https://github.com/predict-idlab/plotly-resampler
Visualize large time series data with plotly.py
https://github.com/predict-idlab/plotly-resampler
data-analysis data-science data-visualization plotly plotly-dash python time-series visualization
Last synced: about 1 year ago
JSON representation
Visualize large time series data with plotly.py
- Host: GitHub
- URL: https://github.com/predict-idlab/plotly-resampler
- Owner: predict-idlab
- License: mit
- Created: 2021-11-20T10:51:56.000Z (over 4 years ago)
- Default Branch: main
- Last Pushed: 2025-04-07T11:52:48.000Z (over 1 year ago)
- Last Synced: 2025-04-28T17:03:00.020Z (about 1 year ago)
- Topics: data-analysis, data-science, data-visualization, plotly, plotly-dash, python, time-series, visualization
- Language: Python
- Homepage: https://predict-idlab.github.io/plotly-resampler/latest
- Size: 45.7 MB
- Stars: 1,105
- Watchers: 16
- Forks: 73
- Open Issues: 61
-
Metadata Files:
- Readme: README.md
- Changelog: CHANGELOG.md
- Contributing: CONTRIBUTING.md
- Funding: .github/FUNDING.yml
- License: LICENSE
Awesome Lists containing this project
- awesome-time-series - plotly-resampler: Visualize large time series data with plotly.py
- awesome-time-series - plotly-resampler
- awesome-dash - plotly-resampler - Wrapper for plotly figures that adds data downsampling (aggregating) functionality, enabling the visualization of large datasets. (Component Libraries)
- awesome - predict-idlab/plotly-resampler - Visualize large time series data with plotly.py (Python)
README

[](https://pypi.org/project/plotly-resampler/)
[](https://img.shields.io/pypi/pyversions/plotly-resampler)
[](https://codecov.io/gh/predict-idlab/plotly-resampler)
[](https://github.com/predict-idlab/plotly-resampler/actions/workflows/codeql.yml)
[](https://pepy.tech/project/plotly-resampler)
[](http://makeapullrequest.com)
[](https://github.com/predict-idlab/plotly-resampler/actions/workflows/test.yml)
[](https://predict-idlab.github.io/plotly-resampler/latest)
[](https://discord.gg/k2d59GrxPX)
> `plotly_resampler`: visualize large sequential data by **adding resampling functionality to Plotly figures**
`plotly-resampler` improves the scalability of [Plotly](https://github.com/plotly/plotly.py) for visualizing large time series datasets. Specifically, our library _dynamically_ **aggregates time-series data respective to the current graph view**, ensuring efficient and responsive updates during user interactions like panning or zooming via callbacks.
This core aggregation functionality is achieved by utilizing by _time-series data point selection algorithms_, for which `plotly-resampler` leverages the highly optimized implementations available in [tsdownsample](https://github.com/predict-idlab/tsdownsample). Our default data aggregation method is `MinMaxLTTB` (and selects 1000 data points for plotting). For a deeper understanding of this method, you can consult to the algorithm's dedicated [MinMaxLTTB repository](https://github.com/predict-idlab/MinMaxLTTB) and the associated [research paper](https://arxiv.org/abs/2305.00332).
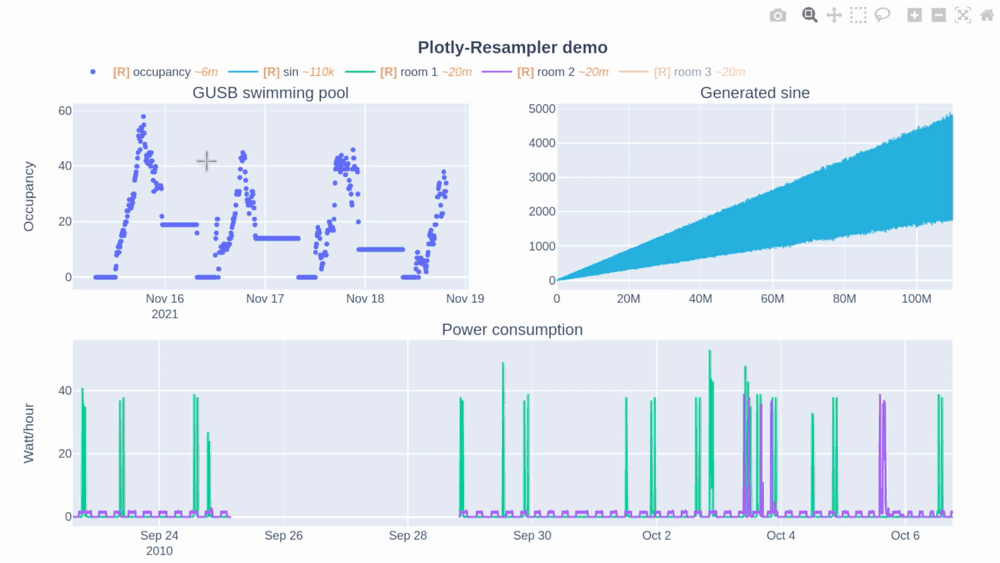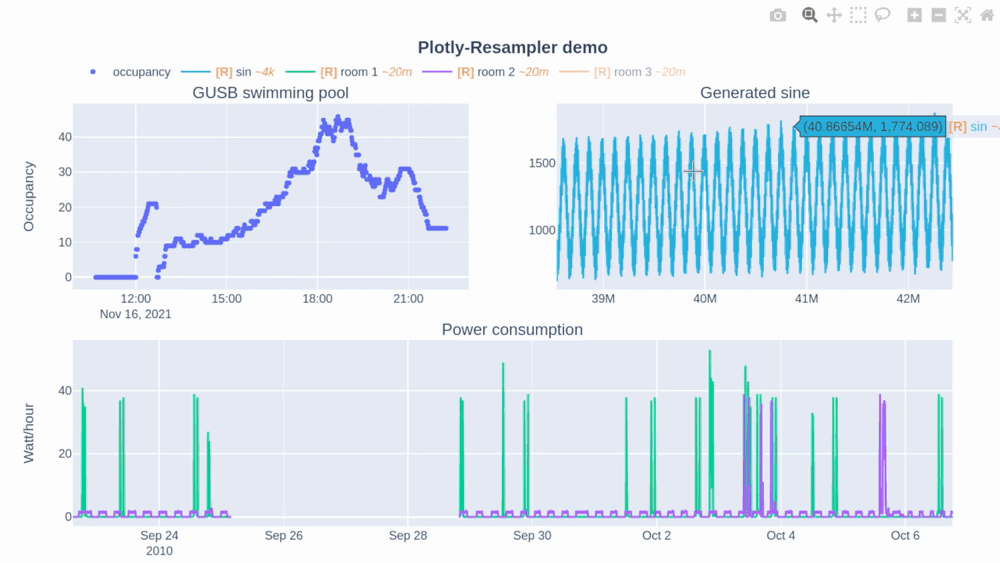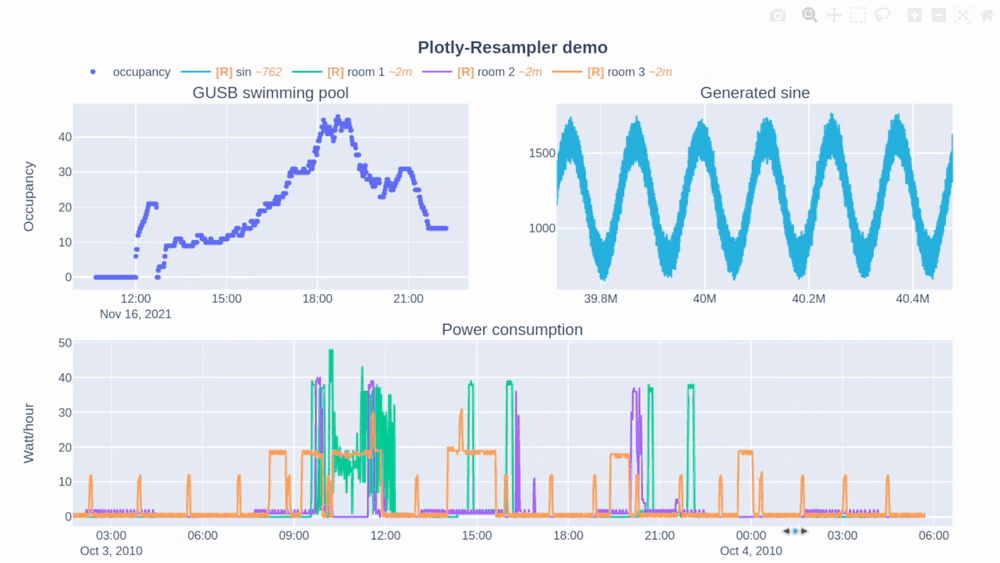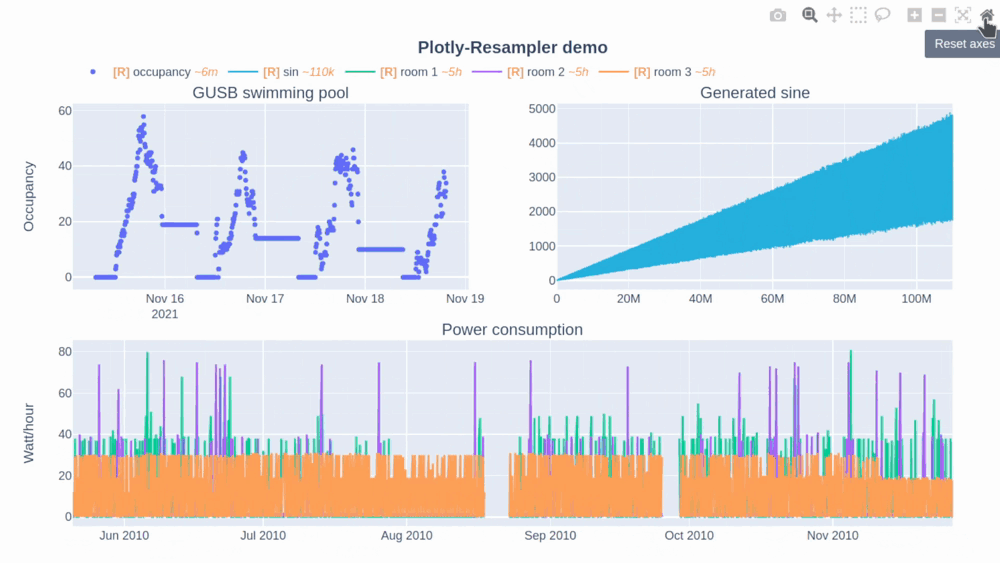
In [this Plotly-Resampler demo](https://github.com/predict-idlab/plotly-resampler/blob/main/examples/basic_example.ipynb) over `110,000,000` data points are visualized!
### 🛠️ Installation
| [**pip**](https://pypi.org/project/plotly_resampler/) | `pip install plotly-resampler` |
| ---| ----|
👀 What is the difference between plotly-resampler figures and plain plotly figures?
`plotly-resampler` can be thought of as wrapper around plain plotly figures which adds visualization scalability to line-charts by dynamically aggregating the data w.r.t. the front-end view. `plotly-resampler` thus adds dynamic aggregation functionality to plain plotly figures.
**❗ Important to know**:
* ``show`` *always* generates a static HTML view of the figure, prohibiting dynamic aggregation.
* To have dynamic aggregation:
* Use `show_dash` with `FigureResampler` to initiate a **Dash** app to realize the dynamic aggregation with **callbacks**.
(or output the object in a cell via ``IPython.display``), which will also spawn a dash-web app
* with ``FigureWidgetResampler``, you need to use ``IPython.display`` on the object, which uses widget-events to realize dynamic aggregation (via the running **IPython kernel**).
**Other changes of plotly-resampler figures w.r.t. vanilla plotly**:
* **double-clicking** within a line-chart area **does not Reset Axes**, as it results in an “Autoscale” event. We decided to implement an Autoscale event as updating your y-range such that it shows all the data that is in your x-range.
* **Note**: vanilla Plotly figures their Autoscale result in Reset Axes behavior, in our opinion this did not make a lot of sense. It is therefore that we have overriden this behavior in plotly-resampler.
### 📋 Features
* **Convenient** to use:
* just add either
* `register_plotly_resampler` function to your notebook with the best suited `mode` argument.
* `FigureResampler` decorator around a plotly Figure and call `.show_dash()`
* `FigureWidgetResampler` decorator around a plotly Figure and output the instance in a cell
* allows all other plotly figure construction flexibility to be used!
* **Environment-independent**
* can be used in Jupyter, vscode-notebooks, Pycharm-notebooks, Google Colab, DataSpell, and even as application (on a server)
* Interface for **various aggregation algorithms**:
* ability to develop or select your preferred sequence aggregation method
## 🚀 Usage
**Add dynamic aggregation** to your plotly Figure _(unfold your fitting use case)_
* 🤖 Automatically _(minimal code overhead)_:
Use the register_plotly_resampler function
1. Import and call the `register_plotly_resampler` method
2. Just use your regular graph construction code
* **code example**:
```python
import plotly.graph_objects as go; import numpy as np
from plotly_resampler import register_plotly_resampler
# Call the register function once and all Figures/FigureWidgets will be wrapped
# according to the register_plotly_resampler its `mode` argument
register_plotly_resampler(mode='auto')
x = np.arange(1_000_000)
noisy_sin = (3 + np.sin(x / 200) + np.random.randn(len(x)) / 10) * x / 1_000
# auto mode: when working in an IPython environment, this will automatically be a
# FigureWidgetResampler else, this will be an FigureResampler
f = go.Figure()
f.add_trace({"y": noisy_sin + 2, "name": "yp2"})
f
```
> **Note**: This wraps **all** plotly graph object figures with a
> `FigureResampler` | `FigureWidgetResampler`. This can thus also be
> used for the `plotly.express` interface. 🎉
* 👷 Manually _(higher data aggregation configurability, more speedup possibilities)_:
* Within a jupyter environment without creating a web application
1. wrap the plotly Figure with `FigureWidgetResampler`
2. output the `FigureWidgetResampler` instance in a cell
```python
import plotly.graph_objects as go; import numpy as np
from plotly_resampler import FigureResampler, FigureWidgetResampler
x = np.arange(1_000_000)
noisy_sin = (3 + np.sin(x / 200) + np.random.randn(len(x)) / 10) * x / 1_000
# OPTION 1 - FigureWidgetResampler: dynamic aggregation via `FigureWidget.layout.on_change`
fig = FigureWidgetResampler(go.Figure())
fig.add_trace(go.Scattergl(name='noisy sine', showlegend=True), hf_x=x, hf_y=noisy_sin)
fig
```
* Using a web-application with dash callbacks
1. wrap the plotly Figure with `FigureResampler`
2. call `.show_dash()` on the `Figure`
```python
import plotly.graph_objects as go; import numpy as np
from plotly_resampler import FigureResampler, FigureWidgetResampler
x = np.arange(1_000_000)
noisy_sin = (3 + np.sin(x / 200) + np.random.randn(len(x)) / 10) * x / 1_000
# OPTION 2 - FigureResampler: dynamic aggregation via a Dash web-app
fig = FigureResampler(go.Figure())
fig.add_trace(go.Scattergl(name='noisy sine', showlegend=True), hf_x=x, hf_y=noisy_sin)
fig.show_dash(mode='inline')
```
> **Tip** 💡:
> For significant faster initial loading of the Figure, we advise to wrap the
> constructor of the plotly Figure and add the trace data as `hf_x` and `hf_y`
> **Note**:
> Any plotly Figure can be wrapped with `FigureResampler` and `FigureWidgetResampler`! 🎉
> But **only** the `go.Scatter`/`go.Scattergl` **traces are resampled**.
## 💭 Important considerations & tips
* When running the code on a server, you should forward the port of the `FigureResampler.show_dash()` method to your local machine.
**Note** that you can add dynamic aggregation to plotly figures with the `FigureWidgetResampler` wrapper without needing to forward a port!
* The `FigureWidgetResampler` *uses the IPython main thread* for its data aggregation functionality, so when this main thread is occupied, no resampling logic can be executed. For example; if you perform long computations within your notebook, the kernel will be occupied during these computations, and will only execute the resampling operations that take place during these computations after finishing that computation.
* In general, when using downsampling one should be aware of (possible) [aliasing](https://en.wikipedia.org/wiki/Aliasing) effects.
The [R] in the legend indicates when the corresponding trace is being resampled (and thus possibly distorted) or not. Additionally, the `~` suffix represent the mean aggregation bin size in terms of the sequence index.
* The plotly **autoscale** event (triggered by the autoscale button or a double-click within the graph), **does not reset the axes but autoscales the current graph-view** of plotly-resampler figures. This design choice was made as it seemed more intuitive for the developers to support this behavior with double-click than the default axes-reset behavior. The graph axes can ofcourse be resetted by using the `reset_axis` button. If you want to give feedback and discuss this further with the developers, see issue [#49](https://github.com/predict-idlab/plotly-resampler/issues/49).
## 📜 Citation and papers
The paper about the plotly-resampler toolkit itself (preprint): https://arxiv.org/abs/2206.08703
```bibtex
@inproceedings{van2022plotly,
title={Plotly-resampler: Effective visual analytics for large time series},
author={Van Der Donckt, Jonas and Van Der Donckt, Jeroen and Deprost, Emiel and Van Hoecke, Sofie},
booktitle={2022 IEEE Visualization and Visual Analytics (VIS)},
pages={21--25},
year={2022},
organization={IEEE}
}
```
**Related papers**:
- **Visual representativeness** of time series data point selection algorithms (preprint): https://arxiv.org/abs/2304.00900
code: https://github.com/predict-idlab/ts-datapoint-selection-vis
- **MinMaxLTTB** - an efficient data point selection algorithm (preprint): https://arxiv.org/abs/2305.00332
code: https://github.com/predict-idlab/MinMaxLTTB
---
👤 Jonas Van Der Donckt, Jeroen Van Der Donckt, Emiel Deprost