https://github.com/prantopodder98/dna-microarray-gene-expression-data-classification-using-svm-mlp-and-rf-with-feature-selection-met
Classified DNA microarray gene expression data used different classifiers on 22 datasets.
https://github.com/prantopodder98/dna-microarray-gene-expression-data-classification-using-svm-mlp-and-rf-with-feature-selection-met
Last synced: 3 months ago
JSON representation
Classified DNA microarray gene expression data used different classifiers on 22 datasets.
- Host: GitHub
- URL: https://github.com/prantopodder98/dna-microarray-gene-expression-data-classification-using-svm-mlp-and-rf-with-feature-selection-met
- Owner: PrantoPodder98
- Created: 2023-01-31T20:17:42.000Z (over 3 years ago)
- Default Branch: main
- Last Pushed: 2023-01-31T22:28:19.000Z (over 3 years ago)
- Last Synced: 2025-08-08T04:45:29.489Z (10 months ago)
- Language: Jupyter Notebook
- Homepage:
- Size: 15.2 MB
- Stars: 2
- Watchers: 1
- Forks: 2
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# DNA-Microarray-Gene-Expression-Data-Classification-Using-SVM-MLP-and-RF-with-Feature-Selection-Met
## Overview
A DNA microarray (also commonly known as DNA chip or biochip) is a collection of microscopic DNA spots attached to a solid surface. Scientists use DNA microarrays to measure the expression levels of large numbers of genes simultaneously or to genotype multiple regions of a genome.DNA microarray gene expression is being used to detect various forms of diseases.
In this problem GÜÇKIRAN et al. have classified DNA microarray gene expression data using different classifiers and came to an end with the best one.Using multiple microarray datasets, this paper compares two different methods for classification and feature selection.They used 22 datasets but they didn't combine the datasets here, these are used individually.
We used these 22 datasets and applied on different classification. In our study we found out that LightGBM accuracy is the best among the other classification.
## Contributors
- **Team Members:** [Pranto Podder](https://www.linkedin.com/in/pranto-podder/), [Moumy Kabir](https://www.linkedin.com/in/moumy-kabir-156a0a232/), [Aysha Siddika](https://www.linkedin.com/in/aysha-siddika-577ba5224/), [Tarin Nafisa](https://www.linkedin.com/in/tarin-nafisa-b174031a9/)
- **Course:** Pattern Recognition Project - B.Sc. in Computer Science and Engineering (CSE)
- **Project Duration:** Fall 2021 Trimester (Nov 2021 - Jan 2022)
- **Dataset:** [22 datasets](https://drive.google.com/drive/folders/1_fn0GqGQJAbpqHfLQVDrIeWWSJgIpLmZ?usp=sharing)
## Installing software and files
To do the project, we need to install some softwares and files. In this regard, we will be doing all the implementations in Python language on jupyter notebook. To install jupyter notebook and launch other application and files at first we have to download Anaconda which is free.
Link to Download Anaconda : https://www.anaconda.com/?modal=nucleus-commercial
Guideline for installing Anaconda : https://www.geeksforgeeks.org/how-to-install-anaconda-on-windows/
Once Anaconda is downloaded and installed successfully, we may proceed to download Jupyter notebook.
## Download and Install Jupyter Notebook
Link to download Jupyter using Anaconda : https://docs.anaconda.com/ae-notebooks/4.3.1/user-guide/basic-tasks/apps/jupyter/
More informations : https://mas-dse.github.io/startup/anaconda-windows-install/
Guideline to use Jupyter notebook : https://www.dataquest.io/blog/jupyter-notebook-tutorial/
## Using Google Colaboratory
For implementing the project with no configuration we can use Google Colaboratory as well.
## Installing Python libraries and packages
The required python libraries and packages are,
- pandas
- Numpy
- sklearn
- matplotlib
- seaborn
## Dataset Understanding
* Total 22 datasets. Each of them consists of small sample high dimensional DNA microarray input space, e.g- In borovecki(Instances=31, Features=22283, Classes=2. Each dataset is named by their author
* They used 22 datasets but they didn't combine the datasets here, these were used individually.
* Most of the datasets are for detecting cancer/healthy samples.
* Also, there are cancer/disease classification datasets.
* In addition to diseases, there are also 3 microarray datasets which are neither disease nor cancer, like aging and environmental effects on DNA.

## State of the Art
1. Feature Selection Methods
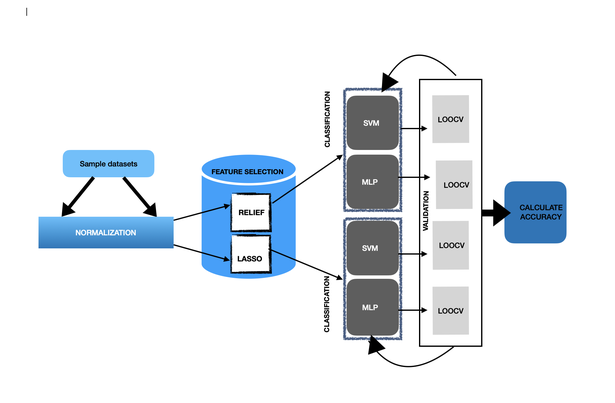
Here they have used Relief and LASSO for feature selection methods
* **RELIEF:**
This algorithm calculates feature value differences with nearest neighbor pairs.Later, these feature scores are used as important values for the system. High feature score means high importance.
* **LASSO:**
LASSO constructs a linear model and penalizes the regression coefficients with L1 distance. Most coefficients are reduced to zero and the remaining inputs are selected.
* Since individual gene counts in microarray data are too many, most informative genes should be selected and used.
* If we look at the dataset , then you can see that the feature count is so large. It is necessary to reduce the number of features and remove the unnecessary features.
* Feature selection is mandatory for these studies.
* For this selection, they have tried Relief and LASSO feature selection methods.
2. Classification Methods
After picking informative genes from microarray data, classification is performed with
* Support Vector Machines (SVM)
* Multilayer Perceptron Networks (MLP)
* Random Forest (RF) methods which are widely used in multiple classification tasks.
3. Cross Validation
Cross-validation is an important step to acquire the validity of results. For small sampled datasets like microarray data, it is convenient to use
Leave-one-out Cross Validation (LOOCV) for the task.
## Methodology
First the LASSO feature selection method has been applied to get the selected features .The selected alpha parameter for LASSO is 0.0001 .Then, feature count is noted for related datasets.After that, MLP and SVM classifiers have been used to classify and validate the results using LOOCV to calculate the scores.After this step, the Relief feature selection algorithm is used on the datasets to select the most important features.Then the selected features are taken from LASSO to compare their performance. Again, MLP and SVM are used to classify and LOOCV to validate.Lastly, the selected features are used to calculate the accuracy.
## Result Analysis
After the training and tests, the accuracy results are very promising.Here's some comparison.
* MLP training takes a much longer time. SVM is nearly 500 times faster.
* LASSO feature selection significantly outperforms Relief feature selection.
* SVM overwhelmingly faster at training, but for accuracy, MLP is slightly better.
* Rom Forest’s training time is faster than MLP and slower than SVM, but in terms of accuracy, unfortunately, it was the least successful among classifiers used in this study.
After comparing other methods they came to the conclution that LASSO and SVM are significantly better.The method has proved to be a reliable classification system compared to other approaches.
## Literature Review

## Proposed Approach
After searching about some other feature selection methods and classification methods we have decided to apply this following steps:
* First, we have trained the model without using feature selection methods and see how it’s performance changes.
* Second, we have applied another feature extraction method like PCA. Then we compared the results with LASSO.
* Thirdly, we have used other classifiers called XGBoost and LightGBM and compared the results with other classifiers like SVM,MLP,RF.
* Finally, we will compare which feature selection method and classification method performs best together and is it better than this existing method which has been applied in this paper.
## Result

XGboost takes a bit longer time and LightGBM is significantly faster.And if we consider accuracy then, Lasso with LightGBM accuracy 68% is better than Lasso with XGboost 67%.MLP takes a bit longer and it’s accuracy is not convincing.
## Discussions
* In previous studies, Lasso with SVM performed the best with 99% accuracy.
* In other studies LightGBM works better for cancer prediction with 88% accuracy.
* In our study LightGBM accuracy is 68%.