https://github.com/pyrustic/paradict
Streamable multi-format serialization with schema
https://github.com/pyrustic/paradict
binary configfile multiformat schema serialization streaming textual
Last synced: 4 months ago
JSON representation
Streamable multi-format serialization with schema
- Host: GitHub
- URL: https://github.com/pyrustic/paradict
- Owner: pyrustic
- License: mit
- Created: 2023-06-17T14:27:15.000Z (over 2 years ago)
- Default Branch: master
- Last Pushed: 2024-09-15T12:05:33.000Z (about 1 year ago)
- Last Synced: 2024-09-15T13:45:28.593Z (about 1 year ago)
- Topics: binary, configfile, multiformat, schema, serialization, streaming, textual
- Language: Python
- Homepage:
- Size: 316 KB
- Stars: 22
- Watchers: 3
- Forks: 1
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
[](https://opensource.org/licenses/MIT)
[](https://pypi.org/project/paradict)
[](https://pepy.tech/project/paradict)
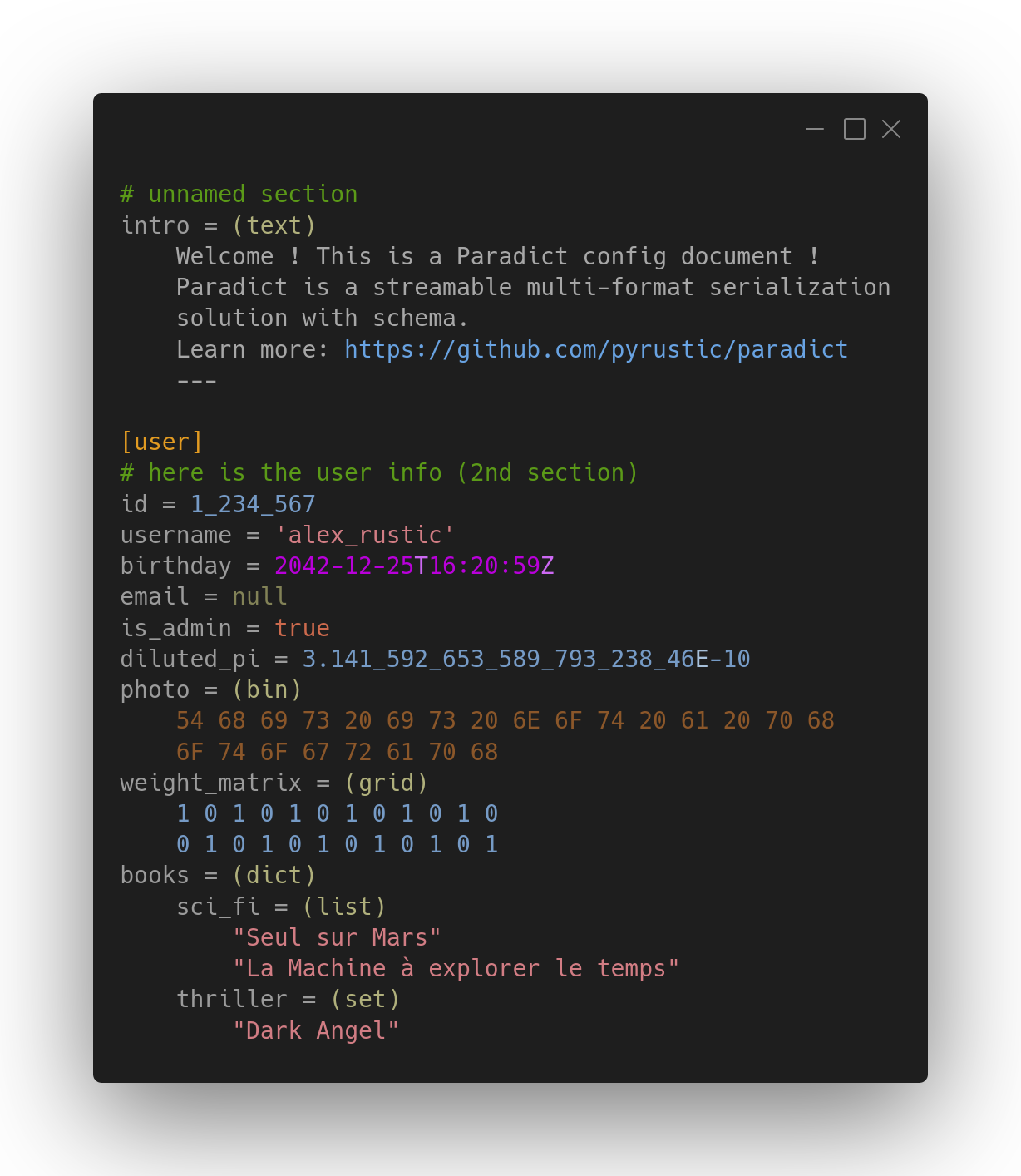
A Braq document with sections containing Paradict-encoded data
# Paradict
Streamable multi-format serialization with schema
## Table of contents
- [Overview](#overview)
- [Paradict textual format: Why not JSON, YAML, or TOML ?](#paradict-textual-format-why-not-json-yaml-or-toml-)
- [Paradict binary format: Why not Protobuf, MessagePack, or CBOR ?](#paradict-binary-format-why-not-protobuf-messagepack-or-cbor-)
- [Code snippets for everyday scenarios](#code-snippets-for-everyday-scenarios)
- [Paradict datatypes](#paradict-datatypes)
- [Data format specification](#data-format-specification)
- [Application programming interface](#application-programming-interface)
- [Textual serialization](#textual-serialization)
- [Binary serialization](#binary-serialization)
- [Type customization](#type-customization)
- [Continuous data stream processing](#continuous-data-stream-processing)
- [Paradict schema for data validation](#paradict-schema-for-data-validation)
- [Attachments](#attachments)
- [Miscellaneous](#miscellaneous)
- [Testing and contributing](#testing-and-contributing)
- [Installation](#installation)
# Overview
**Paradict** is a multi-format [serialization](https://en.wikipedia.org/wiki/Serialization) solution for serializing and deserializing a [dictionary](https://en.wikipedia.org/wiki/Associative_array) data structure in bulk or in a streaming fashion.
It comes with a data validation mechanism as well as other cool stuff, and its eponymous reference library is a [Python](https://www.python.org/) package available on [PyPI](#installation).
> Read the **backstory** in this [HN discussion](https://news.ycombinator.com/item?id=38684724) !
## Transparently used by Braq for config files, AI prompts, and more
Paradict is used by the Braq data format for mixing structured data with prose in the same document
> Discover [Braq](https://github.com/pyrustic/braq) !
## A rich set of datatypes
A Paradict dictionary can be populated with strings, binary data, integers, floats, complex numbers, booleans, dates, times, [datetimes](https://en.wikipedia.org/wiki/ISO_8601), comments, extension objects, and grids (matrices).
Although Paradict's root data structure is a dictionary, lists, sets, and dictionaries can be nested within it at arbitrary depth.
## An extension mechanism
Paradict has an extension mechanism that works with two components:
- **extension object**: dictionary-based structures defined in Paradict data (in textual or binary format).
- **object builder**: Python callable (passed to deserializer) that takes an extension object as input, consumes its contents, builds and returns a new Python object.
## A multi-format solution
Paradict offers binary and textual representations for a compatible arbitrary dictionary data structure.
The human-readable format has two modes, a **data-mode** for bidirectional mapping to binary format, and a **config-mode**, with lighter syntax, suitable for [configuration files](https://en.wikipedia.org/wiki/Configuration_file).
## A validation mechanism
Data validation is performed against a schema which is itself just another dictionary. The schema can be defined in a file with an arbitrary data format (Paradict, JSON, etc.) or programmatically.
Basically, a schema describes the expected keys in the target dictionary and the expected data types of their values. When defined programmatically, the schema allows the programmer to validate the target dictionary with arbitrary rules by incorporating checker [callbacks](https://en.wikipedia.org/wiki/Callback_(computer_programming)).
## An intuitive API
The library [API](https://en.wikipedia.org/wiki/API) is designed to be simple to understand, intuitive and powerful. There are four fundamental classes: `Encoder`, `Decoder`, `Packer`, and `Unpacker`, which serialize and deserialize data iteratively.
On top of these classes, four functions namely `encode`, `decode`, `pack`, and `unpack` do the same thing but in bulk.
Then there are additional classes and functions to perform various tasks such as `TypeRef` class for customizing types, `load`, and `dump` functions for reading and writing Paradict binary files, etc.
## And more...
There's more to say about Paradict that can't fit in this Overview section.
In the following sections, we'll dig deeper into Paradict, but first, why not [JSON](https://en.wikipedia.org/wiki/JSON), [YAML](https://fr.wikipedia.org/wiki/YAML), [TOML](https://en.wikipedia.org/wiki/TOML), [Protobuf](https://en.wikipedia.org/wiki/Protocol_Buffers), [MessagePack](https://en.wikipedia.org/wiki/MessagePack), or [CBOR](https://en.wikipedia.org/wiki/CBOR) ?
# Paradict textual format: Why not JSON, YAML, or TOML ?
With its textual format, Paradict is de-facto alternative to [JSON](https://en.wikipedia.org/wiki/JSON), [YAML](https://fr.wikipedia.org/wiki/YAML), and [TOML](https://en.wikipedia.org/wiki/TOML). Although these three formats are all human-readable, they serve different purposes.
For example, TOML is specifically designed for configuration files while JSON is used as a data interchange format.
Having two modes (**data-mode** and **config-mode**) for its textual format makes Paradict an interesting solution that targets the different purposes of JSON, YAML, and TOML.
Paradict, while offering a binary representation of its textual format, does also reject complexity and ambiguity as it can be found on YAML, has a great extension mechanism and a rich set of datatypes.
# Paradict binary format: Why not Protobuf, MessagePack, or CBOR ?
With its binary format, Paradict is de-facto alternative to [Protobuf](https://en.wikipedia.org/wiki/Protocol_Buffers), [MessagePack](https://en.wikipedia.org/wiki/MessagePack), and [CBOR](https://en.wikipedia.org/wiki/CBOR). However, choosing a binary format requires careful consideration as its strengths and weaknesses are not as readily discernible as in the case of a textual format.
Therefore, this section can be expected to offer comprehensive benchmarking and comparison details on different serialization solutions.
Nonetheless, given the potential bias of benchmarking toward a desired outcome, let us only point out that, unlike others, Paradict provides bidirectional mapping between its textual and binary formats.
> The surge in [LLM](https://en.wikipedia.org/wiki/Large_language_model) adoption is a reminder that people value advanced machine interfaces and intuitive data representation, despite extra compute costs.
# Code snippets for everyday scenarios
Following are working code snippets for everyday scenarios.
## Binary representation of data
**Pack and unpack:**
```python
from paradict import pack, unpack
my_dict = {0: 42}
# serialize my_dict
bin_data = pack(my_dict)
# test
assert my_dict == unpack(bin_data)
```
**Read and write a file:**
```python
from datetime import datetime
from paradict import load, dump
path = "/home/alex/test/user_card.bin"
user_card = {"name": "alex", "id": 42, "group": "admin",
"birthday": datetime(2020, 1, 1, 4, 20, 59)}
# serialize user_card then dump it into the file
dump(user_card, path)
# deserialize user_card from the file
data = load(path)
# test
assert user_card == data
```
The code snippet above will serialize the `user_card` dictionary then dump it into the `user_card.bin` file. The file would contain 43 bytes as following:
```python
from paradict import stringify_bin
path = "/home/alex/test/user_card.bin"
with open(path, "rb") as file:
data = file.read()
print(stringify_bin(data))
```
Output:
```text
\x01\x44\x6e\x61\x6d\x65\x44\x61\x6c\x65\x78\x42\x69\x64\xc5\x45\x67\x72\x6f\x75\x70\x45\x61\x64\x6d\x69\x6e\x48\x62\x69\x72\x74\x68\x64\x61\x79\x18\x9b\x2e\x2b\x3d\xa4\xff
```
## Textual representation of data
**Encode and decode:**
```python
from paradict import encode, decode
my_dict = {0: 42}
# serialize my_dict
txt_data = encode(my_dict)
# test
assert my_dict == decode(txt_data)
```
## Working with config files
> Discover [Braq](https://github.com/pyrustic/braq) !
# Paradict datatypes
Following are Paradict datatypes for both textual and binary formats:
- **dict**: dictionary data structure
- **list**: list data structure
- **set**: set data structure
- **obj**: object type for extension
- **grid**: grid data structure for storing matrix-like data
- **bool**: boolean type (true and false)
- **str**: string type with unicode escape sequences support
- **raw**: raw string without unicode escape sequences support
- **comment**: comment datatype
- **bin**: binary datatype
- **int**: integer datatype
- **float**: float datatype
- **complex**: complex number
- **datetime**: [ISO 8601](https://en.wikipedia.org/wiki/ISO_8601) datetime (with time offsets)
- **date**: ISO 8601 date
- **time**: ISO 8601 time (with time offsets)
> Paradict supports **null** for representing the intentional absence of any value.
For the dictionary data structure, Paradict allows keys to be either strings or numbers. However, in the config mode of the textual format, keys should only be alphanumeric strings with underscores or hyphens.
Paradict allows ordinary and raw strings, integers, and float numbers to span over multiple lines when they are tagged with `(text)`, `(raw)`, `(int)`, and `(float)`, respectively.
# Data format specification
This section is just an overview of the binary and the textual Paradict formats. For more information, consult [txt_paradict_spec.md](https://github.com/pyrustic/paradict/blob/master/paradict/spec/txt_paradict_spec.md) and [bin_paradict_spec.md](https://github.com/pyrustic/paradict/blob/master/paradict/spec/bin_paradict_spec.md).
## Textual format
At the high level of the textual representation is the **message** which represents a dictionary data structure and at the low level is the **line** of text. A line of text can represent either complete data, such as a number, or a portion of some data that spans multiple lines, such as a multiline string.
For human readability, data expected to span multiple lines is first introduced with a **tag** (the data type in parentheses) under which the data is placed with the correct number of **4-space indents**.
The format comes with two modes, the data mode and the config mode. These modes differ based on the data type of dictionary keys and the character utilized to separate each key from its corresponding value.
### Data mode
The data mode formally represents data (bidirectional mapping to binary format). It allows strings and numbers as keys and use a colon as separator between a key and its value.
```text
# this is a comment
"my key": "Hello World"
```
### Config mode
The config mode is only for configuration files. It only allows strings as key, removing the need to surround them with quotes, and also uses the equal sign as separator between a key and its value.
```python
# this is a comment
my_key = "Hello World"
```
> Read the full specification in [txt_paradict_spec.md](https://github.com/pyrustic/paradict/blob/master/paradict/spec/txt_paradict_spec.md) !
## Binary format
At the high level of the [binary](https://en.wikipedia.org/wiki/Byte) representation is the **message** which represents a **dictionary** data structure and at the low level is the **datum** which is often a 2-tuple composed of a **tag** and its **payload** which may be non-existent.
The binary format is designed from scratch, thus each datatype benefited from a scrupulous attention in order to have a compact and coherent binary representation.
> Read the full specification in [bin_paradict_spec.md](https://github.com/pyrustic/paradict/blob/master/paradict/spec/txt_paradict_spec.md) !
# Application programming interface
The API exposes four foundational classes, Encoder, Decoder, Packer, and Unpacker, that serialize and deserialize data iteratively.
On top of these classes, four functions, encode, decode, pack, and unpack, do the same thing but in bulk.
Then there are additional classes and functions to do various stuff such as the TypeRef class for types customization, load and dump functions for reading and writing binary Paradict file, etc.
Note that this section is just an overview of the API, thus it doesn't replace the **API reference**.
> Explore [API reference](https://github.com/pyrustic/paradict/tree/master/docs/api).
## Textual serialization
Encoder and Decoder are the foundation classes for serializing and deserializing data. These classes process data iteratively. On top of these classes, two functions, encode and decode, do the same thing but in bulk.
### Using the Encoder class
The Encoder constructor accepts `mode`, type_ref, skip_comments and skip_bin_data as arguments.
The `encode` method of this class takes as input a Python dictionary, then iteratively serialize it, yielding a line after another.
```python
from paradict import Encoder
data = {"id": 42, "name": "alex"}
encoder = Encoder() # mode=const.DATA_MODE
lines = list()
for r in encoder.encode(data):
lines.append(r)
print("\n".join(lines))
```
Output:
```text
"id": 42
"name": "alex"
```
The same code but with constructor parameter `mode` set to `const.CONFIG_MODE` would output:
```text
id = 42
name = "alex"
```
### Using the Decoder class
The Decoder constructor accepts `type_ref`, `receiver`, `obj_builder` and `skip_comments` as arguments.
The `feed` method of this class takes as input a multiline string that represent the data to deserialize. This string can be fed up to the deserializer, line by line.
```python
from paradict import Decoder
text = 'id = 42\nname = "alex"'
decoder = Decoder()
decoder.feed(text)
if decoder.queue.buffer:
decoder.feed("\n")
decoder.feed("===\n") # end of stream
data = decoder.data
print(type(data))
print(data)
```
Output:
```text
{'id': 42, 'name': 'alex'}
```
### Using the encode function
The `encode` function accepts `data`, `mode`, `type_ref`, `skip_comments`, and `skip_bin_data` as arguments.
```python
from paradict import encode, const
data = {"id": 42, "name": "alex"}
# DATA MODE
r = encode(data) # mode==const.DATA_MODE
print("DATA MODE")
print(r)
# CONFIG MODE
r = encode(data, mode=const.CONFIG_MODE)
print("\nCONFIG MODE")
print(r)
```
Output:
```text
DATA MODE
"id": 42
"name": "alex"
CONFIG MODE
id = 42
name = "alex"
```
### Using the decode function
The `decode` function accepts `type_ref`, `receiver`, `obj_builder`, and `skip_comments` as arguments.
```python
from paradict import decode
# for the sake of the example,
# the 'id' key-value line follows the DATA mode
# and the 'name' key-value line follows the CONFIG mode
data = """\
"id": 42
name = "alex"
"""
r = decode(data)
print(r)
```
Output:
```text
{'id': 42, 'name': 'alex'}
```
### Load and dump
```python
from paradict import read, write
path = "/home/alex/user_card.bin"
data = {"id": 42, "name": "alex"}
# Serialize and write data to user_card.text
write(data, path)
# Read and deserialize data
r = read(path)
# test
assert data == r
```
### Miscellaneous functions
Under the hood, the `Deserializer` class uses a public function for splitting a key-value line into three parts:
- the key,
- the value,
- and the separator character.
```python
from paradict import split_kv
key_val = "my_key = 'my value'"
info = split_kv(key_val)
# info is a namedtuple containing
# the key, the value, the separator char
# which is either a colon ':', or an
# equal '=', and also the mode which is either
# const.CONFIG_MODE or const.DATA_MODE
key, val, sep, mode = info
```
## Binary serialization
Packer and Unpacker are the foundation classes for serializing and deserializing data. These classes process data iteratively and on top of them, two functions, pack and unpack, do the same thing but in bulk.
Two additional functions, load and dump offer to read and write binary files.
### Using the Packer class
The Packer constructor accepts type_ref, and skip_comments as arguments.
The `pack` method of this class takes as input a Python dictionary, then iteratively serialize it, yielding a binary datum (or part of it) after another.
```python
from paradict import Packer, stringify_bin
data = {"id": 42, "name": "alex"}
packer = Packer()
lines = list()
buffer = bytearray()
for d in packer.pack(data):
buffer.extend(d)
print(stringify_bin(buffer))
```
Output:
```text
\x01\x42\x69\x64\xc5\x44\x6e\x61\x6d\x65\x44\x61\x6c\x65\x78\xff
```
### Using the Unpacker class
The Unpacker constructor accepts `type_ref`, `receiver`, `obj_builder` and `skip_comments` as arguments.
The `feed` method of this class takes as input some binary data that represent the data to deserialize. This binary data can be fed up to the deserializer, by small amount of chunks.
```python
from paradict import pack, Unpacker
data = {"id": 42, "name": "alex"}
d = pack(data)
unpacker = Unpacker()
unpacker.feed(d)
assert unpacker.data == data
```
### Using the pack function
The `pack` function accepts `data`, `type_ref`, and `skip_comments` as arguments.
```python
from paradict import pack, stringify_bin
data = {"id": 42, "name": "alex"}
# DATA MODE
r = pack(data)
print(stringify_bin(r))
```
Output:
```text
\x01\x42\x69\x64\xc5\x44\x6e\x61\x6d\x65\x44\x61\x6c\x65\x78\xff
```
### Using the unpack function
The `unpack` function accepts `raw`, `type_ref`, `receiver`, `obj_builder`, and `skip_comments` as arguments.
```python
from paradict import pack, unpack
data = {"id": 42, "name": "alex"}
d = pack(data)
r = unpack(d)
assert data == r
```
### Load and dump
```python
from paradict import dump, load
path = "/home/alex/user_card.bin"
data = {"id": 42, "name": "alex"}
# Serialize and write data to user_card.bin
dump(data, path)
# Read and deserialize data
r = load(path)
# test
assert data == r
```
### Miscellaneous functions
The library exposes some public miscellaneous functions to play with binary data:
- `forge_bin` function to generate a bytearray forged with the provided arguments which can be of bytes, byterarrays, integers,
- `stringify_bin` function that returns the hexadecimal string representation of some binary data given as argument.
```python
from paradict import stringify_bin, forge_bin
args = (b'\x01', b'\x02', None, 3)
r = forge_bin(*args)
print(stringify_bin(r))
```
Output:
```text
\x01\x02\x03
```
## Type customization
The classes and functions for (de)serializing data, all accept an instance of `TypeRef`.
`TypeRef` is the class that is at the core the type customization mechanism.
For example, one might want to only use Python's OrderedDict instead of the regular dict:
```python
from collections import OrderedDict
from paradict import TypeRef, decode
data = """\
pi = 3.14
user = (dict)
id = 42
name = "alex"
"""
type_ref = TypeRef(dict_type=OrderedDict)
r = decode(data, type_ref=type_ref)
assert type(r) is OrderedDict
assert type(r["user"]) is OrderedDict
assert r == {"pi": 3.14, "user": {"id": 42, "name": "alex"}}
```
Also with `TypeRef`, one could _adapt_ some exotic datatype, thus it will
conform with Python datatypes allowed for serialization:
```python
from paradict import TypeRef, encode
class CapitalizedString(str): # an exotic type
pass
type_adapter = lambda s: s.capitalize()
adapters = {CapitalizedString: type_adapter}
type_ref = TypeRef(adapters=adapters)
data = {"name": CapitalizedString("alex")}
r = encode(data, type_ref=type_ref)
print(r)
```
Output:
```text
"name": "Alex"
```
# Continuous data stream processing
Paradict supports both textual and binary continuous data stream processing.
## Textual stream
Following is a heavily commented code snippet for performing continuous data stream processing:
```python
from paradict.serializer.encoder import Encoder
from paradict.deserializer.decoder import Decoder
# This stream is made of messages
# Each message is a dictionary that serves as envelope
stream = [{0: "a"}, {0: "b"}, {0: "c"}]
# Result will hold the unpacked messages
result = list()
# instantiate encoder and decoder
encoder = Encoder()
# the receiver takes as argument the reference to the decoder
decoder = Decoder(receiver=lambda ref: result.append(ref.data))
# iterate over the stream to pack each message into datums
# that will feed the decoder which will call the receiver
# after each complete unpacking of a message.
# The decoder holds a reference to the latest
# unpacked message via the "decoder.data" property
for i, msg in enumerate(stream):
for line in encoder.encode(msg):
decoder.feed(line + "\n")
decoder.feed("===\n")
# check if datum is well unpacked
assert msg == decoder.data # decoder.data holds unpacked data
# check if the original stream contents is mirrored in
# the result variable
assert stream == result
```
## Binary stream
Following is a heavily commented code snippet for performing continuous data stream processing:
```python
from paradict.serializer.packer import Packer
from paradict.deserializer.unpacker import Unpacker
# This stream is made of messages
# Each message is a dictionary that serves as envelope
stream = [{0: "a"}, {0: "b"}, {0: "c"}]
# Result will hold the unpacked messages
result = list()
# instantiate packer and unpacker
packer = Packer()
# the receiver takes as argument the reference to the unpacker
unpacker = Unpacker(receiver=lambda ref: result.append(ref.data))
# iterate over the stream to pack each message into datums
# that will feed the unpacker which will call the receiver
# after each complete unpacking of a message.
# The unpacker holds a reference to the latest
# unpacked message via the "unpacker.data" property
for i, msg in enumerate(stream):
for datum in packer.pack(msg):
unpacker.feed(datum)
# check if datum is well unpacked
assert msg == unpacker.data # unpacker.data holds unpacked data
# check if the original stream contents is mirrored in
# the result variable
assert stream == result
```
# Paradict schema for data validation
A Paradict schema is a dictionary containing specs for data validation.
A spec is either simply a string that represents an expected data type, or a `Spec` object that can contain a checking function for complex validation.
Supported spec strings are: `dict`, `list`, `set`, `obj`, `bin`, `bin`, `bool`, `complex`, `date`, `datetime`, `float`, `grid`, `int`, `str`, `time`
Code snippet:
```python
from paradict import is_valid
from paradict.validator import Spec
# data
data = {"id": 42,
"name": "alex",
"books": ["book 1", "book 2"]}
# schema
schema = {"id": Spec("int", lambda x: 40 < x < 50),
"name": "str",
"books": ["str"]}
assert is_valid(data, schema)
```
# Attachments
The Paradict text format allows you to instruct the parser to automatically load files, namely **attachments**:
```
id = 42
name = 'alex'
photo = load('attachments/pic.png')
```
Here the parser would look for a `pic.png` file in the `attachments` folder located in the root directory and then load it as the binary value for the `photo` key.
Note that when the root directory is not provided as an argument, it is assumed to be the current working directory.
> Depending on whether its `bin_to_text` boolean parameter is `True` or `False`, the encoder processes binary values differently, either by converting them into Base16 strings or by storing them as **attachments**.
# Miscellaneous
The beautiful cover image is generated with [Carbon](https://carbon.now.sh/about).
# Testing and contributing
Feel free to **open an issue** to report a bug, suggest some changes, show some useful code snippets, or discuss anything related to this project. You can also directly email [me](https://pyrustic.github.io/#contact).
## Setup your development environment
Following are instructions to setup your development environment
```bash
# create and activate a virtual environment
python -m venv venv
source venv/bin/activate
# clone the project then change into its directory
git clone https://github.com/pyrustic/paradict.git
cd paradict
# install the package locally (editable mode)
pip install -e .
# run tests
python -m unittest discover -f -s tests -t .
# deactivate the virtual environment
deactivate
```
# Installation
**Paradict** is **cross-platform**. It is built on [Ubuntu](https://ubuntu.com/download/desktop) and should work on **Python 3.5** or **newer**.
## Create and activate a virtual environment
```bash
python -m venv venv
source venv/bin/activate
```
## Install for the first time
```bash
pip install paradict
```
## Upgrade the package
```bash
pip install paradict --upgrade --upgrade-strategy eager
```
## Deactivate the virtual environment
```bash
deactivate
```
# About the author
Hello world, I'm Alex, a tech enthusiast ! Feel free to get in touch with [me](https://pyrustic.github.io/#contact) !
[Back to top](#readme)