https://github.com/philmod/url-shortener
Webserver to shorten url and redirect to pages - using DynamoDB
https://github.com/philmod/url-shortener
Last synced: about 1 year ago
JSON representation
Webserver to shorten url and redirect to pages - using DynamoDB
- Host: GitHub
- URL: https://github.com/philmod/url-shortener
- Owner: Philmod
- Created: 2016-04-06T19:16:18.000Z (about 10 years ago)
- Default Branch: master
- Last Pushed: 2016-04-20T19:51:08.000Z (about 10 years ago)
- Last Synced: 2025-02-08T06:29:46.980Z (over 1 year ago)
- Language: JavaScript
- Homepage:
- Size: 58.6 KB
- Stars: 1
- Watchers: 3
- Forks: 1
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# url-shortener
Webserver to shorten url and redirect pages

## How does that work?
### Overview of the service
Go to the root page and enter an url to shorten:
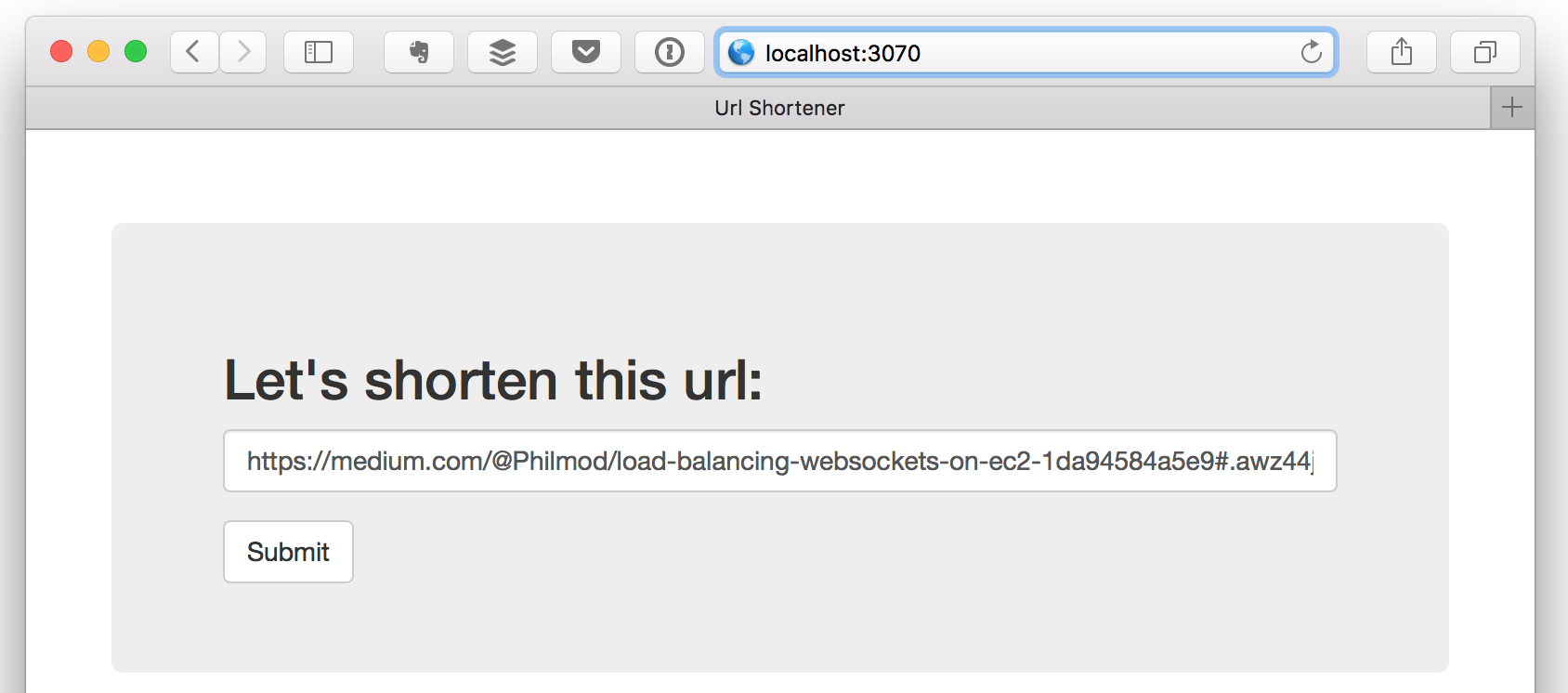
After clicking on Submit, you get the shortened url:

This shortened url can now be used to be redirected to the full page.
After logging-in (`admin` / `password`),
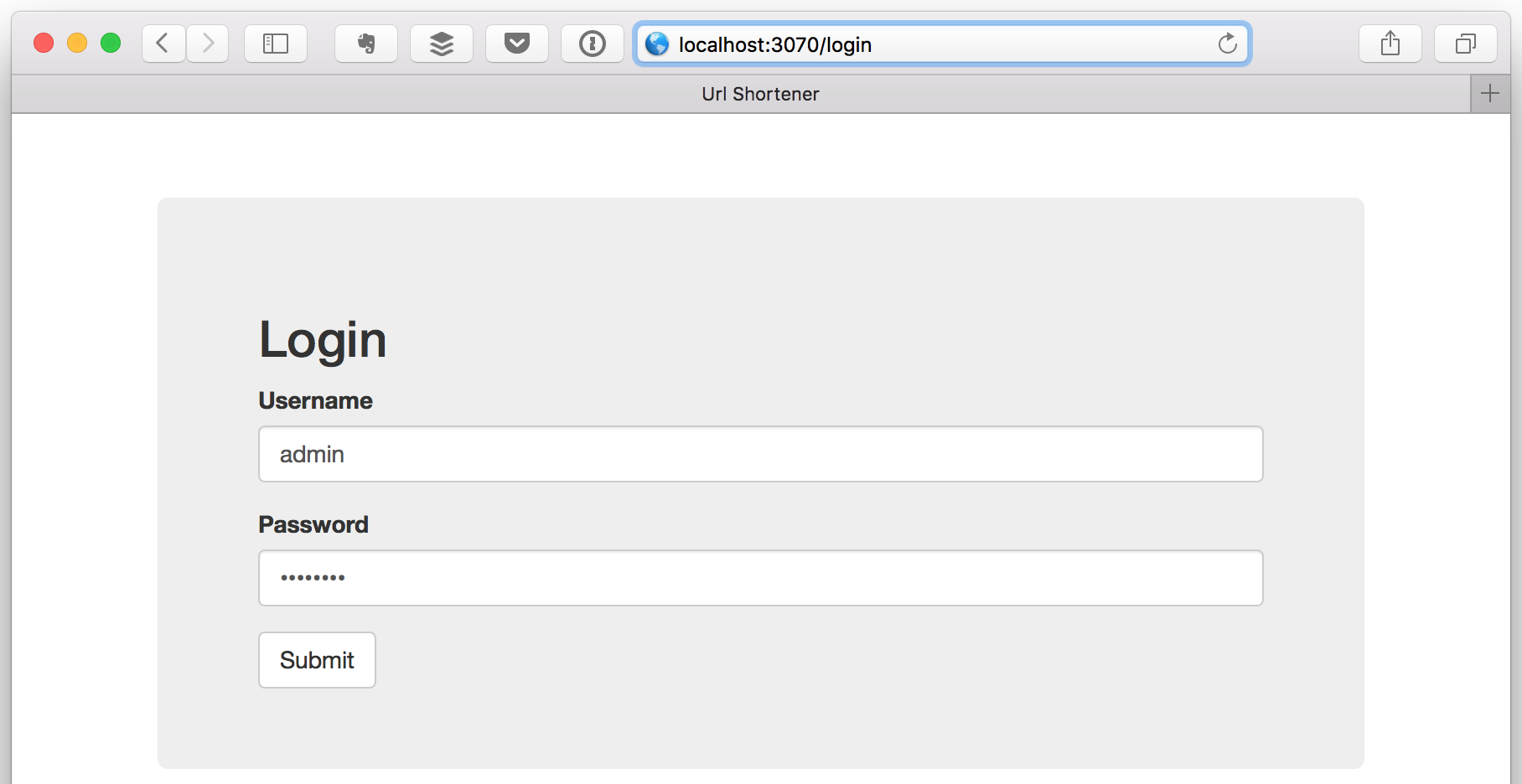
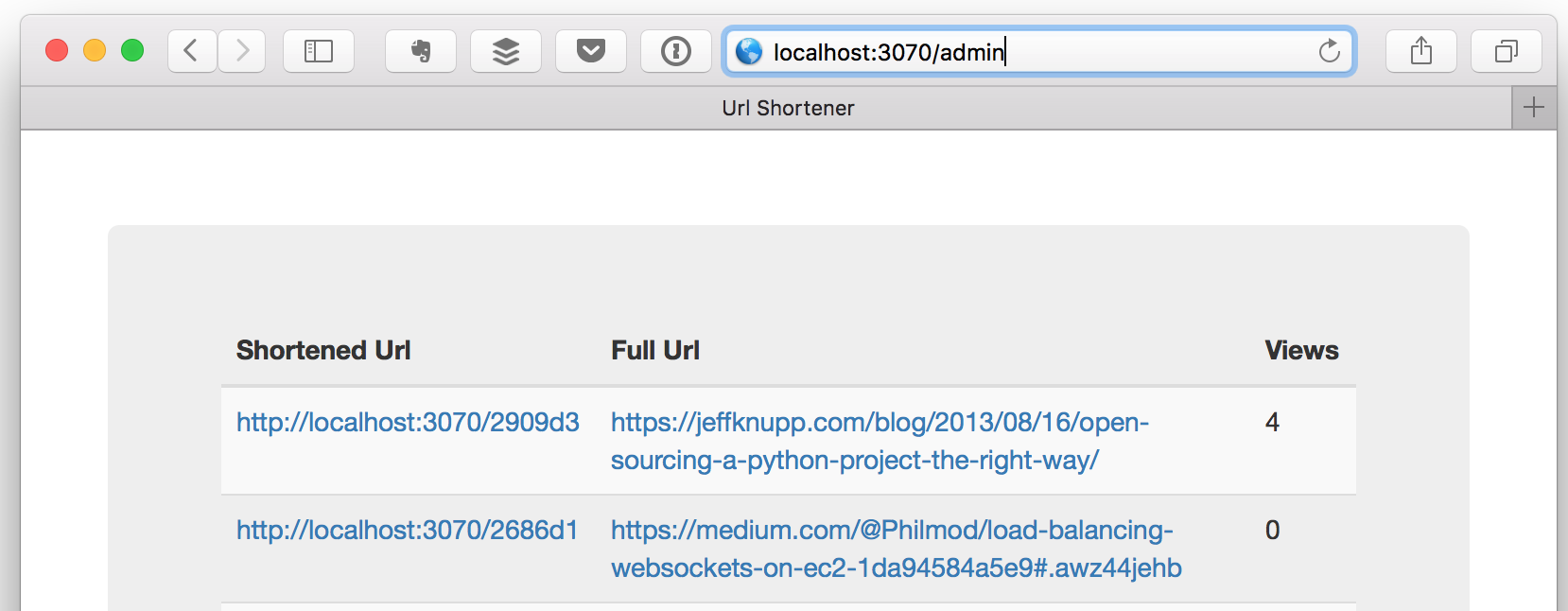
an admin page is accessible. It shows all the urls that have been shortened, and the number of views:
There is also an **API** to:
- shorten an url: `POST /api/urls`
- retrieve information about a shortened url: `GET /api/urls/:id`
- retrieve information about all urls: `GET /api/urls` (need to pass credentials)
### Behind the scenes
The web service is built on top of **Node.js** and Express.js.
I chose to use **DynamoDB** as the persistent database. This is my first time using it, but its key-value solution sounded very appropriate for this use-case.
When a new url is submitted to the service, it creates randomly a unique `id` of a fixed size, check its uniqueness in the database, then creates a new entry in the table. So far, the `id` has a size of 6 characters, see Todo for improvement.
The **sessions**, used for keeping track of logged-in users, are local to the server/thread. That means that a user has to re-login after a server restart. Worse, that would be a big issue if we put this service behind a load balancer, with many instances. In that case, we would need to use Redis as a common store for the sessions.
### Structure of the directories
The routes can be found in `./app/routes.js`.
The configurations for various environments can be found in `./config/`.
The controllers, models, views and others small libraries can be found under `./app/`.
The tests are under `./test/`.
## Install
### Docker
- Install docker
- Add the docker local ip to /etc/hosts:
```
echo "$(docker-machine ip default) localhost.url.canary.is" | sudo tee -a /etc/hosts
```
- Run:
```
docker-compose up
```
### Manual Install
- Install dynamodb locally
```
brew install dynamodb-local
```
- Install Redis locally
```
brew install redis
```
- Install Node.js and NPM, by downloading and installing from https://nodejs.org/en/
- Install Node.js modules for this project
```
npm install
```
## Tests
The tests are using a local dynamodb table for now in order to make sure everything is working perfectly with the database.
It should be better and the tests would run faster by stubbing the database's client.
To run them:
```
npm test
```
### Circle CI
Circle CI is configured and will run all the tests whenever a commit is pushed to this repository.
It could be used to deploy automatically a staging version for testing.
## Run server
```
npm run dev
```
And visit `http://localhost:3070`
## Database's content
To scan the content of the local database:
```
npm run dynamo:getAllLocalData
```
Or just go to the admin page.
## Done
+ Webserver which responds to a status page [GET /status]
+ Web page with a form to enter a full url [GET /]
+ Route to submit a new url [POST /url]
+ Route to redirect from shorten url to full url [GET /:id]
+ Admin page with the list of all shortened [GET /admin]
+ Change the local memory into a persistent one (DynamoDB)
+ Local cache in front of the database
+ API: shorten an url [POST /api/urls]
+ API: get information about an url [POST /api/urls/:id]
+ API: get all urls information [GET /api/urls]
+ Circle CI
+ Make the admin session persistent and available across many servers/thread (Redis)
+ API: restrict the getAll urls with the username/password
+ Docker
+ Deploy a live demo on AWS
## Debates
### Unique short url by full url
If an known url is submitted, the existing id is returned.
In the case of the statistics (number of views) are available for the users, that's an issue because 2 people can share the same statistics for a same url.
Another open question would be : "What about `http://` vs `https://`"? Do they have a different short url?
### More 100.000 users shortening 5urls/day!
#### Server load
Let's assume this app is hosted on EC2. The safest setup would be to have a minimum of 2 instances, behind an ELB. We could set up an Auto Scaling Group that would creates more instances whenever the existing ones overpass a CPU threshold. It could also scale down during lower traffic time.
If there are so many new urls created every day, we can assume we are going to have a way bigger traffic in redirection. For this problem, we need a better caching system than the one I implemented within the app.
There are many options, here are the ones I'm familiar with:
- Cloudfront: as a AWS service, you pay for what you use
- Varnish: there is more devops work to keep these up and running
The problem with a caching outside of the application is that we loose our ability to keep track of the statistics per url as we do now.
#### Database
DynamoDB should be a perfect candidate, as it provides a linear scaling.
But we would need to adjust the Provisioned Throughput (read/write). The read one should be amortized by the caching system, but the write needs to be increased.
It's also very important that all the partitions get equally populated, with a good partition key. This shouldn't be an issue as it's a random hash right now.
If we decide to avoid the external caching in order to keep the number of views per url, we should postpone the update of views number in the database. A good solution would be to gather these updates in Redis, and a worker would randomly get the new changes (a whole bunch of new views per url) and update the database.
#### Id
The `id` is made of 6 characters, meaning there are 2.176.782.336 combinations. At this rate of 500.000 urls a day, that gives us 11 years before all the `id` are used. When that happens, we could increase to 7 characters, giving us ... 430 years.
The problem is more the way we randomly choose a new id, check in the database if unique, if not it tries again. When more and more ids are used, there are more and more chance of collision and so the function will take more time to get an unused one.
A bloom filter would be probably good to faster this process.
## Todo
- Logout
- Paginate the admin page, not to show all the urls
- If the service is very popular, and there is no more free unique id, increase the number of characters required for an id
- Right now, a new id is created randomly; it will take more and more time when the free space will reduce
- Use a Bloom Filter to check for the existence of a given id
- Buffer the incrementView calls (Redis), and so update one entry once for many views
- Stub the database's client for the tests
- Deal with DynamoDB's throughput limits
- Add a expire option
- Avoid loops: short url of short url