https://github.com/oxylabs/csharp-web-scraping
Web Scraping With C#
https://github.com/oxylabs/csharp-web-scraping
csharp web-scraping web-scraping-csharp
Last synced: about 1 month ago
JSON representation
Web Scraping With C#
- Host: GitHub
- URL: https://github.com/oxylabs/csharp-web-scraping
- Owner: oxylabs
- Created: 2022-08-18T07:17:24.000Z (almost 4 years ago)
- Default Branch: main
- Last Pushed: 2025-06-26T08:22:46.000Z (about 1 year ago)
- Last Synced: 2025-06-26T09:30:42.438Z (about 1 year ago)
- Topics: csharp, web-scraping, web-scraping-csharp
- Language: C#
- Homepage: https://oxylabs.io/blog/csharp-web-scraping
- Size: 35.2 KB
- Stars: 1
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Web Scraping With C#
[](https://oxylabs.io/pages/gitoxy?utm_source=877&utm_medium=affiliate&groupid=877&utm_content=csharp-web-scraping-github&transaction_id=102f49063ab94276ae8f116d224b67)
[](https://discord.gg/Pds3gBmKMH) [](https://www.youtube.com/@oxylabs)
See the full article on our [website](https://oxylabs.io/blog/csharp-web-scraping), where we also go over how to scrape dynamic pages in C#.
## Setup Development environment
```bash
dotnet --version
```
## Project Structure and Dependencies
```bash
dotnet new console
```
```bash
dotnet add package HtmlAgilityPack
```
```bash
dotnet add package CsvHelper
```
## Download and Parse Web Pages
The first step of any web scraping program is to download the HTML of a web page. This HTML will be a string that you’ll need to convert into an object that can be processed further. The latter part is called parsing. Html Agility Pack can read and parse files from local files, HTML strings, any URL, or even a browser.
In our case, all we need to do is get HTML from a URL. Instead of using .NET native functions, Html Agility Pack provides a convenient class – HtmlWeb. This class offers a Load function that can take a URL and return an instance of the HtmlDocument class, which is also part of the package we use. With this information, we can write a function that takes a URL and returns an instance of HtmlDocument.
The first step is to import the required library files. Open the `Program.cs` file and import the library files using the following code:
```csharp
using HtmlAgilityPack;
```
Then, open `Program.cs` file and enter this function in the class Program:
```csharp
// Parses the URL and returns HtmlDocument object
static HtmlDocument GetDocument(string url)
{
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load(url);
return doc;
}
```
With this, the first step of the code is complete. The next step is to parse the document.
## Parsing the HTML: Getting Book Links
In this part of the code, we’ll be extracting the required information from the web page. At this stage, a document is now an object of type HtmlDocument. This class exposes two functions to select the elements. Both functions accept XPath as input and return HtmlNode or HtmlNodeCollection. Here is the signature of these two functions:
```csharp
public HtmlNodeCollection SelectNodes(string xpath);
```
```csharp
public HtmlNode SelectSingleNode(string xpath);
```
Let’s discuss `SelectNodes` first.
For this example – C# web scraper – we are going to scrape all the book details from this page. First, it needs to be parsed so that all the links to the books can be extracted. To do that, open this page in the browser, right-click any of the book links and click Inspect. This will open the Developer Tools.
After understanding some time with the markup, your XPath to select should be something like this:
```css
//h3/a
```
This XPath can now be passed to the `SelectNodes` function.
```csharp
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
```
Note that the `SelectNodes` function is being called by the `DocumentNode` attribute of the `HtmlDocument`.
The variable `linkNodes` is a collection. We can write a `foreach` loop over it and get the `href` from each link one by one. There is one tiny problem that we need to take care of – the links on the page are relative. Hence, they need to be converted into an absolute URL before we can scrape these extracted links.
For converting the relative URLs, we can make use of the `Uri` class. We can use this constructor to get a `Uri` object with an absolute URL.
```csharp
Uri(Uri baseUri, string? relativeUri);
```
Once we have the Uri object, we can simply check the `AbsoluteUri` property to get the complete URL.
We can write all this in a function to keep the code organized.
```csharp
static List GetBookLinks(string url)
{
var bookLinks = new List();
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
var baseUri = new Uri(url);
foreach (var link in linkNodes)
{
string href = link.Attributes["href"].Value;
bookLinks.Add(new Uri(baseUri, href).AbsoluteUri);
}
return bookLinks;
}
```
In this function, we are starting with an empty `List` object. In the `foreach` loop, we are adding all the links to this object and returning it.
Now, it’s time to modify the `Main()` function so that we can test the C# code that we have written so far. Modify the function so that it looks like this:
```csharp
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/catalogue/category/books/mystery_3/index.html");
Console.WriteLine("Found {0} links", bookLinks.Count);
}
```
To run this code, open the terminal and navigate to the directory which contains this file, and type in the following:
```bash
dotnet run
```
The output should be as follows:
```
Found 20 links
```
Let’s move to the next part where we will be processing all the links to get the book data.
## Parsing the HTML: Getting Book Details
At this point, we have a list of strings that contain the URLs of the books. We can simply write a loop that will first get the document using the GetDocument function that we’ve already written. After that, we’ll use the SelectSingleNode function to extract the title and the price of the book.
To keep the data organized, let’s start with a class. This class will represent a book. This class will have two properties – Title and Price. It will look like this:
```csharp
public class Book
{
public string Title { get; set; }
public string Price { get; set; }
}
```
Now, open a book page in the browser and create the XPath for the `Title – //h1`. Creating an XPath for the price is a little trickier because the additional books at the bottom have the same class applied.
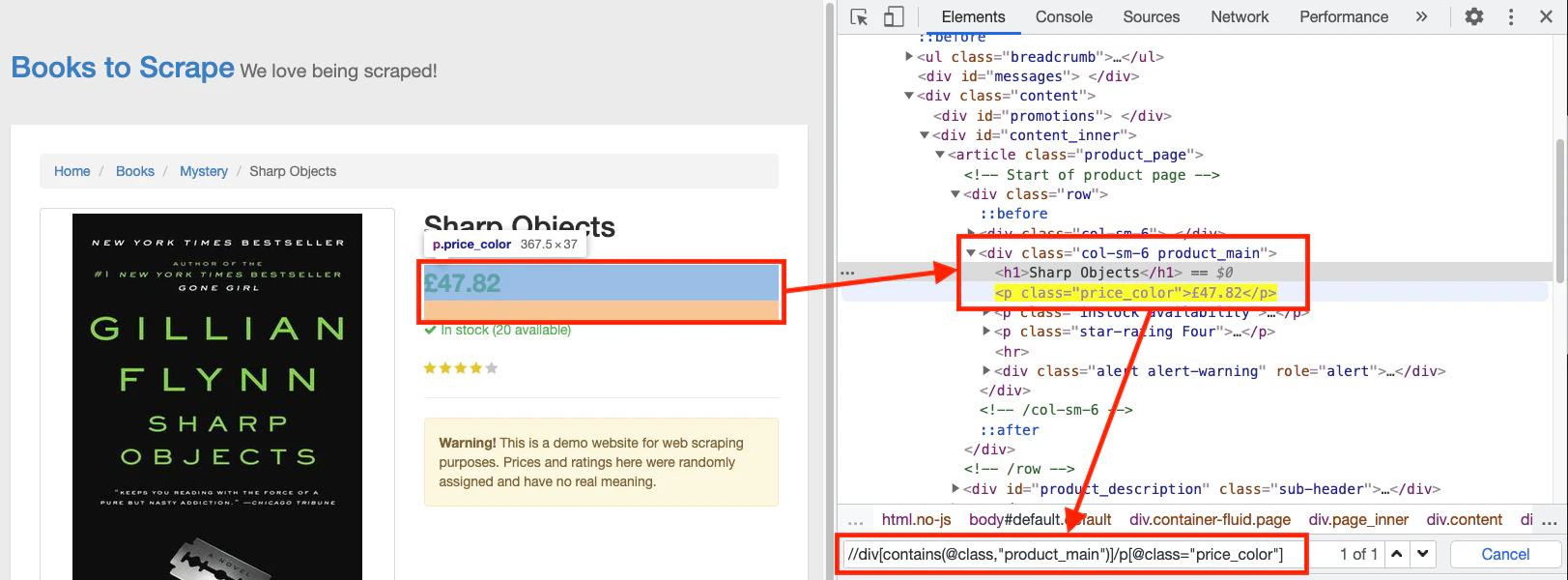
The XPath of the price will be this:
```
//div[contains(@class,"product_main")]/p[@class="price_color"]
```
Note that XPath contains double quotes. We will have to escape these characters by prefixing them with a backslash.
Now we can use the `SelectSingleNode` function to get the Node, and then employ the `InnerText` property to get the text contained in the element. We can organize everything in a function as follows:
```csharp
static List GetBookDetails(List urls)
{
var books = new List();
foreach (var url in urls)
{
HtmlDocument document = GetDocument(url);
var titleXPath = "//h1";
var priceXPath = "//div[contains(@class,\"product_main\")]/p[@class=\"price_color\"]";
var book = new Book();
book.Title = document.DocumentNode.SelectSingleNode(titleXPath).InnerText;
book.Price = document.DocumentNode.SelectSingleNode(priceXPath).InnerText;
books.Add(book);
}
return books;
}
```
This function will return a list of `Book` objects. It’s time to update the `Main()` function as well:
```csharp
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/catalogue/category/books/mystery_3/index.html");
Console.WriteLine("Found {0} links", bookLinks.Count);
var books = GetBookDetails(bookLinks);
}
```
## Exporting Data
If you haven’t yet installed the `CsvHelper`, you can do this by running the command `dotnet add package CsvHelper` from within the terminal.
After installation, import the `CsvHelper` class in your `Program.cs` file like this:
```csharp
using System.Globalization;
using CsvHelper;
```
The export function is pretty straightforward. First, we need to create a `StreamWriter` and send the CSV file name as the parameter. Next, we will use this object to create a `CsvWriter`. Finally, we can use the `WriteRecords` function to write all the books in just one line of code.
To ensure that all the resources are closed properly, we can use the `using` block. We can also wrap everything in a function as follows:
```csharp
static void exportToCSV(List books)
{
using (var writer = new StreamWriter("./books.csv"))
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
csv.WriteRecords(books);
}
}
```
Finally, we can call this function from the `Main()` function:
```csharp
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/catalogue/category/books/mystery_3/index.html");
var books = GetBookDetails(bookLinks);
exportToCSV(books);
}
```
Let’s bring together all the snippets and have a look at the complete code:
```csharp
using System.Globalization;
using CsvHelper;
using HtmlAgilityPack;
namespace webscraping
{
class Program
{
static HtmlDocument GetDocument(string url)
{
HtmlWeb web = new HtmlWeb();
HtmlDocument doc = web.Load(url);
return doc;
}
static List GetBookLinks(string url)
{
var bookLinks = new List();
HtmlDocument doc = GetDocument(url);
HtmlNodeCollection linkNodes = doc.DocumentNode.SelectNodes("//h3/a");
var baseUri = new Uri(url);
foreach (var link in linkNodes)
{
string href = link.Attributes["href"].Value;
bookLinks.Add(new Uri(baseUri, href).AbsoluteUri);
}
return bookLinks;
}
static List GetBookDetails(List urls)
{
var books = new List();
foreach (var url in urls)
{
HtmlDocument document = GetDocument(url);
var titleXPath = "//h1";
var priceXPath = "//div[contains(@class,\"product_main\")]/p[@class=\"price_color\"]";
var book = new Book();
book.Title = document.DocumentNode.SelectSingleNode(titleXPath).InnerText;
book.Price = document.DocumentNode.SelectSingleNode(priceXPath).InnerText;
books.Add(book);
}
return books;
}
static void exportToCSV(List books)
{
using (var writer = new StreamWriter("books.csv"))
using (var csv = new CsvWriter(writer, CultureInfo.InvariantCulture))
{
csv.WriteRecords(books);
}
}
static void Main(string[] args)
{
var bookLinks = GetBookLinks("http://books.toscrape.com/catalogue/category/books/mystery_3/index.html");
Console.WriteLine("Found {0} links", bookLinks.Count);
var books = GetBookDetails(bookLinks);
exportToCSV(books);
}
}
}
```
That’s it! To run this code, open the terminal and run the following command:
```bash
dotnet run
```
Within seconds, you will have a `books.csv` file created.