https://github.com/quva-lab/lang-tracker
https://github.com/quva-lab/lang-tracker
Last synced: about 1 year ago
JSON representation
- Host: GitHub
- URL: https://github.com/quva-lab/lang-tracker
- Owner: QUVA-Lab
- License: other
- Created: 2017-09-05T14:44:26.000Z (almost 9 years ago)
- Default Branch: master
- Last Pushed: 2021-03-30T08:34:29.000Z (about 5 years ago)
- Last Synced: 2025-03-27T23:23:50.996Z (about 1 year ago)
- Language: Python
- Size: 32.7 MB
- Stars: 38
- Watchers: 11
- Forks: 9
- Open Issues: 6
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# Tracking by Natural Language Specification
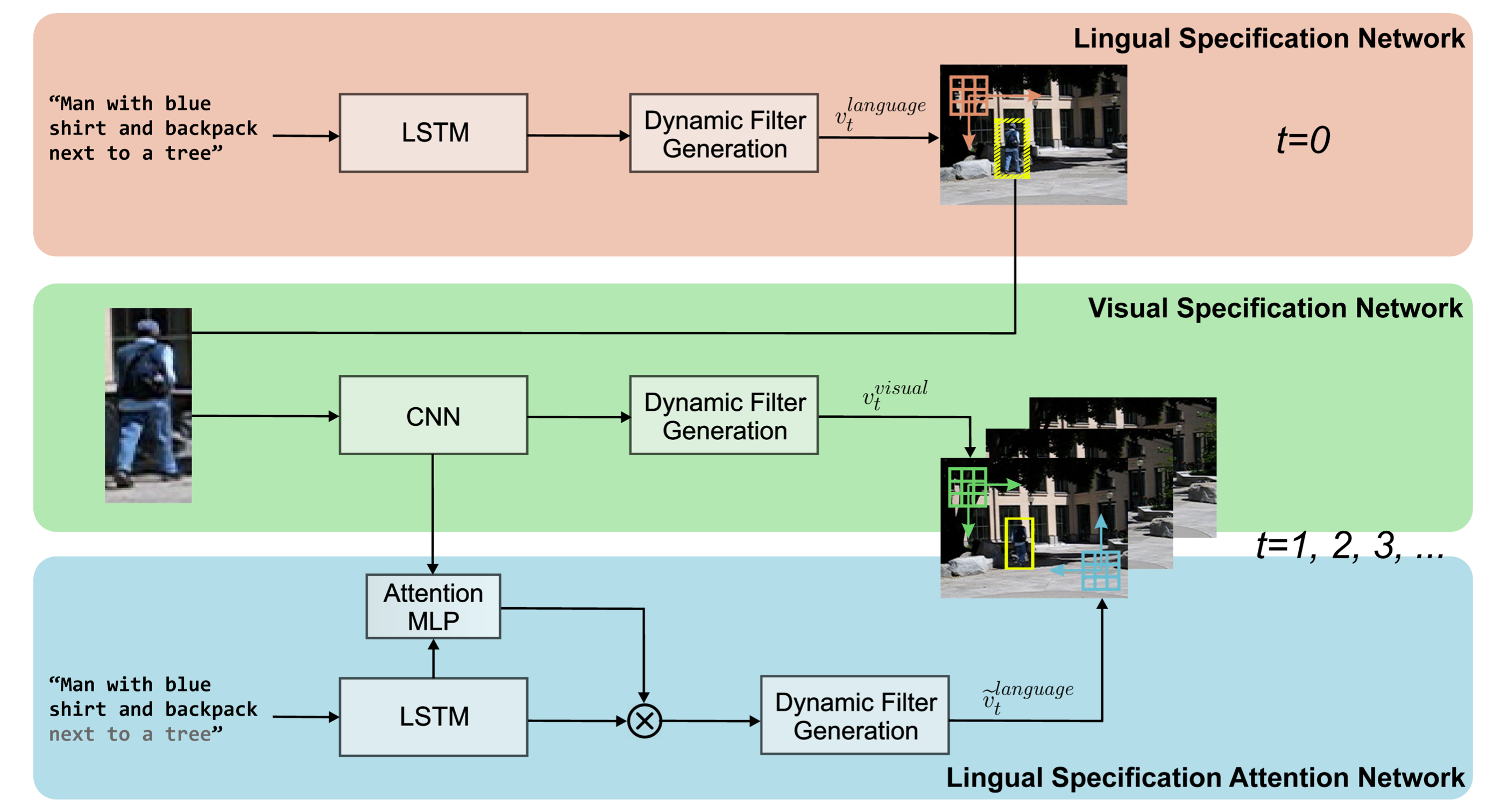
This repository contains the code for the following paper:
* Z. Li, R. Tao, E. Gavves, C. G. M. Snoek, A. W. M. Smeulders, *Tracking by Natural Language Specification*, in Computer Vision and Pattern Recognition (CVPR), 2017 ([PDF](http://openaccess.thecvf.com/content_cvpr_2017/papers/Li_Tracking_by_Natural_CVPR_2017_paper.pdf))
```
@article{li2017cvpr,
title={Tracking by Natural Language Specification},
author={Li, Zhenyang and Tao, Ran and Gavves, Efstratios and Snoek, Cees G. M. and Smeulders, Arnold W. M.},
journal={Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition},
year={2017}
}
```
# Download Dataset
### Lingual Lingual OTB99 [Sentences](http://isis-data.science.uva.nl/zhenyang/cvpr17-langtracker/data/OTB_sentences.zip)
### Lingual ImageNet [Sentences](http://isis-data.science.uva.nl/zhenyang/cvpr17-langtracker/data/ImageNet_sentences.zip)
Please note that we use all the frames from original [OTB100](http://cvlab.hanyang.ac.kr/tracker_benchmark/datasets.html) dataset in our OTB99 videos, while for [ImageNet](http://vision.cs.unc.edu/ilsvrc2015/ui/vid) videos we may only select a subsequence (see start/end frames we selected for each video in `train.txt` or `test.txt`).
# How to use the demo code
## Download and setup Caffe (our own branch)
1. Caffe branch [here](https://github.com/zhenyangli/caffe-lang-track/tree/langtrackV3) (Note: `langtrackV3` branch not `master` branch)
2. Compile Caffe with option
```
WITH_PYTHON_LAYER = 1
```
## Download pre-trained models
1. Download natural language segmentation model [caffemodel](http://isis-data.science.uva.nl/zhenyang/cvpr17-langtracker/code/pretrain-models/snapshots/lang_high_res_seg/_iter_25000.caffemodel)
and copy to `MAIN_PATH/snapshots/lang_high_res_seg/_iter_25000.caffemodel`
2. Download tracking model [caffemodel](http://isis-data.science.uva.nl/zhenyang/cvpr17-langtracker/code/pretrain-models/VGG16.v2.caffemodel)
and copy to `MAIN_PATH/VGG16.v2.caffemodel`
## Run demo code
### ipython notebook code
Here we first demostrate how the model II in the paper works with example videos:
1. Given an image and a natural language query, how to identify a target (applied on the first query frame of a video only)
```
demo/lang_seg_demo.ipynb
```
2. Given a visual target (a box identified from step 1) and a sequence of frames, how to track the object in all the frames
```
demo/lang_track_demo.ipynb
```