https://github.com/polomarcus/scala-kafka-client-examples
Producer and Consumer APIs examples in Scala
https://github.com/polomarcus/scala-kafka-client-examples
Last synced: 3 months ago
JSON representation
Producer and Consumer APIs examples in Scala
- Host: GitHub
- URL: https://github.com/polomarcus/scala-kafka-client-examples
- Owner: polomarcus
- License: gpl-3.0
- Created: 2022-09-13T15:31:51.000Z (over 2 years ago)
- Default Branch: main
- Last Pushed: 2022-09-13T15:38:57.000Z (over 2 years ago)
- Last Synced: 2025-01-23T03:31:09.931Z (5 months ago)
- Language: Scala
- Size: 19.5 KB
- Stars: 0
- Watchers: 3
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
## Scala [Apache Kafka](https://kafka.apache.org/) Producer and Consumer examples
Using Scala, there are 4 examples of the Producer and Consumer APIs:
* Avro Producer using the Schema Registry : com.github.polomarcus.main.MainKafkaAvroProducer
* Avro Consumer using the Schema Registry : com.github.polomarcus.main.MainKafkaAvroConsumer
* String Producer : com.github.polomarcus.main.MainKafkaProducer
* String Consumer : com.github.polomarcus.main.MainKafkaConsumer
### Why using Kafka ?

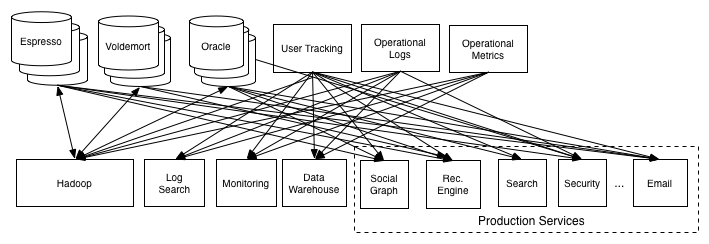
## Tools
* docker and compose (using the [Conduktor's docker-compose.yml](https://github.com/conduktor/kafka-stack-docker-compose))
* `sbt` if not using docker to run the scala app
* Optional : [Conduktor](https://www.conduktor.io/download/) (Kafka User Interface)
## Start
Start multiples kakfa servers (called brokers) using the docker compose recipe `docker-compose.yml` :
```bash
docker-compose -f docker-compose.yml up --detach
```
### SBT
```bash
sbt "runMain com.github.polomarcus.main.MainKafkaProducer"
# OR
sbt run
# and type "2" to run "com.github.polomarcus.main.MainKafkaProducer"
### Docker
```bash
docker-compose run my-scala-kafka-app bash
> sbt
> run
```
#### Some questions about producer and consumer
##### Question 1
Your ops team tells your app is slow and the CPU is not used much, they were hoping to help you but they are not Kafka experts.
* [ ] Look at the method `producer.flush()`, can you improve the speed of the program ?
* [ ] What about batching the messages ? [Help](https://www.conduktor.io/kafka/kafka-producer-batching)
##### Question 2
Your friendly ops team warns you about kafka disks starting to be full. What can you do ?
Tips :
* [ ] What about [messages compression](https://kafka.apache.org/documentation/#producerconfigs_compression.type) ? Can you implement it ? [You heard that snappy compression is great.](https://www.conduktor.io/kafka/producer-default-partitioner-and-sticky-partitioner)
* [ ] What about [messages lifetime](https://kafka.apache.org/documentation/#topicconfigs_delete.retention.ms) on your kafka brokers ? Can you change your topic config ?
##### Question 3
After a while and a lot of deployments and autoscaling (adding and removing due to traffic spikes), on your data quality dashboard you are seeing some messages are duplicates or missing. What can you do ?
* [ ] What are ["acks"](https://kafka.apache.org/documentation/#producerconfigs_acks) ? when to use acks=0 ? when to use acks=all?
* [ ] Can [idempotence](https://kafka.apache.org/documentation/#producerconfigs_enable.idempotence) help us ?
* [ ] what is ["min.insync.replicas"](https://kafka.apache.org/documentation/#brokerconfigs_min.insync.replicas) ?
#### About the Schema Registry
##### Intro
Look at :
* your docker-compose.yml, and the schema-registry service.
* Inside Conduktor, configure the connection with your schema-registry (http://localhost:8081)
##### Questions
* [ ] What are the benefits to use a Schema Registry for messages ? [Help](https://docs.confluent.io/platform/current/schema-registry/index.html)
* [ ] Where are stored schemas information ?
* [ ] What is serialization ? [Help](https://developer.confluent.io/learn-kafka/kafka-streams/serialization/#serialization)
* [ ] What serialization format are supported ? [Help](https://docs.confluent.io/platform/current/schema-registry/index.html#avro-json-and-protobuf-supported-formats-and-extensibility)
* [ ] Why is the Avro format so compact ? [Help](https://docs.confluent.io/platform/current/schema-registry/index.html#ak-serializers-and-deserializers-background)
* [ ] What are the best practices to run a Schema Registry in production ? [Help1](https://docs.confluent.io/platform/current/schema-registry/index.html#sr-high-availability-single-primary) and [Help2](https://docs.confluent.io/platform/current/schema-registry/installation/deployment.html#running-sr-in-production)
##### Useful links
* [How to create a custom serializer ?](https://developer.confluent.io/learn-kafka/kafka-streams/serialization/#custom-serdes)
* [Kafka Streams Data Types and Serialization](https://docs.confluent.io/platform/current/streams/developer-guide/datatypes.html#avro)
* [About schema evolution](https://docs.confluent.io/platform/current/schema-registry/avro.html#schema-evolution)
* https://sparkbyexamples.com/kafka/apache-kafka-consumer-producer-in-scala/
* https://www.confluent.io/fr-fr/blog/kafka-scala-tutorial-for-beginners/
* https://developer.confluent.io/learn-kafka/kafka-streams/get-started/
* [Hands-on Kafka Streams in Scala](https://softwaremill.com/hands-on-kafka-streams-in-scala/)
* [Scala, Avro Serde et Schema registry](https://univalence.io/blog/drafts/scala-avro-serde-et-schema-registry/)
* [Usage as a Kafka Serde (kafka lib for avro)](https://github.com/sksamuel/avro4s#usage-as-a-kafka-serde)
* [Datadog's Kafka dashboard overview](https://www.datadoghq.com/dashboards/kafka-dashboard/)