https://github.com/ranfysvalle02/critical-vectors
Extracting Relevant Text Chunks Using Embeddings and Clustering.
https://github.com/ranfysvalle02/critical-vectors
Last synced: 7 months ago
JSON representation
Extracting Relevant Text Chunks Using Embeddings and Clustering.
- Host: GitHub
- URL: https://github.com/ranfysvalle02/critical-vectors
- Owner: ranfysvalle02
- Created: 2024-11-19T04:01:45.000Z (11 months ago)
- Default Branch: main
- Last Pushed: 2024-11-26T04:27:45.000Z (11 months ago)
- Last Synced: 2025-01-26T07:08:56.153Z (9 months ago)
- Language: Python
- Homepage:
- Size: 714 KB
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# critical-vectors
---
# Extracting Relevant Text Chunks Using Embeddings and Clustering
---
## Introduction
When dealing with large volumes of text, it's often necessary to extract the most relevant or representative parts for tasks like summarization, topic modeling, or information retrieval. Manually sifting through extensive text can be time-consuming and impractical. To address this challenge, **CriticalVectors** was born, a Python class that automates the selection of significant text chunks using embeddings and clustering algorithms.
This tool leverages the power of natural language processing (NLP) and machine learning to extract the most relevant or representative parts from large volumes of text. Here is how it works:
- Split text into manageable chunks.
- Compute embeddings for each chunk to capture semantic meaning.
- Cluster the embeddings to identify groups of similar chunks.
- Select representative chunks from each cluster.
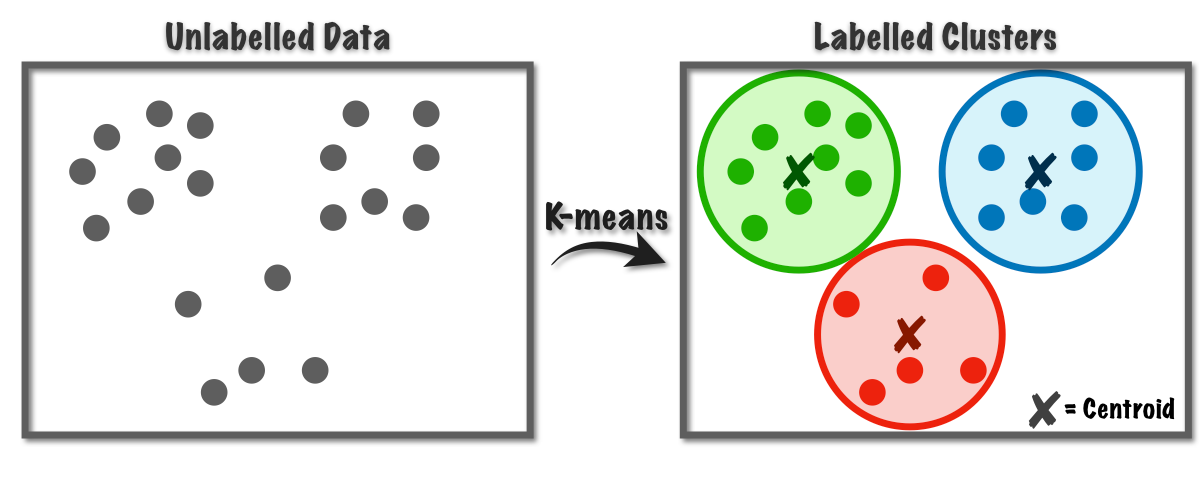
From each cluster, the chunk whose embedding is closest to the centroid (the central point) of that cluster is selected (or more chunks if chunks_per_cluster > 1). This chunk is considered the most representative of its cluster. So, if you have N clusters, you will end up with N representative chunks.
## Key Features
- **Flexible Text Splitting**: Split text into sentences or paragraphs based on your preference.
- **Embeddings with Ollama**: Utilize the `OllamaEmbeddings` model with `'nomic-embed-text'` to compute embeddings.
- **Clustering Strategies**: Choose between KMeans or Agglomerative clustering to group similar text chunks.
- **Automatic Cluster Determination**: Automatically determine the optimal number of clusters based on the data.
- **FAISS Integration**: Optionally use Facebook's FAISS library for efficient clustering on large datasets.
You can choose whether to use FAISS by setting the `use_faiss` parameter during initialization. If `use_faiss` is set to `True`, FAISS will be used for clustering. If it's set to `False`, scikit-learn's implementations of the clustering algorithms will be used instead.
## How It Works
### 1. Text Splitting
The input text is split into smaller chunks to make processing manageable. You can choose to split the text by sentences or paragraphs. Additionally, you can specify the maximum number of tokens per chunk to control the size.
```python
chunks = self.split_text(
text,
method=self.split_method,
max_tokens_per_chunk=self.max_tokens_per_chunk
)
```
### 2. Computing Embeddings
Each text chunk is transformed into an embedding vector using the `OllamaEmbeddings` model. This vector representation captures the semantic meaning of the text.
```python
embeddings = self.compute_embeddings(chunks)
```
### 3. Clustering Embeddings
The embeddings are clustered using either KMeans or Agglomerative clustering. Clustering helps group similar chunks together.
```python
if self.strategy == 'kmeans':
selected_chunks = self._select_chunks_kmeans(chunks, embeddings, num_clusters)
elif self.strategy == 'agglomerative':
selected_chunks = self._select_chunks_agglomerative(chunks, embeddings, num_clusters)
```
### 4. Selecting Representative Chunks
From each cluster, the chunk closest to the centroid (central point) is selected as the representative. This ensures that the selected chunks are the most representative of their respective clusters.
```python
selected_chunks = [chunks[idx] for idx in closest_indices]
```
# Code Explanation
## Initialization
The `CriticalVectors` class is initialized with several parameters:
- **chunk_size** (`int`): The size of each text chunk in characters.
- **strategy** (`str`): The clustering strategy to use. Options include `'kmeans'`, and `'agglomerative'`.
- **num_clusters** (`int` or `'auto'`): The number of clusters to form. If set to `'auto'`, the number of clusters is determined automatically based on the data.
- **chunks_per_cluster** (int): The number of chunks to select from each cluster. This parameter controls the diversity and number of chunks selected.
- **embeddings_model**: The embeddings model to use for generating vector representations of text chunks. Defaults to `OllamaEmbeddings` with the `'nomic-embed-text'` model.
- **split_method** (`str`): The method to split text into chunks. Options are `'sentences'` or `'paragraphs'`.
- **max_tokens_per_chunk** (`int`): This parameter sets the maximum number of words, or tokens, that each chunk of text can contain. For instance, if it's set to 100, each chunk will contain up to 100 words. This is particularly important when working with models that have a limit on the number of words they can process at once.
- **use_faiss** (`bool`): Whether to use FAISS for efficient clustering. Set to `True` to enable FAISS.
## Strategies
The `strategy` parameter determines how the `CriticalVectors` class selects the most relevant chunks from the text. Each strategy has its own advantages and use-cases. Below are the available strategies along with guidance on how to choose between them and examples of their usage.
| Strategy | Description | Pros | Cons | Use Cases |
|-----------------|--------------------------------------------------------------------------------------------------|------------------------------------------------------------|----------------------------------------------------------|---------------------------------------------------------|
| **KMeans** | Uses KMeans clustering to group chunks into clusters and selects the closest chunk to each cluster centroid. | - Handles large amounts of data well.
- Can find representative samples effectively. | - May require manual tuning for number of clusters.
- Clustering quality depends on initialization. | Suitable for general summarization and clustering tasks where representative text segments are required. |
| **Agglomerative Clustering** | Uses a hierarchical approach to cluster the chunks, merging chunks until a desired number of clusters is achieved. | - No need to specify the number of clusters in advance.
- Builds a hierarchy of clusters, which can be informative. | - Computationally expensive for large data sets.
- May not work as well for very large text collections due to complexity. | Useful when a clear hierarchical structure of the text data is beneficial or when the dataset is relatively small. |
Here's a summary of the key aspects of each strategy:
- **KMeans**: This is one of the most popular clustering methods, which works by creating `k` clusters and assigning data points to the nearest cluster center. The approach is well-suited to applications where you want representative samples from distinct groups but requires careful selection of the number of clusters. KMeans is implemented either using **Scikit-Learn** or **FAISS** for accelerated performance.
- **Agglomerative Clustering**: A hierarchical clustering method that recursively merges data points and clusters until a set number of clusters remain. It does not require a specified number of clusters initially, making it more flexible. However, due to its complexity, it is less practical for larger datasets compared to KMeans.
### Recommendations for Use:
- If you need **scalability and efficiency**, especially for large datasets, and can deal with setting cluster numbers, **KMeans** (especially with FAISS) is a good choice.
- When you want **hierarchical relationships** among chunks or you have smaller datasets, **Agglomerative Clustering** provides a good hierarchical breakdown.
If you're looking for a practical approach for summarizing or selecting text from a large document, the **KMeans** strategy with automatic cluster determination (`num_clusters='auto'`) is generally a good starting point due to its balance between simplicity and performance.
### 1. KMeans
**Description**:
KMeans clustering partitions the data into a predefined number of clusters. Each chunk is assigned to the nearest cluster centroid based on its embedding.
**When to Use**:
- When you have a rough estimate of the number of clusters that best represent your data.
- Suitable for large datasets where computational efficiency is a priority.
- When clusters are expected to be roughly spherical in the embedding space.
**Example**:
```python
selector = CriticalVectors(
strategy='kmeans',
num_clusters=10,
chunks_per_cluster=1,
chunk_size=1000,
split_method='sentences',
max_tokens_per_chunk=100,
use_faiss=True
)
relevant_chunks, first_part, last_part = selector.get_relevant_chunks(text)
```
### 2. Agglomerative
**Description**:
Agglomerative Clustering is a hierarchical clustering method that builds nested clusters by successively merging or splitting them based on similarity.
**Agglomerative Hierarchical Clustering (Bottom-Up Approach)**: The most common type of hierarchical clustering. It starts by treating each data point as a single cluster, and then successively merges the closest pairs of clusters until only one cluster (or a specified number of clusters) remains. The "closeness" of two clusters is determined by a distance metric (such as Euclidean distance for numerical data or Jaccard distance for categorical data) and a linkage criterion (such as single, complete, average, or Ward's method).
**When to Use**:
- When you require a hierarchical understanding of the data.
- Suitable for datasets where clusters may not be spherical or have varying densities.
- When interpretability of the cluster hierarchy is important.
**Example**:
```python
selector = CriticalVectors(
strategy='agglomerative',
num_clusters=8,
chunks_per_cluster=1,
chunk_size=1000,
split_method='paragraphs',
max_tokens_per_chunk=150,
use_faiss=False
)
relevant_chunks, first_part, last_part = selector.get_relevant_chunks(text)
```
## Choosing the Right Strategy
Selecting the appropriate clustering strategy depends on the specific requirements of your application and the nature of your data:
- **KMeans** is ideal for standard clustering tasks with a known or estimable number of clusters and when computational efficiency is crucial.
- **Agglomerative** is preferable when you need a hierarchical cluster structure or when dealing with clusters of varying shapes and sizes.
By understanding the characteristics and appropriate use-cases for each strategy, you can effectively leverage the `CriticalVectors` class to select the most relevant and representative chunks from your text data.
### Downloading Content
The `demo_string` method fetches text data from a demo URL.
```python
test_str = demo_string()
```
### Splitting Text
The `split_text` method divides the text into chunks based on the specified method.
```python
chunks = self.split_text(
text,
method=self.split_method,
max_tokens_per_chunk=self.max_tokens_per_chunk
)
```
### Computing Embeddings
Embeddings for each chunk are computed using the specified embeddings model.
```python
embeddings = self.compute_embeddings(chunks)
```
### Selecting Chunks
The most relevant chunks are selected based on the clustering strategy.
```python
selected_chunks = self.select_chunks(chunks, embeddings)
```
### Handling Clustering Internals
#### KMeans Clustering
If using KMeans, FAISS can be utilized for efficient computation.
```python
if self.use_faiss:
kmeans = faiss.Kmeans(d, num_clusters, niter=20, verbose=False)
kmeans.train(embeddings)
else:
kmeans = KMeans(n_clusters=num_clusters, random_state=1337)
kmeans.fit(embeddings)
```
#### Agglomerative Clustering
For Agglomerative clustering, scikit-learn's implementation is used.
```python
clustering = AgglomerativeClustering(n_clusters=num_clusters)
labels = clustering.fit_predict(embeddings)
```
KMeans and Agglomerative Clustering are two popular types of clustering algorithms. Here's a comparison of the two:
1. **Algorithm Structure:**
- **KMeans:** KMeans is a centroid-based or partitioning method. It clusters the data into K groups by minimizing the sum of the squared distances (Euclidean distances) between the data and the corresponding centroid. The algorithm iteratively assigns each data point to one of the K groups based on the features that are provided.
- **Agglomerative Clustering:** Agglomerative Clustering is a hierarchical clustering method. It starts by treating each object as a singleton cluster. Next, pairs of clusters are successively merged until all clusters have been merged into a single cluster that contains all objects. The result is a tree-based representation of the objects, named dendrogram.
2. **Scalability:**
- **KMeans:** KMeans is more scalable. It can handle large datasets because it only needs to store the centroids of the clusters and the data points are clustered based on their distance to the centroids.
- **Agglomerative Clustering:** Agglomerative Clustering is less scalable for large datasets. It needs to store the distance matrix which requires a lot of memory for large datasets.
3. **Number of Clusters:**
- **KMeans:** In KMeans, you need to specify the number of clusters (K) at the beginning.
- **Agglomerative Clustering:** In Agglomerative Clustering, you don't need to specify the number of clusters at the beginning. You can cut the dendrogram at any level and get the desired number of clusters.
4. **Quality of Clusters:**
- **KMeans:** KMeans can result in more compact clusters than hierarchical clustering.
- **Agglomerative Clustering:** Agglomerative Clustering can result in clusters of less compact shape than KMeans.
5. **Use Cases:**
- **KMeans:** KMeans is useful when you have a good idea of the number of distinct clusters your dataset should be segmented into. Typically, it's good for customer segmentation, document clustering, image segmentation, etc.
- **Agglomerative Clustering:** Agglomerative Clustering is useful when you don't know how many clusters you might want to end up with. It's good for hierarchical taxonomies, biological taxonomies, etc.
## Comparing Semantic Extraction and Hierarchical Clustering
### Semantic Extraction
Semantic extraction involves understanding and extracting meaningful information from text. This is often done using techniques like Named Entity Recognition (NER), topic modeling, or semantic embeddings.
**When to Use**: Semantic extraction is useful when you want to understand the content of the text, identify key entities or topics, or transform the text into a structured format.
**Pros**:
1. **Understanding Content**: Semantic extraction can help understand the content of the text at a deeper level, identifying key entities, relationships, and topics.
2. **Structured Information**: It can transform unstructured text into a structured format, making it easier to analyze and use in downstream tasks.
3. **Contextual Understanding**: With advanced NLP models, semantic extraction can capture the context and nuances of the text.
**Cons**:
1. **Complexity**: Semantic extraction can be complex and computationally intensive, especially with large volumes of text.
2. **Accuracy**: The accuracy of semantic extraction depends on the quality of the NLP models used. Errors in the models can lead to incorrect extraction.
### Hierarchical Clustering
Hierarchical clustering is a method of cluster analysis which seeks to build a hierarchy of clusters. In the context of text analysis, it can be used to group similar text chunks together based on their semantic similarity.
**When to Use**: Hierarchical clustering is useful when you want to group similar text chunks together, identify themes or topics in the text, or understand the structure and hierarchy of the content.
**Pros**:
1. **Identifying Themes**: Hierarchical clustering can help identify themes or topics in the text, providing a high-level overview of the content.
2. **Understanding Structure**: It can reveal the structure and hierarchy of the content, showing how different parts of the text are related.
3. **No Need for Predefined Number of Clusters**: Unlike other clustering methods like KMeans, hierarchical clustering doesn't require a predefined number of clusters.
**Cons**:
1. **Loss of Context**: Hierarchical clustering might not preserve the original order or context of the text, especially when used for text summarization or extraction.
2. **Computationally Intensive**: Hierarchical clustering can be computationally intensive, especially with large volumes of text and high-dimensional embeddings.
In summary, semantic extraction and hierarchical clustering serve different purposes and have their own strengths and weaknesses. The choice between the two depends on the specific task at hand and the nature of the text being analyzed.
## Potential Applications
- **Text Summarization**: Extract key chunks of text to create a summary.
- **Topic Modeling**: Identify representative chunks for different topics.
- **Information Retrieval**: Quickly retrieve relevant information from large texts.
- **Preprocessing for NLP Tasks**: Prepare data by selecting significant parts.
## Limitations
1. **Context Preservation**: As mentioned earlier, CriticalVectors might not always preserve the overall narrative or context of the text. This is because it selects individual chunks based on their semantic similarity, which might not align with the original order or flow of the text.
2. **Dependence on Embeddings**: The quality of the extracted chunks heavily depends on the quality of the embeddings used. If the embeddings do not capture the semantic meaning of the text well, the selected chunks might not be truly representative.
3. **Computational Resources**: CriticalVectors can be computationally intensive, especially when dealing with large volumes of text and high-dimensional embeddings. This might limit its usability in resource-constrained environments.
4. **Parameter Tuning**: The performance of CriticalVectors can be sensitive to the choice of parameters like `num_clusters`, `max_tokens_per_chunk`, and `chunk_size`. Finding the right set of parameters might require some experimentation and tuning.
5. **Language Support**: The current implementation of CriticalVectors uses the `OllamaEmbeddings` model and NLTK's sentence tokenizer, which might not support all languages. For languages other than English, additional preprocessing and a different embeddings model might be needed.
6. **FAISS Limitations**: While FAISS provides efficient clustering for large datasets, it only supports Euclidean distance and inner product similarity. This might limit its effectiveness for certain types of data or use cases.
7. **Hierarchical Clustering**: Hierarchical clustering can be computationally expensive for large datasets. Also, the dendrogram produced by hierarchical clustering might not always be easy to interpret, especially for large numbers of clusters.
## "Lost in the Middle" (sortof)
### Context Preservation: A Consideration
While CriticalVectors is a powerful tool for identifying and extracting the most representative chunks of text, it's important to note that it might not always preserve the overall narrative or context of the text. This is particularly true when dealing with long texts or those with complex narratives.
The tool works by selecting individual chunks based on their semantic similarity, which might not align with the original order or flow of the text. Therefore, while it's excellent for extracting key points or topics, it might not always maintain the original storyline or context, especially when the length and complexity of the text increase.
This is not necessarily a limitation, but rather a consideration to keep in mind when using the tool. Depending on your specific use case, you might need to combine the use of CriticalVectors with other methods or tools to ensure that the context or narrative of the text is preserved.
---
## Appendix: Understanding Key Parameters
### How New Chunks Are Created
Depending on the `split_method` chosen, the process of creating new chunks varies:
- If `split_method` is set to 'sentences', the text is first split into individual sentences. These sentences are then grouped into chunks. Once the addition of another sentence would cause a chunk to exceed the `max_tokens_per_chunk` limit, that chunk is completed, and a new chunk is started.
- If `split_method` is set to 'paragraphs', the text is first split into individual paragraphs. These paragraphs are then grouped into chunks. Once the addition of another paragraph would cause a chunk to exceed the `chunk_size` limit, that chunk is completed, and a new chunk is started.
By understanding and appropriately setting these parameters, you can effectively control the granularity and representativeness of the text chunks extracted by the `CriticalVectors` class.
### `max_tokens_per_chunk`
- **Definition**: The maximum number of tokens allowed in each text chunk.
- **Purpose**: Controls the size of each chunk based on token count rather than character count. This is important because models often have token limits.
- **Usage**: When splitting text, sentences are added to a chunk until adding another sentence would exceed the `max_tokens_per_chunk`.
- **Example**: If `max_tokens_per_chunk` is set to `100`, each chunk will contain up to 100 tokens.
```python
max_tokens_per_chunk=100 # Adjust as needed
```
### `num_clusters`
- **Definition**: The number of clusters to form during the clustering step. Can be an integer or `'auto'`.
- **Purpose**: Determines how many representative chunks will be selected.
- **Usage**:
- If set to an integer, that exact number of clusters will be created.
- If set to `'auto'`, the number of clusters is determined automatically based on the data.
- **Automatic Calculation**: When `'auto'`, the number of clusters is calculated as:
```python
num_clusters = max(1, int(np.ceil(np.sqrt(num_chunks))))
```
### `chunk_size`
- **Definition**: The size of each text chunk in characters.
- **Purpose**: Controls the maximum size of a chunk when splitting by paragraphs.
- **Usage**: Primarily used when `split_method` is set to `'paragraphs'`. Chunks are formed by combining paragraphs until the `chunk_size` limit is reached.
- **Example**: If `chunk_size` is `1000`, each chunk will contain up to 1000 characters.
```python
chunk_size=1000
```
### `split_method`
- **Definition**: The method used to split the text into chunks. Options are `'sentences'` or `'paragraphs'`.
- **Purpose**: Determines how the text is divided, affecting the granularity of the chunks.
- **Options**:
- `'sentences'`: Splits the text into sentences and then forms chunks based on `max_tokens_per_chunk`.
- `'paragraphs'`: Splits the text into paragraphs and then forms chunks based on `chunk_size`.
- **Usage**:
```python
split_method='sentences' # or 'paragraphs'
```
### Example Usage of Parameters
```python
selector = CriticalVectors(
strategy='kmeans',
chunks_per_cluster=1,
num_clusters='auto', # Automatically determine the number of clusters
chunk_size=1000, # Maximum size of chunks in characters when using paragraphs
split_method='sentences', # Split the text by sentences
max_tokens_per_chunk=100, # Maximum number of tokens per chunk
use_faiss=True # Use FAISS for efficient clustering
)
```
### Interaction Between Parameters
- When `split_method` is `'sentences'`, the `max_tokens_per_chunk` parameter is used to control chunk sizes.
- When `split_method` is `'paragraphs'`, the `chunk_size` parameter is used instead.
- The `num_clusters` parameter affects how many chunks will be selected as the most relevant.
---
### Real-World Examples
Exploring the practical applications of a text extraction and clustering tool like **CriticalVectors** can open up numerous possibilities across various industries. Here are some concise real-world scenarios where such a class can be effectively utilized:
---
#### 1. **Legal Document Analysis**
**Use Case:**
Law firms handle extensive contracts, case studies, and legal filings. Extracting key clauses and relevant case laws manually is time-consuming.
**Application:**
- **Automated Summarization:** Quickly generate summaries of lengthy contracts to highlight essential terms and conditions.
- **Relevant Case Retrieval:** Identify and retrieve pertinent case studies based on semantic similarity, streamlining legal research.
---
#### 2. **Academic Research and Literature Review**
**Use Case:**
Researchers need to sift through vast amounts of scholarly articles to stay updated and identify relevant studies.
**Application:**
- **Literature Summarization:** Automatically create concise summaries of research papers, focusing on main findings and methodologies.
- **Thematic Clustering:** Organize studies into thematic groups to identify trends and gaps in specific research areas.
---
#### 3. **Customer Feedback and Sentiment Analysis**
**Use Case:**
Businesses receive continuous customer feedback through reviews, surveys, and social media, making manual analysis impractical.
**Application:**
- **Feedback Summarization:** Distill large volumes of customer feedback into key insights, highlighting common praises and complaints.
- **Sentiment Clustering:** Group feedback based on sentiment and topics to identify areas for improvement and strengths.
---
#### 4. **Content Management and Knowledge Bases**
**Use Case:**
Organizations maintain extensive internal documentation and FAQs, requiring efficient organization for easy access.
**Application:**
- **Knowledge Base Optimization:** Identify and highlight the most relevant documents and articles, enhancing information retrieval.
- **Dynamic FAQ Generation:** Automatically generate FAQs by extracting common queries and relevant content from support tickets.
---
#### 5. **Healthcare Data Management**
**Use Case:**
Healthcare professionals manage vast patient records and medical research articles, necessitating efficient information extraction.
**Application:**
- **Patient Record Summarization:** Condense comprehensive patient histories into essential summaries for quick reference.
- **Medical Research Synthesis:** Aggregate findings from multiple studies to provide coherent overviews of medical advancements.
---