https://github.com/pythainlp/attacut
A Fast and Accurate Neural Thai Word Segmenter
https://github.com/pythainlp/attacut
cnn hacktoberfest hactoberfest2022 nlp tokenization
Last synced: over 1 year ago
JSON representation
A Fast and Accurate Neural Thai Word Segmenter
- Host: GitHub
- URL: https://github.com/pythainlp/attacut
- Owner: PyThaiNLP
- License: mit
- Created: 2019-08-24T09:31:47.000Z (almost 7 years ago)
- Default Branch: master
- Last Pushed: 2025-01-14T12:13:51.000Z (over 1 year ago)
- Last Synced: 2025-04-04T05:51:40.097Z (over 1 year ago)
- Topics: cnn, hacktoberfest, hactoberfest2022, nlp, tokenization
- Language: Python
- Homepage: https://pythainlp.github.io/attacut/
- Size: 4.15 MB
- Stars: 85
- Watchers: 5
- Forks: 16
- Open Issues: 8
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# AttaCut: Fast and Reasonably Accurate Word Tokenizer for Thai
[](https://travis-ci.org/PyThaiNLP/attacut)
[](https://ci.appveyor.com/project/wannaphongcom/attacut/branch/master)
[](https://drive.google.com/file/d/16AUNZv1HXVmERgryfBf4JpCo1QrQyHHE/view?usp=sharing)
[](https://arxiv.org/abs/1911.07056)
## How does AttaCut look like?

TL;DR:
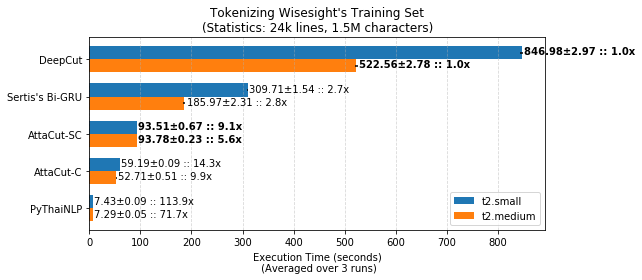
3-Layer Dilated CNN on syllable and character features. It’s 6x faster than DeepCut (SOTA) while its WL-f1 on BEST is 91%, only 2% lower.
## Installation
```
$ pip install attacut
```
**Remarks:** Windows users need to install **PyTorch** before the command above.
Please consult [PyTorch.org](https://pytorch.org) for more details.
## Usage
### Command-Line Interface
```
$ attacut-cli -h
AttaCut: Fast and Reasonably Accurate Word Tokenizer for Thai
Usage:
attacut-cli [--dest=] [--model=]
attacut-cli [-v | --version]
attacut-cli [-h | --help]
Arguments:
Path to input text file to be tokenized
Options:
-h --help Show this screen.
--model= Model to be used [default: attacut-sc].
--dest= If not specified, it'll be -tokenized-by-.txt
-v --version Show version
```
### High-Level API
```
from attacut import tokenize, Tokenizer
# tokenize `txt` using our best model `attacut-sc`
words = tokenize(txt)
# alternatively, an AttaCut tokenizer might be instantiated directly, allowing
# one to specify whether to use `attacut-sc` or `attacut-c`.
atta = Tokenizer(model="attacut-sc")
words = atta.tokenize(txt)
```
For better efficiency, we recommend using attacut-cli. Please consult [our Google Colab tutorial ](https://colab.research.google.com/drive/1-JM19BnSMAWaF4aFgb8jcSiISfKr0PyH) for more detials.
## Benchmark Results
Belows are brief summaries. More details can be found on [our benchmarking page](https://pythainlp.github.io/attacut/benchmark.html).
### Tokenization Quality
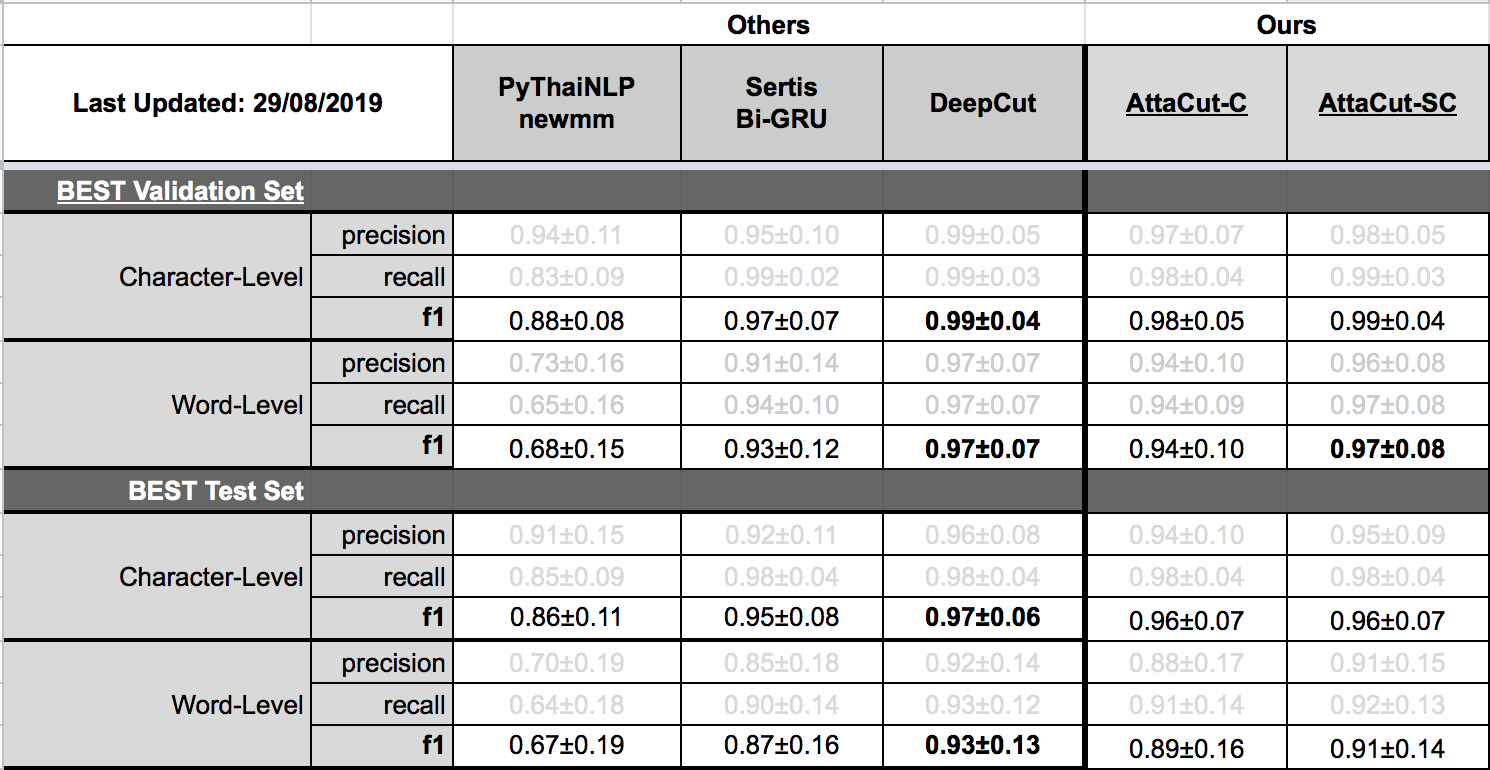
### Speed
## Retraining on Custom Dataset
Please refer to [our retraining page](https://pythainlp.github.io/attacut/)
## Related Resources
- [Tokenization Visualization][tovis]
- [Thai Tokenizer Dockers][docker]
## Acknowledgements
This repository was initially done by [Pattarawat Chormai][pat], while interning at [Dr. Attapol Thamrongrattanarit's NLP Lab][ate], Chulalongkorn University, Bangkok, Thailand.
Many people have involed in this project. Complete list of names can be found on [Acknowledgement](https://pythainlp.github.io/attacut/acknowledgement.html).
[pat]: http://pat.chormai.org
[ate]: https://attapol.github.io/lab.html
[noom]: https://github.com/Ekkalak-T
[can]: https://github.com/c4n
[ake]: https://github.com/ekapolc
[tovis]: https://pythainlp.github.io/tokenization-benchmark-visualization/
[docker]: https://github.com/PyThaiNLP/docker-thai-tokenizers