https://github.com/rafaelfgx/distributedcomputing
Distributed computing is the field of study that deals with the division of tasks between multiple computers connected in a network.
https://github.com/rafaelfgx/distributedcomputing
distributed distributed-computing distributed-systems microservice microservices
Last synced: 7 months ago
JSON representation
Distributed computing is the field of study that deals with the division of tasks between multiple computers connected in a network.
- Host: GitHub
- URL: https://github.com/rafaelfgx/distributedcomputing
- Owner: rafaelfgx
- License: mit
- Created: 2024-05-22T20:16:02.000Z (over 1 year ago)
- Default Branch: main
- Last Pushed: 2025-01-09T11:35:22.000Z (9 months ago)
- Last Synced: 2025-01-09T12:40:38.474Z (9 months ago)
- Topics: distributed, distributed-computing, distributed-systems, microservice, microservices
- Homepage:
- Size: 12.7 KB
- Stars: 2
- Watchers: 0
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: readme-pt-br.md
- License: license.md
Awesome Lists containing this project
README
# Computação Distribuída
#### EN-US: [Distributed Computing](https://github.com/rafaelfgx/DistributedComputing/tree/main/readme.md)
Computação distribuída é a área que lida com a divisão de tarefas entre vários computadores conectados em rede.
Para garantir a comunicação e a cooperação efetiva desses computadores, diversos padrões e conceitos são recomendados e utilizados.
## Falácias da Computação Distribuída
No mundo dos sistemas distribuídos, onde diversos componentes trabalham em conjunto, algumas suposições incorretas podem levar a grandes problemas. As oito falácias da computação distribuída, definidas por Peter Deutsch e James Gosling, servem como um alerta para os perigos de se basear em premissas falsas ao projetar e construir esses sistemas.
**1. Rede é confiável:** Acreditar que a rede está sempre disponível e livre de falhas é um mito. Na realidade, falhas de hardware, software e até mesmo da própria internet são comuns. Sistemas distribuídos robustos precisam ser projetados para lidar com essas falhas e garantir a continuidade das operações.
**2. Latência é zero:** Imagine que enviar dados entre computadores seja instantâneo? Essa é a ideia por trás da falácia da latência zero. Na prática, a latência, o tempo que leva para um dado ser transmitido, sempre existirá. É crucial levar isso em consideração ao projetar sistemas distribuídos, otimizando a comunicação e minimizando os impactos da latência.
**3. Largura de banda é infinita:** A quantidade de dados que podem ser transferidos por uma rede é limitada, e não infinita. Ignorar essa limitação pode levar a gargalos e lentidão no sistema. É importante dimensionar a largura de banda de acordo com as necessidades da aplicação e utilizar técnicas de compressão de dados quando necessário.
**4. Rede é segura:** Acreditar que a rede é um ambiente seguro é um erro grave. Ameaças como hackers, malwares e espionagem estão sempre presentes. Sistemas distribuídos precisam implementar medidas robustas de segurança para proteger dados e garantir a confidencialidade das informações.
**5. Topologia não muda:** A estrutura da rede, como a forma como os computadores estão conectados, pode mudar ao longo do tempo. Novas máquinas podem ser adicionadas, antigas podem ser removidas, e até mesmo a topologia física da rede pode ser alterada. Sistemas distribuídos flexíveis precisam se adaptar a essas mudanças sem comprometer sua operação.
**6. Há somente um administrador:** Em um sistema distribuído, a responsabilidade pela administração pode ser distribuída entre vários indivíduos ou equipes. Acreditar que existe um único administrador central que controla tudo é um equívoco. É necessário definir políticas claras de gerenciamento e estabelecer processos eficientes de comunicação e colaboração entre os administradores.
**7. Custo de transporte é zero:** Mover dados entre computadores pode ter um custo, tanto em termos de desempenho quanto de recursos financeiros. Ignorar esse custo pode levar a soluções ineficientes e dispendiosas. É importante otimizar a transferência de dados e considerar o uso de técnicas como cache e replicação para minimizar custos.
**8. Rede é homogênea:** Sistemas distribuídos podem ser compostos por diferentes tipos de computadores, com recursos e capacidades variadas. Acreditar que todos os computadores são iguais é um erro. É fundamental levar em consideração a heterogeneidade da rede ao projetar o sistema e distribuir as tarefas de forma eficiente.
Ao compreender e evitar essas falácias, você estará no caminho certo para construir sistemas distribuídos robustos, escaláveis e seguros, prontos para os desafios do mundo real.
Lembrando que as falácias da computação distribuída servem como um guia, não como regras absolutas. Cada sistema distribuído possui suas características únicas, e cabe aos arquitetos e desenvolvedores avaliar cada caso com cuidado e tomar as decisões adequadas para garantir o sucesso do projeto.
## Data Collection
Processo de reunir informações de diferentes fontes distribuídas. Imagine reunir dados de vendas de várias lojas em um banco de dados central.
## Retry Pattern
Quando uma operação falha, esse padrão tenta executá-la novamente após um certo tempo, evitando erros temporários. Imagine tentar enviar um email, mas a rede estar congestionada. O Retry Pattern tentaria reenviar o email mais tarde.
## Circuit Breaker Pattern
Se as tentativas de uma operação falham repetidamente, esse padrão "quebra o circuito" temporariamente, evitando tentativas inúteis e protegendo o sistema de sobrecarga. Voltando ao exemplo do email, após várias falhas, o Circuit Breaker impediria novas tentativas por um tempo, evitando sobrecarregar o servidor de email.
## Idempotent Pattern
Garante que a execução múltipla da mesma operação tenha o mesmo efeito. É útil em cenários onde falhas podem causar reenvios. Imagine descontar um item do carrinho de compras. Mesmo se o desconto for tentado duas vezes, o item só será descontado uma vez.
## Publish-Subscribe Pattern
Permite que um componente envie mensagens para vários outros componentes interessados, sem precisar conhecer cada um individualmente. Imagine um sistema de notícias onde um editor publica uma notícia, e todos os usuários inscritos a aquele tema a recebem.
## SAGA Pattern
Coordena uma série de transações distribuídas, garantindo a consistência geral do sistema. Imagine um pedido de compra online. A SAGA pode garantir que o estoque seja reservado, o pagamento seja processado e o envio seja confirmado, revertendo tudo caso alguma etapa falhe.
## Outbox Pattern
Utilizado para mensagens que precisam ser enviadas de forma assíncrona. Imagine um e-commerce que gera um comprovante de compra após o pagamento. O Outbox armazena a mensagem de geração do comprovante para ser enviada posteriormente, desacoplando o processamento do pedido da geração do comprovante.
## Two-Phase Commit Pattern (2PC)
Transações distribuídas em um sistema são coordenadas para garantir que todas as partes envolvidas concordem em commitar ou abortar a transação como um todo. Isso evita que apenas algumas partes da transação sejam atualizadas, enquanto outras permanecem em um estado inconsistente.
## Event Notification
Mecanismo pelo qual um componente informa outros componentes sobre a ocorrência de um evento. Imagine um usuário se cadastrando em um site. A notificação de evento avisa outros componentes do sistema.
## Event Carried Transfer Strategy
Envolve enviar todos os dados necessários para realizar uma ação junto com a notificação do evento. Imagine cancelar um pedido. A notificação pode incluir todos os dados do pedido para que o sistema de cancelamento possa processá-lo diretamente.
## Event Sourcing
Baseia a persistência do estado de um sistema em uma sequência de eventos ocorridos. Imagine o histórico de transações bancárias. Event Sourcing armazena cada depósito e saque como eventos, permitindo reconstruir o saldo em qualquer momento.
## Asynchronous Request-Reply Pattern
Permite enviar uma solicitação e receber uma resposta posteriormente, sem bloquear o solicitante. Imagine enviar um email. O envio pode ser assíncrono, liberando o sistema para continuar outras tarefas enquanto o email é enviado.
## Queue-Based Pattern
Utiliza filas para bufferizar mensagens e desacoplar a produção do consumo. Imagine uma fila de impressão. Documentos são adicionados à fila e impressos individualmente, sem que o programa que os enviou precise se preocupar com a impressora estar ocupada.
## Competing Consumer Pattern
Permite que vários consumidores processem mensagens de uma fila concorrentemente. Imagine uma fila de tarefas. Vários computadores podem pegar tarefas da fila e processá-las simultaneamente, aumentando a performance.
## Eventual Consistency Pattern
Garante que dados replicados em diferentes localidades eventualmente se tornarão consistentes, permitindo a disponibilidade e escalabilidade. Imagine um sistema de vendas com lojas espalhadas. Uma promoção pode levar a preços diferentes temporariamente até a replicação se propagar para todas as lojas.
## Sharding Pattern
Divide um banco de dados grande em partes menores para melhorar a performance e escalabilidade. Imagine uma rede social com milhões de usuários. O Sharding Pattern pode dividir os dados dos usuários em shards menores, facilitando consultas e atualizações.
## Command Query Responsibility Segregation Pattern (CQRS)
Separa os componentes que escrevem dados (comandos) daqueles que leem dados (consultas). Imagine uma loja virtual. O CQRS pode separar o sistema de cadastro de produtos (comando) do sistema de busca de produtos (consulta), otimizando cada um para sua função específica.
## Strangler Pattern
Estratégia para migrar gradualmente um sistema monolítico para uma arquitetura de microsserviços. Inspirado em uma planta que cresce em torno de uma árvore hospedeira, o padrão envolve a construção de novos serviços modulares que substituem funcionalidades específicas do monólito, enquanto este permanece em execução.
## Governance
Estabelece regras, processos e controles para gerenciar um sistema distribuído de forma segura e confiável. Imagine o tráfego em uma rodovia. A governança define as regras de trânsito, fiscalização e manutenção para garantir o bom funcionamento do sistema.
## Event Catalog
Armazena informações sobre eventos utilizados no sistema, facilitando a descoberta e a integração de componentes. Imagine um dicionário de eventos. O catálogo de eventos define o significado e os dados associados a cada tipo de evento, possibilitando que componentes compreendam as notificações recebidas.
## Schema Registry
Gerencia a evolução dos schemas de mensagens utilizadas na comunicação entre componentes. Imagine a gramática de uma língua. O Schema Registry define a estrutura das mensagens para garantir que os componentes falem a mesma linguagem e interpretem os dados corretamente.
## Healthcheck Endpoint
Ponto de acesso que permite verificar a saúde de um serviço. Imagine checar a temperatura do motor de um carro. O Healthcheck Endpoint fornece informações sobre o status do serviço, auxiliando no diagnóstico de problemas.
## Service Registry & Discovery
Permite que serviços anunciem sua disponibilidade e localização, possibilitando que outros serviços os encontrem. Imagine uma lista telefônica para serviços. O Service Registry & Discovery funciona como um catálogo onde os serviços se registram e podem ser localizados por outros componentes que necessitem deles.
## Sidecar Pattern
Contêiner auxiliar que é executado ao lado do contêiner principal. O Sidecar fornece funcionalidades adicionais como monitoramento, registro em log, proxy reverso, segurança e outros.
## Monitoring
Coleta e analisa dados de desempenho e saúde do sistema distribuído. Imagine os painéis de um carro mostrando velocidade, RPM e temperatura. O monitoramento fornece insights sobre o funcionamento do sistema, auxiliando na identificação e resolução de problemas.
## Observability
Entende o comportamento interno de um sistema distribuído. Imagine um mecânico examinando o motor de um carro. A observabilidade vai além do monitoramento, permitindo investigar problemas e entender o funcionamento interno do sistema.
## Distributed Tracing
Monitora o fluxo de requisições em um sistema distribuído. Imagine acompanhar a entrega de um pacote por diversas transportadoras. O rastreamento distribuído identifica gargalos e problemas de performance na cadeia de processamento de uma requisição.
## Log Aggregation
Centraliza e organiza logs de diversos componentes do sistema distribuído. Imagine centralizar os recibos de pedágio de uma viagem. A agregação facilita a análise e correlação de eventos em todo o sistema.
## Auto Scaling
Ajusta automaticamente recursos computacionais para um serviço, conforme demanda. Imagine faróis de carro que se ajustam à luz externa. O Auto Scaling dimensiona o sistema para picos de carga e otimiza o uso de recursos.
## Load Balancing
Distribui automaticamente o tráfego de rede entre vários servidores para otimizar o desempenho e a confiabilidade de um sistema, evitando que um único servidor fique sobrecarregado.
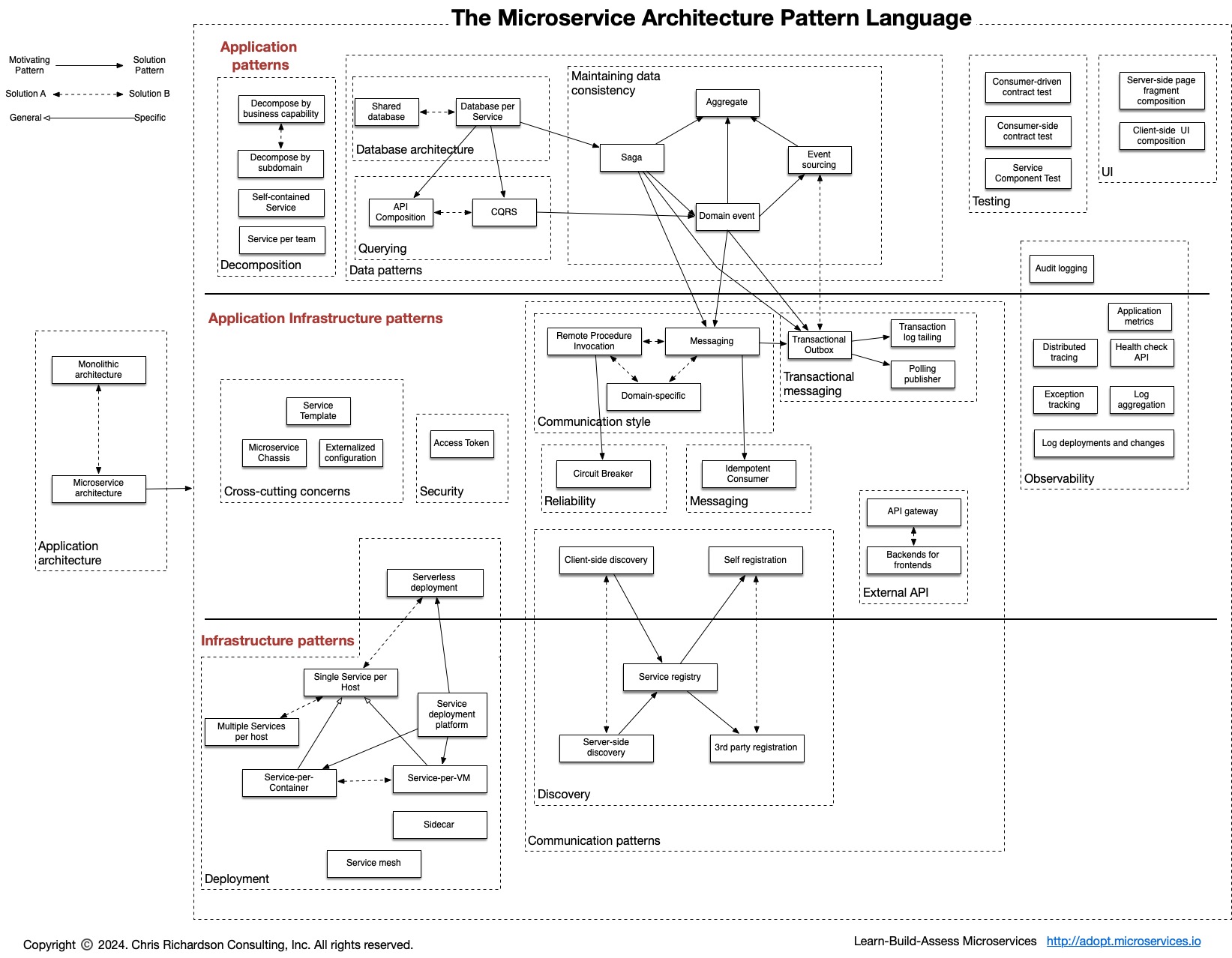
## [The Microservice Architecture Pattern Language](https://microservices.io/patterns/index.html)
## Tools
### API Management / API Gateway
- [Kong](https://konghq.com)
- [KrakenD](https://www.krakend.io)
- [Amazon API Gateway](https://aws.amazon.com/api-gateway)
- [Azure API Management](https://azure.microsoft.com/en-us/services/api-management)
- [Google Cloud Endpoints](https://cloud.google.com/endpoints)
### Service Discovery
- [Consul](https://www.consul.io)
- [AWS Cloud Map](https://aws.amazon.com/cloud-map)
- [Azure Service Fabric](https://azure.microsoft.com/en-us/services/service-fabric)
- [Google Cloud Service Directory](https://cloud.google.com/service-directory)
### Identity and Access Management
- [Keycloak](https://www.keycloak.org)
- [Auth0](https://auth0.com)
- [Amazon Cognito](https://aws.amazon.com/cognito)
- [Azure Active Directory](https://azure.microsoft.com/en-us/services/active-directory)
- [Google Cloud Identity](https://cloud.google.com/identity)
### Load Balancer / Reverse Proxy
- [NGINX](https://www.nginx.com)
- [HAProxy](http://www.haproxy.org)
- [Traefik](https://traefik.io)
- [Envoy](https://www.envoyproxy.io)
- [Amazon Elastic Load Balancing](https://aws.amazon.com/elasticloadbalancing)
- [Azure Load Balancer](https://azure.microsoft.com/en-us/services/load-balancer)
- [Google Cloud Load Balancing](https://cloud.google.com/load-balancing)
### Vault
- [HashiCorp Vault](https://www.vaultproject.io)
- [AWS Secrets Manager](https://aws.amazon.com/secrets-manager)
- [Azure Key Vault](https://azure.microsoft.com/en-us/services/key-vault)
- [Google Cloud Secret Manager](https://cloud.google.com/secret-manager)
### Relational Database
- [PostgreSQL](https://www.postgresql.org)
- [Amazon Relational Database Service](https://aws.amazon.com/rds)
- [Azure SQL Database](https://azure.microsoft.com/en-us/services/sql-database)
- [Google Cloud SQL](https://cloud.google.com/sql)
### Non Relational Database
- [MongoDB](https://www.mongodb.com)
- [Cassandra](https://cassandra.apache.org)
- [Amazon DynamoDB](https://aws.amazon.com/dynamodb)
- [Azure Cosmos DB](https://azure.microsoft.com/products/cosmos-db)
- [Google Cloud Firestore](https://firebase.google.com/products/firestore)
### Change Data Capture (CDC)
- [Debezium](https://debezium.io)
## Extract, Transform, Load (ETL)
- [Airbyte](https://airbyte.com)
### Data Streaming
- [Apache Flink](https://flink.apache.org)
- [Apache Storm](https://storm.apache.org)
- [Amazon Kinesis](https://aws.amazon.com/kinesis)
- [Azure Stream Analytics](https://azure.microsoft.com/en-us/services/stream-analytics)
- [Google Cloud Dataflow](https://cloud.google.com/dataflow)
### Message Broker
- [RabbitMQ](https://www.rabbitmq.com)
- [Apache Kafka](https://kafka.apache.org)
- [Amazon Simple Queue Service](https://aws.amazon.com/sqs)
- [Azure Service Bus](https://azure.microsoft.com/en-us/services/service-bus)
- [Google Cloud Pub/Sub](https://cloud.google.com/pubsub)
### Caching
- [Redis](https://redis.io)
- [Memcached](https://memcached.org)
- [Amazon ElastiCache](https://aws.amazon.com/elasticache)
- [Azure Cache for Redis](https://azure.microsoft.com/en-us/services/cache)
- [Google Cloud Memorystore](https://cloud.google.com/memorystore)
### Serverless / (Function as a Service)
- [OpenFaaS](https://www.openfaas.com)
- [AWS Lambda](https://aws.amazon.com/lambda)
- [Azure Functions](https://azure.microsoft.com/en-us/services/functions)
- [Google Cloud Functions](https://cloud.google.com/functions)
### Containers
- [Docker](https://www.docker.com)
- [Kubernetes](https://kubernetes.io)
- [Helm](https://helm.sh)
- [Rancher](https://rancher.com)
- [Amazon Elastic Kubernetes Service (EKS)](https://aws.amazon.com/eks)
- [Azure Kubernetes Service (AKS)](https://azure.microsoft.com/en-us/services/kubernetes-service)
- [Google Kubernetes Engine (GKE)](https://cloud.google.com/kubernetes-engine)
### Infrastructure as Code / Configuration Management
- [Terraform](https://www.terraform.io)
- [Ansible](https://www.ansible.com)
- [Chef](https://www.chef.io)
- [Pulumi](https://www.pulumi.com)
### Monitoring / Observability
- [Prometheus](https://prometheus.io)
- [Grafana](https://grafana.com)
- [Elasticsearch, Logstash, Kibana (ELK)](https://www.elastic.co/what-is/elk-stack)
- [Jaeger](https://www.jaegertracing.io)
- [Zipkin](https://zipkin.io)
- [OpenTracing](https://opentracing.io)
- [OpenTelemetry](https://opentelemetry.io)
- [Graylog](https://graylog.org)
- [Fluentd](https://www.fluentd.org)
- [Dynatrace](https://www.dynatrace.com)
- [NewRelic](https://newrelic.com)
- [Amazon CloudWatch](https://aws.amazon.com/cloudwatch)
- [Azure Monitor](https://azure.microsoft.com/en-us/services/monitor)
- [Google Cloud Monitoring](https://cloud.google.com/monitoring)
### Service Mesh
- [Istio](https://istio.io)
- [Linkerd](https://linkerd.io)
- [AWS App Mesh](https://aws.amazon.com/app-mesh)
- [Google Cloud Service Mesh](https://cloud.google.com/anthos/service-mesh)
### CI/CD
- [GitHub](https://docs.github.com/en/actions)
- [GitLab](https://about.gitlab.com/solutions/continuous-integration)
- [CircleCI](https://circleci.com)
- [Jenkins](https://www.jenkins.io)
- [AWS CodePipeline](https://aws.amazon.com/codepipeline)
- [Azure DevOps](https://azure.microsoft.com/en-us/services/devops)
- [Google Cloud Build](https://cloud.google.com/cloud-build)
### Documentation
- [Swagger](https://swagger.io)
- [AsyncAPI](https://www.asyncapi.com)
### Testing
- [Postman](https://www.postman.com)
- [Insomnia](https://insomnia.rest)
- [Apidog](https://apidog.com)
- [Testcontainers](https://testcontainers.com)
- [K6](https://k6.io)
- [Cypress](https://www.cypress.io)