Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/oxylabs/puppeteer-on-aws-lambda
Puppeteer on AWS Lambda
https://github.com/oxylabs/puppeteer-on-aws-lambda
aws-lambda chrome-aws-lambada puppeteer puppeteer-core puppeteer-lambada
Last synced: about 2 hours ago
JSON representation
Puppeteer on AWS Lambda
- Host: GitHub
- URL: https://github.com/oxylabs/puppeteer-on-aws-lambda
- Owner: oxylabs
- Created: 2022-08-18T09:01:16.000Z (about 2 years ago)
- Default Branch: main
- Last Pushed: 2024-04-19T10:49:13.000Z (7 months ago)
- Last Synced: 2024-04-21T02:04:46.896Z (7 months ago)
- Topics: aws-lambda, chrome-aws-lambada, puppeteer, puppeteer-core, puppeteer-lambada
- Language: JavaScript
- Homepage:
- Size: 12.7 KB
- Stars: 1
- Watchers: 2
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Puppeteer on AWS Lambda
[](https://oxylabs.go2cloud.org/aff_c?offer_id=7&aff_id=877&url_id=112)
[](https://discord.gg/GbxmdGhZjq)
## Problem #1 – Puppeteer is too big to push to Lambda
AWS Lambda has a 50 MB limit on the zip file you push directly to it. Due to the fact that it installs Chromium, the Puppeteer package is significantly larger than that. However, this 50 MB limit doesn’t apply when you load the function from S3! See the documentation [here](https://docs.aws.amazon.com/lambda/latest/dg/gettingstarted-limits.html).
AWS Lambda quotas can be tight for Puppeteer:
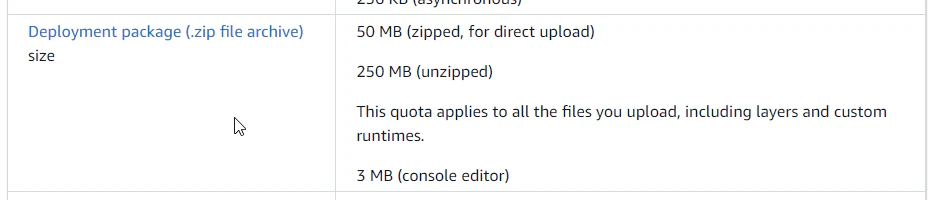
The 250 MB unzipped can be bypassed by uploading directly from an S3 bucket. So I create a bucket in S3, use a node script to upload to S3, and then update my Lambda code from that bucket. The script looks something like this:
```bash
"zip": "npm run build && 7z a -r function.zip ./dist/* node_modules/",
"sendToLambda": "npm run zip && aws s3 cp function.zip s3://chrome-aws && rm function.zip && aws lambda update-function-code --function-name puppeteer-examples --s3-bucket chrome-aws --s3-key function.zip"
```
## Problem #2 – Puppeteer on AWS Lambda doesn’t work
By default, Linux (including AWS Lambda) doesn’t include the necessary libraries required to allow Puppeteer to function.
Fortunately, there already exists a package of Chromium built for AWS Lambda. You can find it [here](https://www.npmjs.com/package/chrome-aws-lambda). You will need to install it and puppeteer-core in your function that you are sending to Lambda.
The regular Puppeteer package will not be needed and, in fact, counts against your 250 MB limit.
```node
npm i --save chrome-aws-lambda puppeteer-core
```
And then, when you are setting it up to launch a browser from Puppeteer, it will look like this:
```javascript
const browser = await chromium.puppeteer
.launch({
args: chromium.args,
defaultViewport: chromium.defaultViewport,
executablePath: await chromium.executablePath,
headless: chromium.headless
});
```
## Final note
Puppeteer requires more memory than a regular script, so keep an eye on your max memory usage. When using Puppeteer, I recommend at least 512 MB on your AWS Lambda function.
Also, don’t forget to run `await browser.close()` at the end of your script. Otherwise, you may end up with your function running until timeout for no reason because the browser is still alive and waiting for commands.