https://github.com/ranfysvalle02/deep-q-basics
https://github.com/ranfysvalle02/deep-q-basics
Last synced: 7 months ago
JSON representation
- Host: GitHub
- URL: https://github.com/ranfysvalle02/deep-q-basics
- Owner: ranfysvalle02
- Created: 2025-01-21T02:26:00.000Z (9 months ago)
- Default Branch: main
- Last Pushed: 2025-01-21T02:48:11.000Z (9 months ago)
- Last Synced: 2025-01-21T03:25:51.213Z (9 months ago)
- Size: 0 Bytes
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Empowering Robots to Make Smart Decisions

**Imagine a robot standing at the entrance of a sprawling maze, its mission clear yet challenging: find the hidden treasure at the maze's end while deftly avoiding lurking traps.** To accomplish this, the robot must learn to make smart decisions—choosing the right path at the right time to maximize its chances of success. This journey mirrors how humans make decisions, weighing options, learning from past experiences, and adapting strategies to achieve desired outcomes. In the realm of artificial intelligence, **Deep Q-Learning (DQN)** empowers robots to emulate this decision-making prowess, enabling them to navigate complex environments intelligently.
---
## The Essence of Smart Decision-Making
At the heart of both human and robotic decision-making lies the ability to evaluate options and predict outcomes. When faced with a choice, humans consider past experiences, assess potential rewards and risks, and select actions that align with their goals. Similarly, a robot navigating a maze must evaluate possible moves, anticipate the consequences of each action, and choose paths that lead it closer to the treasure while minimizing encounters with traps.
This parallel between human cognition and machine learning underscores the incredible potential of AI to not only mimic but also enhance our decision-making processes. By understanding and implementing these principles, we can create machines that assist us in ways previously thought impossible.
---
## Designing the Neural Network: The Brain Behind the Decisions
A neural network is like a collection of digital neurons arranged in layers. Here's a breakdown of the key components:
- **Layers:** Think of layers as groups of neurons stacked together. Data flows from one layer to the next.
- **Neurons:** Each neuron takes input, applies a mathematical operation (usually a weighted sum), and passes the result to the next layer.
- **Activation Functions:** After the weighted sum, an activation function (like ReLU) is applied to introduce non-linearity, enabling the network to learn complex patterns.
In Deep Q-Learning, the neural network serves as the robot's brain, processing information about its current state and determining the best possible actions to take. Designing an effective neural network involves understanding fundamental concepts like regression and linear relationships, which are pivotal in how the network interprets and acts upon data.
### Understanding Regression and Linear Relationships
**Regression** is a statistical method used to model and analyze the relationships between variables. In neural networks, regression helps in predicting continuous outcomes based on input data. For instance, in our maze scenario, regression allows the network to estimate the expected rewards associated with each possible action the robot can take from its current position.
**Linear relationships** refer to scenarios where changes in one variable result in proportional changes in another. Neural networks leverage linear transformations (through layers of neurons) to capture these relationships. By stacking multiple layers with non-linear activation functions like ReLU, the network can model complex, non-linear patterns essential for decision-making in dynamic environments like mazes.
### Neural Network Architecture
Our Deep Q-Network employs a straightforward yet robust architecture comprising two hidden layers, each with 128 neurons. This design strikes a balance between having enough capacity to capture the nuances of the environment and maintaining computational efficiency. The network takes the robot's normalized `(x, y)` position as input and outputs Q-values for the four possible actions: moving up, right, down, or left.
Normalization of input data ensures that the robot's position is scaled consistently, facilitating more stable and efficient training. The output layer's Q-values represent the expected cumulative rewards for each action, guiding the robot to make informed decisions that maximize its chances of finding the treasure while avoiding traps.
---
## Learning Through Experience: The Role of Deep Q-Learning
**Deep Q-Learning** is a powerful reinforcement learning algorithm where an agent learns to make decisions by interacting with its environment. The agent aims to learn a policy that maps states to actions, maximizing cumulative rewards over time.
### Exploration vs. Exploitation
A critical aspect of DQN is balancing **exploration** (trying new actions to discover their effects) and **exploitation** (choosing actions that have yielded high rewards in the past). This balance is managed through an **epsilon-greedy policy**, where the agent selects a random action with probability `epsilon` (exploration) and the best-known action with probability `1 - epsilon` (exploitation). Over time, `epsilon` decays, reducing exploration as the agent becomes more confident in its learned policy.
The epsilon-greedy policy is like deciding when to try a new restaurant:
- **Exploration:** Occasionally, you try new places (random actions) to discover hidden gems.
- **Exploitation:** Once you find a favorite, you visit it more often (choosing known good actions).
### Experience Replay
To enhance learning efficiency and stability, DQN utilizes an **experience replay buffer**. This buffer stores past experiences—comprising the state, action, reward, next state, and done flag—allowing the agent to learn from a diverse set of scenarios. Sampling random batches from this buffer breaks the correlation between sequential experiences, leading to more robust learning and preventing the network from overfitting to recent experiences.
### Visualizing Experience Replay

Imagine a video game recording:
1. **Recording Memories (Buffer):** The robot records its experiences as it navigates the maze.
2. **Replay on Demand:** During training, it randomly plays back these memories to learn better.
This replay system ensures the robot learns from diverse experiences, not just recent ones, reducing bias.
---
### Target Network: Stabilizing the Learning Process
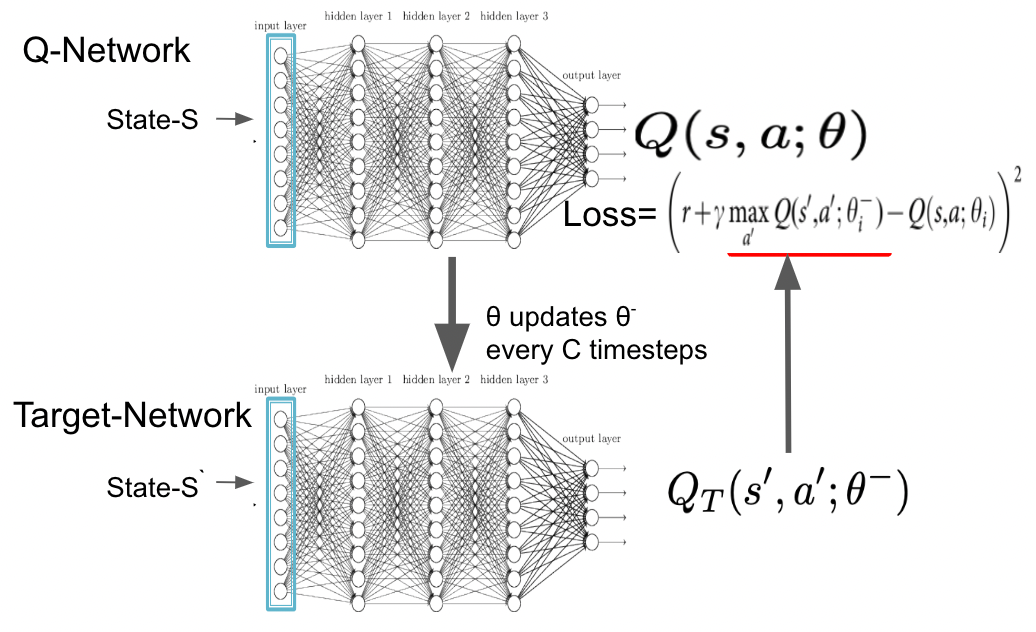
Deep Q-Learning introduces a **target network**, a separate copy of the policy network that remains fixed for a set number of steps. This separation helps stabilize training by providing consistent Q-value targets, reducing oscillations and divergence that can occur when both networks are updated simultaneously. Periodically syncing the target network with the policy network ensures that the agent has a stable reference point for evaluating future actions, enhancing the overall learning stability.
---
## Training the Agent: From Trial to Triumph
Training involves running multiple episodes where the robot interacts with the maze environment, collects experiences, and updates the neural network based on these experiences. Throughout training, the robot's performance is monitored, and progress updates indicate whether it's improving, progressing well, or still learning.
### The Training Journey
1. **Initialization**: The robot starts at the maze's entrance `(0, 0)` with high exploration (`epsilon = 1.0`), meaning it frequently takes random actions to explore the environment.
2. **Action Selection**: Using the epsilon-greedy policy, the robot selects an action.
3. **Environment Interaction**: The robot moves based on the chosen action, receiving a reward and a new state.
4. **Experience Storage**: The experience is stored in the replay buffer.
5. **Network Training**: If sufficient experiences are available, the network samples a batch from the buffer and performs a training step, updating its weights to minimize the difference between predicted and target Q-values.
6. **Epsilon Decay**: Gradually reduces `epsilon` to shift focus from exploration to exploitation.
7. **Target Network Update**: Periodically syncs the target network with the policy network to stabilize training.
Through repeated interactions and learning from past experiences, the robot hones its decision-making abilities, steadily improving its navigation strategy.
### Observing the Learning Progress
Early Episodes: High exploration, random actions, and lower rewards.
Later Episodes: Increased exploitation, more efficient paths, and higher rewards.
---
## Real-World Applications
Machine learning isn't just for games and simple predictions—it powers many amazing technologies we use every day!
### Everyday Magic
- **Weather Forecasting:** Predicting whether it will rain or shine by analyzing patterns in weather data.
- **Smartphones:** Features like autocorrect and voice assistants understand and predict what you need.
- **Streaming Services:** Recommending your favorite movies and shows by recognizing your viewing habits.
---
## Full Code Breakdown: Understanding the Magic Behind the Scenes
Let's take a closer look at how the magic happens with some simple Python code. Don't worry; we'll break it down step by step!
### Defining the Treasure Maze Environment
First, we create a simulated maze environment where the robot can move around, encounter traps, and aim to find the treasure.
```python
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import random
from collections import deque
# Define the TreasureMazeGame environment
class TreasureMazeGame:
def __init__(self):
self.grid_size = 5
self.reset()
def reset(self):
self.state = (0, 0)
self.treasure = (4, 4)
self.traps = [(1, 1), (2, 3), (3, 2)]
return self.state
def step(self, action):
# Actions: 0 = up, 1 = right, 2 = down, 3 = left
x, y = self.state
if action == 0 and x > 0:
x -= 1
elif action == 1 and y < self.grid_size - 1:
y += 1
elif action == 2 and x < self.grid_size - 1:
x += 1
elif action == 3 and y > 0:
y -= 1
self.state = (x, y)
if self.state in self.traps:
return self.state, -10, True # Fell into a trap
if self.state == self.treasure:
return self.state, 10, True # Found the treasure
return self.state, -0.1, False # Each move has a small penalty
def render(self):
grid = [['.' for _ in range(self.grid_size)] for _ in range(self.grid_size)]
x, y = self.state
grid[x][y] = 'R' # Robot
tx, ty = self.treasure
grid[tx][ty] = 'T' # Treasure
for trap in self.traps:
tx, ty = trap
grid[tx][ty] = 'X' # Traps
print("\n".join(" ".join(row) for row in grid))
print("---")
```
**Breaking It Down:**
- **Grid Setup:** The maze is a grid where the robot starts at position `(0, 0)` and aims to reach the treasure at `(4, 4)`. There are traps scattered within the maze that the robot must avoid.
- **Actions:** The robot can move in four directions: up, right, down, or left.
- **Rewards:** Moving into a trap results in a significant negative reward, finding the treasure yields a positive reward, and each move incurs a small penalty to encourage efficiency.
- **Rendering:** The `render` method visually represents the maze, showing the robot, treasure, and traps.
### Designing the Deep Q-Network
Next, we create the neural network that will learn to make decisions based on the robot's state within the maze.
```python
# Define the Deep Q-Network
class DQN(nn.Module):
def __init__(self, state_size, action_size, hidden_size=128):
super(DQN, self).__init__()
self.fc1 = nn.Linear(state_size, hidden_size)
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, hidden_size)
self.relu2 = nn.ReLU()
self.fc3 = nn.Linear(hidden_size, action_size)
def forward(self, x):
x = self.relu1(self.fc1(x))
x = self.relu2(self.fc2(x))
return self.fc3(x)
```
**Breaking It Down:**
- **Layers:** The network consists of two hidden layers with ReLU activation functions, which help in capturing non-linear relationships.
- **Input and Output:** The input layer receives the robot's position, and the output layer provides Q-values for each possible action.
- **Activation Functions:** ReLU introduces non-linearity, enabling the network to model complex patterns.
### Implementing the Replay Buffer
The replay buffer stores past experiences, allowing the agent to learn from a diverse set of scenarios.
```python
# Define Replay Buffer
class ReplayBuffer:
def __init__(self, capacity=20000):
self.buffer = deque(maxlen=capacity)
def push(self, state, action, reward, next_state, done):
self.buffer.append((state, action, reward, next_state, done))
def sample(self, batch_size):
batch = random.sample(self.buffer, batch_size)
state, action, reward, next_state, done = zip(*batch)
state = torch.FloatTensor(state)
action = torch.LongTensor(action).unsqueeze(1)
reward = torch.FloatTensor(reward).unsqueeze(1)
next_state = torch.FloatTensor(next_state)
done = torch.FloatTensor(done).unsqueeze(1)
return state, action, reward, next_state, done
def __len__(self):
return len(self.buffer)
```
**Breaking It Down:**
- **Storage:** Experiences are stored as tuples containing the state, action, reward, next state, and a flag indicating if the episode ended.
- **Sampling:** Random batches are sampled from the buffer to train the network, ensuring the model learns from a variety of experiences.
- **Capacity:** The buffer has a maximum capacity, removing the oldest experiences when full to make room for new ones.
**Key Takeaways:**
- **Capacity:** Limits the buffer to a fixed size.
- **Push:** Adds new experiences to the buffer.
- **Sample:** Retrieves a random batch for training.
### Creating the DQN Agent
The agent interacts with the environment, makes decisions, and learns from experiences.
```python
# Define the DQN Agent
class DQNAgent:
def __init__(
self,
state_size=2, # (x, y) positions
action_size=4, # up, right, down, left
hidden_size=128,
lr=1e-3,
gamma=0.99,
epsilon_start=1.0,
epsilon_end=0.1,
epsilon_decay=0.995,
batch_size=64,
target_update=500,
buffer_size=20000,
min_buffer_size=1000,
):
self.state_size = state_size
self.action_size = action_size
self.gamma = gamma
self.epsilon = epsilon_start
self.epsilon_min = epsilon_end
self.epsilon_decay = epsilon_decay
self.batch_size = batch_size
self.target_update = target_update
self.steps_done = 0
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.policy_net = DQN(state_size, action_size, hidden_size).to(self.device)
self.target_net = DQN(state_size, action_size, hidden_size).to(self.device)
self.target_net.load_state_dict(self.policy_net.state_dict())
self.target_net.eval()
self.optimizer = optim.Adam(self.policy_net.parameters(), lr=lr)
self.criterion = nn.MSELoss()
self.memory = ReplayBuffer(capacity=buffer_size)
self.min_buffer_size = min_buffer_size
def choose_action(self, state, evaluate=False):
state = torch.FloatTensor(state).unsqueeze(0).to(self.device)
if evaluate or random.random() > self.epsilon:
with torch.no_grad():
q_values = self.policy_net(state)
return q_values.argmax().item()
else:
return random.randint(0, self.action_size - 1)
def push_memory(self, state, action, reward, next_state, done):
self.memory.push(state, action, reward, next_state, done)
def train_step(self):
if len(self.memory) < self.min_buffer_size:
return
state, action, reward, next_state, done = self.memory.sample(self.batch_size)
state = state.to(self.device)
action = action.to(self.device)
reward = reward.to(self.device)
next_state = next_state.to(self.device)
done = done.to(self.device)
# Compute current Q values
current_q = self.policy_net(state).gather(1, action)
# Compute next Q values from target network
with torch.no_grad():
max_next_q = self.target_net(next_state).max(1)[0].unsqueeze(1)
target_q = reward + self.gamma * max_next_q * (1 - done)
# Compute loss
loss = self.criterion(current_q, target_q)
# Optimize the model
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
# Update epsilon
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
# Update the target network
if self.steps_done % self.target_update == 0:
self.target_net.load_state_dict(self.policy_net.state_dict())
def save_model(self, path):
torch.save(self.policy_net.state_dict(), path)
def load_model(self, path):
self.policy_net.load_state_dict(torch.load(path))
self.target_net.load_state_dict(self.policy_net.state_dict())
```
---
---
## Key Takeaways
- **State Normalization:** Scaling input features ensures consistent data ranges, facilitating more stable and efficient neural network training.
- **Regression and Linear Relationships:** Understanding how neural networks model linear and non-linear relationships is crucial for designing architectures that can capture the complexities of the environment.
- **Replay Buffer:** Storing and sampling from past experiences breaks temporal correlations, leading to more robust learning.
- **Target Networks:** Providing consistent target Q-values through a separate network stabilizes training and prevents oscillations.
- **Epsilon-Greedy Policy:** Balancing exploration and exploitation is essential for the agent to discover and refine optimal strategies.
- **Neural Network Design:** A well-structured network with appropriate hidden layers and activation functions can effectively model the relationships needed for decision-making in complex environments.
---
## Conclusion: Connecting the Dots
Deep Q-Learning is more than just an algorithm—it's a gateway to teaching machines how to think and act intelligently in dynamic environments. By simulating decision-making processes inspired by human cognition, we empower robots to not just navigate mazes but to tackle real-world challenges with precision and adaptability.
From avoiding traps to finding treasure, the journey of a learning robot mirrors our own—trial, error, and incremental improvement. This parallel underscores the boundless potential of artificial intelligence, where machines don’t merely mimic human abilities but amplify them, opening doors to innovations we’ve yet to imagine.
**Challenge for You**
Can you come up with your own game for a robot to learn? Maybe a maze runner or a treasure hunter? Let your imagination soar and think about how you can teach a machine to make smart decisions just like you!
---
## Appendix: Core Fundamental Concepts
To fully appreciate the intricacies of training a DQN agent, it's essential to understand some core concepts in machine learning and reinforcement learning.
### Neural Networks
A neural network is a series of algorithms that attempt to recognize underlying relationships in a set of data through a process that mimics the way the human brain operates. They consist of layers of interconnected nodes (neurons), where each connection has an associated weight that adjusts as the network learns.
### Regression
Regression is a statistical method used for estimating the relationships among variables. In neural networks, regression is employed to predict continuous outcomes based on input features. For example, predicting the expected reward for each action in a given state.
### Linear Relationships
Linear relationships describe a direct proportional relationship between two variables. In neural networks, linear transformations (via weighted sums) allow the network to model these relationships before applying non-linear activation functions to capture more complex patterns.
### Reinforcement Learning (RL)
RL is a type of machine learning where an agent learns to make decisions by performing actions in an environment to maximize cumulative rewards. Unlike supervised learning, RL does not require labeled input/output pairs but relies on feedback from actions.
### Q-Learning
Q-Learning is a value-based RL algorithm that seeks to learn the quality (Q-value) of actions, telling an agent what action to take under what circumstances. It aims to find the optimal policy that maximizes the expected rewards.
### Deep Q-Learning (DQN)
DQN combines Q-Learning with deep neural networks to handle high-dimensional state spaces. Instead of maintaining a table of Q-values, a neural network approximates the Q-function, allowing the agent to operate in more complex environments.
### Epsilon-Greedy Policy
This policy balances exploration and exploitation by choosing a random action with probability `epsilon` (exploration) and the best-known action with probability `1 - epsilon` (exploitation). It ensures that the agent explores the environment sufficiently while gradually focusing on maximizing rewards.
### Experience Replay
Experience Replay involves storing past experiences in a buffer and sampling random batches from this buffer during training. This technique breaks the correlation between sequential experiences, leading to more stable and efficient learning.
### Target Network
A target network is a copy of the policy network used to provide stable target Q-values during training. Periodically updating the target network with the policy network's weights helps prevent oscillations and divergence in Q-value estimates.
---
---
## Appendix: Connecting Deep Q-Learning with Transformers
### Understanding Transformers
**Transformers** are a type of neural network architecture introduced in the landmark paper "Attention is All You Need" by Vaswani et al. in 2017. Transformers revolutionized natural language processing (NLP) by handling sequential data more efficiently than traditional recurrent neural networks (RNNs) and long short-term memory networks (LSTMs).
**Key Features of Transformers:**
- **Attention Mechanism:** Allows the model to focus on different parts of the input data, capturing contextual relationships more effectively.
- **Parallelization:** Processes input data in parallel rather than sequentially, making training faster on large datasets.
- **Scalability:** Can be scaled to train massive models like GPT-3 with billions of parameters.
---
### Comparing Neural Network Architectures
While both DQN and Transformers utilize neural networks, their architectures and purposes differ significantly.
#### Deep Q-Networks (DQN):
- **Purpose:** Designed for **reinforcement learning**, where an agent learns to make decisions by interacting with an environment to maximize cumulative rewards.
- **Architecture:** Typically consists of fully connected (dense) layers.
- **Input:** Represents the current state of the environment (e.g., robot's position).
- **Output:** Q-values for each possible action, indicating the expected future rewards.
- **Learning Paradigm:** Learns from experiences (state-action-reward sequences) through techniques like experience replay and target networks.
#### Transformers:
- **Purpose:** Primarily used for **sequence modeling tasks** in NLP, such as language translation, text summarization, and content generation.
- **Architecture:**
- **Encoder-Decoder Structure:** Original Transformers consist of an encoder (processes input) and a decoder (generates output).
- **Attention Mechanisms:** Self-attention layers capture relationships between all elements in the input sequence.
- **Positional Encoding:** Adds information about the position of words in the sequence, since the model processes input in parallel.
- **Learning Paradigm:** Trained on large text corpora using unsupervised learning objectives like predicting masked words or the next word in a sequence.
---
### Similarities Between DQN and Transformers
Despite their differences, there are foundational similarities in how these models learn and operate:
1. **Neural Network Foundations:**
- Both models rely on neural networks to approximate complex functions.
- They use layers of neurons with activation functions to model non-linear relationships.
2. **Backpropagation and Optimization:**
- Training involves optimizing weights through backpropagation, minimizing a loss function using algorithms like stochastic gradient descent or its variants (e.g., Adam optimizer).
3. **Scalability with Computational Advances:**
- Both benefit from advancements in computational power (e.g., GPUs, TPUs) to handle large-scale computations and models.
---
### Key Differences in Learning Paradigms
The primary differences stem from the **learning paradigms** and application domains:
#### Reinforcement Learning vs. Unsupervised/Self-Supervised Learning
- **DQN (Reinforcement Learning):**
- **Agent-Environment Interaction:** The model learns by interacting with an environment and receiving feedback in the form of rewards.
- **Goal-Oriented Learning:** Aims to learn a policy that dictates the best action to take in each state to maximize cumulative rewards.
- **Temporal Dynamics:** Considers how actions affect future states and rewards over time.
- **Transformers (Unsupervised/Self-Supervised Learning):**
- **Pattern Recognition in Data:** The model learns patterns and structures within the data without explicit rewards.
- **Predictive Modeling:** Focuses on predicting elements of the input data (e.g., the next word in a sentence) based on context.
- **Static Data Processing:** Processes data sequences as they are, without actions influencing future inputs in training.
---
### The Role of Attention Mechanisms
A fundamental component that sets Transformers apart is the **attention mechanism**, particularly **self-attention**, which allows the model to weigh the importance of different parts of the input data.
- **In Transformers:**
- Self-attention helps the model understand relationships between all words in a sentence, regardless of their position.
- Enables the capture of long-range dependencies, crucial for understanding context and meaning in language.
- **In DQN:**
- Traditional DQN architectures do not incorporate attention mechanisms.
- The model focuses on mapping states to action values without explicit mechanisms to weigh parts of the state differently.
---
### Interplay Between Transformers and Reinforcement Learning
While DQN and Transformers originate from different AI subfields, there has been growing interest in integrating ideas from both:
1. **Transformers in Reinforcement Learning:**
- **Behavioral Cloning and Imitation Learning:**
- Transformers can be used to model policies by learning from sequences of state-action pairs.
- **Trajectory Modeling:**
- Transformers can process entire sequences of states and actions, potentially improving the agent's ability to plan over long horizons.
- **Attention in RL:**
- Incorporating attention mechanisms can help agents focus on relevant parts of the state space, improving decision-making in complex environments.
2. **Reinforcement Learning for Training Transformers:**
- **Fine-Tuning with RL:**
- Models like GPT-3 can be fine-tuned using reinforcement learning from human feedback (RLHF) to produce more aligned and coherent responses.
- **Policy Optimization:**
- Reinforcement learning algorithms optimize policies, which can be applied to guide language models in generating outputs that meet certain criteria (e.g., factual accuracy, style).
---