https://github.com/pmhalvor/whale-speech
A pipeline to map whale sightings to hydrophone audio
https://github.com/pmhalvor/whale-speech
beam bigquery gcs mle model-as-a-service python tensorflow2
Last synced: 4 months ago
JSON representation
A pipeline to map whale sightings to hydrophone audio
- Host: GitHub
- URL: https://github.com/pmhalvor/whale-speech
- Owner: pmhalvor
- License: gpl-3.0
- Created: 2024-09-12T19:10:54.000Z (almost 2 years ago)
- Default Branch: main
- Last Pushed: 2025-04-22T11:18:04.000Z (about 1 year ago)
- Last Synced: 2025-09-09T00:34:38.293Z (9 months ago)
- Topics: beam, bigquery, gcs, mle, model-as-a-service, python, tensorflow2
- Language: Python
- Homepage:
- Size: 16.3 MB
- Stars: 1
- Watchers: 1
- Forks: 0
- Open Issues: 9
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# 📣🐋 Whale Speech
A pipeline to map whale encounters to hydrophone audio.
Derived from PacificSoundDetectHumpbackSong, though not directly affiliated with MBARI, NOAA, or HappyWhale.
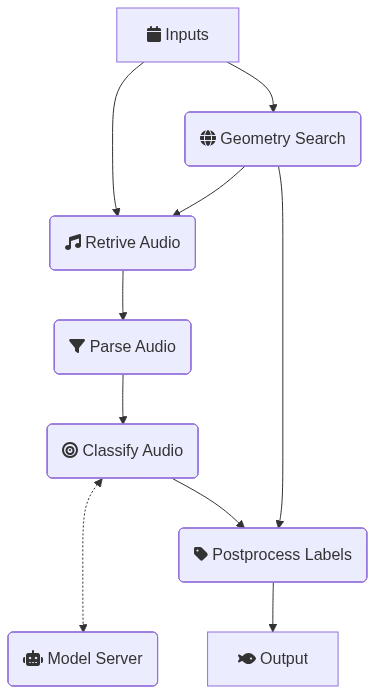
## Pipeline description
Stages:
1. **Input**: When (and where*) to look for whale encounters on [HappyWhale](https://happywhale.com/).
2. **Geometry Search**: Query [open-oceans/happywhale](https://github.com/open-oceans/happywhale) to find potential whale encounters.
→ Expected outputs: encounter ids, start and end times, and longitude and latitude.
3. **Retrive Audio**: Download audio from MBARI's [Pacific Ocean Sound Recordings](https://registry.opendata.aws/pacific-sound/) around the time of the encounter.
→ Expected outputs: audio array, start and end times, and encounter ids.
4. **Parse Audio**: Break audio into non-overlaping segments with flagged frequency detections.
→ Expected outputs: cut audio array, detection intervals, and encounter ids.
5. **Classify Audio**: Use a NOAA and Google's [humpback_whale model](https://tfhub.dev/google/humpback_whale/1) to classify the flagged segments.
→ Expected outputs: resampled audio, classification score array, and encounter ids.
6. **Postprocess Labels**: Build clip-intervals for each encounter for playback snippets.
→ Expected outputs: encounter ids, cut/resampled audio array, and aggregated classification score.
7. **Output**: Map the whale encounter ids to the playback snippets.
[](https://mermaid.live/edit#pako:eNpVkttOwkAQhl9lMleaFIJFTo0x4SBIItGoV1ouhnZKm2y7ZA9oJby7S1uJzNX-s98cMweMZMwYYCLkV5SSMvA-CwtwNv5MKEioFZHgIiYFy2JnjV5Dq3UPk6v6cyvkhmHBMmejSnhjUlF63SSoyGlD5lZnEbw6LNszjG2cyYab1FwtppV4aIKSTBhW8EJKX8Y8VNi8wTZWCM0lw1SQ1llSXrBzuGu3Hb1saCU30sDKzS1cw2rP6gyeki4azNAWXqQ2OyUj1hqeaMNCN-iiQh8__9rUKTxb4_az_j_TAk4KPcxZ5ZTFbs-HkydEk3LOIQbuGXNCVpgQw-LoULJGvpVFhIFRlj1U0m5TdFXchB7aXUyGZxltFeVn746KDykvNAYH_Mag2_HbN0P_ZtjvjUa3frff9bDEoHP08KeK6LRHtQ38nt8b3A4HHnKcGalW9WFU93H8BWH3qDQ)
*Currently only support encounters around the Monterey Bay Hydrophone (MARS).
## Getting started
### Install
Create a virtual environment and install the required packages.
We'll use conda for this, but you can use any package manager you prefer.
Since we're developing on an M1 machine, we'll need to specify the `CONDA_SUBDIR` to `osx-arm64`.
This step should be adapted based on the virtual environment you're using.
#### M1:
```bash
CONDA_SUBDIR=osx-arm64 conda create -n whale-speech python=3.11
conda activate whale-speech
pip install -r requirements.txt
```
#### Other:
```bash
conda create -n whale-speech python=3.11
conda activate whale-speech
pip install -r requirements.txt
```
### Google Cloud SDK
To run the pipeline on Google Cloud Dataflow, you'll need to install the Google Cloud SDK.
You can find the installation instructions [here](https://cloud.google.com/sdk/docs/install).
Make sure you authentication your using and initialize the project you are using.
```bash
gcloud auth login
gcloud init
```
For newly created projects, each of the services used will need to be enabled.
This can be easily done in the console, or via the command line.
For example:
```bash
gcloud services enable bigquery.googleapis.com
gcloud services enable dataflow.googleapis.com
gcloud services enable storage-api.googleapis.com
gcloud services enable run.googleapis.com
```
### Run locally
To run the pipeline and model server locally, you can use the `make` target `local-run`.
```bash
make local-run
```
This target starts by killing any previous model servers that might be running (needed for when a pipeline fails, without tearing down the server, causing the previous call to hang).
Then it starts the model server in the background and runs the pipeline.
### Build and push the model server
To build and push the model server to your model registry (stored as an environment variable), you can use the following `make` target.
```bash
make build-push-model-server
```
This target builds the model server image and pushes it to the registry specified in the `env.sh` file.
The tag is a combination of the version set in the makefile and the last git commit hash.
This helps keep track of what is included in the image, and allows for easy rollback if needed.
The target fails if there are any uncommited changes in the git repository.
The `latest` tag is only added to images deployed via GHA.
### Run pipeline with Dataflow
To run the pipeline on Google Cloud Dataflow, you can use the following `make` target.
```bash
make run-dataflow
```
Logging in the terminal will tell you the status of the pipeline, and you can follow the progress in the [Dataflow console](https://console.cloud.google.com/dataflow/jobs).
In addition to providing the inference url and filesystem to store outputs on, the definition of the above target also provides an example on how a user can pass additional arguments to and request different resources for the pipeline run.
**Pipeline specific parameters**
You can configure all the paramters set in the config files directly when running the pipeline.
The most important here is probably the start and end time for the initial search.
```bash
--start "2024-07-11" \
--end "2024-07-11" \
--offset 0 \
--margin 1800 \
--batch_duration 60
```
Note that any parameters with the same name under different sections will only be updated if its the last section in the list.
Also, since these argparse-parameters are added automatically, behavior of boolean flags might be unexpected (always true is added).
**Compute resources**
The default compute resources are quite small and slow. To speed things up, you can request more workers and a larger machine type. For more on Dataflow resources, check out [the docs](https://cloud.google.com/dataflow/docs/reference/pipeline-options#worker-level_options).
```
--worker_machine_type=n1-highmem-8 \
--disk_size_gb=100 \
--num_workers=8 \
--max_num_workers=8 \
```
Note, you may need to configure IAM permissions to allow Dataflow Runners to access images in your Artifact Registry. Read more about that [here](https://cloud.google.com/dataflow/docs/concepts/security-and-permissions).
## References
- [HappyWhale](https://happywhale.com/)
- [open-oceans/happywhale](https://github.com/open-oceans/happywhale)
- [NOAA and Google's humpback_whale model](https://tfhub.dev/google/humpback_whale/1)
- [Google Cloud Console](https://console.cloud.google.com/)
- [Monterey Bay Hydrophone MARS](https://www.mbari.org/technology/monterey-accelerated-research-system-mars/)
- [MBARI's Pacific Ocean Sound Recordings](https://registry.opendata.aws/pacific-sound/)
- J. Ryan et al., "New Passive Acoustic Monitoring in Monterey Bay National Marine Sanctuary," OCEANS 2016 MTS/IEEE Monterey, Monterey, CA, USA, 2016, pp. 1-8, doi: [10.1109/OCEANS.2016.7761363](https://ieeexplore.ieee.org/document/7761363).