https://github.com/ranfysvalle02/captionn
Convolutional Neural Network (CNN) as an encoder and a Long Short-Term Memory (LSTM) network as a decoder to generate captions for images. The model is trained on a custom dataset of images of different shapes and colors, and the captions are generated based on these attributes.
https://github.com/ranfysvalle02/captionn
Last synced: 6 months ago
JSON representation
Convolutional Neural Network (CNN) as an encoder and a Long Short-Term Memory (LSTM) network as a decoder to generate captions for images. The model is trained on a custom dataset of images of different shapes and colors, and the captions are generated based on these attributes.
- Host: GitHub
- URL: https://github.com/ranfysvalle02/captionn
- Owner: ranfysvalle02
- Created: 2024-11-04T12:40:27.000Z (11 months ago)
- Default Branch: main
- Last Pushed: 2024-11-06T04:12:50.000Z (11 months ago)
- Last Synced: 2025-02-16T04:45:02.795Z (8 months ago)
- Language: Python
- Homepage:
- Size: 254 KB
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# captioNN: Building an Image Captioning Model using a [CNN](https://github.com/ranfysvalle02/shapeclassifer-cnn) + [RNN](https://github.com/ranfysvalle02/rnn-4-stocks)
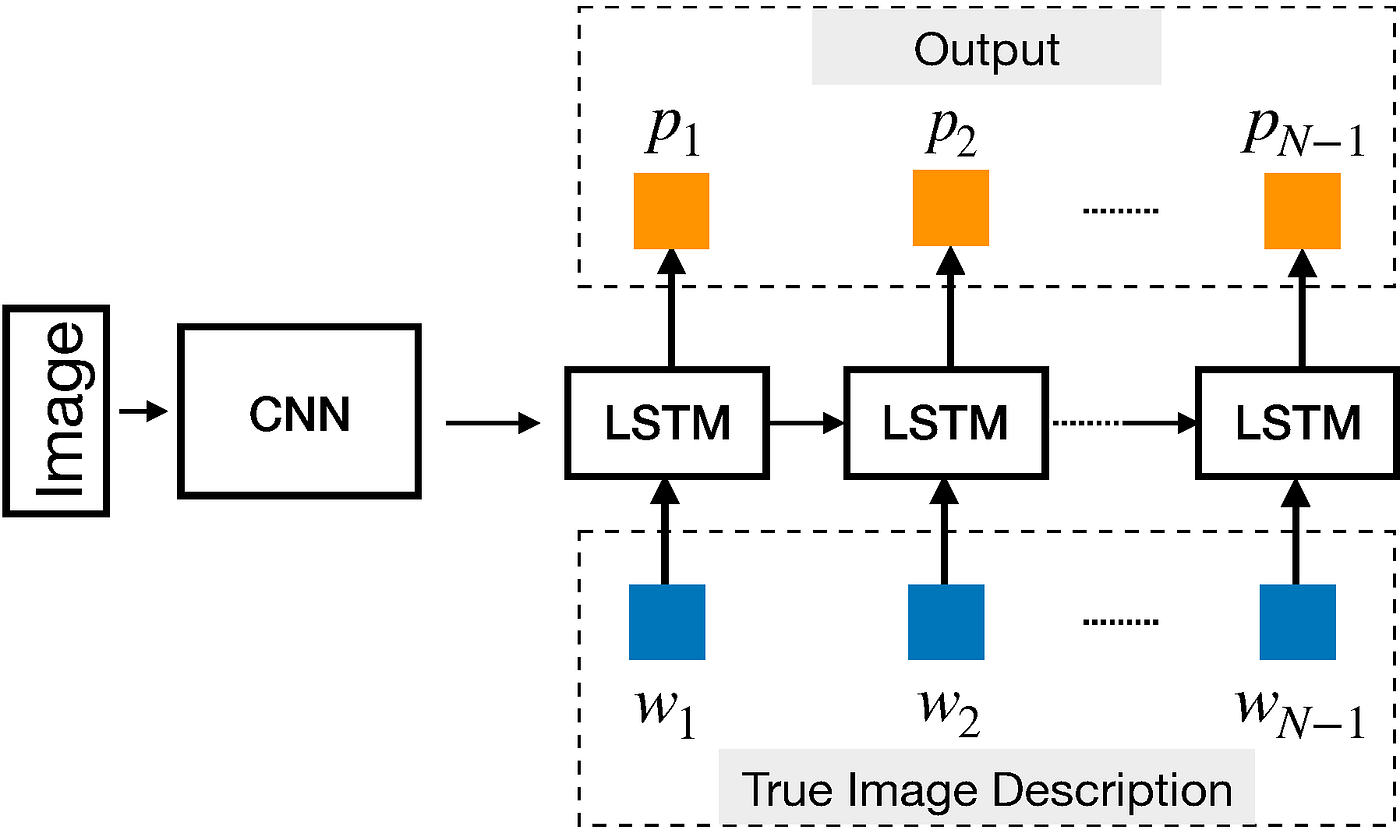
---
## Behind the Scenes: How Does the Magic Work?
Creating a descriptive caption from an image involves several complex steps. Let's break down the magic behind the **captioNN** model:
### Step 1: [Feature Extraction with CNN Encoder](https://github.com/ranfysvalle02/pheature)
The journey starts with the CNN encoder, which extracts high-level features from the input image. By processing the image through convolutional layers (e.g., a pretrained ResNet50), the model identifies essential visual patterns, like edges, shapes, and textures, that help distinguish objects within the image. This transformation reduces the image into a dense feature map, retaining crucial details needed for captioning while discarding unnecessary information. To prepare these features for the next stage, an adaptive pooling layer reduces the feature map to a fixed size, making it compatible with the RNN decoder.
### Step 2: Feature Aggregation – Building a Compact Representation
Once the feature map is created, the model compresses this information into a compact feature vector. By averaging or pooling the feature map, the model produces a fixed-size representation that captures the most salient visual characteristics. This step simplifies the input for the RNN decoder, ensuring it focuses only on the core details required to generate an accurate caption.
### Step 3: Caption Generation with the [RNN](https://github.com/ranfysvalle02/rnn-4-stocks) Decoder
With a compact representation of the image, the RNN decoder, often an LSTM, begins the process of generating a coherent caption. Here’s how it works:
- **Embedding and Decoding:** The decoder starts with an initial hidden state derived from the image features. It receives a `` (start of sentence) token as input and outputs the first word in the caption. This word is embedded into a vector and fed back into the LSTM, along with the previous hidden state.
- **Sequential Prediction:** Word by word, the decoder predicts the next word in the sequence based on both the visual features and the context of previous words. This process continues until the decoder predicts an `` (end of sentence) token, signaling the completion of the caption.
### Step 4: Vocabulary Mapping and Word Selection
Each output from the decoder is a probability distribution over the entire vocabulary. The model selects the word with the highest probability (or applies a search strategy like beam search for more refined results). This word is mapped to a vocabulary token, converting the raw predictions into human-readable text.
### Step 5: Iterating Until the Caption is Complete
The decoder repeats this process, generating words one by one until it reaches the end of the caption. Through this synergy of visual features and sequential processing, the model constructs a coherent and contextually accurate sentence that describes the content of the image.
### The Magic of Fusion: Visual and Linguistic Synergy
By blending feature extraction, compact representation, and sequential prediction, **captioNN** translates visual information into a descriptive sentence. This collaboration between the CNN encoder and RNN decoder makes the model remarkably adept at generating captions that not only capture what’s in the image but also present it in a meaningful and grammatically coherent way.
---
## Table of Contents
1. [Introduction](#introduction)
2. [Creating Synthetic Data](#synthetic-data-generation)
3. [Managing Vocabulary](#vocabulary-management)
4. [Building a Custom Dataset and DataLoader](#custom-dataset-and-dataloader)
5. [Designing the Model: CNN Encoder and LSTM Decoder](#model-architecture-cnn-encoder-and-lstm-decoder)
6. [Training with PyTorch Lightning](#training-with-pytorch-lightning)
7. [Making Predictions and Generating Captions](#inference-and-caption-generation)
8. [Conclusion](#conclusion)
---
## Introduction
Image captioning is a fascinating area that combines computer vision and natural language processing. Its goal is to generate descriptive and coherent sentences that accurately represent the content of an image. This task requires not only a deep understanding of visual elements but also the ability to construct meaningful and grammatically correct sentences.
In this guide, we will explore how to build an image captioning model named **captioNN** using PyTorch and PyTorch Lightning. We will use a synthetic dataset composed of simple geometric shapes, creating a controlled environment that makes it easier to understand each model component. This approach ensures that the model is both easy to understand and maintain, laying a strong foundation for scaling to more complex datasets and architectures.
---
## Creating Synthetic Data
### Why Synthetic Data?
Building an image captioning model requires a carefully curated dataset. **Creating synthetic data** offers several unique advantages that make it a valuable tool in this context:
- **Control:** Synthetic datasets give you full control over data attributes such as shapes, colors, sizes, and positions. This level of control ensures consistency and allows for systematic experimentation with different variables.
- **Simplicity:** By focusing on basic geometric shapes, synthetic data reduces complexity, making it easier to debug and interpret the model's behavior. This simplicity helps to understand basic associations without the noise inherent in real-world data.
- **Reproducibility:** Synthetic data guarantees consistent results across different runs and environments. Removing variability ensures that observations and conclusions drawn are solely due to model performance rather than data inconsistencies.
### Generating Shape Images
Our synthetic data generation process involves creating images featuring specified geometric shapes and colors. By focusing on basic shapes like circles, squares, and triangles, each image has distinct and easily identifiable features. This simplicity is key in facilitating effective learning, allowing the model to form clear associations between visual elements and their textual descriptions.
Imagine a blank canvas where a single, vibrant shape is drawn. The uniformity and clarity of these images ensure that the model's attention is not distracted by unnecessary details, focusing solely on the relationship between the shape's geometry and its corresponding caption.
---
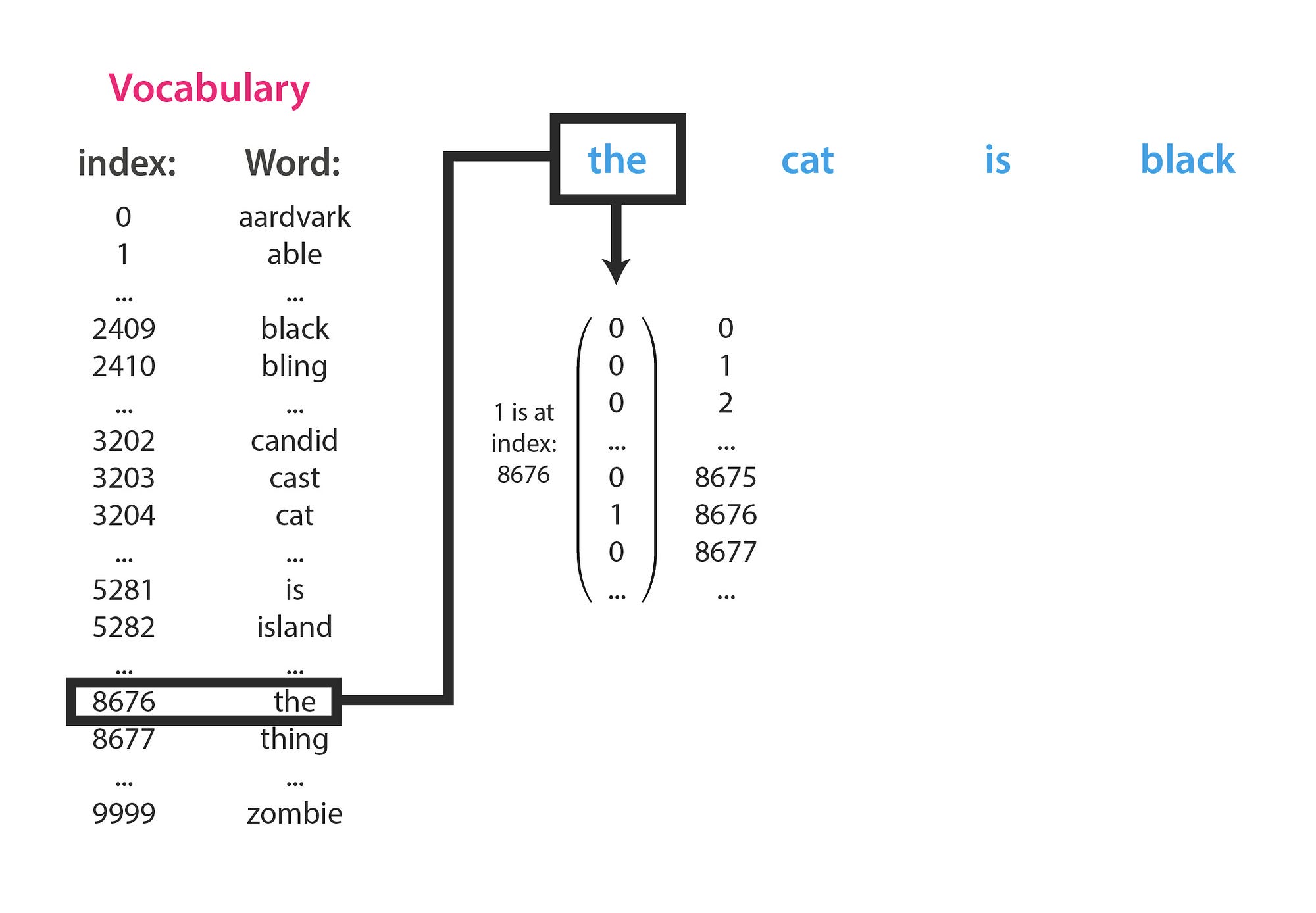
## Managing Vocabulary: The Backbone of Caption Generation
### The Importance of Vocabulary
In the field of natural language processing, **managing vocabulary** is a key task. It involves creating and maintaining mappings between words and unique numerical indices, enabling the model to process and generate language effectively. Proper vocabulary management is not just a technical necessity; it's important in ensuring that the model can handle both known and unknown words effectively, thereby improving the accuracy of caption generation.
### Building a Strong Vocabulary
A well-structured vocabulary serves multiple purposes in the caption generation process:
- **Encoding and Decoding:** It helps translate between human-readable text and numerical data that the model can process. Each word is assigned a unique index, allowing the model to convert captions into sequences of numbers during training and back into text during prediction.
- **Handling Unknown Words:** In real-world scenarios, models often encounter words they haven't seen during training. By incorporating special tokens like `` (unknown), `` (padding), `` (start of sentence), and `` (end of sentence), the model can manage such instances without compromising performance.
- **Sequence Alignment:** Special tokens ensure that sequences of varying lengths can be handled uniformly, allowing for efficient batch processing and consistent model behavior.
### Managing Vocabulary Effectively
Effective vocabulary management involves several key strategies:
1. **Frequency Thresholding:** Words that appear infrequently in the dataset can be replaced with the `` token. This reduces the vocabulary size, focusing the model's capacity on the most informative words.
2. **Inclusion of All Relevant Words:** To handle unseen shapes effectively, it's essential to include all possible shape names in the vocabulary, even if some of them aren't present in the training data. This awareness allows the model to generate captions for new shapes by referencing their corresponding tokens.
3. **Consistent Tokenization:** Ensuring that text is tokenized consistently (e.g., converting to lowercase, removing punctuation) is vital for maintaining uniformity in how words are represented and processed.
### The Vocabulary Class: A Key Component
At the heart of our vocabulary management system is the `Vocabulary` class. This class encapsulates all functionalities required to build, manage, and use the vocabulary effectively. By maintaining mappings between words and indices, tracking word frequencies, and providing methods for tokenization and numericalization, the `Vocabulary` class ensures that the model can seamlessly transition between textual captions and their numerical counterparts.
---
## Handling Unseen Shapes: Improving Model Generalization
### The Challenge of Unseen Data
One of the main challenges in image captioning is enabling the model to **generalize** to inputs it hasn't explicitly seen during training. In our synthetic dataset, while shapes like circles, squares, and triangles are part of the training data, introducing **unseen shapes** like pentagons or hexagons tests the model's ability to adapt and generate accurate captions for new inputs.
### Strategies for Effective Generalization
To help the model handle unseen shapes effectively, several strategies are used:
1. **Comprehensive Vocabulary Inclusion:** By including the names of all potential shapes (both seen and unseen) in the vocabulary, the model remains aware of these words. This knowledge is crucial for generating accurate captions, even if the model hasn't processed images containing them during training.
2. **Distinct Visual Features:** Unseen shapes have unique geometric properties that differentiate them from seen shapes. The model's CNN encoder learns to extract these distinct features, enabling it to associate them with the correct textual descriptions during caption generation.
3. **Consistent Caption Structure:** Maintaining a uniform structure in captions (e.g., "A [color] [shape].") helps the model in predicting the correct sequence of words, ensuring that color and shape descriptors are placed appropriately, regardless of whether the shape is seen or unseen.
### The Power of Synthetic Data in Generalization
The controlled environment provided by synthetic data generation plays a key role in fostering effective generalization:
- **Clear Feature Associations:** By limiting the dataset to distinct shapes with uniform attributes, the model can form clear and unambiguous associations between visual features and their textual descriptions.
- **Focused Learning:** The absence of unnecessary details ensures that the model's learning is focused on the essential relationships between shapes and captions, enhancing its ability to generalize to new shapes.
### Demonstrating Generalization
Consider the following scenarios:
- **Seen Shape:** The model has been trained on triangles. When presented with an image of a blue triangle, it accurately generates the caption "A blue triangle."
- **Unseen Shape:** Although the model hasn't seen pentagons during training, including "pentagon" in the vocabulary allows it to generate the caption "A red pentagon" when presented with a red pentagon image. This success stems from the model's ability to extract pentagon-specific features and reference the correct vocabulary token.
This demonstration underscores the effectiveness of strategic vocabulary management and the benefits of synthetic data in enabling models to generalize beyond their training data.
---
## Building a Custom Dataset and DataLoader
### Creating a Custom Dataset
Creating a custom dataset is key to tailoring the data generation process to meet specific project requirements. In our case, the `ShapeCaptionDataset` class serves this purpose, enabling the generation of image-caption pairs that align with our focus on shapes and vocabulary management.
Key features of the `ShapeCaptionDataset` include:
- **Controlled Shape Selection:** The dataset can include both seen and unseen shapes based on configuration, ensuring flexibility in testing the model's generalization capabilities.
- **Color Diversity:** By selecting from a predefined set of colors, the dataset maintains uniformity while introducing variability through color differentiation.
- **Transformations:** Optional transformations (e.g., resizing, normalization) can be applied to the images, preparing them for optimal processing by the CNN encoder.
### The Role of DataLoaders
DataLoaders play a key role in efficiently feeding data to the model during training and evaluation. They handle batching, shuffling, and parallel processing, ensuring that the model receives data in a format conducive to learning.
In our setup:
- **Batching:** Images and captions are grouped into batches, facilitating efficient computation and gradient updates.
- **Shuffling:** Randomizing the order of data presentation prevents the model from learning spurious patterns and enhances its ability to generalize.
- **Custom Collate Function:** Given the variable lengths of captions, a custom collate function ensures that all captions within a batch are padded to the same length, maintaining consistency and enabling parallel processing.
---
## Designing the Model: CNN Encoder and LSTM Decoder
### Overview of the Architecture
Our image captioning model, **captioNN**, is designed with a clear separation of concerns, leveraging the strengths of Convolutional Neural Networks (CNNs) for feature extraction and Recurrent Neural Networks (RNNs) for language generation. This modular design ensures clarity, maintainability, and scalability, allowing each component to specialize in its designated task.

### CNN Encoder: Extracting Visual Features
At the heart of the visual processing pipeline is the **CNN Encoder**. This component is responsible for transforming raw images into high-level feature representations that encapsulate the essential visual information required for caption generation.
**Key Attributes:**
- **Pretrained Models:** Using a pretrained CNN (e.g., ResNet50) speeds up training and enhances feature extraction capabilities, benefiting from [transfer learning](https://github.com/ranfysvalle02/cnn-transfer-learning/).
- **Feature Extraction:** The CNN processes the input image through multiple convolutional layers, capturing intricate patterns and structures inherent in the shapes and colors.
- **Dimensionality Reduction:** Techniques like adaptive pooling ensure that the extracted features are of a manageable size, balancing computational efficiency with informational richness.
### RNN Decoder: Generating Coherent Captions
Complementing the CNN Encoder is the **RNN Decoder**, typically instantiated as an LSTM (Long Short-Term Memory) network. This component translates the visual features into coherent and contextually appropriate captions.
**Key Attributes:**
- **Sequential Processing:** RNNs excel at handling sequential data, making them ideal for language generation tasks where the order of words is important.
- **Contextual Understanding:** By maintaining hidden states, RNNs capture the context of previously generated words, ensuring that the caption remains coherent and grammatically correct.
- **Vocabulary Integration:** The decoder leverages the managed vocabulary to translate numerical representations back into human-readable text, seamlessly integrating visual information with language constructs.
### Bridging the Gap: From Visual to Linguistic
The seamless interaction between the CNN Encoder and RNN Decoder is key in ensuring that the model can generate accurate and meaningful captions. The CNN extracts the necessary visual features, which are then fed into the RNN, guiding the generation of captions that aptly describe the image's content.
---
## Making Predictions and Generating Captions
### The Caption Generation Process
Once the model has been trained, the process of generating captions for new images involves several key steps:
1. **Image Processing:** The input image is passed through the CNN Encoder to extract its visual features.
2. **Feature Interpretation:** These features are then fed into the RNN Decoder, which begins the process of generating a caption by predicting the most probable sequence of words.
3. **Sequential Generation:** Starting with the `` token, the decoder predicts one word at a time, using the context of previously generated words to inform each subsequent prediction.
4. **Termination:** The generation process continues until the `` token is predicted or a predefined maximum length is reached, ensuring that captions are concise and complete.
### Handling Unseen Shapes During Prediction
A noteworthy aspect of our model is its ability to generate accurate captions for unseen shapes. This capability hinges on two primary factors:
- **Comprehensive Vocabulary Inclusion:** By incorporating all potential shape names (both seen and unseen) into the vocabulary, the model can reference these words even if it hasn't encountered their corresponding images during training.
- **Distinct Feature Representation:** Unseen shapes have unique geometric attributes that the CNN Encoder can capture, allowing the RNN Decoder to associate these distinct features with the correct vocabulary tokens.
This combination of vocabulary management and feature extraction allows the model to generalize effectively, ensuring accurate caption generation for both familiar and new shapes.
### Demonstrating Accurate Caption Generation
Consider the following scenarios:
- **Seen Shape:** The model has been trained on triangles. When presented with an image of a blue triangle, it accurately generates the caption "A blue triangle."
- **Unseen Shape:** Although the model hasn't seen pentagons during training, by including "pentagon" in the vocabulary and recognizing its unique features, it can generate the caption "A red pentagon" when presented with a red pentagon image.
This demonstration underscores the model's robustness and its ability to generalize beyond its training data, a testament to effective vocabulary management and feature extraction.
---
## How the Model Generates Captions for Unseen Shapes
### Understanding Generalization
A fundamental question arises: **How can the model generate accurate captions for shapes it hasn't explicitly seen during training?** The answer lies in the interplay between vocabulary management, feature extraction, and the structured simplicity of the synthetic dataset.
### Vocabulary as the Gatekeeper
Our vocabulary isn't just a list of words; it's a carefully crafted mapping that bridges visual features with linguistic expressions. By ensuring that all potential shape names, including those not present in the training data, are part of the vocabulary, the model remains aware of these words' existence. This awareness is crucial for generating accurate captions for unseen shapes.
### Distinct Feature Extraction
The CNN Encoder's ability to extract unique visual features for each shape plays a key role. Even if a shape like a pentagon wasn't part of the training dataset, its geometric properties (e.g., five sides) are distinct enough for the encoder to capture its essence. These captured features are then relayed to the RNN Decoder, which references the correct vocabulary token to formulate the caption.
### Consistent Caption Structure
The uniformity in caption structure (e.g., "A [color] [shape].") simplifies the model's task, allowing it to predict the correct sequence of words based on the extracted features. This consistency ensures that, regardless of whether a shape is seen or unseen, the model can accurately place color and shape descriptors in their respective positions within the caption.
### The Synergy of Components
The seamless collaboration between the CNN Encoder, RNN Decoder, and the managed vocabulary culminates in a model that not only excels at generating captions for familiar shapes but also demonstrates remarkable adaptability when faced with new inputs. This synergy is a testament to the thoughtful design and strategic management of vocabulary and feature extraction.
---
## Conclusion
In this exploration of **captioNN**, we've traversed the essential components that underpin effective image captioning models. From the controlled simplicity of synthetic data generation to the important role of vocabulary management, each element plays a crucial part in enabling the model to generate accurate and coherent captions.
### **Key Takeaways:**
- **Vocabulary Management:** A well-structured vocabulary is indispensable. It serves as the bridge between visual features and linguistic expressions, enabling the model to handle both seen and unseen words effectively.
- **Handling Unseen Shapes:** Strategic inclusion of all potential shape names in the vocabulary, coupled with the CNN Encoder's ability to extract distinct features, allows the model to generalize effectively, generating accurate captions for new shapes.
- **Modular Architecture:** The clear separation between the CNN Encoder and RNN Decoder fosters maintainability and scalability, allowing each component to specialize in its designated task.
- **Synthetic Data Advantage:** Using synthetic data provides unparalleled control, simplicity, and reproducibility, creating an ideal environment for honing fundamental model capabilities.
Here's an enhanced appendix for your project:
---
## Appendix
### 1. LSTM Architecture: The Sequential Powerhouse
Long Short-Term Memory (LSTM) networks are a type of Recurrent Neural Network (RNN) specifically designed to handle long-term dependencies in sequential data. This ability to retain information over longer sequences makes them particularly suitable for tasks like image captioning, where word order and context are essential.
**Key Components of an LSTM:**
- **Cell State:** The cell state serves as a long-term memory, capable of carrying information across multiple time steps.
- **Input Gate:** Controls the amount of new information added to the cell state.
- **Forget Gate:** Decides which parts of the cell state should be discarded, enhancing the model's ability to focus on relevant information.
- **Output Gate:** Filters the information from the cell state to produce the output, which informs the next prediction in the sequence.
### 2. CNN Encoder Layers: Leveraging Convolutional Features
In **captioNN**, the CNN encoder utilizes a pretrained ResNet model, with convolutional layers designed to capture detailed spatial features from images. This step reduces the image into a feature map, preserving the essential characteristics required for generating captions.
**Convolutional Layers' Key Advantages:**
- **Pattern Recognition:** Convolutional layers identify shapes, edges, and textures, aiding in distinguishing between different geometric shapes.
- **Dimensionality Reduction:** Pooling layers compactly represent the image, ensuring that each feature is manageable without losing crucial details.
### 3. Special Tokens in Vocabulary Management
Vocabulary management is crucial for transforming textual descriptions into a format suitable for model processing and generation. In **captioNN**, the following special tokens are introduced:
- **``:** Used for padding sequences, ensuring consistency in batch processing.
- **`` (Start of Sentence):** Marks the beginning of a caption, guiding the decoder on where to start generating text.
- **`` (End of Sentence):** Indicates the end of a caption, allowing the model to know when to stop generating words.
- **`` (Unknown):** Handles rare or unseen words by providing a placeholder, enabling the model to manage cases where certain vocabulary is missing.
### 4. Training with Synthetic Data: Benefits and Best Practices
Using synthetic data is a valuable approach in **captioNN** for controlled, reproducible experimentation:
- **Advantages of Synthetic Data:**
- **Enhanced Control:** Synthetic datasets allow precise manipulation of attributes like shape, color, and size, facilitating focused learning.
- **Simplified Debugging:** With fewer distractions from real-world noise, synthetic data helps isolate model behavior and associations.
- **Reproducibility:** Synthetic data reduces variability across experiments, making model evaluation more consistent and reliable.
- **Best Practices for Synthetic Data Generation:**
- **Choose Clear, Distinct Features:** Simple shapes and vibrant colors improve interpretability.
- **Establish Consistent Patterns:** Uniform structures in captions (e.g., "A [color] [shape].") support model learning.
- **Consider Scaling and Expansion:** Begin with basic shapes and expand to more complex or real-world images to generalize the model.
### 5. Training and Inference Tips for captioNN
- **Transfer Learning Optimization:** Fine-tune the pretrained CNN layers in small increments to maintain valuable feature extraction abilities without overfitting.
- **Batch Normalization and Regularization:** Apply techniques such as dropout to reduce overfitting, especially when training with a limited synthetic dataset.
- **Adaptive Learning Rate Scheduling:** Use learning rate schedulers to dynamically adjust during training, improving convergence and stability.
### 6. Supervised, Unsupervised, and Self-Supervised Learning
**Different Learning Approaches for Future Enhancements:**
- **Supervised Learning:** Suitable for this project as it requires labeled image-caption pairs for model training.
- **Unsupervised Learning:** For scenarios without labeled captions, clustering and feature extraction techniques might be applied to group similar images.
- **Self-Supervised Learning:** Use unlabeled data by creating pretext tasks (e.g., predicting shape from incomplete captions) to improve the model's robustness.
### 7. Real-World Considerations and Beyond
* **Explainability:** While deep learning models are powerful, understanding their decision-making process can be challenging. Techniques like attention mechanisms can help visualize which parts of the image the model is focusing on when generating each word.
* **Supervised vs Unsupervised vs Semi-Supervised vs Self-Supervised Learning:**
- **Supervised Learning:** Requires a large amount of labeled data.
- **Unsupervised Learning:** Learns patterns from unlabeled data.
- **Semi-Supervised Learning:** Combines both labeled and unlabeled data.
- **Self-Supervised Learning:** Learns from the data itself by creating pretext tasks.
## FULL CODE
```python
import os
import cv2
import numpy as np
import torch
import pytorch_lightning as pl
from torchvision import transforms
from torch.utils.data import DataLoader, random_split, Dataset
from torchvision.transforms import ToTensor
from torch import nn
from torch.optim import Adam
from collections import defaultdict
import string
import torchvision.models as models
from torchvision.models import ResNet50_Weights # Import the weights enum
# Constants
NUM_SAMPLES = 1000
SHAPES = ['square', 'triangle']
UNSEEN_SHAPES = ['circle'] # For demonstration purposes
ALL_SHAPES = SHAPES + UNSEEN_SHAPES
COLORS = {
'red': (255, 0, 0),
'green': (0, 255, 0),
'blue': (0, 0, 255),
'yellow': (255, 255, 0),
'orange': (255, 165, 0),
'purple': (128, 0, 128)
}
IMAGE_SIZE = (256, 256)
BATCH_SIZE = 32
EMBEDDING_DIM = 256
HIDDEN_DIM = 512
NUM_EPOCHS = 10
MAX_CAPTION_LENGTH = 10
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Ensure reproducibility
torch.manual_seed(42)
np.random.seed(42)
# Function to generate shape images
def generate_shape_image(shape, color, size=IMAGE_SIZE):
image = np.zeros(size + (3,), dtype=np.uint8)
cv2_color = COLORS[color]
if shape == 'circle':
center = (np.random.randint(50, size[0]-50), np.random.randint(50, size[1]-50))
radius = np.random.randint(20, 50)
cv2.circle(image, center, radius, cv2_color, thickness=-1)
elif shape == 'square':
top_left = (np.random.randint(0, size[0]-100), np.random.randint(0, size[1]-100))
side_length = np.random.randint(50, 100)
bottom_right = (top_left[0] + side_length, top_left[1] + side_length)
cv2.rectangle(image, top_left, bottom_right, cv2_color, thickness=-1)
elif shape == 'triangle':
pt1 = (np.random.randint(0, size[0]), np.random.randint(0, size[1]))
pt2 = (pt1[0] + np.random.randint(-50, 50), pt1[1] + np.random.randint(50, 100))
pt3 = (pt1[0] + np.random.randint(-50, 50), pt1[1] + np.random.randint(-50, 50))
points = np.array([pt1, pt2, pt3])
cv2.fillPoly(image, [points], cv2_color)
return image
# Function to create captions based on color and shape
def create_caption(color, shape):
return f"A {color} {shape}."
# Vocabulary class
class Vocabulary:
def __init__(self):
self.word2idx = {}
self.idx2word = {}
self.word_freq = defaultdict(int)
self.idx = 0
self.add_word("")
self.add_word("")
self.add_word("")
self.add_word("")
def add_word(self, word):
if word not in self.word2idx:
self.word2idx[word] = self.idx
self.idx2word[self.idx] = word
self.idx += 1
def build_vocabulary(self, captions):
for caption in captions:
tokens = self.tokenize(caption)
for token in tokens:
self.word_freq[token] += 1
if self.word_freq[token] == 1:
self.add_word(token)
def tokenize(self, sentence):
sentence = sentence.lower()
sentence = sentence.translate(str.maketrans('', '', string.punctuation))
return sentence.split()
def numericalize(self, caption):
tokens = self.tokenize(caption)
return [self.word2idx.get(token, self.word2idx[""]) for token in tokens]
def decode(self, indices):
words = []
for idx in indices:
word = self.idx2word.get(idx, "")
if word == "":
break
if word not in ["", ""]:
words.append(word)
return ' '.join(words)
# Custom Dataset
class ShapeCaptionDataset(Dataset):
def __init__(self, num_samples, shapes, colors, transform=None, include_unseen=False):
self.images = []
self.captions = []
self.shapes = shapes.copy()
if include_unseen:
self.shapes += UNSEEN_SHAPES
self.colors = list(colors.keys())
self.transform = transform
for _ in range(num_samples):
shape = np.random.choice(self.shapes)
color = np.random.choice(self.colors)
image = generate_shape_image(shape, color)
caption = create_caption(color, shape) # Renamed function
self.images.append(image)
self.captions.append(caption)
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
image = self.images[idx]
caption = self.captions[idx]
if self.transform:
image = self.transform(image)
return image, caption
# Initialize Vocabulary
caption_vocab = Vocabulary()
# Function to build vocabulary
def build_vocabulary(dataset, vocab):
captions = dataset.captions
vocab.build_vocabulary(captions)
# Collate function for DataLoader
def collate_fn(batch):
images, captions = zip(*batch)
images = torch.stack(images, 0)
captions = [torch.tensor(caption_vocab.numericalize(cap) + [caption_vocab.word2idx[""]]) for cap in captions]
captions_padded = nn.utils.rnn.pad_sequence(captions, batch_first=True, padding_value=caption_vocab.word2idx[""])
return images, captions_padded
# CNN Encoder
class CNNEncoder(nn.Module):
def __init__(self, encoded_image_size=8):
super(CNNEncoder, self).__init__()
self.enc_image_size = encoded_image_size
# Updated model loading with weights enum
resnet = models.resnet50(weights=ResNet50_Weights.IMAGENET1K_V1)
# Remove linear and pool layers (since we're not doing classification)
modules = list(resnet.children())[:-2]
self.resnet = nn.Sequential(*modules)
self.adaptive_pool = nn.AdaptiveAvgPool2d((encoded_image_size, encoded_image_size))
self.fine_tune()
def forward(self, images):
features = self.resnet(images) # (batch_size, 2048, H/32, W/32)
features = self.adaptive_pool(features) # (batch_size, 2048, encoded_image_size, encoded_image_size)
features = features.permute(0, 2, 3, 1) # (batch_size, encoded_image_size, encoded_image_size, 2048)
return features
def fine_tune(self, fine_tune=True):
for p in self.resnet.parameters():
p.requires_grad = False
# If fine-tuning, only fine-tune the layers4
for c in list(self.resnet.children())[5:]:
for p in c.parameters():
p.requires_grad = fine_tune
# LSTM Decoder
class LSTMDecoder(nn.Module):
def __init__(self, embed_dim, hidden_dim, vocab_size, num_layers=1):
super(LSTMDecoder, self).__init__()
self.embed = nn.Embedding(vocab_size, embed_dim)
self.hidden_dim = hidden_dim
self.lstm = nn.LSTM(embed_dim, hidden_dim, num_layers, batch_first=True)
self.linear = nn.Linear(hidden_dim, vocab_size)
self.init_hidden = nn.Sequential(
nn.Linear(2048, hidden_dim),
nn.ReLU()
)
self.init_cell = nn.Sequential(
nn.Linear(2048, hidden_dim),
nn.ReLU()
)
def forward(self, captions, features, lengths):
lengths = lengths.cpu().type(torch.int64) # Ensure lengths are on CPU and int64
embeddings = self.embed(captions) # (batch_size, seq_len, embed_dim)
# Initialize hidden and cell states from image features
h = self.init_hidden(features) # (batch_size, hidden_dim)
c = self.init_cell(features) # (batch_size, hidden_dim)
h = h.unsqueeze(0) # (1, batch_size, hidden_dim)
c = c.unsqueeze(0) # (1, batch_size, hidden_dim)
packed = nn.utils.rnn.pack_padded_sequence(embeddings, lengths, batch_first=True, enforce_sorted=False)
outputs, _ = self.lstm(packed, (h, c))
outputs = self.linear(outputs.data) # (sum(lengths), vocab_size)
return outputs
# Combined Model
class CNN_RNN(pl.LightningModule):
def __init__(self, vocab_size, embed_dim, hidden_dim, learning_rate=1e-3):
super(CNN_RNN, self).__init__()
self.save_hyperparameters()
self.encoder = CNNEncoder()
self.decoder = LSTMDecoder(embed_dim, hidden_dim, vocab_size)
self.criterion = nn.CrossEntropyLoss(ignore_index=caption_vocab.word2idx[""])
self.learning_rate = learning_rate
def forward(self, images, captions, lengths):
features = self.encoder(images) # (batch_size, encoded_image_size, encoded_image_size, 2048)
features = features.mean(dim=[1, 2]) # (batch_size, 2048)
outputs = self.decoder(captions, features, lengths) # (sum(lengths), vocab_size)
return outputs
def training_step(self, batch, batch_idx):
images, captions = batch
captions_input = captions[:, :-1]
captions_target = captions[:, 1:]
lengths = (captions_input != caption_vocab.word2idx[""]).sum(dim=1)
outputs = self.forward(images, captions_input, lengths) # (sum(lengths), vocab_size)
loss = self.criterion(outputs, captions_target.reshape(-1))
self.log('train_loss', loss, prog_bar=True)
return loss
def validation_step(self, batch, batch_idx):
images, captions = batch
captions_input = captions[:, :-1]
captions_target = captions[:, 1:]
lengths = (captions_input != caption_vocab.word2idx[""]).sum(dim=1)
outputs = self.forward(images, captions_input, lengths) # (sum(lengths), vocab_size)
loss = self.criterion(outputs, captions_target.reshape(-1))
self.log('val_loss', loss, prog_bar=True)
def configure_optimizers(self):
optimizer = Adam(self.parameters(), lr=self.learning_rate)
return optimizer
# Function to generate caption using the trained model
def generate_caption(model, image, vocab, max_length=MAX_CAPTION_LENGTH):
model.eval()
transform = transforms.Compose([ToTensor()])
image = transform(image).unsqueeze(0).to(DEVICE)
with torch.no_grad():
features = model.encoder(image) # (1, encoded_image_size, encoded_image_size, 2048)
features = features.mean(dim=[1, 2]) # (1, 2048)
# Initialize hidden and cell states
h = model.decoder.init_hidden(features) # (batch_size, hidden_dim)
c = model.decoder.init_cell(features) # (batch_size, hidden_dim)
h = h.unsqueeze(0) # (1, batch_size, hidden_dim)
c = c.unsqueeze(0) # (1, batch_size, hidden_dim)
caption = [vocab.word2idx[""]]
input_caption = torch.tensor(caption).unsqueeze(0).to(DEVICE) # (1, 1)
for _ in range(max_length):
embeddings = model.decoder.embed(input_caption) # (1, 1, embed_dim)
outputs, (h, c) = model.decoder.lstm(embeddings, (h, c)) # outputs: (1,1,hidden_dim)
logits = model.decoder.linear(outputs.squeeze(1)) # (1, vocab_size)
predicted = logits.argmax(1).item()
if predicted == vocab.word2idx[""]:
break
caption.append(predicted)
input_caption = torch.tensor([predicted]).unsqueeze(0).to(DEVICE) # (1,1)
return vocab.decode(caption[1:])
def main():
# Create Dataset
dataset = ShapeCaptionDataset(NUM_SAMPLES, SHAPES, COLORS, transform=transforms.Compose([ToTensor()]))
build_vocabulary(dataset, caption_vocab)
# Split Dataset
train_size = int(0.8 * len(dataset))
val_size = len(dataset) - train_size
train_dataset, val_dataset = random_split(dataset, [train_size, val_size])
# Data Loaders with num_workers=0 to prevent multiprocessing issues
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, collate_fn=collate_fn, num_workers=0)
val_loader = DataLoader(val_dataset, batch_size=BATCH_SIZE, shuffle=False, collate_fn=collate_fn, num_workers=0)
# Initialize Model
model = CNN_RNN(vocab_size=len(caption_vocab.word2idx), embed_dim=EMBEDDING_DIM, hidden_dim=HIDDEN_DIM)
# Initialize Trainer with Updated Arguments
trainer = pl.Trainer(
max_epochs=NUM_EPOCHS,
accelerator='auto',
devices='auto',
enable_progress_bar=True,
log_every_n_steps=10
)
# Train the Model
trainer.fit(model, train_loader, val_loader)
# Save the trained model
torch.save(model.state_dict(), "cnn_rnn_caption_model.pth")
# Load the model for inference
model = CNN_RNN(vocab_size=len(caption_vocab.word2idx), embed_dim=EMBEDDING_DIM, hidden_dim=HIDDEN_DIM)
model.load_state_dict(torch.load("cnn_rnn_caption_model.pth", map_location=DEVICE))
model.to(DEVICE)
# Demonstration
print("=== Caption Generation Demo ===\n")
# Generate a seen shape (e.g., triangle)
seen_shape = 'triangle'
seen_color = 'blue'
seen_image = generate_shape_image(seen_shape, seen_color)
seen_caption = generate_caption(model, seen_image, caption_vocab)
print(f"Generated Caption for seen shape ({seen_shape}, {seen_color}): {seen_caption}")
# Generate an unseen shape (e.g., circle)
unseen_shape = 'circle'
unseen_color = 'red'
unseen_image = generate_shape_image(unseen_shape, unseen_color)
unseen_caption = generate_caption(model, unseen_image, caption_vocab)
print(f"Generated Caption for unseen shape ({unseen_shape}, {unseen_color}): {unseen_caption}")
if __name__ == "__main__":
main()
"""
=== Caption Generation Demo ===
Generated Caption for seen shape (triangle, blue):
Generated Caption for unseen shape (circle, red):
"""
```