Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/pmbaumgartner/syntax-speaker-prediction
The tastiest machine learning project. Can we predict who is speaking for how long during an episode of the syntax.fm podcast?
https://github.com/pmbaumgartner/syntax-speaker-prediction
Last synced: 3 months ago
JSON representation
The tastiest machine learning project. Can we predict who is speaking for how long during an episode of the syntax.fm podcast?
- Host: GitHub
- URL: https://github.com/pmbaumgartner/syntax-speaker-prediction
- Owner: pmbaumgartner
- Created: 2018-12-17T12:17:23.000Z (almost 6 years ago)
- Default Branch: master
- Last Pushed: 2018-12-17T12:42:32.000Z (almost 6 years ago)
- Last Synced: 2024-07-18T17:53:47.592Z (4 months ago)
- Language: Jupyter Notebook
- Homepage:
- Size: 11 MB
- Stars: 36
- Watchers: 3
- Forks: 3
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Syntax Speaker Prediction
This repository contains notebooks used to train a model to predict the speaker (Scott or Wes) in one second cilps of their podcast, syntax.fm. There are accompanying files for using Prodigy to label the data required to build the model. There is a brief description of the purpose of each notebook as the first cell.
## The Results
**Total Podcast Time**: 3 days, 15 hours, 56 minutes, 39 seconds
**Wes**: 2 days, 1 hours, 51 minutes, 11 seconds
**Scott**: 1 days, 11 hours, 51 minutes, 45 seconds
**Non-speaking time (crosstalk, laughing, intros)**: 0 days, 2 hours, 13 minutes, 43 seconds
## Cumulative Speaking Time
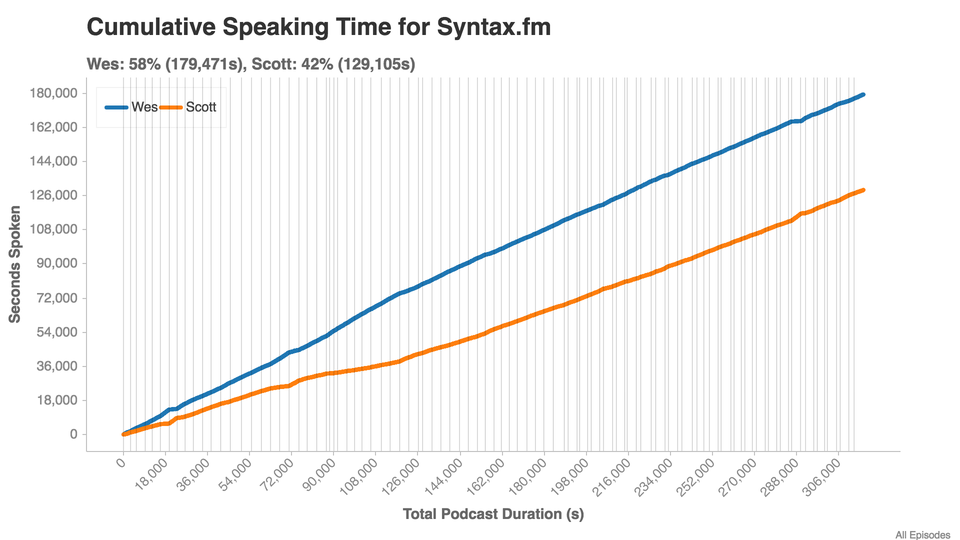
Each vertical line is the start of a new episode.
##
Helpful tools:
- [Prodigy](https://prodi.gy/) for data labeling
- [Pydub](http://pydub.com/) for slicing audio
- [Librosa](https://librosa.github.io/librosa/) for audio analysis
- [pandas](https://pandas.pydata.org/) for data manipulation
- [scikit-learn](https://scikit-learn.org/stable/index.html) for machine learning
- [chartify](https://github.com/spotify/chartify/) for plots