https://github.com/rahulschand/gpu_poor
Calculate token/s & GPU memory requirement for any LLM. Supports llama.cpp/ggml/bnb/QLoRA quantization
https://github.com/rahulschand/gpu_poor
ggml gpu huggingface language-model llama llama2 llamacpp llm pytorch quantization
Last synced: about 1 year ago
JSON representation
Calculate token/s & GPU memory requirement for any LLM. Supports llama.cpp/ggml/bnb/QLoRA quantization
- Host: GitHub
- URL: https://github.com/rahulschand/gpu_poor
- Owner: RahulSChand
- Created: 2023-09-12T10:41:29.000Z (almost 3 years ago)
- Default Branch: main
- Last Pushed: 2024-12-03T20:52:37.000Z (over 1 year ago)
- Last Synced: 2025-05-11T01:37:03.449Z (about 1 year ago)
- Topics: ggml, gpu, huggingface, language-model, llama, llama2, llamacpp, llm, pytorch, quantization
- Language: JavaScript
- Homepage: https://rahulschand.github.io/gpu_poor/
- Size: 1.56 MB
- Stars: 1,303
- Watchers: 7
- Forks: 73
- Open Issues: 7
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Can my GPU run this LLM? & at what token/s?

Calculates how much **GPU memory you need** and how much **token/s you can get** for any LLM & GPU/CPU.
Also breakdown of where it goes for training/inference with quantization (GGML/bitsandbytes/QLoRA) & inference frameworks (vLLM/llama.cpp/HF) supported
Link: **https://rahulschand.github.io/gpu_poor/**
### Demo

---
## Use cases/Features
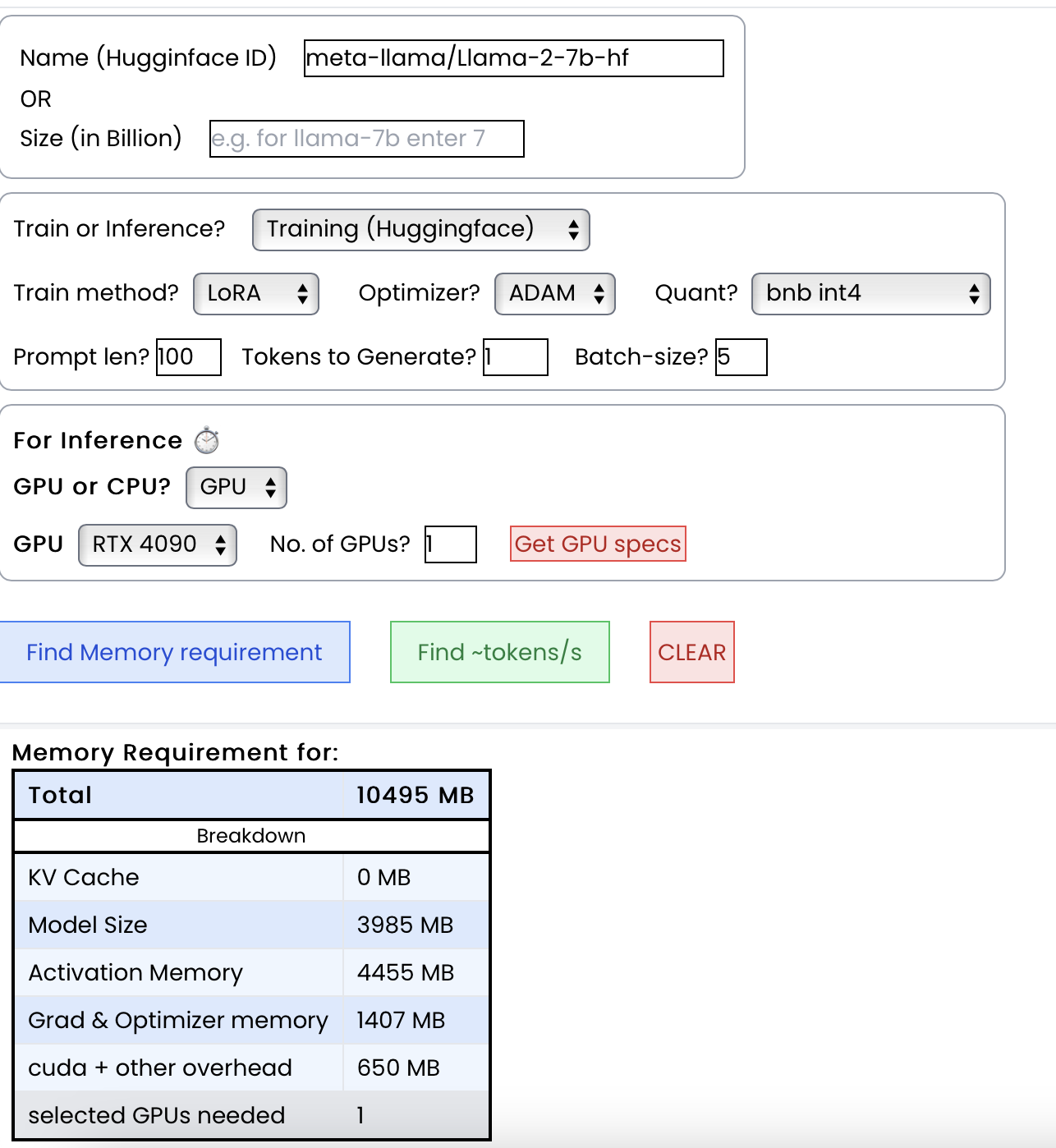
#### 1. Calculate vRAM memory requirement 💾
---
#### 2. Calculate ~token/s you can get ⏱️

---
#### 3. Approximate time for finetuning (ms per iteration) ⌛️

---
For memory, output is total vRAM & its breakdown. It looks like below
```
{
"Total": 4000,
"KV Cache": 1000,
"Model Size": 2000,
"Activation Memory": 500,
"Grad & Optimizer memory": 0,
"cuda + other overhead": 500
}
```
For token/s, additional info looks like below
```
{
"Token per second": 50,
"ms per token": 20,
"Prompt process time (s)": 5 s,
"memory or compute bound?": Memory,
}
```
For training, output is time for each forward pass (in ms)
```
{
"ms per iteration (forward + backward)": 100,
"memory or compute bound?": Memory,
}
```
---
### Purpose
made this to check if you can run a particular LLM on your GPU. Useful to figure out the following
1. How much token/s can I get?
2. How much total time to finetune?
3. What quantization will fit on my GPU?
4. Max context length & batch-size my GPU can handle?
5. Which finetuning? Full? LoRA? QLoRA?
6. What is consuming my GPU memory? What to change to fit the LLM on GPU?
---
## Additional info + FAQ
### Can't we just look at the model size & figure this out?
Finding which LLMs your GPU can handle isn't as easy as looking at the model size because during inference (KV cache) takes susbtantial amount of memory. For example, with sequence length 1000 on llama-2-7b it takes 1GB of extra memory (using hugginface LlamaForCausalLM, with exLlama & vLLM this is 500MB). And during training both KV cache & activations & quantization overhead take a lot of memory. For example, llama-7b with bnb int8 quant is of size ~7.5GB but it isn't possible to finetune it using LoRA on data with 1000 context length even with RTX 4090 24 GB. Which means an additional 16GB memory goes into quant overheads, activations & grad memory.
### How reliable are the numbers?
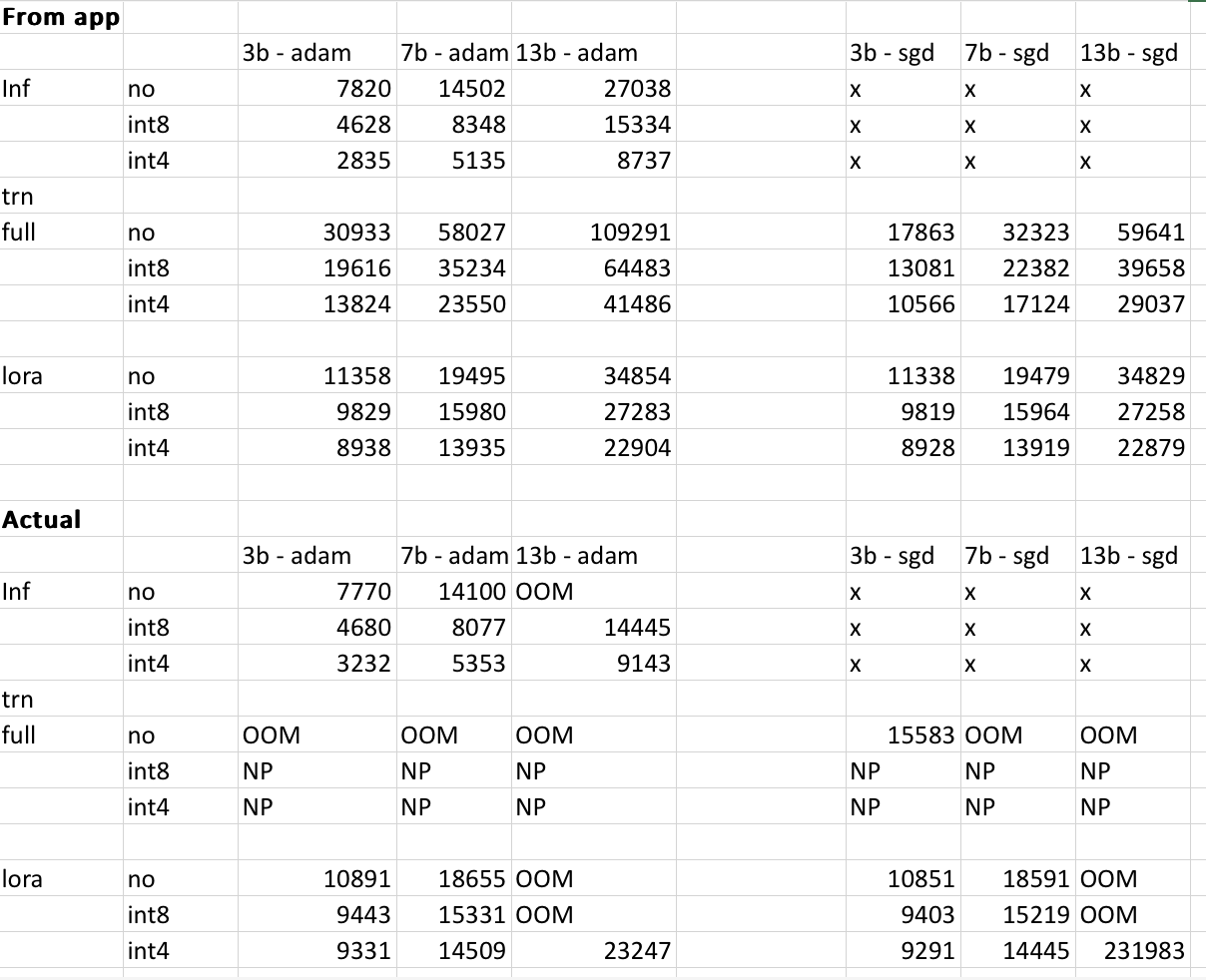
The results can vary depending on your model, input data, cuda version & what quant you are using & it is impossible to predict exact values. I have tried to take these into account & make sure the results are within 500MB. Below table I cross-check 3b,7b & 13b model memories given by the website vs. what what I get on my RTX 4090 & 2060 GPUs. All values are within 500MB.
### How are the values calculated?
`Total memory = model size + kv-cache + activation memory + optimizer/grad memory + cuda etc. overhead`
1. **Model size** = this is your `.bin` file size (divide it by 2 if Q8 quant & by 4 if Q4 quant).
2. **KV-Cache** = Memory taken by KV (key-value) vectors. Size = `(2 x sequence length x hidden size)` _per layer_. For huggingface this `(2 x 2 x sequence length x hidden size)` _per layer_. In training the whole sequence is processed at once (therefore KV cache memory = 0)
3. **Activation Memory** = In forward pass every operation's output has to be stored for doing `.backward()`. For example if you do `output = Q * input` where `Q = (dim, dim)` and `input = (batch, seq, dim)` then output of shape `(batch, seq, dim)` will need to be stored (in fp16). This consumes the most memory in LoRA/QLoRA. In LLMs there are many such intermediate steps (after Q,K,V and after attention, after norm, after FFN1, FFN2, FFN3, after skip layer ....) Around 15 intermediate representations are saved _per layer_.
4. **Optimizer/Grad memory** = Memory taken by `.grad` tensors & tensors associated with the optimizer (`running avg` etc.)
5. **Cuda etc. overhead** = Around 500-1GB memory is taken by CUDA whenever cuda is loaded. Also there are additional overheads when you use any quantization (like bitsandbytes). There is not straightforward formula here (I assume 650 MB overhead in my calculations for cuda overhead)
### Why are the results wrong?
Sometimes the answers might be very wrong in which case please open an issue here & I will try to fix it.
---
### TODO
1. Add support for vLLM for token/s
2. ~Add QLora~ ✅
3. ~Add way to measure approximste tokens/s you can get for a particular GPU~ ✅
4. ~Improve logic to get hyper-params from size~ (since hidden layer/intermediate size/number of layers can vary for a particular size) ✅
5. Add AWQ