https://github.com/projectphysx/fluidx3d
The fastest and most memory efficient lattice Boltzmann CFD software, running on all GPUs and CPUs via OpenCL. Free for non-commercial use.
https://github.com/projectphysx/fluidx3d
benchmark cfd computational-fluid-dynamics fluid-dynamics fluid-simulation fluid-solver gpgpu gpu gpu-computing high-performance-computing hpc interactive-visualization lattice-boltzmann lbm opencl physics raytracing scientific-computing scientific-visualization simulation
Last synced: about 1 year ago
JSON representation
The fastest and most memory efficient lattice Boltzmann CFD software, running on all GPUs and CPUs via OpenCL. Free for non-commercial use.
- Host: GitHub
- URL: https://github.com/projectphysx/fluidx3d
- Owner: ProjectPhysX
- License: other
- Created: 2022-08-04T08:49:44.000Z (almost 4 years ago)
- Default Branch: master
- Last Pushed: 2025-05-13T04:49:17.000Z (about 1 year ago)
- Last Synced: 2025-05-13T05:29:25.241Z (about 1 year ago)
- Topics: benchmark, cfd, computational-fluid-dynamics, fluid-dynamics, fluid-simulation, fluid-solver, gpgpu, gpu, gpu-computing, high-performance-computing, hpc, interactive-visualization, lattice-boltzmann, lbm, opencl, physics, raytracing, scientific-computing, scientific-visualization, simulation
- Language: C++
- Homepage: https://youtube.com/@ProjectPhysX
- Size: 21 MB
- Stars: 4,416
- Watchers: 62
- Forks: 382
- Open Issues: 30
-
Metadata Files:
- Readme: README.md
- License: LICENSE.md
- Citation: CITATION.cff
Awesome Lists containing this project
README
# FluidX3D
The fastest and most memory efficient lattice Boltzmann CFD software, running on all GPUs and CPUs via [OpenCL](https://github.com/ProjectPhysX/OpenCL-Wrapper "OpenCL-Wrapper"). Free for non-commercial use.
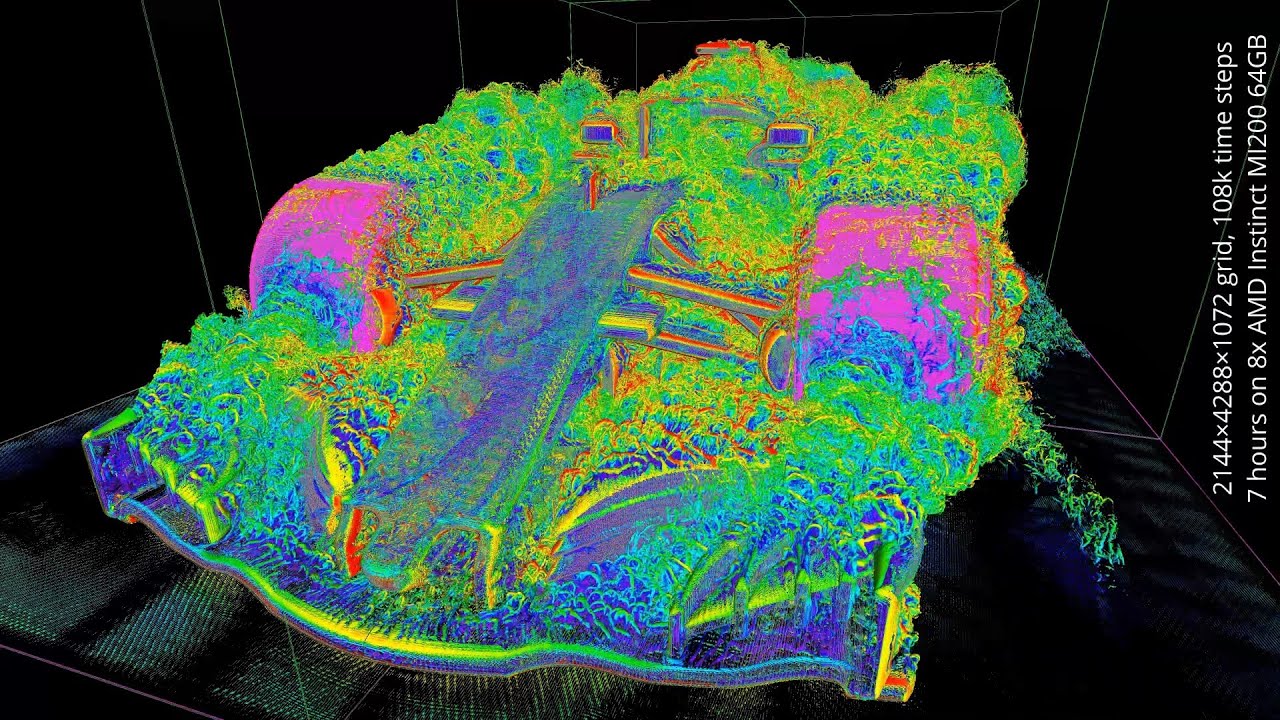


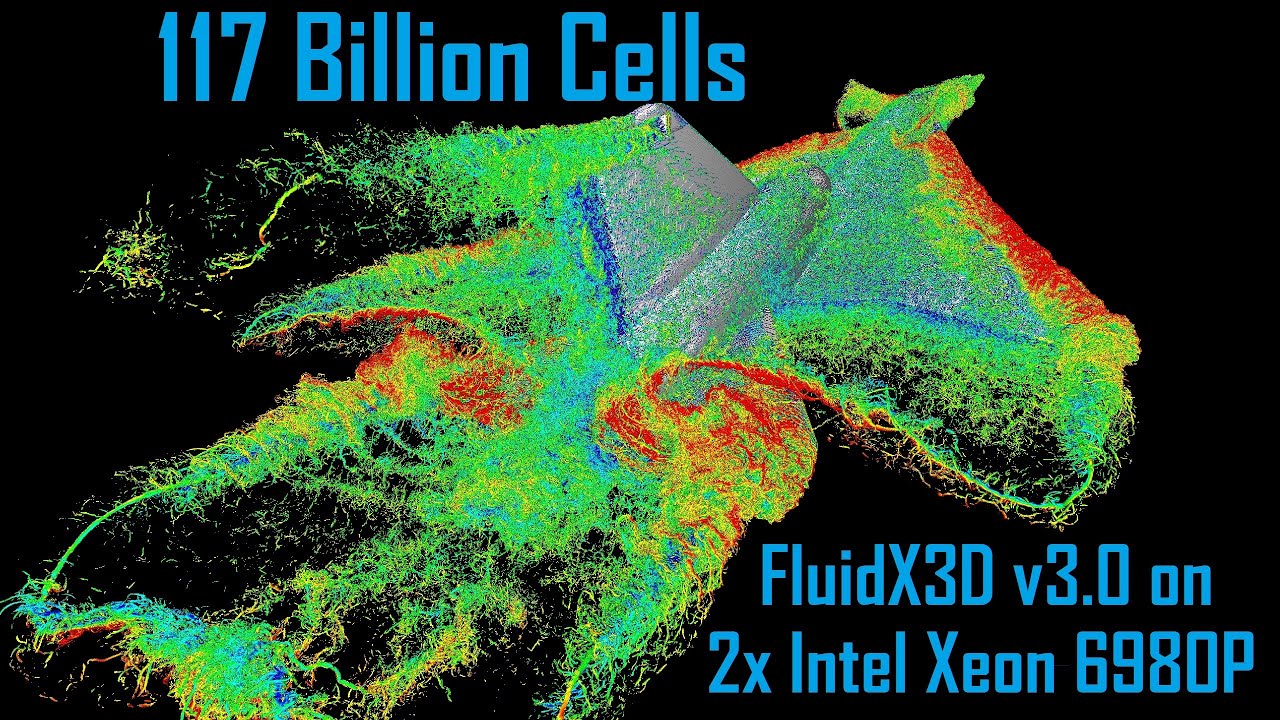
(click on images to show videos on YouTube)
Update History
- [v1.0](https://github.com/ProjectPhysX/FluidX3D/releases/tag/v1.0) (04.08.2022) [changes](https://github.com/ProjectPhysX/FluidX3D/commit/768073501af725e392a4b85885009e2fa6400e48) (public release)
- public release
- [v1.1](https://github.com/ProjectPhysX/FluidX3D/releases/tag/v1.1) (29.09.2022) [changes](https://github.com/ProjectPhysX/FluidX3D/compare/v1.0...v1.1) (GPU voxelization)
- added solid voxelization on GPU (slow algorithm)
- added tool to print current camera position (key G)
- minor bug fix (workaround for Intel iGPU driver bug with triangle rendering)
- [v1.2](https://github.com/ProjectPhysX/FluidX3D/releases/tag/v1.2) (24.10.2022) [changes](https://github.com/ProjectPhysX/FluidX3D/compare/v1.1...v1.2) (force/torque compuatation)
- added functions to compute force/torque on objects
- added function to translate Mesh
- added Stokes drag validation setup
- [v1.3](https://github.com/ProjectPhysX/FluidX3D/releases/tag/v1.3) (10.11.2022) [changes](https://github.com/ProjectPhysX/FluidX3D/compare/v1.2...v1.3) (minor bug fixes)
- added unit conversion functions for torque
- `FORCE_FIELD` and `VOLUME_FORCE` can now be used independently
- minor bug fix (workaround for AMD legacy driver bug with binary number literals)
- [v1.4](https://github.com/ProjectPhysX/FluidX3D/releases/tag/v1.4) (14.12.2022) [changes](https://github.com/ProjectPhysX/FluidX3D/compare/v1.3...v1.4) (Linux graphics)
- complete rewrite of C++ graphics library to minimize API dependencies
- added interactive graphics mode on Linux with X11
- fixed streamline visualization bug in 2D
- [v2.0](https://github.com/ProjectPhysX/FluidX3D/releases/tag/v2.0) (09.01.2023) [changes](https://github.com/ProjectPhysX/FluidX3D/compare/v1.4...v2.0) (multi-GPU upgrade)
- added (cross-vendor) multi-GPU support on a single node (PC/laptop/server)
- [v2.1](https://github.com/ProjectPhysX/FluidX3D/releases/tag/v2.1) (15.01.2023) [changes](https://github.com/ProjectPhysX/FluidX3D/compare/v2.0...v2.1) (fast voxelization)
- made solid voxelization on GPU lightning fast (new algorithm, from minutes to milliseconds)
- [v2.2](https://github.com/ProjectPhysX/FluidX3D/releases/tag/v2.0) (20.01.2023) [changes](https://github.com/ProjectPhysX/FluidX3D/compare/v2.1...v2.2) (velocity voxelization)
- added option to voxelize moving/rotating geometry on GPU, with automatic velocity initialization for each grid point based on center of rotation, linear velocity and rotational velocity
- cells that are converted from solid->fluid during re-voxelization now have their DDFs properly initialized
- added option to not auto-scale mesh during `read_stl(...)`, with negative `size` parameter
- added kernel for solid boundary rendering with marching-cubes
- [v2.3](https://github.com/ProjectPhysX/FluidX3D/releases/tag/v2.3) (30.01.2023) [changes](https://github.com/ProjectPhysX/FluidX3D/compare/v2.2...v2.3) (particles)
- added particles with immersed-boundary method (either passive or 2-way-coupled, only supported with single-GPU)
- minor optimization to GPU voxelization algorithm (workgroup threads outside mesh bounding-box return after ray-mesh intersections have been found)
- displayed GPU memory allocation size is now fully accurate
- fixed bug in `write_line()` function in `src/utilities.hpp`
- removed `.exe` file extension for Linux/macOS
- [v2.4](https://github.com/ProjectPhysX/FluidX3D/releases/tag/v2.4) (11.03.2023) [changes](https://github.com/ProjectPhysX/FluidX3D/compare/v2.3...v2.4) (UI improvements)
- added a help menu with key H that shows keyboard/mouse controls, visualization settings and simulation stats
- improvements to keyboard/mouse control (+/- for zoom, mouseclick frees/locks cursor)
- added suggestion of largest possible grid resolution if resolution is set larger than memory allows
- minor optimizations in multi-GPU communication (insignificant performance difference)
- fixed bug in temperature equilibrium function for temperature extension
- fixed erroneous double literal for Intel iGPUs in skybox color functions
- fixed bug in make.sh where multi-GPU device IDs would not get forwarded to the executable
- minor bug fixes in graphics engine (free cursor not centered during rotation, labels in VR mode)
- fixed bug in `LBM::voxelize_stl()` size parameter standard initialization
- [v2.5](https://github.com/ProjectPhysX/FluidX3D/releases/tag/v2.5) (11.04.2023) [changes](https://github.com/ProjectPhysX/FluidX3D/compare/v2.4...v2.5) (raytracing overhaul)
- implemented light absorption in fluid for raytracing graphics (no performance impact)
- improved raytracing framerate when camera is inside fluid
- fixed skybox pole flickering artifacts
- fixed bug where moving objects during re-voxelization would leave an erroneous trail of solid grid cells behind
- [v2.6](https://github.com/ProjectPhysX/FluidX3D/releases/tag/v2.6) (16.04.2023) [changes](https://github.com/ProjectPhysX/FluidX3D/compare/v2.5...v2.6) (Intel Arc patch)
- patched OpenCL issues of Intel Arc GPUs: now VRAM allocations >4GB are possible and correct VRAM capacity is reported
- [v2.7](https://github.com/ProjectPhysX/FluidX3D/releases/tag/v2.7) (29.05.2023) [changes](https://github.com/ProjectPhysX/FluidX3D/compare/v2.6...v2.7) (visualization upgrade)
- added slice visualization (key 2 / key 3 modes, then switch through slice modes with key T, move slice with keys Q/E)
- made flag wireframe / solid surface visualization kernels toggleable with key 1
- added surface pressure visualization (key 1 when `FORCE_FIELD` is enabled and `lbm.calculate_force_on_boundaries();` is called)
- added binary `.vtk` export function for meshes with `lbm.write_mesh_to_vtk(Mesh* mesh);`
- added `time_step_multiplicator` for `integrate_particles()` function in PARTICLES extension
- made correction of wrong memory reporting on Intel Arc more robust
- fixed bug in `write_file()` template functions
- reverted back to separate `cl::Context` for each OpenCL device, as the shared Context otherwise would allocate extra VRAM on all other unused Nvidia GPUs
- removed Debug and x86 configurations from Visual Studio solution file (one less complication for compiling)
- fixed bug that particles could get too close to walls and get stuck, or leave the fluid phase (added boundary force)
- [v2.8](https://github.com/ProjectPhysX/FluidX3D/releases/tag/v2.8) (24.06.2023) [changes](https://github.com/ProjectPhysX/FluidX3D/compare/v2.7...v2.8) (documentation + polish)
- finally added more [documentation](DOCUMENTATION.md)
- cleaned up all sample setups in `setup.cpp` for more beginner-friendliness, and added required extensions in `defines.hpp` as comments to all setups
- improved loading of composite `.stl` geometries, by adding an option to omit automatic mesh repositioning, added more functionality to `Mesh` struct in `utilities.hpp`
- added `uint3 resolution(float3 box_aspect_ratio, uint memory)` function to compute simulation box resolution based on box aspect ratio and VRAM occupation in MB
- added `bool lbm.graphics.next_frame(...)` function to export images for a specified video length in the `main_setup` compute loop
- added `VIS_...` macros to ease setting visualization modes in headless graphics mode in `lbm.graphics.visualization_modes`
- simulation box dimensions are now automatically made equally divisible by domains for multi-GPU simulations
- fixed Info/Warning/Error message formatting for loading files and made Info/Warning/Error message labels colored
- added Ahmed body setup as an example on how body forces and drag coefficient are computed
- added Cessna 172 and Bell 222 setups to showcase loading composite .stl geometries and revoxelization of moving parts
- added optional semi-transparent rendering mode (`#define GRAPHICS_TRANSPARENCY 0.7f` in `defines.hpp`)
- fixed flickering of streamline visualization in interactive graphics
- improved smooth positioning of streamlines in slice mode
- fixed bug where `mass` and `massex` in `SURFACE` extension were also allocated in CPU RAM (not required)
- fixed bug in Q-criterion rendering of halo data in multi-GPU mode, reduced gap width between domains
- removed shared memory optimization from mesh voxelization kernel, as it crashes on Nvidia GPUs with new GPU drivers and is incompatible with old OpenCL 1.0 GPUs
- fixed raytracing attenuation color when no surface is at the simulation box walls with periodic boundaries
- [v2.9](https://github.com/ProjectPhysX/FluidX3D/releases/tag/v2.9) (31.07.2023) [changes](https://github.com/ProjectPhysX/FluidX3D/compare/v2.8...v2.9) (multithreading)
- added cross-platform `parallel_for` implementation in `utilities.hpp` using `std::threads`
- significantly (>4x) faster simulation startup with multithreaded geometry initialization and sanity checks
- faster `calculate_force_on_object()` and `calculate_torque_on_object()` functions with multithreading
- added total runtime and LBM runtime to `lbm.write_status()`
- fixed bug in voxelization ray direction for re-voxelizing rotating objects
- fixed bug in `Mesh::get_bounding_box_size()`
- fixed bug in `print_message()` function in `utilities.hpp`
- [v2.10](https://github.com/ProjectPhysX/FluidX3D/releases/tag/v2.10) (05.11.2023) [changes](https://github.com/ProjectPhysX/FluidX3D/compare/v2.9...v2.10) (frustrum culling)
- improved rasterization performance via frustrum culling when only part of the simulation box is visible
- improved switching between centered/free camera mode
- refactored OpenCL rendering library
- unit conversion factors are now automatically printed in console when `units.set_m_kg_s(...)` is used
- faster startup time for FluidX3D benchmark
- miner bug fix in `voxelize_mesh(...)` kernel
- fixed bug in `shading(...)`
- replaced slow (in multithreading) `std::rand()` function with standard C99 LCG
- more robust correction of wrong VRAM capacity reporting on Intel Arc GPUs
- fixed some minor compiler warnings
- [v2.11](https://github.com/ProjectPhysX/FluidX3D/releases/tag/v2.11) (07.12.2023) [changes](https://github.com/ProjectPhysX/FluidX3D/compare/v2.10...v2.11) (improved Linux graphics)
- interactive graphics on Linux are now in fullscreen mode too, fully matching Windows
- made CPU/GPU buffer initialization significantly faster with `std::fill` and `enqueueFillBuffer` (overall ~8% faster simulation startup)
- added operating system info to OpenCL device driver version printout
- fixed flickering with frustrum culling at very small field of view
- fixed bug where rendered/exported frame was not updated when `visualization_modes` changed
- [v2.12](https://github.com/ProjectPhysX/FluidX3D/releases/tag/v2.12) (18.01.2024) [changes](https://github.com/ProjectPhysX/FluidX3D/compare/v2.11...v2.12) (faster startup)
- ~3x faster source code compiling on Linux using multiple CPU cores if [`make`](https://www.gnu.org/software/make/) is installed
- significantly faster simulation initialization (~40% single-GPU, ~15% multi-GPU)
- minor bug fix in `Memory_Container::reset()` function
- [v2.13](https://github.com/ProjectPhysX/FluidX3D/releases/tag/v2.13) (11.02.2024) [changes](https://github.com/ProjectPhysX/FluidX3D/compare/v2.12...v2.13) (improved .vtk export)
- data in exported `.vtk` files is now automatically converted to SI units
- ~2x faster `.vtk` export with multithreading
- added unit conversion functions for `TEMPERATURE` extension
- fixed graphical artifacts with axis-aligned camera in raytracing
- fixed `get_exe_path()` for macOS
- fixed X11 multi-monitor issues on Linux
- workaround for Nvidia driver bug: `enqueueFillBuffer` is broken for large buffers on Nvidia GPUs
- fixed slow numeric drift issues caused by `-cl-fast-relaxed-math`
- fixed wrong Maximum Allocation Size reporting in `LBM::write_status()`
- fixed missing scaling of coordinates to SI units in `LBM::write_mesh_to_vtk()`
- [v2.14](https://github.com/ProjectPhysX/FluidX3D/releases/tag/v2.14) (03.03.2024) [changes](https://github.com/ProjectPhysX/FluidX3D/compare/v2.13...v2.14) (visualization upgrade)
- coloring can now be switched between velocity/density/temperature with key Z
- uniform improved color palettes for velocity/density/temperature visualization
- color scale with automatic unit conversion can now be shown with key H
- slice mode for field visualization now draws fully filled-in slices instead of only lines for velocity vectors
- shading in `VIS_FLAG_SURFACE` and `VIS_PHI_RASTERIZE` modes is smoother now
- `make.sh` now automatically detects operating system and X11 support on Linux and only runs FluidX3D if last compilation was successful
- fixed compiler warnings on Android
- fixed `make.sh` failing on some systems due to nonstandard interpreter path
- fixed that `make` would not compile with multiple cores on some systems
- [v2.15](https://github.com/ProjectPhysX/FluidX3D/releases/tag/v2.15) (09.04.2024) [changes](https://github.com/ProjectPhysX/FluidX3D/compare/v2.14...v2.15) (framerate boost)
- eliminated one frame memory copy and one clear frame operation in rendering chain, for 20-70% higher framerate on both Windows and Linux
- enabled `g++` compiler optimizations for faster startup and higher rendering framerate
- fixed bug in multithreaded sanity checks
- fixed wrong unit conversion for thermal expansion coefficient
- fixed density to pressure conversion in LBM units
- fixed bug that raytracing kernel could lock up simulation
- fixed minor visual artifacts with raytracing
- fixed that console sometimes was not cleared before `INTERACTIVE_GRAPHICS_ASCII` rendering starts
- [v2.16](https://github.com/ProjectPhysX/FluidX3D/releases/tag/v2.16) (02.05.2024) [changes](https://github.com/ProjectPhysX/FluidX3D/compare/v2.15...v2.16) (bug fixes)
- simplified 10% faster marching-cubes implementation with 1D interpolation on edges instead of 3D interpolation, allowing to get rid of edge table
- added faster, simplified marching-cubes variant for solid surface rendering where edges are always halfway between grid cells
- refactoring in OpenCL rendering kernels
- fixed that voxelization failed in Intel OpenCL CPU Runtime due to array out-of-bounds access
- fixed that voxelization did not always produce binary identical results in multi-GPU compared to single-GPU
- fixed that velocity voxelization failed for free surface simulations
- fixed terrible performance on ARM GPUs by macro-replacing fused-multiply-add (`fma`) with `a*b+c`
- fixed that Y/Z keys were incorrect for `QWERTY` keyboard layout in Linux
- fixed that free camera movement speed in help overlay was not updated in stationary image when scrolling
- fixed that cursor would sometimes flicker when scrolling on trackpads with Linux-X11 interactive graphics
- fixed flickering of interactive rendering with multi-GPU when camera is not moved
- fixed missing `XInitThreads()` call that could crash Linux interactive graphics on some systems
- fixed z-fighting between `graphics_rasterize_phi()` and `graphics_flags_mc()` kernels
- [v2.17](https://github.com/ProjectPhysX/FluidX3D/releases/tag/v2.17) (05.06.2024) [changes](https://github.com/ProjectPhysX/FluidX3D/compare/v2.16...v2.17) (unlimited domain resolution)
- domains are no longer limited to 4.29 billion (2³², 1624³) grid cells or 225 GB memory; if more are used, the OpenCL code will automatically compile with 64-bit indexing
- new, faster raytracing-based field visualization for single-GPU simulations
- added [GPU Driver and OpenCL Runtime installation instructions](DOCUMENTATION.md#0-install-gpu-drivers-and-opencl-runtime) to documentation
- refactored `INTERACTIVE_GRAPHICS_ASCII`
- fixed memory leak in destructors of `floatN`, `floatNxN`, `doubleN`, `doubleNxN` (all unused)
- made camera movement/rotation/zoom behavior independent of framerate
- fixed that `smart_device_selection()` would print a wrong warning if device reports 0 MHz clock speed
- [v2.18](https://github.com/ProjectPhysX/FluidX3D/releases/tag/v2.18) (21.07.2024) [changes](https://github.com/ProjectPhysX/FluidX3D/compare/v2.17...v2.18) (more bug fixes)
- added support for high refresh rate monitors on Linux
- more compact OpenCL Runtime installation scripts in Documentation
- driver/runtime installation instructions will now be printed to console if no OpenCL devices are available
- added domain information to `LBM::write_status()`
- added `LBM::index` function for `uint3` input parameter
- fixed that very large simulations sometimes wouldn't render properly by increasing maximum render distance from 10k to 2.1M
- fixed mouse input stuttering at high screen refresh rate on Linux
- fixed graphical artifacts in free surface raytracing on Intel CPU Runtime for OpenCL
- fixed runtime estimation printed in console for setups with multiple `lbm.run(...)` calls
- fixed density oscillations in sample setups (too large `lbm_u`)
- fixed minor graphical artifacts in `raytrace_phi()`
- fixed minor graphical artifacts in `ray_grid_traverse_sum()`
- fixed wrong printed time step count on raindrop sample setup
- [v2.19](https://github.com/ProjectPhysX/FluidX3D/releases/tag/v2.19) (07.09.2024) [changes](https://github.com/ProjectPhysX/FluidX3D/compare/v2.18...v2.19) (camera splines)
- the camera can now fly along a smooth path through a list of provided keyframe camera placements, [using Catmull-Rom splines](https://github.com/ProjectPhysX/FluidX3D/blob/master/DOCUMENTATION.md#video-rendering)
- more accurate remaining runtime estimation that includes time spent on rendering
- enabled FP16S memory compression by default
- printed camera placement using key G is now formatted for easier copy/paste
- added benchmark chart in Readme using mermaid gantt chart
- placed memory allocation info during simulation startup at better location
- fixed threading conflict between `INTERACTIVE_GRAPHICS` and `lbm.graphics.write_frame();`
- fixed maximum buffer allocation size limit for AMD GPUs and in Intel CPU Runtime for OpenCL
- fixed wrong `Re
## How to get started?
Read the [FluidX3D Documentation](DOCUMENTATION.md)!
## Compute Features - Getting the Memory Problem under Control
- CFD model: lattice Boltzmann method (LBM)
- streaming (part 2/2)
f0temp(x,t) = f0(x, t)
fitemp(x,t) = f(t%2 ? i : (i%2 ? i+1 : i-1))(i%2 ? x : x-ei, t) for i ∈ [1, q-1]
- collisionρ(x,t) = (Σi fitemp(x,t)) + 1
u(x,t) = 1∕ρ(x,t) Σi ci fitemp(x,t)
fieq-shifted(x,t) = wi ρ · ((u°ci)2∕(2c4) - (u°u)∕(2c2) + (u°ci)∕c2) + wi (ρ-1)
fitemp(x, t+Δt) = fitemp(x,t) + Ωi(fitemp(x,t), fieq-shifted(x,t), τ)
- streaming (part 1/2)f0(x, t+Δt) = f0temp(x, t+Δt)
f(t%2 ? (i%2 ? i+1 : i-1) : i)(i%2 ? x+ei : x, t+Δt) = fitemp(x, t+Δt) for i ∈ [1, q-1]
- variables and notation
| variable | SI units | defining equation | description |
| :------------------: | :---------------------------------: | :-------------------------------------------------: | :------------------------------------------------------------------------------ |
| | | | |
| x | m | x = (x,y,z)T | 3D position in Cartesian coordinates |
| t | s | - | time |
| ρ | kg∕m³ | ρ = (Σi fi)+1 | mass density of fluid |
| p | kg∕m s² | p = c² ρ | pressure of fluid |
| u | m∕s | u = 1∕ρ Σi ci fi | velocity of fluid |
| ν | m²∕s | ν = μ∕ρ | kinematic shear viscosity of fluid |
| μ | kg∕m s | μ = ρ ν | dynamic viscosity of fluid |
| | | | |
| fi | kg∕m³ | - | shifted density distribution functions (DDFs) |
| Δx | m | Δx = 1 | lattice constant (in LBM units) |
| Δt | s | Δt = 1 | simulation time step (in LBM units) |
| c | m∕s | c = 1∕√3 Δx∕Δt | lattice speed of sound (in LBM units) |
| i | 1 | 0 ≤ i < q | LBM streaming direction index |
| q | 1 | q ∈ { 9,15,19,27 } | number of LBM streaming directions |
| ei | m | D2Q9 / D3Q15/19/27 | LBM streaming directions |
| ci | m∕s | ci = ei∕Δt | LBM streaming velocities |
| wi | 1 | Σi wi = 1 | LBM velocity set weights |
| Ωi | kg∕m³ | SRT or TRT | LBM collision operator |
| τ | s | τ = ν∕c² + Δt∕2 | LBM relaxation time |
- velocity sets: D2Q9, D3Q15, D3Q19 (default), D3Q27
- collision operators: single-relaxation-time (SRT/BGK) (default), two-relaxation-time (TRT)
- [DDF-shifting](https://www.researchgate.net/publication/362275548_Accuracy_and_performance_of_the_lattice_Boltzmann_method_with_64-bit_32-bit_and_customized_16-bit_number_formats) and other algebraic optimization to minimize round-off error
- optimized to minimize VRAM footprint to 1/6 of other LBM codes
- traditional LBM (D3Q19) with FP64 requires ~344 Bytes/cell
- 🟧🟧🟧🟧🟧🟧🟧🟧🟦🟦🟦🟦🟦🟦🟦🟦🟦🟦🟦🟦🟦🟦🟦🟦🟦🟦🟦🟦🟦🟦🟦🟦🟨🟨🟨🟨🟨🟨🟨🟨🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥🟥
(density 🟧, velocity 🟦, flags 🟨, 2 copies of DDFs 🟩/🟥; each square = 1 Byte)
- allows for 3 Million cells per 1 GB VRAM
- FluidX3D (D3Q19) requires only 55 Bytes/cell with [Esoteric-Pull](https://doi.org/10.3390/computation10060092)+[FP16](https://www.researchgate.net/publication/362275548_Accuracy_and_performance_of_the_lattice_Boltzmann_method_with_64-bit_32-bit_and_customized_16-bit_number_formats)
- 🟧🟧🟧🟧🟦🟦🟦🟦🟦🟦🟦🟦🟦🟦🟦🟦🟨🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩🟩
(density 🟧, velocity 🟦, flags 🟨, DDFs 🟩; each square = 1 Byte)
- allows for 19 Million cells per 1 GB VRAM
- in-place streaming with [Esoteric-Pull](https://doi.org/10.3390/computation10060092): eliminates redundant copy of density distribution functions (DDFs) in memory; almost cuts memory demand in half and slightly increases performance due to implicit bounce-back boundaries; offers optimal memory access patterns for single-cell in-place streaming
- [decoupled arithmetic precision (FP32) and memory precision (FP32 or FP16S or FP16C)](https://www.researchgate.net/publication/362275548_Accuracy_and_performance_of_the_lattice_Boltzmann_method_with_64-bit_32-bit_and_customized_16-bit_number_formats): all arithmetic is done in FP32 for compatibility on all hardware, but DDFs in memory can be compressed to FP16S or FP16C: almost cuts memory demand in half again and almost doubles performance, without impacting overall accuracy for most setups
- only 8 flag bits per lattice point (can be used independently / at the same time)
- `TYPE_S` (stationary or moving) solid boundaries
- `TYPE_E` equilibrium boundaries (inflow/outflow)
- `TYPE_T` temperature boundaries
- `TYPE_F` free surface (fluid)
- `TYPE_I` free surface (interface)
- `TYPE_G` free surface (gas)
- `TYPE_X` remaining for custom use or further extensions
- `TYPE_Y` remaining for custom use or further extensions
- large cost saving: comparison of maximum single-GPU grid resolution for D3Q19 LBM
| GPU VRAM capacity | 1 GB | 2 GB | 3 GB | 4 GB | 6 GB | 8 GB | 10 GB | 11 GB | 12 GB | 16 GB | 20 GB | 24 GB | 32 GB | 40 GB | 48 GB | 64 GB | 80 GB | 94 GB | 128 GB | 192 GB | 256 GB |
| :------------------------------- | --------: | --------: | --------: | --------: | --------: | --------: | ---------: | ---------: | ---------: | ---------: | ---------: | ---------: | ---------: | ---------: | ---------: | ---------: | ---------: | ---------: | ----------: | ----------: | ----------: |
| approximate GPU price | $25
GT 210 | $25
GTX 950 | $12
GTX 1060 | $50
GT 730 | $35
GTX 1060 | $70
RX 470 | $500
RTX 3080 | $240
GTX 1080 Ti | $75
Tesla M40 | $75
Instinct MI25 | $900
RX 7900 XT | $205
Tesla P40 | $600
Instinct MI60 | $5500
A100 | $2400
RTX 8000 | $10k
Instinct MI210 | $11k
A100 | >$40k
H100 NVL | ?
GPU Max 1550 | ~$10k
MI300X | - |
| traditional LBM (FP64) | 144³ | 182³ | 208³ | 230³ | 262³ | 288³ | 312³ | 322³ | 330³ | 364³ | 392³ | 418³ | 460³ | 494³ | 526³ | 578³ | 624³ | 658³ | 730³ | 836³ | 920³ |
| FluidX3D (FP32/FP32) | 224³ | 282³ | 322³ | 354³ | 406³ | 448³ | 482³ | 498³ | 512³ | 564³ | 608³ | 646³ | 710³ | 766³ | 814³ | 896³ | 966³ | 1018³ | 1130³ | 1292³ | 1422³ |
| FluidX3D (FP32/FP16) | 266³ | 336³ | 384³ | 424³ | 484³ | 534³ | 574³ | 594³ | 610³ | 672³ | 724³ | 770³ | 848³ | 912³ | 970³ | 1068³ | 1150³ | 1214³ | 1346³ | 1540³ | 1624³ |
- cross-vendor multi-GPU support on a single computer/server
- domain decomposition allows pooling VRAM from multiple GPUs for much larger grid resolution
- GPUs don't have to be identical, not even from the same vendor - any combination of AMD+Intel+Nvidia GPUs will work - but similar VRAM capacity/bandwidth is recommended
- domain communication architecture (simplified)
```diff
++ .-----------------------------------------------------------------. ++
++ | GPU 0 | ++
++ | LBM Domain 0 | ++
++ '-----------------------------------------------------------------' ++
++ | selective /|\ ++
++ \|/ in-VRAM copy | ++
++ .-------------------------------------------------------. ++
++ | GPU 0 - Transfer Buffer 0 | ++
++ '-------------------------------------------------------' ++
!! | PCIe /|\ !!
!! \|/ copy | !!
@@ .-------------------------. .-------------------------. @@
@@ | CPU - Transfer Buffer 0 | | CPU - Transfer Buffer 1 | @@
@@ '-------------------------'\ /'-------------------------' @@
@@ pointer X swap @@
@@ .-------------------------./ \.-------------------------. @@
@@ | CPU - Transfer Buffer 1 | | CPU - Transfer Buffer 0 | @@
@@ '-------------------------' '-------------------------' @@
!! /|\ PCIe | !!
!! | copy \|/ !!
++ .-------------------------------------------------------. ++
++ | GPU 1 - Transfer Buffer 1 | ++
++ '-------------------------------------------------------' ++
++ /|\ selective | ++
++ | in-VRAM copy \|/ ++
++ .-----------------------------------------------------------------. ++
++ | GPU 1 | ++
++ | LBM Domain 1 | ++
++ '-----------------------------------------------------------------' ++
## | ##
## domain synchronization barrier ##
## | ##
|| -------------------------------------------------------------> time ||
```
- domain communication architecture (detailed)
```diff
++ .-----------------------------------------------------------------. ++
++ | GPU 0 | ++
++ | LBM Domain 0 | ++
++ '-----------------------------------------------------------------' ++
++ | selective in- /|\ | selective in- /|\ | selective in- /|\ ++
++ \|/ VRAM copy (X) | \|/ VRAM copy (Y) | \|/ VRAM copy (Z) | ++
++ .---------------------.---------------------.---------------------. ++
++ | GPU 0 - TB 0X+ | GPU 0 - TB 0Y+ | GPU 0 - TB 0Z+ | ++
++ | GPU 0 - TB 0X- | GPU 0 - TB 0Y- | GPU 0 - TB 0Z- | ++
++ '---------------------'---------------------'---------------------' ++
!! | PCIe /|\ | PCIe /|\ | PCIe /|\ !!
!! \|/ copy | \|/ copy | \|/ copy | !!
@@ .---------. .---------.---------. .---------.---------. .---------. @@
@@ | CPU 0X+ | | CPU 1X- | CPU 0Y+ | | CPU 3Y- | CPU 0Z+ | | CPU 5Z- | @@
@@ | CPU 0X- | | CPU 2X+ | CPU 0Y- | | CPU 4Y+ | CPU 0Z- | | CPU 6Z+ | @@
@@ '---------\ /---------'---------\ /---------'---------\ /---------' @@
@@ pointer X swap (X) pointer X swap (Y) pointer X swap (Z) @@
@@ .---------/ \---------.---------/ \---------.---------/ \---------. @@
@@ | CPU 1X- | | CPU 0X+ | CPU 3Y- | | CPU 0Y+ | CPU 5Z- | | CPU 0Z+ | @@
@@ | CPU 2X+ | | CPU 0X- | CPU 4Y+ | | CPU 0Y- | CPU 6Z+ | | CPU 0Z- | @@
@@ '---------' '---------'---------' '---------'---------' '---------' @@
!! /|\ PCIe | /|\ PCIe | /|\ PCIe | !!
!! | copy \|/ | copy \|/ | copy \|/ !!
++ .--------------------..---------------------..--------------------. ++
++ | GPU 1 - TB 1X- || GPU 3 - TB 3Y- || GPU 5 - TB 5Z- | ++
++ :====================::=====================::====================: ++
++ | GPU 2 - TB 2X+ || GPU 4 - TB 4Y+ || GPU 6 - TB 6Z+ | ++
++ '--------------------''---------------------''--------------------' ++
++ /|\ selective in- | /|\ selective in- | /|\ selective in- | ++
++ | VRAM copy (X) \|/ | VRAM copy (Y) \|/ | VRAM copy (Z) \|/ ++
++ .--------------------..---------------------..--------------------. ++
++ | GPU 1 || GPU 3 || GPU 5 | ++
++ | LBM Domain 1 || LBM Domain 3 || LBM Domain 5 | ++
++ :====================::=====================::====================: ++
++ | GPU 2 || GPU 4 || GPU 6 | ++
++ | LBM Domain 2 || LBM Domain 4 || LBM Domain 6 | ++
++ '--------------------''---------------------''--------------------' ++
## | | | ##
## | domain synchronization barriers | ##
## | | | ##
|| -------------------------------------------------------------> time ||
```
- peak performance on GPUs (datacenter/gaming/professional/laptop)
- [single-GPU/CPU benchmarks](#single-gpucpu-benchmarks)
- [multi-GPU benchmarks](#multi-gpu-benchmarks)
- [boundary types](https://doi.org/10.15495/EPub_UBT_00005400)
- stationary mid-grid bounce-back boundaries (stationary solid boundaries)
- moving mid-grid bounce-back boundaries (moving solid boundaries)
- equilibrium boundaries (non-reflective inflow/outflow)
- temperature boundaries (fixed temperature)
- global force per volume (Guo forcing), can be modified on-the-fly
- local force per volume (force field)
- optional computation of forces from the fluid on solid boundaries
- state-of-the-art [free surface LBM](https://doi.org/10.3390/computation10060092) (FSLBM) implementation:
- [volume-of-fluid model](https://doi.org/10.15495/EPub_UBT_00005400)
- [fully analytic PLIC](https://doi.org/10.3390/computation10020021) for efficient curvature calculation
- improved mass conservation
- ultra efficient implementation with only [4 kernels](https://doi.org/10.3390/computation10060092) additionally to `stream_collide()` kernel
- thermal LBM to simulate thermal convection
- D3Q7 subgrid for thermal DDFs
- in-place streaming with [Esoteric-Pull](https://doi.org/10.3390/computation10060092) for thermal DDFs
- optional [FP16S or FP16C compression](https://www.researchgate.net/publication/362275548_Accuracy_and_performance_of_the_lattice_Boltzmann_method_with_64-bit_32-bit_and_customized_16-bit_number_formats) for thermal DDFs with [DDF-shifting](https://www.researchgate.net/publication/362275548_Accuracy_and_performance_of_the_lattice_Boltzmann_method_with_64-bit_32-bit_and_customized_16-bit_number_formats)
- Smagorinsky-Lilly subgrid turbulence LES model to keep simulations with very large Reynolds number stable
Παβ = Σi eiα eiβ (fi - fieq-shifted)
Q = Σαβ Παβ2
______________________
τ = ½ (τ0 + √ τ02 + (16√2)∕(3π2) √Q∕ρ )
- particles with immersed-boundary method (either passive or 2-way-coupled, single-GPU only)
## Solving the Visualization Problem
- FluidX3D can do simulations so large that storing the volumetric data for later rendering becomes unmanageable (like 120GB for a single frame, hundreds of TeraByte for a video)
- instead, FluidX3D allows [rendering raw simulation data directly in VRAM](https://www.researchgate.net/publication/360501260_Combined_scientific_CFD_simulation_and_interactive_raytracing_with_OpenCL), so no large volumetric files have to be exported to the hard disk (see my [technical talk](https://youtu.be/pD8JWAZ2f8o))
- the rendering is so fast that it works interactively in real time for both rasterization and raytracing
- rasterization and raytracing are done in OpenCL and work on all GPUs, even the ones without RTX/DXR raytracing cores or without any rendering hardware at all (like A100, MI200, ...)
- if no monitor is available (like on a remote Linux server), there is an [ASCII rendering mode](https://youtu.be/pD8JWAZ2f8o&t=1456) to interactively visualize the simulation in the terminal (even in WSL and/or through SSH)
- rendering is fully multi-GPU-parallelized via seamless domain decomposition rasterization
- with interactive graphics mode disabled, image resolution can be as large as VRAM allows for (4K/8K/16K and above)
- (interacitive) visualization modes:
- flag wireframe / solid surface (and force vectors on solid cells or surface pressure if the extension is used)
- velocity field (with slice mode)
- streamlines (with slice mode)
- velocity-colored Q-criterion isosurface
- rasterized free surface with [marching-cubes](http://paulbourke.net/geometry/polygonise/)
- [raytraced free surface](https://www.researchgate.net/publication/360501260_Combined_scientific_CFD_simulation_and_interactive_raytracing_with_OpenCL) with fast ray-grid traversal and marching-cubes, either 1-4 rays/pixel or 1-10 rays/pixel
## Solving the Compatibility Problem
- FluidX3D is written in OpenCL 1.2, so it runs on all hardware from all vendors (Nvidia, AMD, Intel, ...):
- world's fastest datacenter GPUs: MI300X, H100 (NVL), A100, MI200, MI100, V100(S), GPU Max 1100, ...
- gaming GPUs (desktop/laptop): Nvidia GeForce, AMD Radeon, Intel Arc
- professional/workstation GPUs: Nvidia Quadro, AMD Radeon Pro / FirePro, Intel Arc Pro
- integrated GPUs
- CPUs (requires [installation of Intel CPU Runtime for OpenCL](DOCUMENTATION.md#0-install-gpu-drivers-and-opencl-runtime))
- Intel Xeon Phi (requires [installation of Intel CPU Runtime for OpenCL](DOCUMENTATION.md#0-install-gpu-drivers-and-opencl-runtime))
- smartphone ARM GPUs
- native cross-vendor multi-GPU implementation
- uses PCIe communication, so no SLI/Crossfire/NVLink/InfinityFabric required
- single-node parallelization, so no MPI installation required
- [GPUs don't even have to be from the same vendor](https://youtu.be/_8Ed8ET9gBU), but similar memory capacity and bandwidth are recommended
- works on [Windows](DOCUMENTATION.md#windows) and [Linux](DOCUMENTATION.md#linux--macos--android) with C++17, with limited support also for [macOS](DOCUMENTATION.md#linux--macos--android) and [Android](DOCUMENTATION.md#linux--macos--android)
- supports [importing and voxelizing triangle meshes](DOCUMENTATION.md#loading-stl-files) from binary `.stl` files, with fast GPU voxelization
- supports [exporting volumetric data](DOCUMENTATION.md#data-export) as binary `.vtk` files
- supports [exporting triangle meshes](DOCUMENTATION.md#data-export) as binary `.vtk` files
- supports [exporting rendered images](DOCUMENTATION.md#video-rendering) as `.png`/`.qoi`/`.bmp` files; encoding runs in parallel on the CPU while the simulation on GPU can continue without delay
## Single-GPU/CPU Benchmarks
Here are [performance benchmarks](https://doi.org/10.3390/computation10060092) on various hardware in MLUPs/s, or how many million lattice cells are updated per second. The settings used for the benchmark are D3Q19 SRT with no extensions enabled (only LBM with implicit mid-grid bounce-back boundaries) and the setup consists of an empty cubic box with sufficient size (typically 256³). Without extensions, a single lattice cell requires:
- a memory capacity of 93 (FP32/FP32) or 55 (FP32/FP16) Bytes
- a memory bandwidth of 153 (FP32/FP32) or 77 (FP32/FP16) Bytes per time step
- 363 (FP32/FP32) or 406 (FP32/FP16S) or 1275 (FP32/FP16C) FLOPs per time step (FP32+INT32 operations counted combined)
In consequence, the arithmetic intensity of this implementation is 2.37 (FP32/FP32) or 5.27 (FP32/FP16S) or 16.56 (FP32/FP16C) FLOPs/Byte. So performance is only limited by memory bandwidth. The table in the left 3 columns shows the hardware specs as found in the data sheets (theoretical peak FP32 compute performance, memory capacity, theoretical peak memory bandwidth). The right 3 columns show the measured FluidX3D performance for FP32/FP32, FP32/FP16S, FP32/FP16C floating-point precision settings, with the ([roofline model](https://en.wikipedia.org/wiki/Roofline_model) efficiency) in round brackets, indicating how much % of theoretical peak memory bandwidth are being used.
If your GPU/CPU is not on the list yet, you can report your benchmarks [here](https://github.com/ProjectPhysX/FluidX3D/issues/8).
```mermaid
gantt
title FluidX3D Performance [MLUPs/s] - FP32 arithmetic, (fastest of FP32/FP16S/FP16C) memory storage
dateFormat X
axisFormat %s
%%{
init: {
"gantt": {
'titleTopMargin': 42,
'topPadding': 70,
'leftPadding': 260,
'rightPadding': 5,
'sectionFontSize': 20,
'fontSize': 20,
'barHeight': 20,
'barGap': 3,
'numberSectionStyles': 2
},
'theme': 'forest',
'themeVariables': {
'sectionBkgColor': '#99999999',
'altSectionBkgColor': '#00000000',
'titleColor': '#AFAFAF',
'textColor': '#AFAFAF',
'taskTextColor': 'black',
'taskBorderColor': '#487E3A'
}
}
}%%
section MI300X
41327 :crit, 0, 41327
section MI250 (1 GCD)
9030 :crit, 0, 9030
section MI210
9547 :crit, 0, 9547
section MI100
8542 :crit, 0, 8542
section MI60
5111 :crit, 0, 5111
section MI50 32GB
8477 :crit, 0, 8477
section Radeon VII
7778 :crit, 0, 7778
section GPU Max 1100
6303 :done, 0, 6303
section GH200 94GB GPU
34689 : 0, 34689
section H100 NVL
32922 : 0, 32922
section H100 SXM5 80GB HBM3
29561 : 0, 29561
section H100 PCIe 80GB HBM2e
20624 : 0, 20624
section A100 SXM4 80GB
18448 : 0, 18448
section A100 PCIe 80GB
17896 : 0, 17896
section PG506-242/243
15654 : 0, 15654
section A100 SXM4 40GB
16013 : 0, 16013
section A100 PCIe 40GB
16035 : 0, 16035
section CMP 170HX
12392 : 0, 12392
section A30
9721 : 0, 9721
section V100 SXM2 32GB
8947 : 0, 8947
section V100 PCIe 16GB
10325 : 0, 10325
section GV100
6641 : 0, 6641
section Titan V
7253 : 0, 7253
section P100 PCIe 16GB
5950 : 0, 5950
section P100 PCIe 12GB
4141 : 0, 4141
section GTX TITAN
2500 : 0, 2500
section K40m
1868 : 0, 1868
section K80 (1 GPU)
1642 : 0, 1642
section K20c
1507 : 0, 1507
section RX 9070 XT
6688 :crit, 0, 6688
section RX 9070
6019 :crit, 0, 6019
section RX 7900 XTX
7716 :crit, 0, 7716
section PRO W7900
5939 :crit, 0, 5939
section RX 7900 XT
5986 :crit, 0, 5986
section RX 7800 XT
3105 :crit, 0, 3105
section PRO W7800
4426 :crit, 0, 4426
section RX 7900 GRE
4570 :crit, 0, 4570
section PRO W7700
2943 :crit, 0, 2943
section RX 7600
2561 :crit, 0, 2561
section PRO W7600
2287 :crit, 0, 2287
section PRO W7500
1682 :crit, 0, 1682
section RX 6900 XT
4227 :crit, 0, 4227
section RX 6800 XT
4241 :crit, 0, 4241
section PRO W6800
3361 :crit, 0, 3361
section RX 6700 XT
2908 :crit, 0, 2908
section RX 6800M
3213 :crit, 0, 3213
section RX 6700M
2429 :crit, 0, 2429
section RX 6600
1839 :crit, 0, 1839
section RX 6500 XT
1030 :crit, 0, 1030
section RX 5700 XT
3253 :crit, 0, 3253
section RX 5700
3167 :crit, 0, 3167
section RX 5600 XT
2214 :crit, 0, 2214
section RX Vega 64
3227 :crit, 0, 3227
section RX 590
1688 :crit, 0, 1688
section RX 580 4GB
1848 :crit, 0, 1848
section RX 580 2048SP 8GB
1622 :crit, 0, 1622
section R9 390X
2217 :crit, 0, 2217
section HD 7850
635 :crit, 0, 635
section Arc B580 LE
4979 :done, 0, 4979
section Arc A770 LE
4568 :done, 0, 4568
section Arc A750 LE
4314 :done, 0, 4314
section Arc A580
3889 :done, 0, 3889
section Arc Pro A40
985 :done, 0, 985
section Arc A380
1115 :done, 0, 1115
section RTX 5090
19141 : 0, 19141
section RTX 5080
10304 : 0, 10304
section RTX 5070
7238 : 0, 7238
section RTX 4090
11496 : 0, 11496
section RTX 6000 Ada
10293 : 0, 10293
section L40S
7637 : 0, 7637
section L40
7945 : 0, 7945
section RTX 4080 Super
8218 : 0, 8218
section RTX 4080
7933 : 0, 7933
section RTX 4070 Ti Super
7295 : 0, 7295
section RTX 4090M
6901 : 0, 6901
section RTX 4070 Super
5554 : 0, 5554
section RTX 4070
5016 : 0, 5016
section RTX 4080M
5114 : 0, 5114
section RTX 4000 Ada
4221 : 0, 4221
section RTX 4060
3124 : 0, 3124
section RTX 4070M
3092 : 0, 3092
section RTX 2000 Ada
2526 : 0, 2526
section RTX 3090 Ti
10956 : 0, 10956
section RTX 3090
10732 : 0, 10732
section RTX 3080 Ti
9832 : 0, 9832
section RTX 3080 12GB
9657 : 0, 9657
section RTX A6000
8814 : 0, 8814
section RTX 3080 10GB
8118 : 0, 8118
section RTX 3070 Ti
6807 : 0, 6807
section RTX 3080M Ti
5908 : 0, 5908
section RTX 3070
5096 : 0, 5096
section RTX 3060 Ti
5129 : 0, 5129
section RTX A4000
4945 : 0, 4945
section RTX A5000M
4461 : 0, 4461
section RTX 3060
4070 : 0, 4070
section RTX 3060M
4012 : 0, 4012
section A2
2051 : 0, 2051
section RTX 3050M Ti
2341 : 0, 2341
section RTX 3050M
2339 : 0, 2339
section Titan RTX
7554 : 0, 7554
section RTX 6000
6879 : 0, 6879
section RTX 8000 Passive
5607 : 0, 5607
section RTX 2080 Ti
6853 : 0, 6853
section RTX 2080 Super
5284 : 0, 5284
section RTX 5000
4773 : 0, 4773
section RTX 2080
4977 : 0, 4977
section RTX 2070 Super
4893 : 0, 4893
section RTX 2070
5017 : 0, 5017
section RTX 2060 Super
5035 : 0, 5035
section RTX 4000
4584 : 0, 4584
section RTX 2060 KO
3376 : 0, 3376
section RTX 2060
3604 : 0, 3604
section GTX 1660 Super
3551 : 0, 3551
section T4
2887 : 0, 2887
section GTX 1660 Ti
3041 : 0, 3041
section GTX 1660
1992 : 0, 1992
section GTX 1650M 896C
1858 : 0, 1858
section GTX 1650M 1024C
1400 : 0, 1400
section T500
665 : 0, 665
section Titan Xp
5495 : 0, 5495
section GTX 1080 Ti
4877 : 0, 4877
section GTX 1080
3182 : 0, 3182
section GTX 1060 6GB
1925 : 0, 1925
section GTX 1060M
1882 : 0, 1882
section GTX 1050M Ti
1224 : 0, 1224
section P1000
839 : 0, 839
section GTX 980 Ti
2703 : 0, 2703
section GTX 980
1965 : 0, 1965
section GTX 970
1721 : 0, 1721
section M4000
1519 : 0, 1519
section M60 (1 GPU)
1571 : 0, 1571
section GTX 960M
872 : 0, 872
section GTX 770
1215 : 0, 1215
section GTX 680 4GB
1274 : 0, 1274
section K2000
444 : 0, 444
section GT 630 (OEM)
185 : 0, 185
section NVS 290
9 : 0, 9
section Arise 1020
6 :active, 0, 6
section M2 Ultra (76-CU, 192GB)
8769 :active, 0, 8769
section M2 Max (38-CU, 32GB)
4641 :active, 0, 4641
section M1 Ultra (64-CU, 128GB)
8418 :active, 0, 8418
section M1 Max (24-CU, 32GB)
4496 :active, 0, 4496
section M1 Pro (16-CU, 16GB)
2329 :active, 0, 2329
section M1 (8-CU, 16GB)
759 :active, 0, 759
section Radeon 8060S (Max+ 395)
2563 :crit, 0, 2563
section Radeon 780M (Z1 Extreme)
860 :crit, 0, 860
section Radeon Graphics (7800X3D)
498 :crit, 0, 498
section Vega 8 (4750G)
511 :crit, 0, 511
section Vega 8 (3500U)
288 :crit, 0, 288
section Arc 140V GPU (16GB)
1282 :done, 0, 1282
section Arc Graphics (Ultra 9 185H)
724 :done, 0, 724
section Iris Xe Graphics (i7-1265U)
621 :done, 0, 621
section UHD Xe 32EUs
245 :done, 0, 245
section UHD 770
475 :done, 0, 475
section UHD 630
301 :done, 0, 301
section UHD P630
288 :done, 0, 288
section HD 5500
192 :done, 0, 192
section HD 4600
115 :done, 0, 115
section Orange Pi 5 Mali-G610 MP4
232 :active, 0, 232
section Samsung Mali-G72 MP18
230 :active, 0, 230
section 2x EPYC 9754
5179 :crit, 0, 5179
section 2x EPYC 9654
1814 :crit, 0, 1814
section 2x EPYC 9554
2552 :crit, 0, 2552
section 1x EPYC 9124
772 :crit, 0, 772
section 2x EPYC 7713
1418 :crit, 0, 1418
section 2x EPYC 7352
739 :crit, 0, 739
section 2x EPYC 7313
498 :crit, 0, 498
section 2x EPYC 7302
784 :crit, 0, 784
section 2x 6980P
7875 :done, 0, 7875
section 2x 6979P
8135 :done, 0, 8135
section 2x Platinum 8592+
3135 :done, 0, 3135
section 2x Gold 6548N
1811 :done, 0, 1811
section 2x CPU Max 9480
2037 :done, 0, 2037
section 2x Platinum 8480+
2162 :done, 0, 2162
section 2x Platinum 8470
2068 :done, 0, 2068
section 2x Gold 6438Y+
1945 :done, 0, 1945
section 2x Platinum 8380
1410 :done, 0, 1410
section 2x Platinum 8358
1285 :done, 0, 1285
section 2x Platinum 8256
396 :done, 0, 396
section 2x Platinum 8153
691 :done, 0, 691
section 2x Gold 6248R
755 :done, 0, 755
section 2x Gold 6128
254 :done, 0, 254
section Phi 7210
415 :done, 0, 415
section 4x E5-4620 v4
460 :done, 0, 460
section 2x E5-2630 v4
264 :done, 0, 264
section 2x E5-2623 v4
125 :done, 0, 125
section 2x E5-2680 v3
304 :done, 0, 304
section GH200 Neoverse-V2
1323 : 0, 1323
section TR PRO 7995WX
1715 :crit, 0, 1715
section TR 3970X
463 :crit, 0, 463
section TR 1950X
273 :crit, 0, 273
section Ryzen 7900X3D
521 :crit, 0, 521
section Ryzen 7800X3D
363 :crit, 0, 363
section Ryzen 5700X3D
229 :crit, 0, 229
section FX-6100
22 :crit, 0, 22
section Athlon X2 QL-65
3 :crit, 0, 3
section Ultra 7 258V
287 :done, 0, 287
section Ultra 9 185H
317 :done, 0, 317
section i9-14900K
490 :done, 0, 490
section i7-13700K
504 :done, 0, 504
section i7-1265U
128 :done, 0, 128
section i9-11900KB
208 :done, 0, 208
section i9-10980XE
286 :done, 0, 286
section E-2288G
198 :done, 0, 198
section i7-9700
103 :done, 0, 103
section i5-9600
147 :done, 0, 147
section i7-8700K
152 :done, 0, 152
section E-2176G
201 :done, 0, 201
section i7-7700HQ
108 :done, 0, 108
section E3-1240 v5
141 :done, 0, 141
section i5-5300U
37 :done, 0, 37
section i7-4770
104 :done, 0, 104
section i7-4720HQ
80 :done, 0, 80
section N2807
7 :done, 0, 7
```
Single-GPU/CPU Benchmark Table
Colors: 🔴 AMD, 🔵 Intel, 🟢 Nvidia, ⚪ Apple, 🟡 ARM, 🟤 Glenfly
| Device | FP32
[TFlops/s] | Mem
[GB] | BW
[GB/s] | FP32/FP32
[MLUPs/s] | FP32/FP16S
[MLUPs/s] | FP32/FP16C
[MLUPs/s] |
| :----------------------------------------------- | -----------------: | ----------: | -----------: | ---------------------: | ----------------------: | ----------------------: |
| | | | | | | |
| 🔴 Instinct MI300X | 163.40 | 192 | 5300 | 22867 (66%) | 41327 (60%) | 31670 (46%) |
| 🔴 Instinct MI250 (1 GCD) | 45.26 | 64 | 1638 | 5638 (53%) | 9030 (42%) | 8506 (40%) |
| 🔴 Instinct MI210 | 45.26 | 64 | 1638 | 6517 (61%) | 9547 (45%) | 8829 (41%) |
| 🔴 Instinct MI100 | 46.14 | 32 | 1228 | 5093 (63%) | 8133 (51%) | 8542 (54%) |
| 🔴 Instinct MI60 | 14.75 | 32 | 1024 | 3570 (53%) | 5047 (38%) | 5111 (38%) |
| 🔴 Instinct MI50 32GB | 13.25 | 32 | 1024 | 4446 (66%) | 8477 (64%) | 4406 (33%) |
| 🔴 Radeon VII | 13.83 | 16 | 1024 | 4898 (73%) | 7778 (58%) | 5256 (40%) |
| 🔵 Data Center GPU Max 1100 | 22.22 | 48 | 1229 | 3769 (47%) | 6303 (39%) | 3520 (22%) |
| 🟢 GH200 94GB GPU | 66.91 | 94 | 4000 | 20595 (79%) | 34689 (67%) | 19407 (37%) |
| 🟢 H100 NVL | 60.32 | 94 | 3938 | 20303 (79%) | 32922 (64%) | 18424 (36%) |
| 🟢 H100 SXM5 80GB HBM3 | 66.91 | 80 | 3350 | 17602 (80%) | 29561 (68%) | 20227 (46%) |
| 🟢 H100 PCIe 80GB HBM2e | 51.01 | 80 | 2000 | 11128 (85%) | 20624 (79%) | 13862 (53%) |
| 🟢 A100 SXM4 80GB | 19.49 | 80 | 2039 | 10228 (77%) | 18448 (70%) | 11197 (42%) |
| 🟢 A100 PCIe 80GB | 19.49 | 80 | 1935 | 9657 (76%) | 17896 (71%) | 10817 (43%) |
| 🟢 PG506-243 / PG506-242 | 22.14 | 64 | 1638 | 8195 (77%) | 15654 (74%) | 12271 (58%) |
| 🟢 A100 SXM4 40GB | 19.49 | 40 | 1555 | 8522 (84%) | 16013 (79%) | 11251 (56%) |
| 🟢 A100 PCIe 40GB | 19.49 | 40 | 1555 | 8526 (84%) | 16035 (79%) | 11088 (55%) |
| 🟢 CMP 170HX | 6.32 | 8 | 1493 | 7684 (79%) | 12392 (64%) | 6859 (35%) |
| 🟢 A30 | 10.32 | 24 | 933 | 5004 (82%) | 9721 (80%) | 5726 (47%) |
| 🟢 Tesla V100 SXM2 32GB | 15.67 | 32 | 900 | 4471 (76%) | 8947 (77%) | 7217 (62%) |
| 🟢 Tesla V100 PCIe 16GB | 14.13 | 16 | 900 | 5128 (87%) | 10325 (88%) | 7683 (66%) |
| 🟢 Quadro GV100 | 16.66 | 32 | 870 | 3442 (61%) | 6641 (59%) | 5863 (52%) |
| 🟢 Titan V | 14.90 | 12 | 653 | 3601 (84%) | 7253 (86%) | 6957 (82%) |
| 🟢 Tesla P100 16GB | 9.52 | 16 | 732 | 3295 (69%) | 5950 (63%) | 4176 (44%) |
| 🟢 Tesla P100 12GB | 9.52 | 12 | 549 | 2427 (68%) | 4141 (58%) | 3999 (56%) |
| 🟢 GeForce GTX TITAN | 4.71 | 6 | 288 | 1460 (77%) | 2500 (67%) | 1113 (30%) |
| 🟢 Tesla K40m | 4.29 | 12 | 288 | 1131 (60%) | 1868 (50%) | 912 (24%) |
| 🟢 Tesla K80 (1 GPU) | 4.11 | 12 | 240 | 916 (58%) | 1642 (53%) | 943 (30%) |
| 🟢 Tesla K20c | 3.52 | 5 | 208 | 861 (63%) | 1507 (56%) | 720 (27%) |
| | | | | | | |
| 🔴 Radeon RX 9070 XT | 48.66 | 16 | 640 | 3089 (74%) | 6688 (80%) | 6090 (73%) |
| 🔴 Radeon RX 9070 | 36.13 | 16 | 640 | 3007 (72%) | 5746 (69%) | 6019 (72%) |
| 🔴 Radeon RX 7900 XTX | 61.44 | 24 | 960 | 3665 (58%) | 7644 (61%) | 7716 (62%) |
| 🔴 Radeon PRO W7900 | 61.30 | 48 | 864 | 3107 (55%) | 5939 (53%) | 5780 (52%) |
| 🔴 Radeon RX 7900 XT | 51.61 | 20 | 800 | 3013 (58%) | 5856 (56%) | 5986 (58%) |
| 🔴 Radeon RX 7800 XT | 37.32 | 16 | 624 | 1704 (42%) | 3105 (38%) | 3061 (38%) |
| 🔴 Radeon PRO W7800 | 45.20 | 32 | 576 | 1872 (50%) | 4426 (59%) | 4145 (55%) |
| 🔴 Radeon RX 7900 GRE | 42.03 | 16 | 576 | 1996 (53%) | 4570 (61%) | 4463 (60%) |
| 🔴 Radeon PRO W7700 | 28.30 | 16 | 576 | 1547 (41%) | 2943 (39%) | 2899 (39%) |
| 🔴 Radeon RX 7600 | 21.75 | 8 | 288 | 1250 (66%) | 2561 (68%) | 2512 (67%) |
| 🔴 Radeon PRO W7600 | 20.00 | 8 | 288 | 1179 (63%) | 2263 (61%) | 2287 (61%) |
| 🔴 Radeon PRO W7500 | 12.20 | 8 | 172 | 856 (76%) | 1630 (73%) | 1682 (75%) |
| 🔴 Radeon RX 6900 XT | 23.04 | 16 | 512 | 1968 (59%) | 4227 (64%) | 4207 (63%) |
| 🔴 Radeon RX 6800 XT | 20.74 | 16 | 512 | 2008 (60%) | 4241 (64%) | 4224 (64%) |
| 🔴 Radeon PRO W6800 | 17.83 | 32 | 512 | 1620 (48%) | 3361 (51%) | 3180 (48%) |
| 🔴 Radeon RX 6700 XT | 13.21 | 12 | 384 | 1408 (56%) | 2883 (58%) | 2908 (58%) |
| 🔴 Radeon RX 6800M | 11.78 | 12 | 384 | 1439 (57%) | 3190 (64%) | 3213 (64%) |
| 🔴 Radeon RX 6700M | 10.60 | 10 | 320 | 1194 (57%) | 2388 (57%) | 2429 (58%) |
| 🔴 Radeon RX 6600 | 8.93 | 8 | 224 | 963 (66%) | 1817 (62%) | 1839 (63%) |
| 🔴 Radeon RX 6500 XT | 5.77 | 4 | 144 | 459 (49%) | 1011 (54%) | 1030 (55%) |
| 🔴 Radeon RX 5700 XT | 9.75 | 8 | 448 | 1368 (47%) | 3253 (56%) | 3049 (52%) |
| 🔴 Radeon RX 5700 | 7.72 | 8 | 448 | 1521 (52%) | 3167 (54%) | 2758 (47%) |
| 🔴 Radeon RX 5600 XT | 6.73 | 6 | 288 | 1136 (60%) | 2214 (59%) | 2148 (57%) |
| 🔴 Radeon RX Vega 64 | 13.35 | 8 | 484 | 1875 (59%) | 2878 (46%) | 3227 (51%) |
| 🔴 Radeon RX 590 | 5.53 | 8 | 256 | 1257 (75%) | 1573 (47%) | 1688 (51%) |
| 🔴 Radeon RX 580 4GB | 6.50 | 4 | 256 | 946 (57%) | 1848 (56%) | 1577 (47%) |
| 🔴 Radeon RX 580 2048SP 8GB | 4.94 | 8 | 224 | 868 (59%) | 1622 (56%) | 1240 (43%) |
| 🔴 Radeon R9 390X | 5.91 | 8 | 384 | 1733 (69%) | 2217 (44%) | 1722 (35%) |
| 🔴 Radeon HD 7850 | 1.84 | 2 | 154 | 112 (11%) | 120 ( 6%) | 635 (32%) |
| 🔵 Arc B580 LE | 14.59 | 12 | 456 | 2598 (87%) | 4443 (75%) | 4979 (84%) |
| 🔵 Arc A770 LE | 19.66 | 16 | 560 | 2663 (73%) | 4568 (63%) | 4519 (62%) |
| 🔵 Arc A750 LE | 17.20 | 8 | 512 | 2555 (76%) | 4314 (65%) | 4047 (61%) |
| 🔵 Arc A580 | 12.29 | 8 | 512 | 2534 (76%) | 3889 (58%) | 3488 (52%) |
| 🔵 Arc Pro A40 | 5.02 | 6 | 192 | 594 (47%) | 985 (40%) | 927 (37%) |
| 🔵 Arc A380 | 4.20 | 6 | 186 | 622 (51%) | 1097 (45%) | 1115 (46%) |
| 🟢 GeForce RTX 5090 | 104.88 | 32 | 1792 | 9522 (81%) | 18459 (79%) | 19141 (82%) |
| 🟢 GeForce RTX 5080 | 56.34 | 16 | 960 | 5174 (82%) | 10252 (82%) | 10304 (83%) |
| 🟢 GeForce RTX 5070 | 30.84 | 12 | 672 | 3658 (83%) | 7238 (83%) | 7107 (81%) |
| 🟢 GeForce RTX 4090 | 82.58 | 24 | 1008 | 5624 (85%) | 11091 (85%) | 11496 (88%) |
| 🟢 RTX 6000 Ada | 91.10 | 48 | 960 | 4997 (80%) | 10249 (82%) | 10293 (83%) |
| 🟢 L40S | 91.61 | 48 | 864 | 3788 (67%) | 7637 (68%) | 7617 (68%) |
| 🟢 L40 | 90.52 | 48 | 864 | 3870 (69%) | 7778 (69%) | 7945 (71%) |
| 🟢 GeForce RTX 4080 Super | 52.22 | 16 | 736 | 4089 (85%) | 7660 (80%) | 8218 (86%) |
| 🟢 GeForce RTX 4080 | 55.45 | 16 | 717 | 3914 (84%) | 7626 (82%) | 7933 (85%) |
| 🟢 GeForce RTX 4070 Ti Super | 44.10 | 16 | 672 | 3694 (84%) | 6435 (74%) | 7295 (84%) |
| 🟢 GeForce RTX 4090M | 28.31 | 16 | 576 | 3367 (89%) | 6545 (87%) | 6901 (92%) |
| 🟢 GeForce RTX 4070 Super | 35.55 | 12 | 504 | 2751 (83%) | 5149 (79%) | 5554 (85%) |
| 🟢 GeForce RTX 4070 | 29.15 | 12 | 504 | 2646 (80%) | 4548 (69%) | 5016 (77%) |
| 🟢 GeForce RTX 4080M | 33.85 | 12 | 432 | 2577 (91%) | 5086 (91%) | 5114 (91%) |
| 🟢 RTX 4000 Ada | 26.73 | 20 | 360 | 2130 (91%) | 3964 (85%) | 4221 (90%) |
| 🟢 GeForce RTX 4060 | 15.11 | 8 | 272 | 1614 (91%) | 3052 (86%) | 3124 (88%) |
| 🟢 GeForce RTX 4070M | 18.25 | 8 | 256 | 1553 (93%) | 2945 (89%) | 3092 (93%) |
| 🟢 RTX 2000 Ada | 12.00 | 16 | 224 | 1351 (92%) | 2452 (84%) | 2526 (87%) |
| 🟢 GeForce RTX 3090 Ti | 40.00 | 24 | 1008 | 5717 (87%) | 10956 (84%) | 10400 (79%) |
| 🟢 GeForce RTX 3090 | 39.05 | 24 | 936 | 5418 (89%) | 10732 (88%) | 10215 (84%) |
| 🟢 GeForce RTX 3080 Ti | 37.17 | 12 | 912 | 5202 (87%) | 9832 (87%) | 9347 (79%) |
| 🟢 GeForce RTX 3080 12GB | 32.26 | 12 | 912 | 5071 (85%) | 9657 (81%) | 8615 (73%) |
| 🟢 RTX A6000 | 40.00 | 48 | 768 | 4421 (88%) | 8814 (88%) | 8533 (86%) |
| 🟢 GeForce RTX 3080 10GB | 29.77 | 10 | 760 | 4230 (85%) | 8118 (82%) | 7714 (78%) |
| 🟢 GeForce RTX 3070 Ti | 21.75 | 8 | 608 | 3490 (88%) | 6807 (86%) | 5926 (75%) |
| 🟢 GeForce RTX 3080M Ti | 23.61 | 16 | 512 | 2985 (89%) | 5908 (89%) | 5780 (87%) |
| 🟢 GeForce RTX 3070 | 20.31 | 8 | 448 | 2578 (88%) | 5096 (88%) | 5060 (87%) |
| 🟢 GeForce RTX 3060 Ti | 16.49 | 8 | 448 | 2644 (90%) | 5129 (88%) | 4718 (81%) |
| 🟢 RTX A4000 | 19.17 | 16 | 448 | 2500 (85%) | 4945 (85%) | 4664 (80%) |
| 🟢 RTX A5000M | 16.59 | 16 | 448 | 2228 (76%) | 4461 (77%) | 3662 (63%) |
| 🟢 GeForce RTX 3060 | 13.17 | 12 | 360 | 2108 (90%) | 4070 (87%) | 3566 (76%) |
| 🟢 GeForce RTX 3060M | 10.94 | 6 | 336 | 2019 (92%) | 4012 (92%) | 3572 (82%) |
| 🟢 A2 | 4.53 | 15 | 200 | 1031 (79%) | 2051 (79%) | 1199 (46%) |
| 🟢 GeForce RTX 3050M Ti | 7.60 | 4 | 192 | 1181 (94%) | 2341 (94%) | 2253 (90%) |
| 🟢 GeForce RTX 3050M | 7.13 | 4 | 192 | 1180 (94%) | 2339 (94%) | 2016 (81%) |
| 🟢 Titan RTX | 16.31 | 24 | 672 | 3471 (79%) | 7456 (85%) | 7554 (87%) |
| 🟢 Quadro RTX 6000 | 16.31 | 24 | 672 | 3307 (75%) | 6836 (78%) | 6879 (79%) |
| 🟢 Quadro RTX 8000 Passive | 14.93 | 48 | 624 | 2591 (64%) | 5408 (67%) | 5607 (69%) |
| 🟢 GeForce RTX 2080 Ti | 13.45 | 11 | 616 | 3194 (79%) | 6700 (84%) | 6853 (86%) |
| 🟢 GeForce RTX 2080 Super | 11.34 | 8 | 496 | 2434 (75%) | 5284 (82%) | 5087 (79%) |
| 🟢 Quadro RTX 5000 | 11.15 | 16 | 448 | 2341 (80%) | 4766 (82%) | 4773 (82%) |
| 🟢 GeForce RTX 2080 | 10.07 | 8 | 448 | 2318 (79%) | 4977 (86%) | 4963 (85%) |
| 🟢 GeForce RTX 2070 Super | 9.22 | 8 | 448 | 2255 (77%) | 4866 (84%) | 4893 (84%) |
| 🟢 GeForce RTX 2070 | 7.47 | 8 | 448 | 2444 (83%) | 4387 (75%) | 5017 (86%) |
| 🟢 GeForce RTX 2060 Super | 7.18 | 8 | 448 | 2503 (85%) | 5035 (87%) | 4463 (77%) |
| 🟢 Quadro RTX 4000 | 7.12 | 8 | 416 | 2284 (84%) | 4584 (85%) | 4062 (75%) |
| 🟢 GeForce RTX 2060 KO | 6.74 | 6 | 336 | 1643 (75%) | 3376 (77%) | 3266 (75%) |
| 🟢 GeForce RTX 2060 | 6.74 | 6 | 336 | 1681 (77%) | 3604 (83%) | 3571 (82%) |
| 🟢 GeForce GTX 1660 Super | 5.03 | 6 | 336 | 1696 (77%) | 3551 (81%) | 3040 (70%) |
| 🟢 Tesla T4 | 8.14 | 15 | 300 | 1356 (69%) | 2869 (74%) | 2887 (74%) |
| 🟢 GeForce GTX 1660 Ti | 5.48 | 6 | 288 | 1467 (78%) | 3041 (81%) | 3019 (81%) |
| 🟢 GeForce GTX 1660 | 5.07 | 6 | 192 | 1016 (81%) | 1924 (77%) | 1992 (80%) |
| 🟢 GeForce GTX 1650M 896C | 2.72 | 4 | 192 | 963 (77%) | 1836 (74%) | 1858 (75%) |
| 🟢 GeForce GTX 1650M 1024C | 3.20 | 4 | 128 | 706 (84%) | 1214 (73%) | 1400 (84%) |
| 🟢 T500 | 3.04 | 4 | 80 | 339 (65%) | 578 (56%) | 665 (64%) |
| 🟢 Titan Xp | 12.15 | 12 | 548 | 2919 (82%) | 5495 (77%) | 5375 (76%) |
| 🟢 GeForce GTX 1080 Ti | 12.06 | 11 | 484 | 2631 (83%) | 4837 (77%) | 4877 (78%) |
| 🟢 GeForce GTX 1080 | 9.78 | 8 | 320 | 1623 (78%) | 3100 (75%) | 3182 (77%) |
| 🟢 GeForce GTX 1060 6GB | 4.57 | 6 | 192 | 997 (79%) | 1925 (77%) | 1785 (72%) |
| 🟢 GeForce GTX 1060M | 4.44 | 6 | 192 | 983 (78%) | 1882 (75%) | 1803 (72%) |
| 🟢 GeForce GTX 1050M Ti | 2.49 | 4 | 112 | 631 (86%) | 1224 (84%) | 1115 (77%) |
| 🟢 Quadro P1000 | 1.89 | 4 | 82 | 426 (79%) | 839 (79%) | 778 (73%) |
| 🟢 GeForce GTX 980 Ti | 6.05 | 6 | 336 | 1509 (69%) | 2703 (62%) | 2381 (55%) |
| 🟢 GeForce GTX 980 | 4.98 | 4 | 224 | 1018 (70%) | 1965 (68%) | 1872 (64%) |
| 🟢 GeForce GTX 970 | 4.17 | 4 | 224 | 980 (67%) | 1721 (59%) | 1623 (56%) |
| 🟢 Quadro M4000 | 2.57 | 8 | 192 | 899 (72%) | 1519 (61%) | 1050 (42%) |
| 🟢 Tesla M60 (1 GPU) | 4.82 | 8 | 160 | 853 (82%) | 1571 (76%) | 1557 (75%) |
| 🟢 GeForce GTX 960M | 1.51 | 4 | 80 | 442 (84%) | 872 (84%) | 627 (60%) |
| 🟢 GeForce GTX 770 | 3.33 | 2 | 224 | 800 (55%) | 1215 (42%) | 876 (30%) |
| 🟢 GeForce GTX 680 4GB | 3.33 | 4 | 192 | 783 (62%) | 1274 (51%) | 814 (33%) |
| 🟢 Quadro K2000 | 0.73 | 2 | 64 | 312 (75%) | 444 (53%) | 171 (21%) |
| 🟢 GeForce GT 630 (OEM) | 0.46 | 2 | 29 | 151 (81%) | 185 (50%) | 78 (21%) |
| 🟢 Quadro NVS 290 | 0.03 | 1/4 | 6 | 9 (22%) | 4 ( 5%) | 4 ( 5%) |
| 🟤 Arise 1020 | 1.50 | 2 | 19 | 6 ( 5%) | 6 ( 2%) | 6 ( 2%) |
| | | | | | | |
| ⚪ M2 Ultra GPU 76CU 192GB | 19.46 | 147 | 800 | 4629 (89%) | 8769 (84%) | 7972 (77%) |
| ⚪ M2 Max GPU 38CU 32GB | 9.73 | 22 | 400 | 2405 (92%) | 4641 (89%) | 2444 (47%) |
| ⚪ M1 Ultra GPU 64CU 128GB | 16.38 | 98 | 800 | 4519 (86%) | 8418 (81%) | 6915 (67%) |
| ⚪ M1 Max GPU 24CU 32GB | 6.14 | 22 | 400 | 2369 (91%) | 4496 (87%) | 2777 (53%) |
| ⚪ M1 Pro GPU 16CU 16GB | 4.10 | 11 | 200 | 1204 (92%) | 2329 (90%) | 1855 (71%) |
| ⚪ M1 GPU 8CU 16GB | 2.05 | 11 | 68 | 384 (86%) | 758 (85%) | 759 (86%) |
| 🔴 Radeon 8060S Graphics (Max+ 395)) | 29.70 | 15 | 256 | 1231 (74%) | 2541 (76%) | 2563 (77%) |
| 🔴 Radeon 780M (Z1 Extreme) | 8.29 | 8 | 102 | 443 (66%) | 860 (65%) | 820 (62%) |
| 🔴 Radeon Graphics (7800X3D) | 0.56 | 12 | 102 | 338 (51%) | 498 (37%) | 283 (21%) |
| 🔴 Radeon Vega 8 (4750G) | 2.15 | 27 | 57 | 263 (71%) | 511 (70%) | 501 (68%) |
| 🔴 Radeon Vega 8 (3500U) | 1.23 | 7 | 38 | 157 (63%) | 282 (57%) | 288 (58%) |
| 🔵 Arc 140V GPU (16GB) | 3.99 | 16 | 137 | 636 (71%) | 1282 (72%) | 773 (44%) |
| 🔵 Arc Graphics (Ultra 9 185H) | 4.81 | 14 | 90 | 271 (46%) | 710 (61%) | 724 (62%) |
| 🔵 Iris Xe Graphics (i7-1265U) | 1.92 | 13 | 77 | 342 (68%) | 621 (62%) | 574 (58%) |
| 🔵 UHD Graphics Xe 32EUs | 0.74 | 25 | 51 | 128 (38%) | 245 (37%) | 216 (32%) |
| 🔵 UHD Graphics 770 | 0.82 | 30 | 90 | 342 (58%) | 475 (41%) | 278 (24%) |
| 🔵 UHD Graphics 630 | 0.46 | 7 | 51 | 151 (45%) | 301 (45%) | 187 (28%) |
| 🔵 UHD Graphics P630 | 0.46 | 51 | 42 | 177 (65%) | 288 (53%) | 137 (25%) |
| 🔵 HD Graphics 5500 | 0.35 | 3 | 26 | 75 (45%) | 192 (58%) | 108 (32%) |
| 🔵 HD Graphics 4600 | 0.38 | 2 | 26 | 105 (63%) | 115 (35%) | 34 (10%) |
| 🟡 Mali-G610 MP4 (Orange Pi 5) | 0.06 | 16 | 34 | 130 (58%) | 232 (52%) | 93 (21%) |
| 🟡 Mali-G72 MP18 (Samsung S9+) | 0.24 | 4 | 29 | 110 (59%) | 230 (62%) | 21 ( 6%) |
| | | | | | | |
| 🔴 2x EPYC 9754 | 50.79 | 3072 | 922 | 3276 (54%) | 5077 (42%) | 5179 (43%) |
| 🔴 2x EPYC 9654 | 43.62 | 1536 | 922 | 1381 (23%) | 1814 (15%) | 1801 (15%) |
| 🔴 2x EPYC 9554 | 30.72 | 384 | 922 | 2552 (42%) | 2127 (18%) | 2144 (18%) |
| 🔴 1x EPYC 9124 | 3.69 | 128 | 307 | 772 (38%) | 579 (15%) | 586 (15%) |
| 🔴 2x EPYC 7713 | 8.19 | 512 | 410 | 1298 (48%) | 492 ( 9%) | 1418 (27%) |
| 🔴 2x EPYC 7352 | 3.53 | 512 | 410 | 739 (28%) | 106 ( 2%) | 412 ( 8%) |
| 🔴 2x EPYC 7313 | 3.07 | 128 | 410 | 498 (19%) | 367 ( 7%) | 418 ( 8%) |
| 🔴 2x EPYC 7302 | 3.07 | 128 | 410 | 784 (29%) | 336 ( 6%) | 411 ( 8%) |
| 🔵 2x Xeon 6980P | 98.30 | 6144 | 1690 | 7875 (71%) | 5112 (23%) | 5610 (26%) |
| 🔵 2x Xeon 6979P | 92.16 | 3072 | 1690 | 8135 (74%) | 4175 (19%) | 4622 (21%) |
| 🔵 2x Xeon Platinum 8592+ | 31.13 | 1024 | 717 | 3135 (67%) | 2359 (25%) | 2466 (26%) |
| 🔵 2x Xeon Gold 6548N | 22.94 | 2048 | 666 | 1811 (42%) | 1388 (16%) | 1425 (16%) |
| 🔵 2x Xeon CPU Max 9480 | 27.24 | 256 | 614 | 2037 (51%) | 1520 (19%) | 1464 (18%) |
| 🔵 2x Xeon Platinum 8480+ | 28.67 | 512 | 614 | 2162 (54%) | 1845 (23%) | 1884 (24%) |
| 🔵 2x Xeon Platinum 8470 | 25.29 | 2048 | 614 | 1865 (46%) | 1909 (24%) | 2068 (26%) |
| 🔵 2x Xeon Gold 6438Y+ | 16.38 | 1024 | 614 | 1945 (48%) | 1219 (15%) | 1257 (16%) |
| 🔵 2x Xeon Platinum 8380 | 23.55 | 2048 | 410 | 1410 (53%) | 1159 (22%) | 1298 (24%) |
| 🔵 2x Xeon Platinum 8358 | 21.30 | 256 | 410 | 1285 (48%) | 1007 (19%) | 1120 (21%) |
| 🔵 2x Xeon Platinum 8256 | 3.89 | 1536 | 282 | 396 (22%) | 158 ( 4%) | 175 ( 5%) |
| 🔵 2x Xeon Platinum 8153 | 8.19 | 384 | 256 | 691 (41%) | 290 ( 9%) | 328 (10%) |
| 🔵 2x Xeon Gold 6248R | 18.43 | 384 | 282 | 755 (41%) | 566 (15%) | 694 (19%) |
| 🔵 2x Xeon Gold 6128 | 5.22 | 192 | 256 | 254 (15%) | 185 ( 6%) | 193 ( 6%) |
| 🔵 Xeon Phi 7210 | 5.32 | 192 | 102 | 415 (62%) | 193 (15%) | 223 (17%) |
| 🔵 4x Xeon E5-4620 v4 | 2.69 | 512 | 273 | 460 (26%) | 275 ( 8%) | 239 ( 7%) |
| 🔵 2x Xeon E5-2630 v4 | 1.41 | 64 | 137 | 264 (30%) | 146 ( 8%) | 129 ( 7%) |
| 🔵 2x Xeon E5-2623 v4 | 0.67 | 64 | 137 | 125 (14%) | 66 ( 4%) | 59 ( 3%) |
| 🔵 2x Xeon E5-2680 v3 | 1.92 | 128 | 137 | 304 (34%) | 234 (13%) | 291 (16%) |
| 🟢 GH200 Neoverse-V2 CPU | 7.88 | 480 | 384 | 1323 (53%) | 853 (17%) | 683 (14%) |
| 🔴 Threadripper PRO 7995WX | 15.36 | 256 | 333 | 1134 (52%) | 1697 (39%) | 1715 (40%) |
| 🔴 Threadripper 3970X | 3.79 | 128 | 102 | 376 (56%) | 103 ( 8%) | 463 (35%) |
| 🔴 Threadripper 1950X | 0.87 | 128 | 85 | 273 (49%) | 43 ( 4%) | 151 (14%) |
| 🔴 Ryzen 9 7900X3D | 1.69 | 128 | 83 | 278 (51%) | 521 (48%) | 462 (43%) |
| 🔴 Ryzen 7 7800X3D | 1.08 | 32 | 102 | 296 (44%) | 361 (27%) | 363 (27%) |
| 🔴 Ryzen 7 5700X3D | 0.87 | 32 | 51 | 229 (68%) | 135 (20%) | 173 (26%) |
| 🔴 FX-6100 | 0.16 | 16 | 26 | 11 ( 7%) | 11 ( 3%) | 22 ( 7%) |
| 🔴 Athlon X2 QL-65 | 0.03 | 4 | 11 | 3 ( 4%) | 2 ( 2%) | 3 ( 2%) |
| 🔵 Core Ultra 7 258V | 0.56 | 32 | 137 | 287 (32%) | 123 ( 7%) | 167 ( 9%) |
| 🔵 Core Ultra 9 185H | 1.79 | 16 | 90 | 317 (54%) | 267 (23%) | 288 (25%) |
| 🔵 Core i9-14900K | 3.74 | 32 | 96 | 443 (71%) | 453 (36%) | 490 (39%) |
| 🔵 Core i7-13700K | 2.51 | 64 | 90 | 504 (86%) | 398 (34%) | 424 (36%) |
| 🔵 Core i7-1265U | 1.23 | 32 | 77 | 128 (26%) | 62 ( 6%) | 58 ( 6%) |
| 🔵 Core i9-11900KB | 0.84 | 32 | 51 | 109 (33%) | 195 (29%) | 208 (31%) |
| 🔵 Core i9-10980XE | 3.23 | 128 | 94 | 286 (47%) | 251 (21%) | 223 (18%) |
| 🔵 Xeon E-2288G | 0.95 | 32 | 43 | 196 (70%) | 182 (33%) | 198 (36%) |
| 🔵 Core i7-9700 | 0.77 | 64 | 43 | 103 (37%) | 62 (11%) | 95 (17%) |
| 🔵 Core i5-9600 | 0.60 | 16 | 43 | 146 (52%) | 127 (23%) | 147 (27%) |
| 🔵 Core i7-8700K | 0.71 | 16 | 51 | 152 (45%) | 134 (20%) | 116 (17%) |
| 🔵 Xeon E-2176G | 0.71 | 64 | 42 | 201 (74%) | 136 (25%) | 148 (27%) |
| 🔵 Core i7-7700HQ | 0.36 | 12 | 38 | 81 (32%) | 82 (16%) | 108 (22%) |
| 🔵 Xeon E3-1240 v5 | 0.50 | 32 | 34 | 141 (63%) | 75 (17%) | 88 (20%) |
| 🔵 Core i7-4770 | 0.44 | 16 | 26 | 104 (62%) | 69 (21%) | 59 (18%) |
| 🔵 Core i7-4720HQ | 0.33 | 16 | 26 | 80 (48%) | 23 ( 7%) | 60 (18%) |
| 🔵 Celeron N2807 | 0.01 | 4 | 11 | 7 (10%) | 3 ( 2%) | 3 ( 2%) |
## Multi-GPU Benchmarks
Multi-GPU benchmarks are done at the largest possible grid resolution with cubic domains, and either 2x1x1, 2x2x1 or 2x2x2 of these domains together. The (percentages in round brackets) are single-GPU [roofline model](https://en.wikipedia.org/wiki/Roofline_model) efficiency, and the (multiplicators in round brackets) are scaling factors relative to benchmarked single-GPU performance.
```mermaid
gantt
title FluidX3D Performance [MLUPs/s] - FP32 arithmetic, (fastest of FP32/FP16S/FP16C) memory storage
dateFormat X
axisFormat %s
%%{