https://github.com/pseudotensor/temporal_autoencoder
Temporal Autoencoder Project
https://github.com/pseudotensor/temporal_autoencoder
Last synced: 9 months ago
JSON representation
Temporal Autoencoder Project
- Host: GitHub
- URL: https://github.com/pseudotensor/temporal_autoencoder
- Owner: pseudotensor
- License: gpl-3.0
- Created: 2017-01-29T21:19:18.000Z (over 9 years ago)
- Default Branch: master
- Last Pushed: 2017-03-11T03:49:34.000Z (about 9 years ago)
- Last Synced: 2025-07-10T16:31:20.900Z (11 months ago)
- Language: Python
- Size: 130 KB
- Stars: 5
- Watchers: 3
- Forks: 1
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
## What: Temporal Autoencoder for Predicting Video
## How: Tensorflow version of CNN to LSTM to uCNN
## Why:
# Inspired by papers:
http://www.jmlr.org/proceedings/papers/v2/sutskever07a/sutskever07a.pdf
https://arxiv.org/abs/1411.4389
https://arxiv.org/abs/1504.08023
https://arxiv.org/abs/1506.04214 (like this paper with RNN but now with LSTM)
https://arxiv.org/abs/1511.06380
https://arxiv.org/abs/1511.05440
https://arxiv.org/abs/1605.08104
http://file.scirp.org/pdf/AM20100400007_46529567.pdf
https://arxiv.org/abs/1607.03597
http://web.mit.edu/vondrick/tinyvideoa
https://arxiv.org/abs/1605.07157
https://arxiv.org/abs/1502.04681
https://arxiv.org/abs/1605.07157
http://www.ri.cmu.edu/pub_files/2014/3/egpaper_final.pdf
# Uses parts of (or inspired by) the following repos:
https://github.com/tensorflow/models/blob/master/real_nvp/real_nvp_utils.py
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/rnn/python/ops/core_rnn_cell_impl.py
https://github.com/machrisaa/tensorflow-vgg
https://github.com/loliverhennigh/
https://coxlab.github.io/prednet/
https://github.com/tensorflow/models/tree/master/video_prediction
https://github.com/yoonkim/lstm-char-cnn
https://github.com/anayebi/keras-extra
https://github.com/tgjeon/TensorFlow-Tutorials-for-Time-Series
https://github.com/jtoy/awesome-tensorflow
https://github.com/aymericdamien/TensorFlow-Examples
# Inspired by the following articles:
http://spectrum.ieee.org/automaton/robotics/artificial-intelligence/deep-learning-ai-listens-to-machines-for-signs-of-trouble?adbsc=social_20170124_69611636&adbid=823956941219053569&adbpl=tw&adbpr=740238495952736256
http://www.theverge.com/2016/8/4/12369494/descartes-artificial-intelligence-crop-predictions-usda
https://devblogs.nvidia.com/parallelforall/exploring-spacenet-dataset-using-digits/
# And inspired to a lesser extent the following papers:
https://arxiv.org/abs/1508.01211
https://arxiv.org/abs/1507.08750
https://arxiv.org/abs/1505.00295
www.ijcsi.org/papers/IJCSI-8-4-1-139-148.pdf
cs231n.stanford.edu/reports2016/223_Report.pdf
# Program Requirements:
* Tensorflow 0.12
* Python 2.7
* OpenCV
# Post-Processing requirements
* avconv, mencoder, MP4Box,smplayer
# How to run:
python main.py
# Post-processing: making model vs. predicted video:
sh mergemov.sh
smplayer out_all.mp4
or
smplayer out_all2_fast.mp4
# Some training results:
* Balls, slow movie: [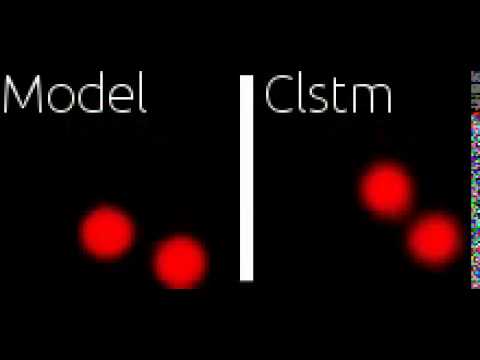](https://www.youtube.com/watch?v=xQdaaYogRMM)
* Balls, fast movie: [](https://www.youtube.com/watch?v=wxxD4sDUEfg)
* Training Curve in Tensorflow (norm order 80): 
* Wheel, slow movie: [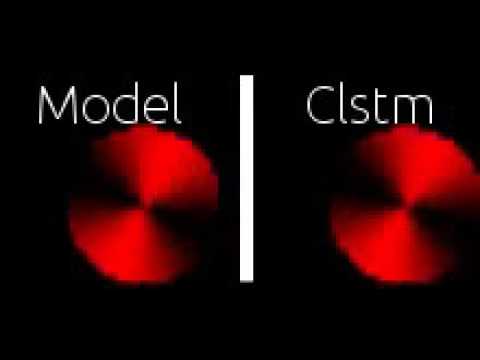](https://www.youtube.com/watch?v=8IsqTFnZ_1w)
* Wheel, fast movie: [](https://www.youtube.com/watch?v=lABUOLzCp-k)
* Training Curve in Tensorflow (norm order 40): 
# Parameters:
1) In main.py:
* Choose global flags
* In main():
* Choose to use checkpoints (if exist) or not: continuetrain
* type of model: modeltype
* number of balls: num_balls
2) In balls.py:
* SIZE: size of ball's bounding box in pixels
# Ideas and Future Work:
* Test on other models
* Try more filters
* Try temporal convolution
* Try other LSTM architectures (C-peek, bind forget-recall, GRU, etc.)
* Try adversarial loss:
https://github.com/carpedm20/DCGAN-tensorflow
http://blog.aylien.com/introduction-generative-adversarial-networks-code-tensorflow/
http://blog.aylien.com/introduction-generative-adversarial-networks-code-tensorflow/
http://blog.aylien.com/introduction-generative-adversarial-networks-code-tensorflow/
http://blog.aylien.com/introduction-generative-adversarial-networks-code-tensorflow/ (pytorch)
http://blog.aylien.com/introduction-generative-adversarial-networks-code-tensorflow/
https://arxiv.org/pdf/1511.05644v2.pdf
* Try more depth in time
* Train with geodesic acceleration (can't be done in python in tensorflow)
* Try homogenous LSTM/CNN architecture
* Include depth in CNN even if not explicitly 3D data, to avoid issues
with overlapping pixel space causing diffusion
* Estimate velocity field in rgb, to avoid collisions most likely state as
averaging to no motion due to L2 error's treatment of two possible
states.
* Use entropy generation rate to train attention where can best predict.
* Try rotation, faces, and ultimately real video.