https://github.com/paganini2008/greenfinger
GreenFinger is a cutting-edge distributed web crawling framework built on Spring Cloud, PostgreSQL, and Elasticsearch, powered by the high-performance Netty NIO engine. It features an intuitive Web UI for managing and monitoring tasks, dynamic node scaling, and real-time data processing.
https://github.com/paganini2008/greenfinger
distributed-systems high-performance mircoservice netty4 playwright realtime-messaging selenium springboot2 webcrawler webscraping
Last synced: 4 months ago
JSON representation
GreenFinger is a cutting-edge distributed web crawling framework built on Spring Cloud, PostgreSQL, and Elasticsearch, powered by the high-performance Netty NIO engine. It features an intuitive Web UI for managing and monitoring tasks, dynamic node scaling, and real-time data processing.
- Host: GitHub
- URL: https://github.com/paganini2008/greenfinger
- Owner: paganini2008
- License: apache-2.0
- Created: 2021-02-02T08:37:54.000Z (over 5 years ago)
- Default Branch: main
- Last Pushed: 2025-02-04T00:37:47.000Z (over 1 year ago)
- Last Synced: 2025-09-22T16:43:16.765Z (9 months ago)
- Topics: distributed-systems, high-performance, mircoservice, netty4, playwright, realtime-messaging, selenium, springboot2, webcrawler, webscraping
- Language: Java
- Homepage: https://paganini2008.github.io/2021/06/Introduction-to-Greenfinger-High-Performance-Distributed-Web-Crawling-Framework/
- Size: 273 MB
- Stars: 1
- Watchers: 1
- Forks: 1
- Open Issues: 7
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# Greenfinger
[](LICENSE)
[](https://spring.io/projects/spring-cloud)
[](https://www.postgresql.org/)
[](https://www.elastic.co/)
[](https://netty.io/)
[**GreenFinger**](https://github.com/paganini2008/greenfinger) is a high-performance, highly scalable distributed web crawler built in Java. Designed for both enterprise and individual users, it offers an intuitive user interface and minimal configuration, enabling seamless and efficient web resource extraction. As an open-source solution, [**GreenFinger**](https://github.com/paganini2008/greenfinger) provides a powerful yet user-friendly approach to large-scale web crawling and data acquisition.
## 🌟Features:
------------------------------
1. Seamless Spring Boot Integration
Natively integrates with Spring Boot, ensuring effortless configuration, deployment, and maintenance.
2. Scalable, High-Throughput Distributed Crawling
Architected for distributed environments, enabling seamless horizontal scaling to handle massive workloads efficiently.
3. Optimized Network Communication with Netty
Leverages Netty for ultra-low-latency networking, with additional support for Mina and Grizzly for flexible communication strategies.
4. Enterprise-Grade URL Deduplication
Implements billion-scale deduplication using Bloom Filter and RocksDB, ensuring optimal storage efficiency and crawl accuracy.
5. Granular URL Customization
Supports fine-grained control over URL selection, allowing users to define initial URLs, retain only relevant URLs, and exclude undesired links dynamically.
6. Advanced Fault Tolerance & Crawler Constraints
Incorporates intelligent retry mechanisms, configurable timeouts, target URL limits, and maximum crawl depth enforcement for robust error handling.
7. Multi-Engine Web Content Extraction
Integrates Playwright, Selenium, and HtmlUnit to capture and process dynamic web content efficiently.
8. Strict Adherence to Robots.txt
Fully complies with the Robots Exclusion Protocol, ensuring ethical and responsible web crawling.
9. Comprehensive Developer API
Exposes a rich set of APIs, enabling seamless customization, extension, and integration into diverse ecosystems.
10. Automated Authentication Handling
Supports intelligent login and logout workflows, facilitating seamless authentication across secured web portals.
11. Version-Controlled Web Document Management
Assigns unique versioning to crawled documents, enabling multi-version indexing for enhanced content tracking and retrieval.
12. Intuitive Angular-Based Web Interface
Provides a modern, interactive dashboard built with Angular, empowering users with real-time monitoring, configuration, and management capabilities.
## 🚀 Technology Stack
-----------------------------------------
| Technology | Version Requirement | Description |
|---------------|----------------|-------------|
| ☕ **JDK** | 17 or later | Core Java runtime environment |
| 🌱 **Spring Boot** | 2.7.18 | Backend framework for microservices and rapid development |
| ⚡ **Netty** | 4.x | High-performance asynchronous networking framework |
| 🔥 **Redis** | 7.x or later | In-memory data store for caching and message queuing |
| 🐘 **PostgreSQL** | 9.x or later | High-performance, open-source relational database |
| 🔍 **ElasticSearch** | 7.16.2 or later | Distributed search and analytics engine |
| 🕷 **Selenium** | 4.x | Web automation framework for headless and UI-based scraping |
| 🎭 **Playwright** | 1.48 | Modern browser automation tool for scraping and testing |
| 📄 **HtmlUnit** | 2.6 | Lightweight headless browser for quick HTML processing |
| 🌐 **Angular** | 19.x | Frontend framework for building interactive web applications |
| 🎨 **Angular Material** | Latest | UI component library for modern, responsive designs |
## Install:
-----------------------------
* Git Repository:
https://github.com/paganini2008/greenfinger.git
* Wiki:
https://paganini2008.github.io/greenfinger/
* Directory Structure:
``` shell
📂 greenfinger
├── 📂 greenfinger-ui
│ ├── 📜 pom.xml
│ ├── 📂 src
│ │ ├── 📂 config # Configuration files
│ │ ├── 📂 db # Database-related scripts and configurations
│ │ └── ...
├── 📂 greenfinger-spring-boot-starter
│ ├── 📜 pom.xml
│ ├── 📂 src
│ └── ...
├── 📜 LICENSE
├── 📜 pom.xml
└── 📜 README.md
```
### Steps:
1. Modify configuration:
``` yaml
spring:
redis:
database: 0
host: 127.0.0.1
port: 6379
password: 123456
elasticsearch:
rest:
uris: http://127.0.0.1:9200
connection-timeout: 10000
read-timeout: 60000
datasource:
driver-class-name: org.postgresql.Driver
url: jdbc:postgresql://localhost:5432/test?characterEncoding=utf8&allowMultiQueries=true&useSSL=false&stringtype=unspecified
username: admin
password: 123456
# Binding host name is preferred
doodler:
transmitter:
nio:
server:
bindHostName: 127.0.0.1
# Internal Work ThreadPool Threads
greenfinger:
workThreads: 1000
```
2. Create database and import table scripts
**execute db/crawler.sql**
3. mvn clean install
4. run jar with java --add-opens=java.base/java.lang=ALL-UNNAMED -jar greenfinger-ui-service-1.0.0-SNAPSHOT.jar
2. Open the Web UI
http://localhost:6120/ui/index.html

## Greenfinger UI Guide:
-------------------------
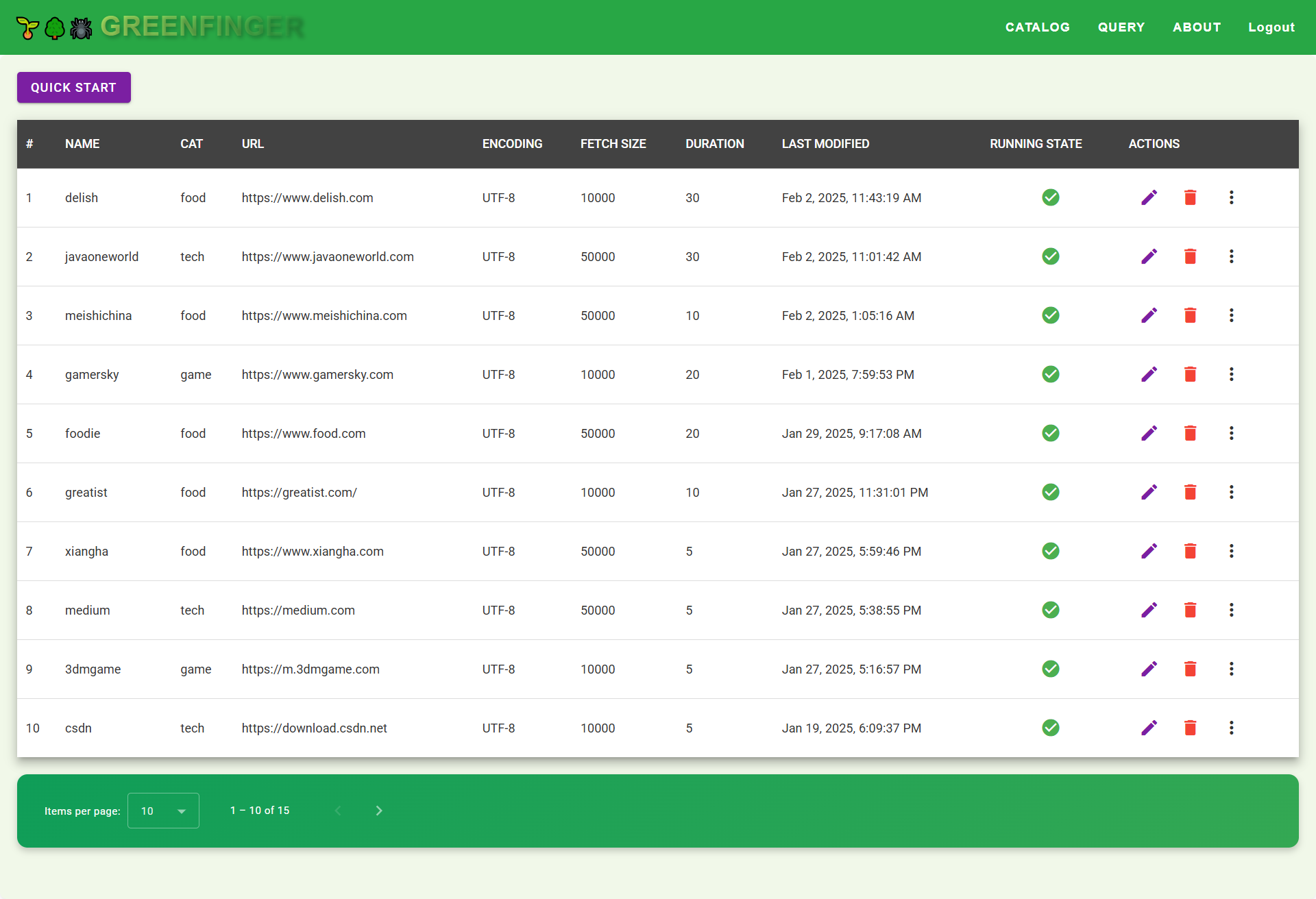
#### Catalog Management
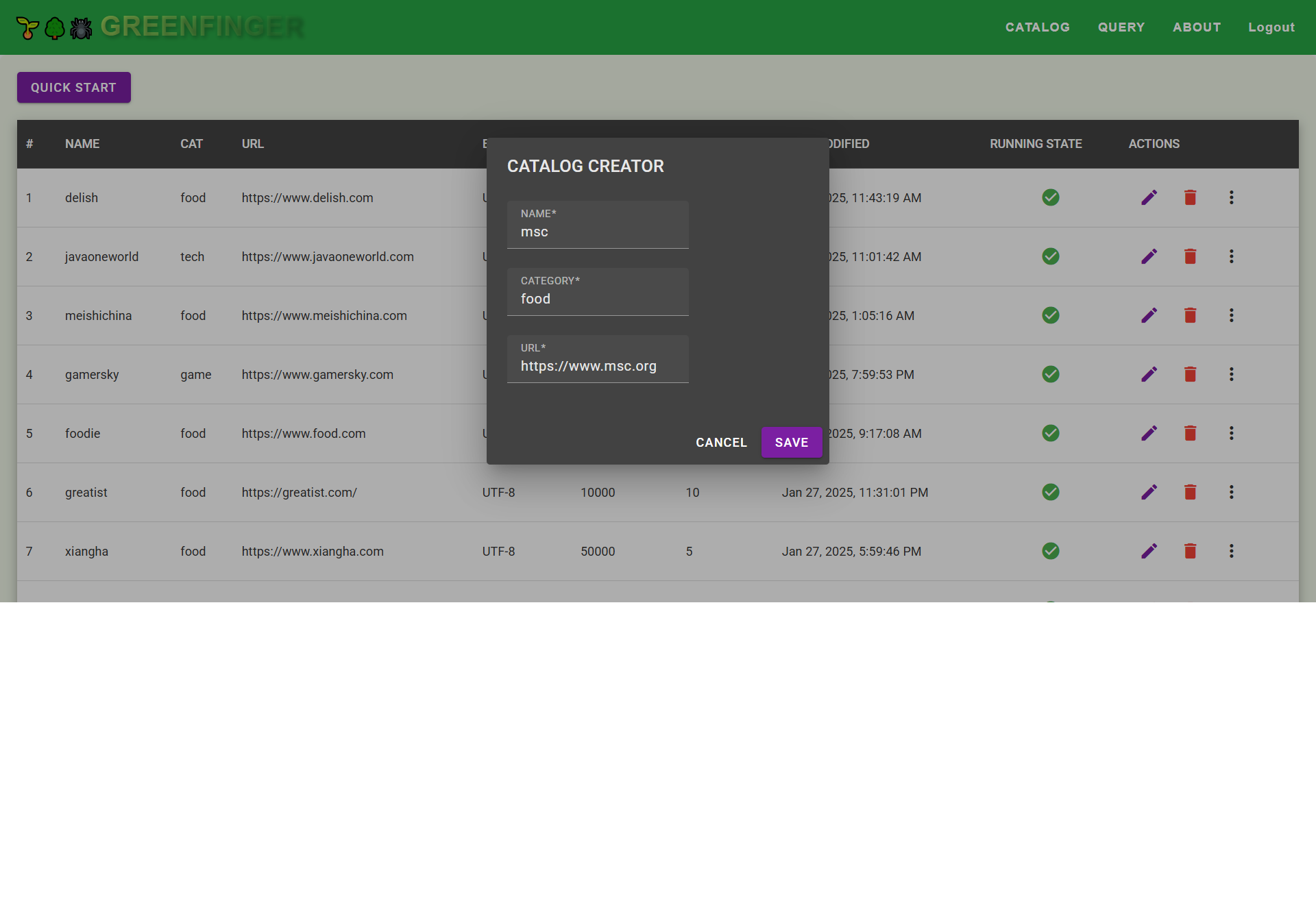
#### Create a catalog
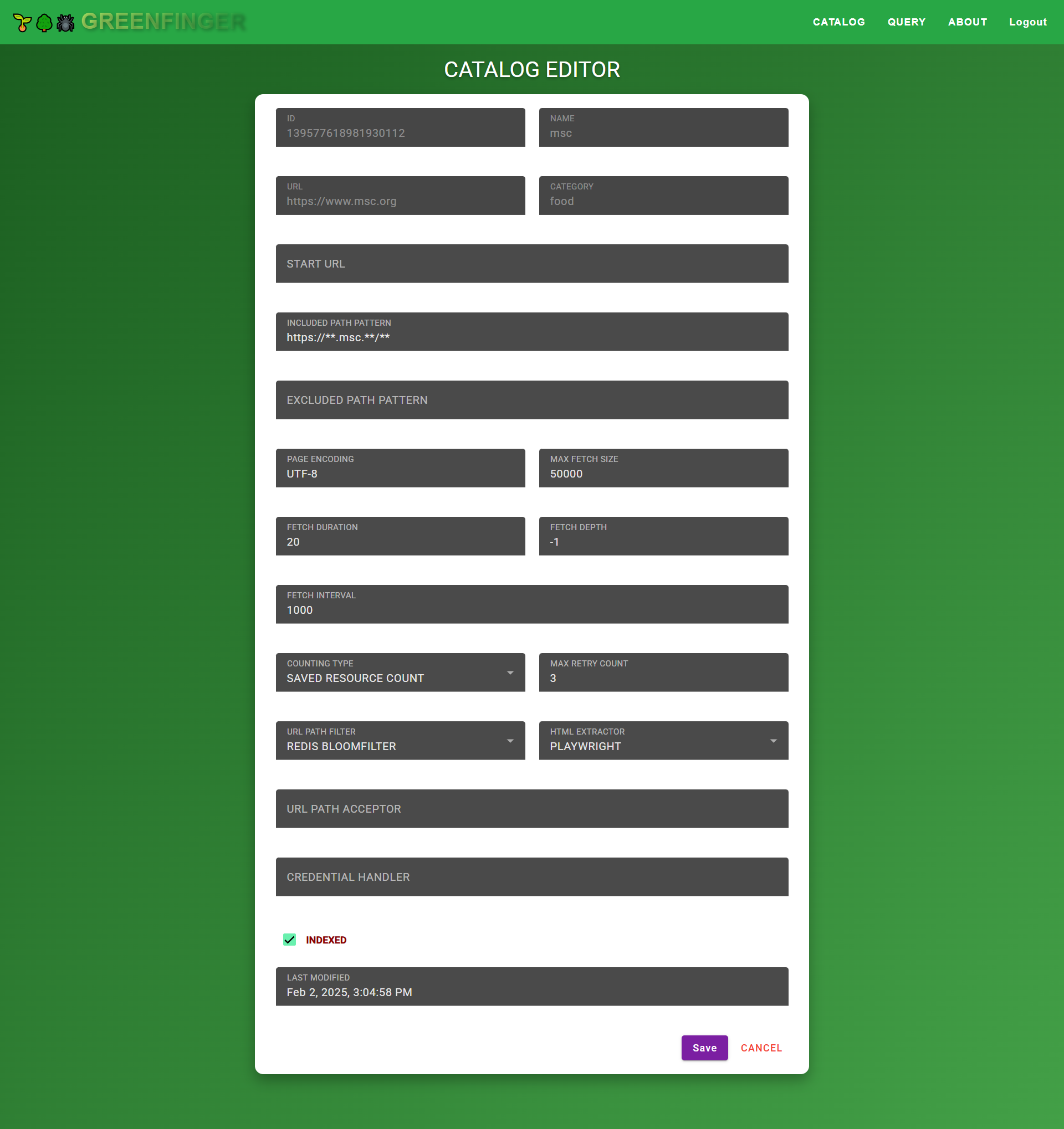
#### Edit a catalog
#### Run web crawler
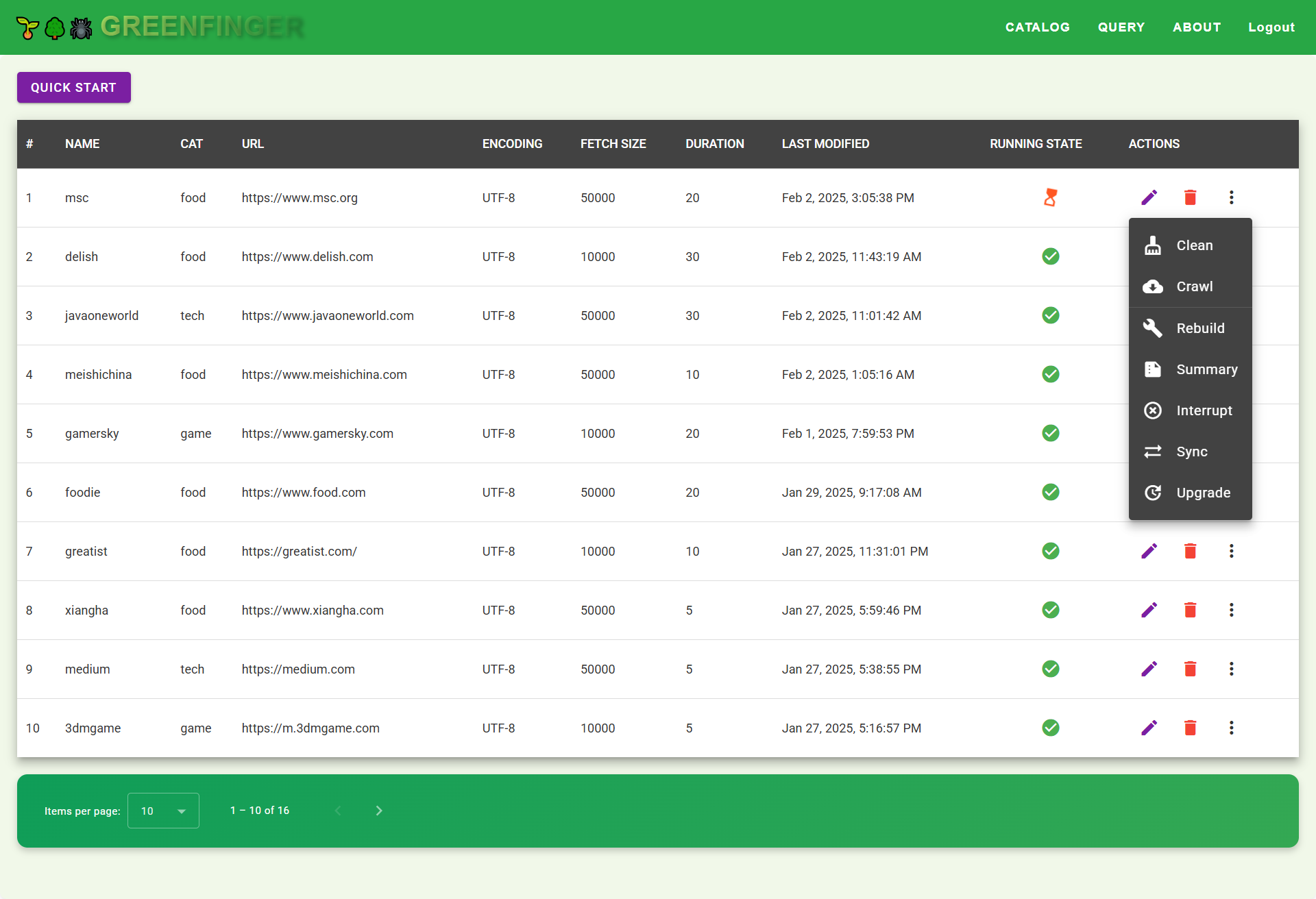
#### Monitor
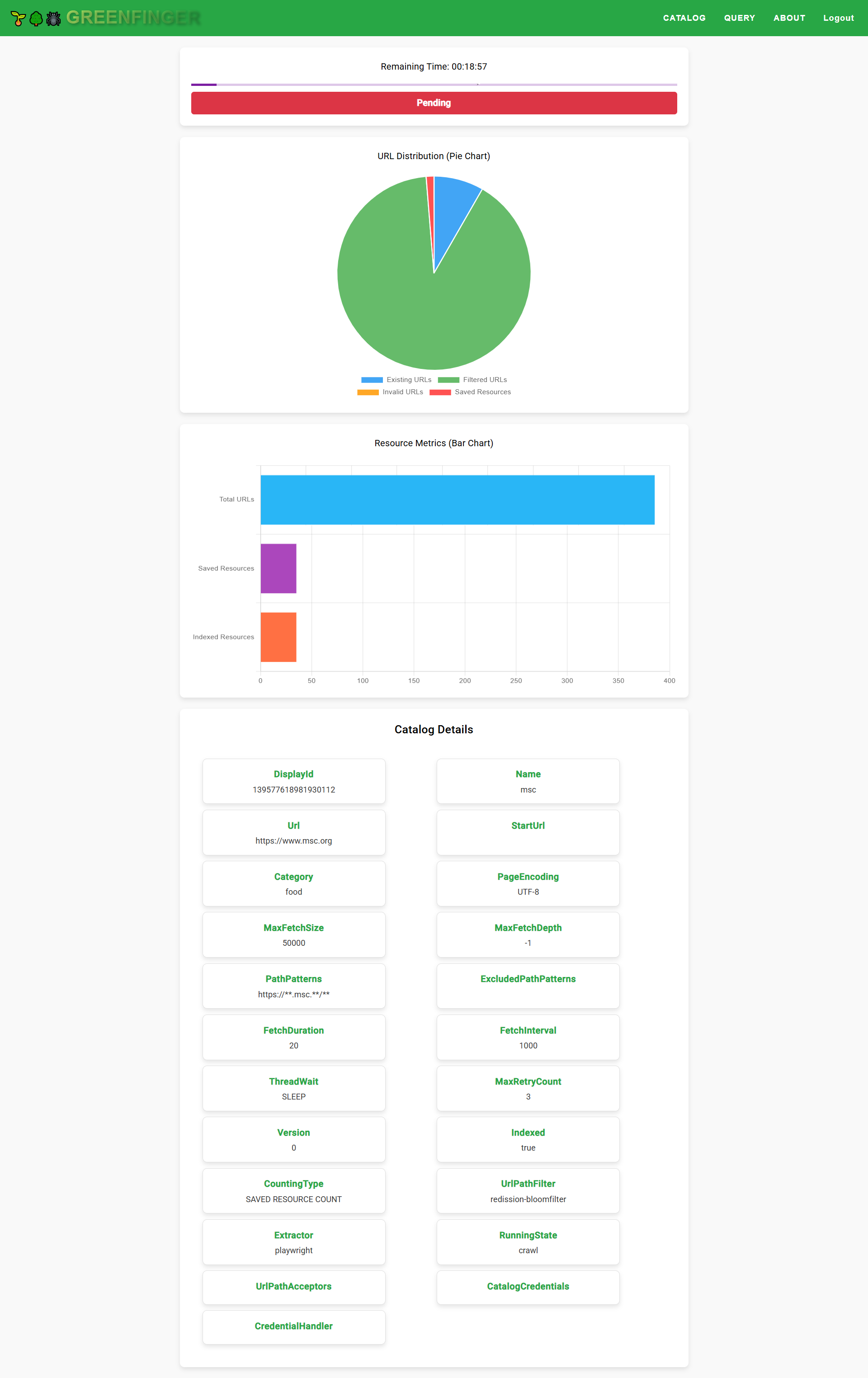
#### Query
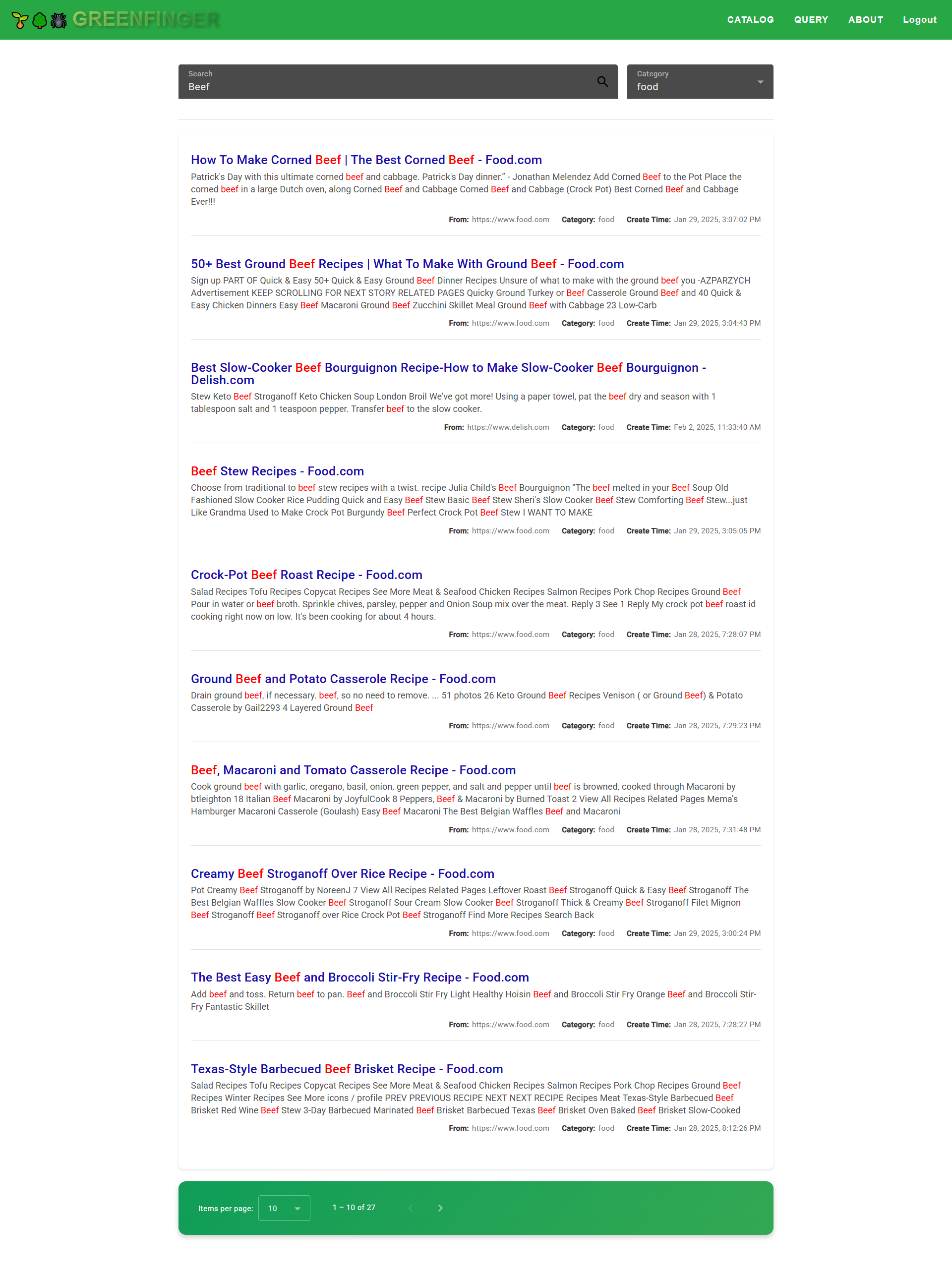
## Customize your application
### Application Integration
-------------------------
**Step1**: add dependency in your pom.xml:
``` xml
com.github.paganini2008
greenfinger-spring-boot-starter
1.0.0-SNAPSHOT
```
**Step2**: add @EnableGreenFingerServer on the main:
``` java
@EnableAsync(proxyTargetClass = true)
@EnableScheduling
@EnableGreenfingerServer
@SpringBootApplication
public class GreenFingerServerConsoleMain {
public static void main(String[] args) {
SpringApplication.run(GreenFingerServerConsoleMain.class, args);
}
}
```
**Step3**: Run it
## Documentation
For detailed setup instructions, API references, and advanced configuration, visit the [Official Documentation](https://github.com/paganini2008/greenfinger/wiki/QuickStart).
---
## Contributing
Contributions are welcome! Refer to the [Contributing Guide](CONTRIBUTING.md) for more information.
---
## License
Greenfinger is licensed under the Apache License. See the [LICENSE](LICENSE) file for more details.
---