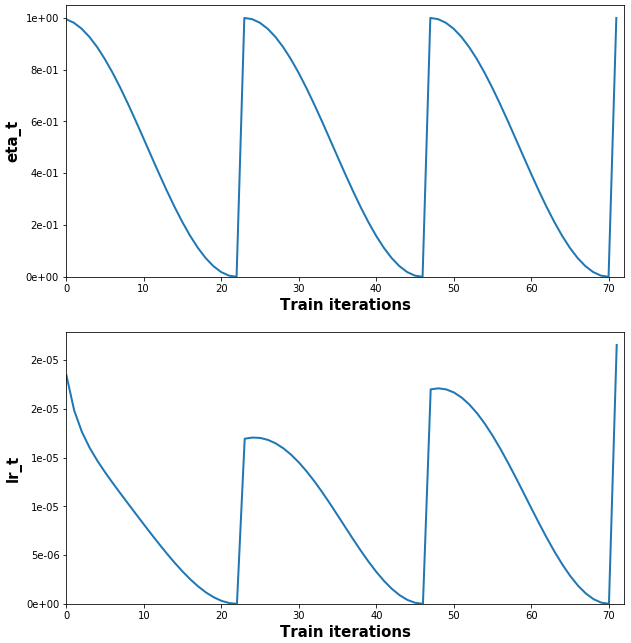
(Full example + plot code, and explanation of `lr_t` vs. `lr`: [example.py](https://github.com/OverLordGoldDragon/keras-adamw/blob/master/example.py))
## Use guidelines
### Weight decay
- **Set L2 penalty to ZERO** if regularizing a weight via `weight_decays` - else the purpose of the 'fix' is largely defeated, and weights will be over-decayed --_My recommendation_
- `lambda = lambda_norm * sqrt(1/total_iterations)` --> _can be changed_; the intent is to scale λ to _decouple_ it from other hyperparams - including (but _not limited to_), # of epochs & batch size. --_Authors_ (Appendix, pg.1) (A-1)
- `total_iterations_wd` --> set to normalize over _all epochs_ (or other interval `!= total_iterations`) instead of per-WR when using WR; may _sometimes_ yield better results --_My note_
### Warm restarts
- Done automatically with `autorestart=True`, which is the default if `use_cosine_annealing=True`; internally sets `t_cur=0` after `total_iterations` iterations.
- Manually: set `t_cur = -1` to restart schedule multiplier (see _Example_). Can be done at compilation or during training. Non-`-1` is also valid, and will start `eta_t` at another point on the cosine curve. Details in A-2,3
- `t_cur` should be set at `iter == total_iterations - 2`; explanation [here](https://github.com/OverLordGoldDragon/keras-adamw/blob/v1.35/tests/test_optimizers.py#L52)
- Set `total_iterations` to the # of expected weight updates _for the given restart_ --_Authors_ (A-1,2)
- `eta_min=0, eta_max=1` are tunable hyperparameters; e.g., an exponential schedule can be used for `eta_max`. If unsure, the defaults were shown to work well in the paper. --_Authors_
- **[Save/load](https://keras.io/getting-started/faq/#how-can-i-save-a-keras-model) optimizer state**; WR relies on using the optimizer's update history for effective transitions --_Authors_ (A-2)
```python
# 'total_iterations' general purpose example
def get_total_iterations(restart_idx, num_epochs, iterations_per_epoch):
return num_epochs[restart_idx] * iterations_per_epoch[restart_idx]
get_total_iterations(0, num_epochs=[1,3,5,8], iterations_per_epoch=[240,120,60,30])
```
### Learning rate multipliers
- Best used for pretrained layers - e.g. greedy layer-wise pretraining, or pretraining a feature extractor to a classifier network. Can be a better alternative to freezing layer weights. --_My recommendation_
- It's often best not to pretrain layers fully (till convergence, or even best obtainable validation score) - as it may inhibit their ability to adapt to newly-added layers. --_My recommendation_
- The more the layers are pretrained, the lower their fraction of new layers' `lr` should be. --_My recommendation_
## How to cite
Short form:
> John Muradeli, keras-adamw, 2019. GitHub repository, https://github.com/OverLordGoldDragon/keras-adamw/. DOI: 10.5281/zenodo.5080529
BibTeX:
```bibtex
@article{OverLordGoldDragon2019keras-adamw,
title={Keras AdamW},
author={John Muradeli},
journal={GitHub. Note: https://github.com/OverLordGoldDragon/keras-adamw/},
year={2019},
doi={10.5281/zenodo.5080529},
}
```