Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/princeton-nlp/mezo
[NeurIPS 2023] MeZO: Fine-Tuning Language Models with Just Forward Passes. https://arxiv.org/abs/2305.17333
https://github.com/princeton-nlp/mezo
Last synced: 30 days ago
JSON representation
[NeurIPS 2023] MeZO: Fine-Tuning Language Models with Just Forward Passes. https://arxiv.org/abs/2305.17333
- Host: GitHub
- URL: https://github.com/princeton-nlp/mezo
- Owner: princeton-nlp
- License: mit
- Created: 2023-05-22T18:51:33.000Z (over 1 year ago)
- Default Branch: main
- Last Pushed: 2024-01-11T18:07:52.000Z (10 months ago)
- Last Synced: 2024-10-14T09:01:10.487Z (30 days ago)
- Language: Python
- Homepage:
- Size: 383 KB
- Stars: 1,032
- Watchers: 19
- Forks: 62
- Open Issues: 25
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# MeZO: Fine-Tuning Language Models with Just Forward Passes
This is the implementation for the paper [Fine-Tuning Language Models with Just Forward Passes](https://arxiv.org/pdf/2305.17333.pdf).
In this paper we propose a memory-efficient zeroth-order optimizer (**MeZO**),
adapting the classical zeroth-order SGD method to operate in-place, thereby fine-tuning language models (LMs) with the same memory footprint as inference.
With a single A100 80GB GPU, MeZO can train a 30-billion parameter OPT model, whereas fine-tuning with Adam can train only a 2.7B LM.
MeZO demonstrates comparable performance to fine-tuning with backpropagation across multiple tasks, with up to 12× memory reduction. MeZO is also compatible with both full-parameter and parameter-efficient tuning techniques such as LoRA and prefix tuning. We also show that MeZO can effectively optimize non-differentiable objectives (e.g., maximizing accuracy or F1).
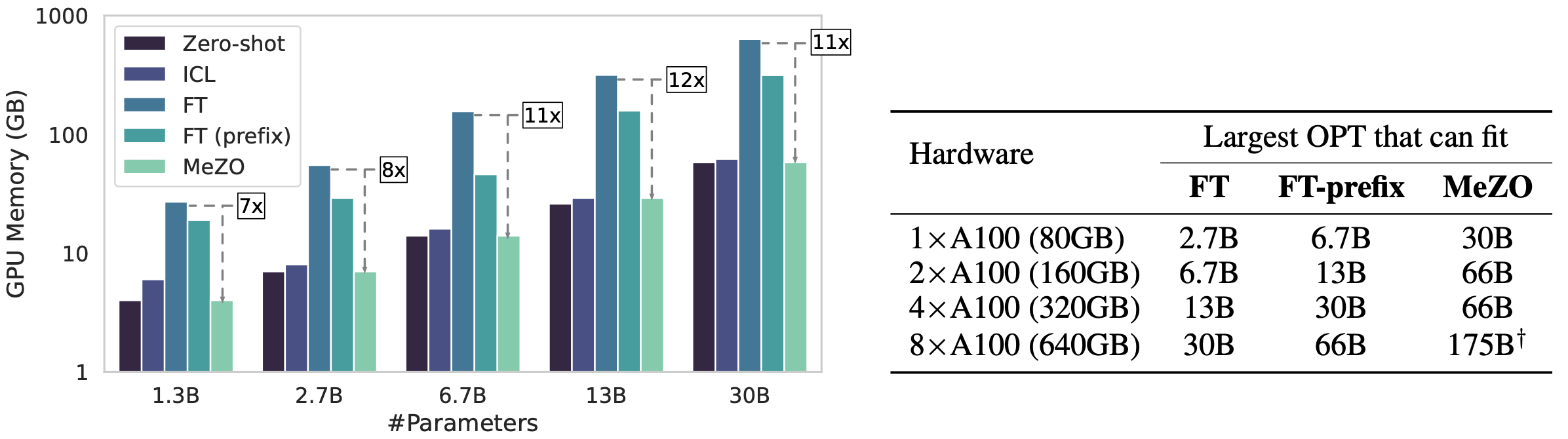
GPU memory usage comparison between zero-shot, in-context learning (ICL), Adam fine-tuning (FT), and our proposed MeZO.

OPT-13B results with zero-shot, in-context learning (ICL), MeZO (we report the best among MeZO/MeZO (LoRA)/MeZO (prefix)), and fine-tuning with Adam (FT). MeZO demonstrates superior results over zero-shot and ICL and performs on par with FT (within 1%) on 7 out of 11 tasks, despite using only 1/12 memory.
## Reproduce our paper results
For reproducing RoBERTa-large experiments, please refer to the [medium_models](https://github.com/princeton-nlp/MeZO/tree/main/medium_models) folder. For autoregressive LM (OPT) experiments, please refer to the [large_models](https://github.com/princeton-nlp/MeZO/tree/main/large_models) folder. If you want to learn more about how MeZO works and how we implement it, we recommend you to read the [large_models](https://github.com/princeton-nlp/MeZO/tree/main/large_models) folder as the implementation is clearer and more extensible. If you want to explore more variants of MeZO, we recommend trying out [medium_models](https://github.com/princeton-nlp/MeZO/tree/main/medium_models) as it's faster and has more variants implemented.
## How to add MeZO to my own code?
Our implementation of MeZO is based on [HuggingFace's Trainer](https://github.com/huggingface/transformers/blob/main/src/transformers/trainer.py). We add MeZO to the official implementation of trainer with minimum editing. Please refer to "How to add MeZO to my own code?" section in [large_models](https://github.com/princeton-nlp/MeZO/tree/main/large_models) README for more details.
## Bugs or questions?
If you have any questions related to the code or the paper, feel free to email Sadhika (`[email protected]`) or Tianyu (`[email protected]`). If you encounter any problems when using the code, or want to report a bug, you can open an issue. Please try to specify the problem with details so we can help you better and quicker!
## Citation
```bibtex
@article{malladi2023mezo,
title={Fine-Tuning Large Language Models with Just Forward Passes},
author={Malladi, Sadhika and Gao, Tianyu and Nichani, Eshaan and Damian, Alex and Lee, Jason D and Chen, Danqi and Arora, Sanjeev},
year={2023}
}
```