https://github.com/oxylabs/web-scraping-with-java
Web Scraping With Java. Let’s examine this library to create a Java website scraper.
https://github.com/oxylabs/web-scraping-with-java
java-web-scraper jsoup-library node-js node-scraper nodejs web-scraping-with-java
Last synced: about 1 month ago
JSON representation
Web Scraping With Java. Let’s examine this library to create a Java website scraper.
- Host: GitHub
- URL: https://github.com/oxylabs/web-scraping-with-java
- Owner: oxylabs
- Created: 2022-08-18T08:33:44.000Z (almost 4 years ago)
- Default Branch: main
- Last Pushed: 2025-09-23T08:51:51.000Z (9 months ago)
- Last Synced: 2025-09-23T10:27:38.822Z (9 months ago)
- Topics: java-web-scraper, jsoup-library, node-js, node-scraper, nodejs, web-scraping-with-java
- Homepage:
- Size: 29.3 KB
- Stars: 3
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Web Scraping With Java
[](https://oxylabs.io/pages/gitoxy?utm_source=877&utm_medium=affiliate&groupid=877&utm_content=web-scraping-with-java-github&transaction_id=102f49063ab94276ae8f116d224b67)
[](https://discord.gg/Pds3gBmKMH) [](https://www.youtube.com/@oxylabs)
## Getting JSoup
The first step of web scraping with Java is to get the Java libraries. Maven can help here. Use any Java IDE, and create a Maven project. If you do not want to use Maven, head over to this page to find alternate downloads.
In the `pom.xml` (Project Object Model) file, add a new section for dependencies and add a dependency for JSoup. The `pom.xml` file would look something like this:
```java
org.jsoup
jsoup
1.14.1
```
With this, we are ready to create a Java scraper.
## Getting and parsing the HTML
The second step of web scraping with Java is to get the HTML from the target URL and parse it into a Java object. Let’s begin with the imports:
```java
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
```
Note that it is not a good practice to import everything with a wildcard – `import org.jsoup.*.` Always import exactly what you need. The above imports are what we are going to use in this Java web scraping tutorial.
JSoup provides the `connect` function. This function takes the URL and returns a `Document`. Here is how you can get the page’s HTML:
```java
Document doc = Jsoup.connect("https://en.wikipedia.org/wiki/Jsoup").get();
```
You will often see this line in places, but it has a disadvantage. This shortcut does not have any error handling. A better approach would be to create a function. This function takes a URL as the parameter. First, it creates a connection and stores it in a variable. After that, the `get()` method of the connection object is called to retrieve the HTML document. This document is returned as an instance of the `Document` class. The `get()` method can throw an `IOException`, which needs to be handled.
```java
public static Document getDocument(String url) {
Connection conn = Jsoup.connect(url);
Document document = null;
try {
document = conn.get();
} catch (IOException e) {
e.printStackTrace();
// handle error
}
return document;
}
```
In some instances, you would need to pass a custom user agent. This can be done by sending the user agent string to the `userAgent()` function before calling the `get()` function.
```java
Connection conn = Jsoup.connect(url);
conn.userAgent("custom user agent");
document = conn.get();
```
This action should resolve all the common problems.
## Querying HTML
The most crucial step of any Java web scraper building process is to query the HTML `Document` object for the desired data. This is the point where you will be spending most of your time while writing the web scraper in Java.
JSoup supports many ways to extract the desired elements. There are many methods, such as `getElementByID`, `getElementsByTag`, etc., that make it easier to query the DOM.
Here is an example of navigating to the JSoup page on Wikipedia. Right-click the heading and select Inspect, thus opening the developer tool with the heading selected.
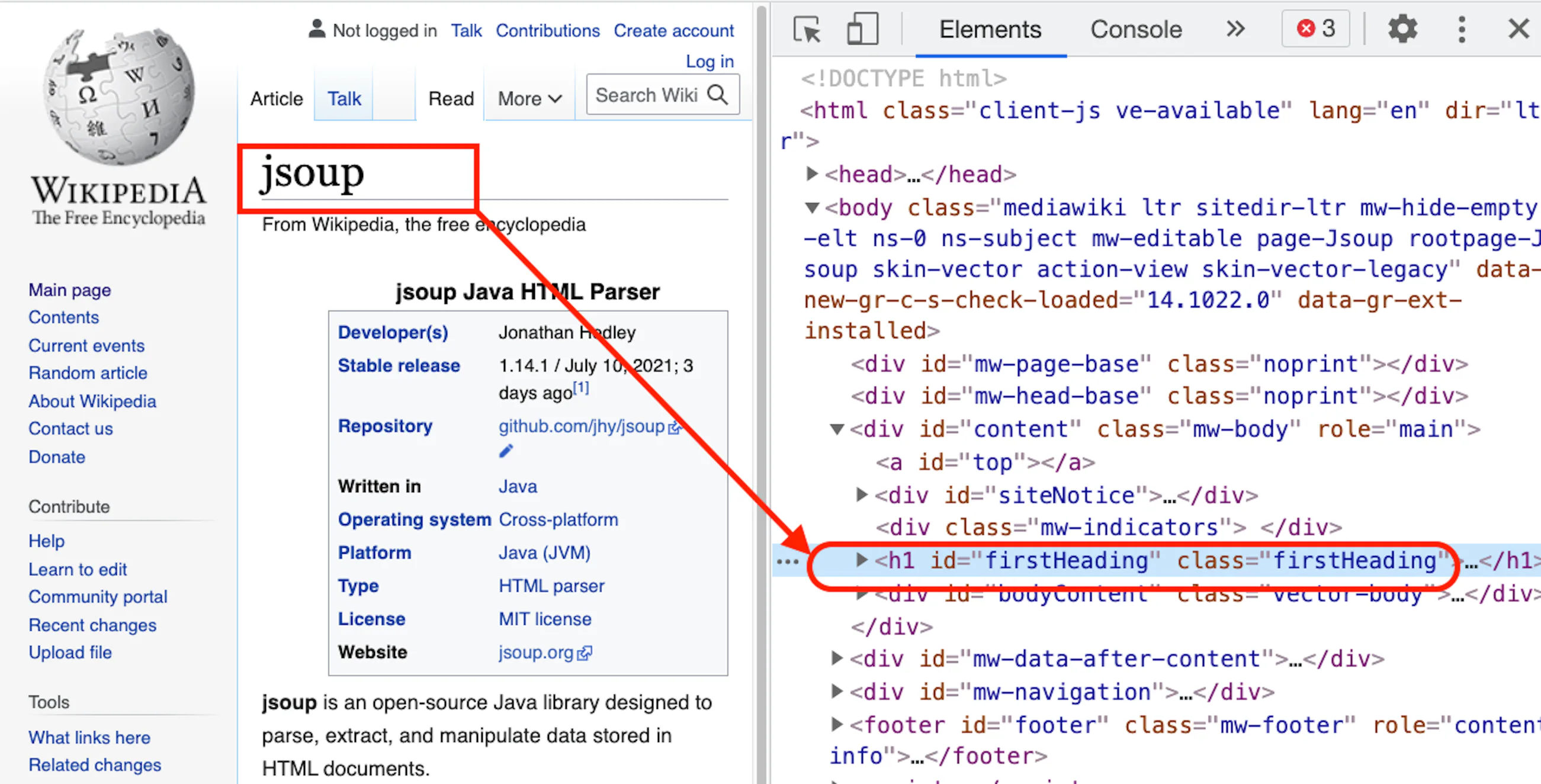
In this case, either `getElementByID` or `getElementsByClass` can be used. One important point to note here is that `getElementById` (note the singular `Element`) returns one `Element` object, whereas `getElementsByClass` (note plural `Elements`) returns an Array list of `Element` objects.
Conveniently, this library has a class `Elements` that extends `ArrayList`. This makes code cleaner and provides more functionality.
In the code example below, the `first()` method can be used to get the first element from the `ArrayList`. After getting the reference of the element, the `text()` method can be called to get the text.
```java
Element firstHeading = document.getElementsByClass("firstHeading").first();
System.out.println(firstHeading.text());
```
These functions are good; however, they are specific to JSoup. For most cases, the select function can be a better choice. The only case when select functions will not work is when you need to traverse up the document. In these cases, you may want to use `parent()`, `children()`, and `child()`. For a complete list of all the available methods, visit this page.
The following code demonstrates how to use the `selectFirst()` method, which returns the first match.
```java
Element firstHeading= document.selectFirst(".firstHeading");
```
In this example, `selectFirst()` method was used. If multiple elements need to be selected, you can use the `select()` method. This will take the CSS selector as a parameter and return an instance of Elements, which is an extension of the type `ArrayList`.
## Getting and parsing the HTML
The first step of web scraping with Java is to get the Java libraries. Maven can help here. Create a new maven project or use the one created in the previous section. If you do not want to use Maven, head over to this page to find alternate downloads.
In the `pom.xml` file, add a new section for `dependencies` and add a dependency for HtmlUnit. The `pom.xml` file would look something like this:
```java
net.sourceforge.htmlunit
htmlunit
2.51.0
```
## Getting the HTML
The second step of web scraping with Java is to retrieve the HTML from the target URL as a Java object. Let’s begin with the imports:
```java
import com.gargoylesoftware.htmlunit.WebClient;
import com.gargoylesoftware.htmlunit.html.DomNode;
import com.gargoylesoftware.htmlunit.html.DomNodeList;
import com.gargoylesoftware.htmlunit.html.HtmlElement;
import com.gargoylesoftware.htmlunit.html.HtmlPage;
```
As discussed in the previous section, it is not a good practice to do a wildcard import such as `import com.gargoylesoftware.htmlunit.html.*`. Import only what you need. The above imports are what we are going to use in this Java web scraping tutorial.
In this example, we will scrape this Librivox page.
HtmlUnit uses `WebClient` class to get the page. The first step would be to create an instance of this class. In this example, there is no need for CSS rendering, and there is no use of JavaScript as well. We can set the options to disable these two.
```java
WebClient webClient = new WebClient();
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
HtmlPage page = webClient.getPage("https://librivox.org/the-first-men-in-the-moon-by-hg-wells");
```
Note that `getPage()` functions can throw `IOException`. You would need to surround it in try-catch.
Here is one example implementation of a function that returns an instance of `HtmlPage`:
```java
public static HtmlPage getDocument(String url) {
HtmlPage page = null;
try (final WebClient webClient = new WebClient()) {
webClient.getOptions().setCssEnabled(false);
webClient.getOptions().setJavaScriptEnabled(false);
page = webClient.getPage(url);
} catch (IOException e) {
e.printStackTrace();
}
return page;
}
```
Now we can proceed with the next step.
## Querying HTML
There are three categories of methods that can be used with `HTMLPage`. The first is DOM methods such as `getElementById()`, `getElementByName()`, etc. that return one element. These also have their counterparts like `getElementsById()` that return all the matches. These methods return a `DomElement` object or a List of `DomElement` objects.
```java
HtmlPage page = webClient.getPage("https://en.wikipedia.org/wiki/Jsoup");
DomElement firstHeading = page.getElementById("firstHeading");
System.out.print(firstHeading.asNormalizedText()); // prints Jsoup
```
The second category of a selector uses XPath. In this Java web scraping tutorial, we will go through creating a web scraper using Java.
Navigate to this page, right-click the book title and click inspect. If you are already comfortable with XPath, you should be able to see that the XPath to select the book title would be `//div[@class="content-wrap clearfix"]/h1`.
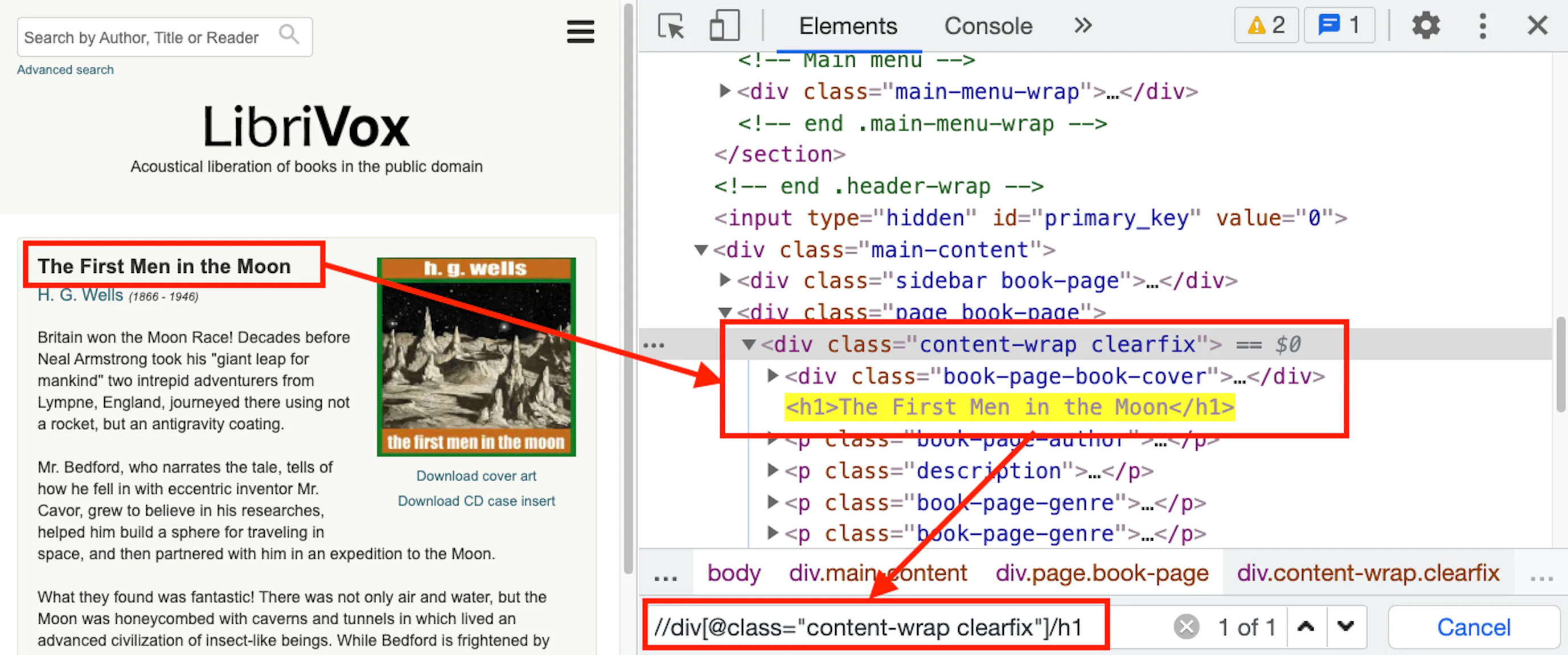
There are two methods that can work with XPath — `getByXPath()` and `getFirstByXPath()`. They return HtmlElement instead of DomElement. Note that special characters like quotation marks will need to be escaped using a backslash:
```java
HtmlElement book = page.getFirstByXPath("//div[@class=\"content-wrap clearfix\"]/h1");
System.out.print(book.asNormalizedText());
```
Lastly, the third category of methods uses CSS selectors. These methods are `querySelector()` and `querySelectorAll()`. They return `DomNode` and `DomNodeList` respectively.
To make this Java web scraper tutorial more realistic, let’s print all the chapter names, reader names, and duration from the page. The first step is to determine the selector that can select all rows. Next, we will use the `querySelectorAll()` method to select all the rows. Finally, we will run a loop on all the rows and call `querySelector()` to extract the content of each cell.
```java
String selector = ".chapter-download tbody tr";
DomNodeList rows = page.querySelectorAll(selector);
for (DomNode row : rows) {
String chapter = row.querySelector("td:nth-child(2) a").asNormalizedText();
String reader = row.querySelector("td:nth-child(3) a").asNormalizedText();
String duration = row.querySelector("td:nth-child(4)").asNormalizedText();
System.out.println(chapter + "\t " + reader + "\t " + duration);
}
```