https://github.com/pth1993/NNVLP
NNVLP - A Neural Network-Based Vietnamese Language Processing Toolkit
https://github.com/pth1993/NNVLP
Last synced: 22 days ago
JSON representation
NNVLP - A Neural Network-Based Vietnamese Language Processing Toolkit
- Host: GitHub
- URL: https://github.com/pth1993/NNVLP
- Owner: pth1993
- Created: 2017-09-20T09:49:49.000Z (over 7 years ago)
- Default Branch: master
- Last Pushed: 2017-09-22T00:27:40.000Z (over 7 years ago)
- Last Synced: 2024-11-16T17:40:55.472Z (7 months ago)
- Language: Python
- Size: 17.9 MB
- Stars: 40
- Watchers: 6
- Forks: 20
- Open Issues: 1
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
- awesome-vietnamese-language - Xử lý tiếng Việt bằng phương pháp Neural Network
README
# NNVLP - A Neural Network-Based Vietnamese Language Processing Toolkit
-----------------------------------------------------------------
Code by **Thai-Hoang Pham** at Alt Inc. (Utilize some code at a [repository](https://github.com/XuezheMax/LasagneNLP))
A demo website is available at [nnvlp.org](http://nnvlp.org)
## 1. Introduction
**NNVLP** is a Python implementation of the system described in a paper [NNVLP: A Neural Network-Based Vietnamese
Language Processing Toolkit](https://arxiv.org/abs/1708.07241).
This system is used for some common sequence labeling tasks for Vietnamese including part-of-speech (POS) tagging,
chunking, named entity recognition (NER).
The architecture of this system is the combination of bi-directional Long Short-Term Memory (Bi-LSTM),
Conditional Random Field (CRF), and word embeddings that is the concatenation of pre-trained word embeddings learnt
from skip-gram model and character-level word features learnt from Convolutional Neural Network (CNN).
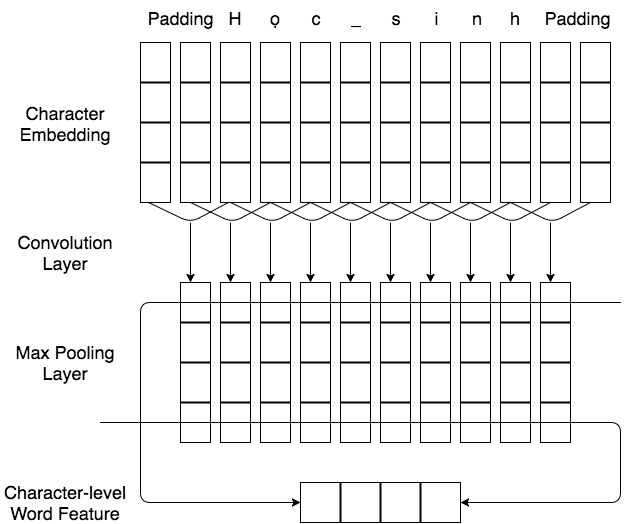
Figure 1: The CNN layer for extracting character-level word features of word Học_sinh (Student).
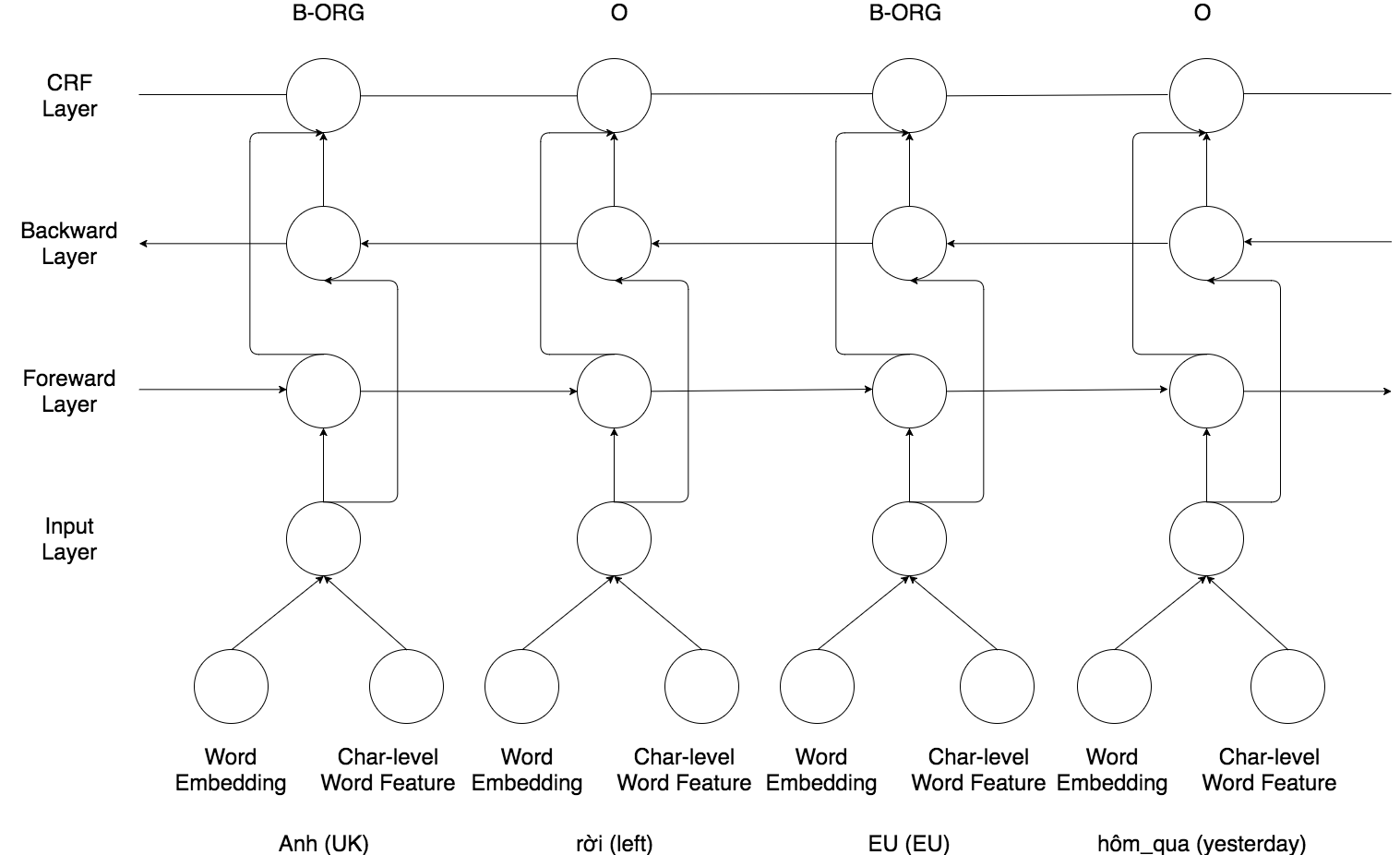
Figure 2: The Bi-LSTM-CRF layers for input sentence Anh rời EU hôm qua (UK left EU yesterday).
Our system achieves an accuracy of 91.92%, F1 scores of 84.11% and 92.91% for POS tagging, chunking, and NER tasks
respectively.
The following tables compare the performance of **NNVLP** and other previous toolkit on POS tagging, chunking, and NER
task respectively.
### POS tagging
| System | Accuracy |
|--------------|----------|
| Vitk | 88.41 |
| vTools | 90.73 |
| RDRPOSTagger | 91.96 |
| NNVLP | **91.92** |
### Chunking
| System | P | R | F1 |
|--------|-------|-------|-------|
| vTools | 82.79 | 83.55 | 83.17 |
| NNVLP | 83.93 | 84.28 | **84.11** |
### NER
| System | P | R | F1 |
|--------------|-------|-------|-------|
| Vitk | 88.36 | 89.20 | 88.78 |
| vie-ner-lstm | 91.09 | 93.03 | 92.05 |
| NNVLP | 92.76 | 93.07 | **92.91** |
## 2. Installation
This software depends on Numpy, Theano, and Lasagne. You must have them installed before using **NNVLP**.
The simple way to install them is using pip:
```sh
$ pip install -U numpy theano lasagne
```
## 3. Usage
### 3.1. Data
The input data's format of **NNVLP** follows CoNLL format. The corpus of POS tagging task consists of two columns
namely word, and POS tag. For chunking task, there are three columns namely word, POS tag, and chunk in the corpus.
The corpus of NER task consists of four columns. The order of these columns are word, POS tag, chunk, and named entity.
The table below describes an example Vietnamese sentence in NER corpus.
| Word | POS | Chunk | NER |
|-----------|-----|-------|-------|
| Từ | E | B-PP | O |
| Singapore | NNP | B-NP | B-LOC |
| , | CH | O | O |
| chỉ | R | O | O |
| khoảng | N | B-NP | O |
| vài | L | B-NP | O |
| chục | M | B-NP | O |
| phút | Nu | B-NP | O |
| ngồi | V | B-VP | O |
| phà | N | B-NP | O |
| là | V | B-VP | O |
| dến | V | B-VP | O |
| được | R | O | O |
| Batam | NNP | B-NP | B-LOC |
| . | CH | O | O |
To access the full dataset of VLSP, you need to sign the user agreement of the VLSP consortium.
### 3.2. Command-line Usage
You can use NNVLP software by shell commands:
For POS tagging:
```sh
$ bash pos.sh
```
For chunking:
```sh
$ bash chunk.sh
```
For NER:
```sh
$ bash ner.sh
```
Arguments in these scripts:
* ``train_dir``: path for training data
* ``dev_dir``: path for development data
* ``test_dir``: path for testing data
* ``word_dir``: path for word dictionary
* ``vector_dir``: path for vector dictionary
* ``char_embedd_dim``: character embedding dimension
* ``num_units``: number of hidden units for LSTM
* ``num_filters``: number of filters for CNN
* ``grad_clipping``: grad clipping
* ``peepholes``: peepholes (True or False)
* ``learning_rate``: learning rate
* ``decay_rate``: decay rate
* ``dropout``: dropout for input data (True or False)
* ``batch_size``: size of input batch for training this system.
* ``patience``: number used for early stopping in training stage
**Note**: In the first time of running **NNVLP**, this system will automatically download word embeddings for
Vietnamese from the internet. (It may take a long time because a size of this embedding set is about 1 GB). If the
system cannot automatically download this embedding set, you can manually download it from here
([vector](https://drive.google.com/open?id=0BytHkPDTyLo9WU93NEI1bGhmYmc),
[unknown vector](https://drive.google.com/open?id=0BytHkPDTyLo9VVlld1VlVVVoSHM),
[word](https://drive.google.com/open?id=0BytHkPDTyLo9SC1mRXpkbWhfUDA)) and put it into **embedding** directory.
## 4. References
[Thai-Hoang Pham, Xuan-Khoai Pham, Tuan-Anh Nguyen, Phuong Le-Hong, "NNVLP: A Neural Network-Based Vietnamese Language
Processing Toolkit" Proceedings of The 8th International Joint Conference on Natural Language Processing (IJCNLP 2017)](https://arxiv.org/abs/1708.07241)
```
@inproceedings{Pham:2017b,
title={NNVLP: A Neural Network-Based Vietnamese Language Processing Toolkit},
author={Thai-Hoang Pham and Xuan-Khoai Pham and Tuan-Anh Nguyen and Phuong Le-Hong},
booktitle={Proceedings of The 8th International Joint Conference on Natural Language Processing},
year={2017},
}
```
[Thai-Hoang Pham, Phuong Le-Hong, "End-to-end Recurrent Neural Network Models for Vietnamese Named Entity Recognition:
Word-level vs. Character-level" Proceedings of The 15th International Conference of the Pacific Association for
Computational Linguistics (PACLING 2017)](https://arxiv.org/abs/1705.04044)
```
@inproceedings{Pham:2017a,
title={End-to-end Recurrent Neural Network Models for Vietnamese Named Entity Recognition: Word-level vs. Character-level},
author={Thai-Hoang Pham and Phuong Le-Hong},
booktitle={Proceedings of The 15th International Conference of the Pacific Association for Computational Linguistics},
year={2017},
}
```
## 5. Contact
**Thai-Hoang Pham** < [email protected] >
Alt Inc, Hanoi, Vietnam