Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/pszczesnowicz/SDC-P12-Semantic-Segmentation
https://github.com/pszczesnowicz/SDC-P12-Semantic-Segmentation
Last synced: 5 days ago
JSON representation
- Host: GitHub
- URL: https://github.com/pszczesnowicz/SDC-P12-Semantic-Segmentation
- Owner: pszczesnowicz
- Created: 2017-10-13T10:27:16.000Z (about 7 years ago)
- Default Branch: master
- Last Pushed: 2017-11-06T12:25:07.000Z (about 7 years ago)
- Last Synced: 2024-08-02T12:44:49.932Z (3 months ago)
- Language: Python
- Size: 43.8 MB
- Stars: 1
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
- awesome-starred - pszczesnowicz/SDC-P12-Semantic-Segmentation - (others)
README
This is my submission for the Udacity Self-Driving Car Nanodegree Semantic Segmentation Project. The goal of this project was to build a Fully Convolutional Network (FCN) that could label the individual pixels of an image as road or not road. The FCN was trained on the [KITTI Road Dataset](http://www.cvlibs.net/datasets/kitti/eval_road.php).
## Fully Convolutional Network Architecture
My network was based on the FCN-8 architecture (right) that was built using the VGG network (left).
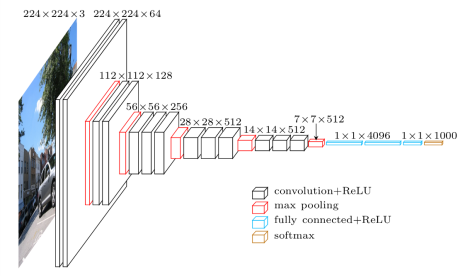
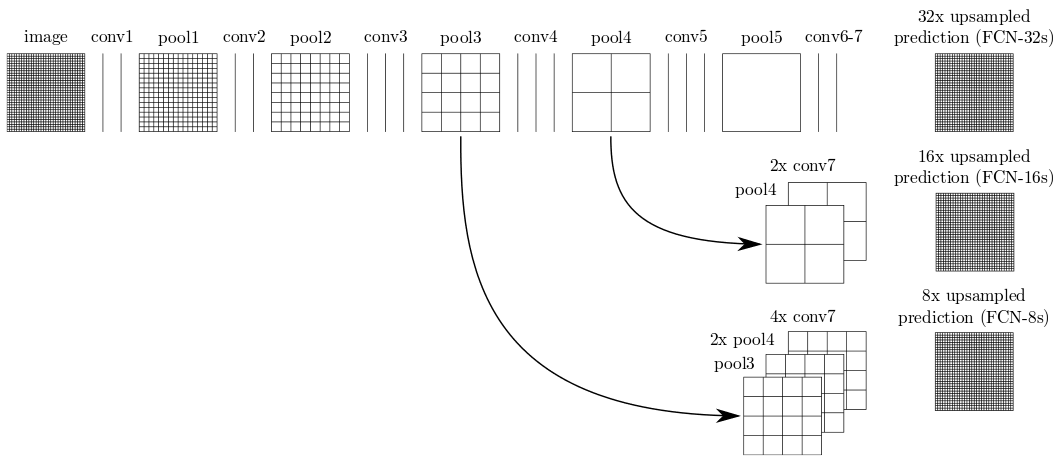
The encoder portion of the network consists of the convolution and pooling layers of the VGG network with the final two fully connected layers replaced with 1x1 convolutions to prevent the complete loss of spatial information. The decoder portion of the network consists of 1x1 convolution, upsampling, and summation layers.
The 1x1 convolution layers reduce the encoder's output depth from 4096 to the number of classes that the network is trained to recognize. The upsampling layers increase the encoder's output spatial dimensions from 7x7 to the original input image dimensions. The summation layers add together the upsampling and pooling layers. The pooling layers are from upstream of the encoder output and therefore contain more spatial information which improves the network's inference accuracy.
## Parameters and Hyperparameters
My network was trained to recognize two classes: road and not road. The final network was trained for 10 epochs using a batch size of 4.
A [truncated normal initializer](https://www.tensorflow.org/api_docs/python/tf/truncated_normal_initializer) with a standard deviation of 1e-2 was used to initialize the kernel weights. A [random normal initializer](https://www.tensorflow.org/api_docs/python/tf/random_normal_initializer) was also tested but yielded worse performance. The kernel biases were initialized using the default [zeros initializer](https://www.tensorflow.org/api_docs/python/tf/zeros_initializer). To help prevent overfitting the kernel weights were regularized using an [L2 regularizer](https://www.tensorflow.org/api_docs/python/tf/contrib/layers/l2_regularizer) with a scale of 1e-3 and the network was trained using dropout with a keep probability of 0.5.
The [Adam optimizer](https://www.tensorflow.org/api_docs/python/tf/train/AdamOptimizer) default learning rate of 1e-3 was used throughout training on different parameters and hyperparameters. A random search was employed for the Adam optimizer beta 1, beta 2, and epsilon hyperparameters:
```
beta1s = np.random.uniform(0, 1, 3)
beta2s = np.random.uniform(0, 1, 3)
epsilons = np.random.uniform(1e-8, 1, 3)
```
The network was trained for 4 epochs during the random hyperparameter search. Unfortunately, the best performing hyperparameters (based on loss and inference quality) from the random search yielded worse results than the defaults when trained again for 10 epochs. The following are the final network's parameters and hyperparameters:
| (Hyper)Parameter | Value |
| --------------------------------- |--------:|
| Number of classes | 2 |
| Epochs | 10 |
| Batch size | 4 |
| Initialization standard deviation | 1e-2 |
| Regularization scale | 1e-3 |
| Dropout keep probability | 0.5 |
| Adam learning rate | 1e-3 |
| Adam beta 1 | 0.9 |
| Adam beta 2 | 0.999 |
| Adam epsilon | 1e-8 |
## Data Augmentation
The training dataset consists of only 289 images (left) and corresponding ground truth images (right).


This is a rather small dataset and may cause overfitting. I created additional data by horizontally flipping the images to double the size of the training dataset.
## Results
As can be seen below, the FCN is able to distinguish the road from other elements in the image. Unfortunately it is not able to separate the oncoming and correct lanes and makes some incorrect classifications to the left of the railroad tracks.

## Conclusion
I plan on returning to this project to improve its performance by further increasing the training dataset and better parameter and hyperparameter settings. I also plan on implementing a better performance metric to help select the optimal settings.
## References
[Udacity Self-Driving Car ND](http://www.udacity.com/drive)
[Udacity Self-Driving Car ND - Semantic Segmentation Project](https://github.com/udacity/CarND-Semantic-Segmentation)
[Very Deep Convolutional Networks for Large-Scale Image Recognition](https://arxiv.org/pdf/1409.1556.pdf)
[Fully Convolutional Networks for Semantic Segmentation](https://arxiv.org/pdf/1411.4038.pdf)