https://github.com/ranfysvalle02/id-me
Captures real-time audio input, differentiates between speakers, and transcribes their speech into text. It records samples of the user's voice to create a unique voice embedding, allowing the system to distinguish between the user ("Me") and other speakers. It uses two vector spaces—one for "Me" and one for "Not Me"—
https://github.com/ranfysvalle02/id-me
Last synced: 7 months ago
JSON representation
Captures real-time audio input, differentiates between speakers, and transcribes their speech into text. It records samples of the user's voice to create a unique voice embedding, allowing the system to distinguish between the user ("Me") and other speakers. It uses two vector spaces—one for "Me" and one for "Not Me"—
- Host: GitHub
- URL: https://github.com/ranfysvalle02/id-me
- Owner: ranfysvalle02
- Created: 2025-01-04T18:16:27.000Z (10 months ago)
- Default Branch: main
- Last Pushed: 2025-01-04T19:05:19.000Z (10 months ago)
- Last Synced: 2025-01-22T21:19:04.493Z (9 months ago)
- Language: Python
- Homepage:
- Size: 231 KB
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# id-me

__inspired by: https://github.com/ranfysvalle02/live-speaker-id__
---
# Intro: Harnessing Real-Time Voice Identification
This project Captures real-time audio input, differentiates between speakers, and transcribes their speech into text. It records samples of the user's voice to create a unique voice embedding, allowing the system to distinguish between the user ("Me") and other speakers. It uses two vector spaces—one for "Me" and one for "Not Me". We'll unpack the code, discuss the challenges faced during development, and explore the ethical considerations inherent in working with biometric data.
## The Project Overview
The project aims to create a real-time system that:
- **Identifies speakers**: Distinguishes between the enrolled user ("Me") and others ("Not Me").
- **Transcribes speech**: Converts spoken words into text.
- **Operates in real-time**: Processes live audio streams.
---
## Key Components of the Code
### Voice Activity Detection (VAD)
**Purpose**: To detect periods of speech (voiced audio) within the audio stream.
**Implementation**:
- Uses **WebRTC VAD** to process audio frames.
- Frames are classified as speech or non-speech.
- Voiced frames are collected for further processing.
**Challenges**:
- **Accuracy**: Incorrect detection can lead to missed speech or false positives.
- **Latency**: Needs to process frames quickly for real-time performance.
**Mitigation**:
- Adjusting VAD parameters (e.g., aggressiveness level).
- Implementing buffering strategies to smooth out detection.
### Voice Embeddings and Speaker Recognition
**Purpose**: To generate numerical representations (embeddings) of voice segments for comparison.
**Implementation**:
- **SpeechBrain's EncoderClassifier** creates embeddings from audio data.
- **FAISS** indexes embeddings for 'Me' and 'Not Me' speakers separately.
- Similarity scores determine if the current speaker matches the enrolled profile.
**Key Functions**:
- `create_embedding()`: Generates and normalizes embeddings.
- `compare_to_me()`: Computes similarity with 'Me' embeddings.
- `identify_not_me_speaker()`: Identifies or labels new speakers.
**Challenges**:
- **Variability in Speech**: Different speaking conditions affect embeddings.
- **Threshold Determination**: Setting appropriate similarity thresholds for identification.
**Mitigation**:
- Collecting multiple enrollment samples for robustness.
- Experimenting with threshold values based on testing.
### Speech Transcription
**Purpose**: To convert spoken words into text for documentation and analysis.
**Implementation**:
- Utilizes **Vosk**, an open-source offline speech recognition toolkit.
- Processes audio segments identified by VAD for transcription.
**Challenges**:
- **Accuracy**: Transcription errors due to accents, background noise, or speech impediments.
- **Resource Usage**: Real-time transcription can be computationally intensive.
**Mitigation**:
- Using language-specific models optimized for accuracy.
- Ensuring the system runs on capable hardware.
---
## Understanding Voice Identification
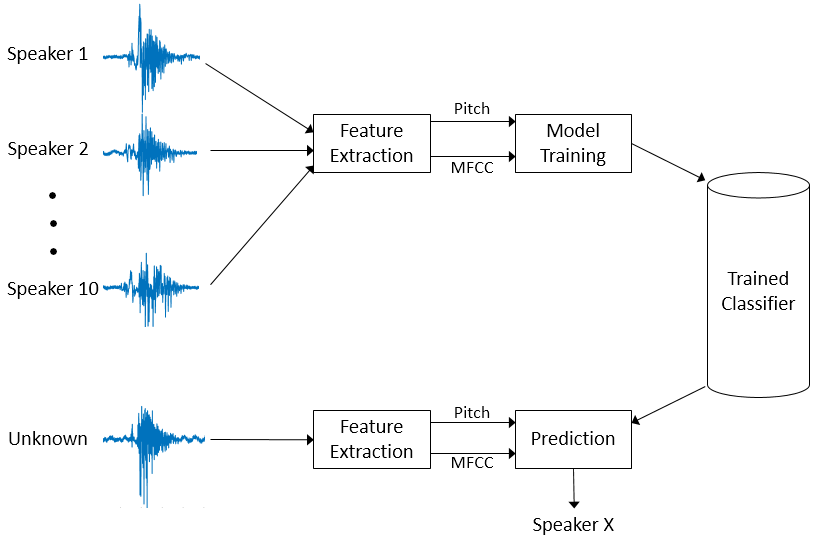
**Voice identification** is the process of recognizing a person based on their unique vocal characteristics. Unlike voice recognition, which converts spoken words into text, voice identification focuses on determining who is speaking.
Key concepts include:
- **Voice Embeddings**: Numerical representations of voice characteristics.
- **Speaker Verification**: Confirming if a voice matches a known profile.
- **Speaker Identification**: Determining who is speaking among a set of known voices.
Applications span across:
- **Security**: Voice biometrics for authentication.
- **Personalization**: Tailoring services based on the identified speaker.
- **Transcription Services**: Identifying speakers in meetings or calls.
---
## Understanding Vector Embeddings and the Vector Space
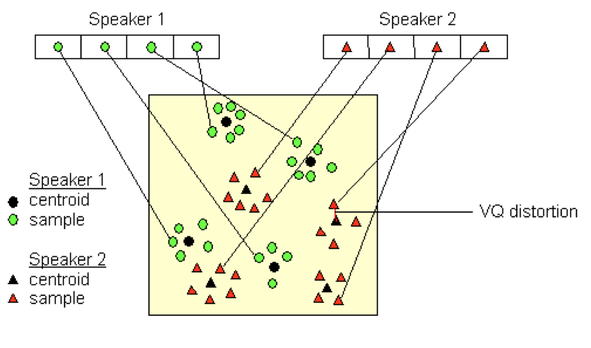
A core component of the speaker identification system is the use of **vector embeddings** to represent voices numerically. This section delves into how these embeddings work and how they enable the system to differentiate between "Me" and "Not Me" voices within a high-dimensional vector space.
### What Are Voice Embeddings?
**Voice embeddings** are fixed-length numerical representations of variable-length audio signals. They capture the unique characteristics of a speaker's voice, such as pitch, tone, and speaking style, in a way that can be compared mathematically.
- **Dimensionality**: In this system, embeddings are 192-dimensional vectors generated by the **ECAPA-TDNN** model from **SpeechBrain**.
- **Normalization**: Embeddings are normalized to have a unit norm, ensuring they lie on the surface of a hypersphere in the 192-dimensional space.
### The Vector Space: "Me" vs. "Not Me"
The vector space is a high-dimensional space where each embedding corresponds to a point on the hypersphere. The proximity of these points reflects the similarity between the voices they represent.
- **"Me" Embeddings**: These are embeddings generated from the user's enrollment recordings. They are stored in a **FAISS index** dedicated to "Me" embeddings.
- **"Not Me" Embeddings**: Embeddings from other speakers encountered during runtime are stored in a separate FAISS index.
### Comparing Embeddings
**Similarity Measurement**:
- **Cosine Similarity**: The system uses cosine similarity to measure how close two embeddings are.
- **Inner Product**: Since the embeddings are normalized, the inner product effectively computes cosine similarity.
**Thresholds**:
- **`ME_THRESHOLD`**: Set to 0.7. If the similarity between an input embedding and the closest "Me" embedding exceeds this threshold, the speaker is identified as "Me".
- **`NOT_ME_THRESHOLD`**: Set to 0.6. Used to determine if a "Not Me" speaker matches an existing "Not Me" embedding.
### Visualizing the Embedding Space
While we can't visualize a 192-dimensional space directly, we can conceptualize it:
- **Clusters**: Embeddings from the same speaker tend to form clusters.
- **Distances**: The distance (or angle, since they are on a hypersphere) between embeddings reflects how similar the voices are.
Consider an embedding space where:
- **"Me" Cluster**: Your voice embeddings are close together, forming a distinct cluster.
- **"Not Me" Clusters**: Each new speaker forms their own cluster in the space, separated from others.
### How the System Uses the Vector Space
1. **Enrollment Phase**:
- Multiple samples of the user's voice are recorded.
- Embeddings are generated and stored in the "Me" FAISS index.
- This forms the "Me" cluster in the vector space.
2. **Runtime Identification**:
- For each voiced segment, an embedding is created.
- **Comparison with "Me"**:
- The embedding is compared against the "Me" index.
- If similarity > `ME_THRESHOLD`, the speaker is identified as "Me".
- **Comparison with "Not Me"**:
- If not "Me," the embedding is compared against the "Not Me" index.
- If similarity > `NOT_ME_THRESHOLD`, the speaker is labeled with the existing "Not Me" speaker label.
- Else, a new speaker label is assigned, and the embedding is added to the "Not Me" index.
### Code Insights: Managing the Vector Space
**Adding Embeddings**:
- **Me Embeddings**:
```python
def add_embedding_to_me_index(self, embedding):
embedding = embedding.reshape(1, -1)
self.me_index.add(embedding)
```
- **Not Me Embeddings**:
```python
def add_embedding_to_not_me_index(self, embedding, label):
embedding = embedding.reshape(1, -1)
self.not_me_index.add(embedding)
index_id = self.not_me_index.ntotal - 1
self.not_me_id_to_label[index_id] = label
```
**Similarity Search**:
- **Compare to "Me"**:
```python
def compare_to_me(self, segment_embedding):
if self.me_index.ntotal == 0:
return 0.0
segment_embedding = segment_embedding.reshape(1, -1)
D, _ = self.me_index.search(segment_embedding, 1)
similarity = D[0][0]
return similarity
```
- **Identify "Not Me" Speaker**:
```python
def identify_not_me_speaker(self, segment_embedding):
segment_embedding = segment_embedding.reshape(1, -1)
if self.not_me_index.ntotal == 0:
# Assign new speaker label
else:
D, I = self.not_me_index.search(segment_embedding, 1)
similarity = D[0][0]
index_id = I[0][0]
if similarity >= self.NOT_ME_THRESHOLD:
# Existing speaker
else:
# New speaker
```
### Analysis of the Output Logs
Looking at the output logs provided:
- **High Similarity to "Me"**:
```
INFO:__main__:Similarity to 'Me': 0.8749
INFO:__main__:[0:00:00 - 0:00:07] [Me] hi my name is fabian can you keep track of this voice for have more than five minutes
```
- The similarity score is above `ME_THRESHOLD`, correctly identifying the speaker as "Me".
- **First Encounter with "Not Me" Speaker**:
```
INFO:__main__:Similarity to 'Me': 0.4935
INFO:__main__:Added new embedding to 'Not Me' FAISS index with label 'Speaker 1'.
```
- Since the similarity to "Me" is below the threshold, the system assigns a new label "Speaker 1" and adds the embedding to the "Not Me" index.
- **Subsequent Matches to "Speaker 1"**:
```
INFO:__main__:Similarity to 'Me': 0.3721
INFO:__main__:Similarity to closest 'Not Me' speaker: 0.7559
INFO:__main__:[0:00:29 - 0:00:33] [Speaker 1] then we wrapped us all into a dataset
```
- The similarity to "Me" remains low.
- High similarity to "Speaker 1" (> `NOT_ME_THRESHOLD`) confirms that it's the same "Not Me" speaker.
- **Switching Back to "Me"**:
```
INFO:__main__:Similarity to 'Me': 0.7118
INFO:__main__:[0:01:01 - 0:01:06] [Me] what about this do you know who's speaking now based on my profile
```
- Similarity to "Me" exceeds the threshold again, correctly re-identifying the user's voice.
### Implications of the Vector Space Separation
- **Clarity in Identification**: By maintaining separate indices for "Me" and "Not Me", the system ensures clear differentiation and avoids confusion between the user's voice and others.
- **Efficiency**: Using FAISS for similarity search allows efficient querying even as the number of embeddings grows.
- **Scalability**: The vector space can accommodate more speakers by adding new embeddings to the "Not Me" index without affecting the "Me" embeddings.
### Potential Enhancements
- **Dynamic Thresholds**: Adjusting thresholds based on statistical analysis of similarity scores could improve accuracy.
- **Clustering Algorithms**: Applying clustering methods to the "Not Me" embeddings might help in better grouping and identifying unknown speakers.
By understanding how vector embeddings and the vector space work in this system, we gain insight into the mathematical foundation that enables accurate speaker identification. It highlights the power of combining signal processing, machine learning, and efficient data structures to solve complex real-time problems.
---
## Challenges and Mitigation Strategies
### Background Noise and Audio Quality
**Problem**: Noise can interfere with VAD, embedding accuracy, and transcription.
**Strategies**:
- Use high-quality microphones with noise-cancellation features.
- Implement digital noise reduction algorithms.
- Conduct enrollment in quiet environments for clean voice profiles.
### Speaker Similarity and Identification Thresholds
**Problem**: Different individuals may have similar vocal characteristics, leading to misidentification.
**Strategies**:
- Collect more enrollment data to capture voice variability.
- Fine-tune similarity thresholds (`ME_THRESHOLD`, `NOT_ME_THRESHOLD`).
- Implement additional authentication factors if security is critical.
### Computational Efficiency
**Problem**: Real-time processing demands significant computational resources.
**Strategies**:
- Optimize code and use efficient data structures.
- Utilize GPUs if available for processing with **PyTorch** and **FAISS**.
- Process audio in chunks to manage workload.
---
## Real-World Applications and Use Cases
### Business Meetings and Transcriptions
In corporate environments, accurately transcribing meetings and attributing statements to the correct speakers is invaluable. This system can:
- **Enhance Meeting Records**: Provide accurate minutes with speaker labels.
- **Improve Accountability**: Clearly identify who made specific comments or decisions.
- **Facilitate Remote Collaboration**: Assist in virtual meetings where participants may have varying audio qualities.
### Customer Service and Call Centers
Voice identification can revolutionize customer interactions by:
- **Personalized Service**: Recognize returning customers and tailor responses based on their history.
- **Security Verification**: Authenticate users through voice biometrics, adding a layer of security.
- **Quality Assurance**: Monitor and evaluate staff performance with accurate speaker attribution.
### Secure Authentication Systems
Implementing voice ID in security protocols offers:
- **Biometric Access Control**: Secure entry systems that recognize authorized personnel.
- **Fraud Prevention**: In financial services, voice ID can prevent unauthorized transactions.
- **Multi-Factor Authentication**: Combine voice ID with other authentication methods for robust security.
### Assistive Technologies
For individuals with disabilities:
- **Hands-Free Control**: Operate devices using voice commands with personalized recognition.
- **Accessibility**: Systems can adapt to the user's speech patterns, including those with speech impairments.
---
## The Code Explained
### Dependencies and Setup
**Required Libraries**:
- `numpy`, `scipy`, `sounddevice`: For audio processing.
- `webrtcvad`: For voice activity detection.
- `faiss`: For similarity search between embeddings.
- `SpeechBrain`, `PyTorch`: For generating voice embeddings.
- `Vosk`: For speech-to-text transcription.
- `queue`, `threading`, `logging`: For real-time processing.
**Setup Instructions**:
1. **Install Dependencies**: Use `pip` to install required packages.
2. **Download Models**:
- **Vosk Model**: Place in the `models/` directory.
- **SpeechBrain Pretrained Model**: Automatically downloaded and saved in `models/spkrec-ecapa-voxceleb`.
3. **Environment Variables**: Set `os.environ["KMP_DUPLICATE_LIB_OK"] = "True"` to handle OpenMP runtime issues.
### Class Structure and Methods
**`SpeakerIdentifier` Class**:
- **Initialization**:
- Sets up sample rates, loads models, initializes indices.
- **Enrollment (`record_enrollment`)**:
- Records samples from the user to create 'Me' embeddings.
- **Voice Activity Detection (`vad_collector`)**:
- Collects voiced frames from the audio stream.
- **Processing Segments (`process_segment`)**:
- Handles speaker identification and transcription for each voiced segment.
- **Embedding Creation**:
- **`create_embedding`**: Generates embeddings from audio data.
- **`add_embedding_to_me_index`**, **`add_embedding_to_not_me_index`**: Manage FAISS indices.
- **Speaker Identification**:
- **`compare_to_me`**: Compares embeddings to 'Me' profile.
- **`identify_not_me_speaker`**: Identifies or labels new speakers.
- **Transcription (`transcribe_audio`)**:
- Uses Vosk to convert audio to text.
- **Audio Callback (`audio_callback`)**:
- Feeds audio data into the processing queue.
- **Runtime Management**:
- **`start_listening`**, **`wait_for_completion`**, **`print_final_transcript`**.
---
## Security Implications and Best Practices
### Potential Vulnerabilities
- **Impersonation Attacks**: Someone attempting to mimic a voice to gain unauthorized access.
- **Replay Attacks**: Using recordings of a person's voice to trick the system.
### Mitigation Techniques
- **Liveness Detection**: Implement checks to ensure the voice is coming from a live person (e.g., prompt for random phrases).
- **Multi-Factor Authentication**: Combine voice ID with other authentication methods like passwords or tokens.
- **Regular Updates**: Keep models and software up-to-date to patch known vulnerabilities.
### Best Practices
- **Secure Communication**: Encrypt data transmissions, especially if the system interfaces with networks or other devices.
- **Access Control**: Limit who can access the system and voice data, enforcing strict permission settings.
- **Audit Trails**: Maintain logs of access attempts and system usage for monitoring and forensic purposes.
---
## Ethical Considerations
### Privacy and Consent
**Issue**: Recording and processing voice data involves personal information.
**Guidelines**:
- **Obtain Consent**: Always inform and get permission from individuals whose voices are being recorded.
- **Transparent Policies**: Clearly communicate how the data will be used and stored.
### Biometric Data Storage
**Issue**: Voice embeddings are biometric identifiers and must be protected.
**Guidelines**:
- **Secure Storage**: Encrypt embeddings and restrict access.
- **Data Minimization**: Store only what is necessary and delete data when it's no longer needed.
- **Compliance**: Follow regulations like GDPR or CCPA regarding biometric data.
### Bias and Fairness
**Issue**: Systems may perform differently across various demographics.
**Guidelines**:
- **Diverse Data**: Train and test the system with diverse voice samples.
- **Continuous Evaluation**: Regularly assess system performance across different groups.
- **Adjust Models**: Update models to address identified biases.
---
## Voice Profiling Nuances
### Accents and Dialects
**Challenge**: Variations in pronunciation can affect both identification and transcription.
**Approach**:
- Use models trained on diverse datasets.
- Allow users to provide enrollment samples that capture their typical speaking patterns.
- Adjust system parameters to be more inclusive.
### Speech Impediments and Variability
**Challenge**: Speech disorders or temporary conditions (like a cold) can alter voice characteristics.
**Approach**:
- Collect enrollment samples over different conditions.
- Implement adaptive algorithms that account for variability.
- Provide users the option to re-enroll if significant changes occur.
---
## Future Directions and Enhancements
Looking ahead, several avenues can enhance the system's capabilities.
### Incorporating Deep Learning Advancements
- **Transformer Models**: Utilize more advanced models like **Wav2Vec 2.0** for improved speech recognition and embeddings.
- **Continuous Learning**: Implement systems that learn and adapt to new voices and speech patterns over time.
### Multilingual Support
- Expand the system to recognize and transcribe multiple languages by integrating language detection and appropriate models.
### User Interface Development
- **Graphical User Interface (GUI)**: Develop a user-friendly interface for easier interaction.
- **Web Integration**: Create web-based applications or services utilizing the system.
### Expanded Ethical Features
- **User Control**: Allow users to access, download, or delete their voice data.
- **Transparency Reports**: Provide insights into how data is used, stored, and protected.
---
## Conclusion
The exploration of real-time voice identification using Python demonstrates the remarkable potential of combining machine learning with audio processing. By dissecting the code and understanding its components, we gain insight into the complexities and considerations necessary for building such systems.
**Key Takeaways**:
- **Interdisciplinary Knowledge**: Successful implementation requires understanding signal processing, machine learning, and ethical considerations.
- **Ethical Responsibility**: Developers must prioritize user privacy, data security, and fairness throughout the project lifecycle.
- **Continuous Improvement**: Ongoing testing, user feedback, and technological advancements drive system enhancements.
Voice identification technology is rapidly evolving, and with responsible development, it holds the promise of making interactions with technology more natural and secure. As we venture further, collaboration and knowledge sharing will be pivotal in harnessing this technology's full potential.
*Embracing voice identification technology offers exciting possibilities. By understanding both its capabilities and responsibilities, we can harness its power to create secure, personalized, and user-friendly applications. Let's continue exploring and innovating responsibly!*
---
## References and Further Reading
1. **SpeechBrain**: [speechbrain.github.io](https://speechbrain.github.io/)
2. **Vosk Speech Recognition Toolkit**: [github.com/alphacep/vosk-api](https://github.com/alphacep/vosk-api)
3. **FAISS (Facebook AI Similarity Search)**: [github.com/facebookresearch/faiss](https://github.com/facebookresearch/faiss)
4. **WebRTC Voice Activity Detector**: [github.com/wiseman/py-webrtcvad](https://github.com/wiseman/py-webrtcvad)
5. **Privacy Regulations**:
- General Data Protection Regulation (GDPR): [gdpr-info.eu](https://gdpr-info.eu)
- California Consumer Privacy Act (CCPA): [oag.ca.gov/privacy/ccpa](https://oag.ca.gov/privacy/ccpa)
6. **Ethical AI Guidelines**:
- **AI Ethics and Fairness**: [ethicsinaction.ieee.org](https://ethicsinaction.ieee.org/)
- **Fairness in Machine Learning**: [fairmlbook.org](http://www.fairmlbook.org/)
---
*Embracing voice identification technology offers exciting possibilities. By understanding both its capabilities and responsibilities, we can harness its power to create secure, personalized, and user-friendly applications. Let's continue exploring and innovating responsibly!*
---
# CODE
```
import os
import sys
import threading
import numpy as np
import sounddevice as sd
from datetime import timedelta
import webrtcvad
import json
from vosk import Model, KaldiRecognizer
import queue
import time
import logging
import torch
from speechbrain.pretrained import EncoderClassifier
# Import FAISS for efficient similarity search
import faiss
"""
OMP: Error #15: Initializing libomp.dylib, but found libomp.dylib already initialized.
OMP: Hint This means that multiple copies of the OpenMP runtime have been linked into the program.
That is dangerous, since it can degrade performance or cause incorrect results.
The best thing to do is to ensure that only a single OpenMP runtime is linked into the process,
e.g. by avoiding static linking of the OpenMP runtime in any library.
As an unsafe, unsupported, undocumented workaround you can set the environment variable KMP_DUPLICATE_LIB_OK=TRUE
to allow the program to continue to execute, but that may cause crashes or silently produce incorrect results.
For more information, please see http://openmp.llvm.org/
"""
os.environ["KMP_DUPLICATE_LIB_OK"] = "True"
# Set up logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class SpeakerIdentifier:
"""
A class to perform real-time speaker identification and transcription using FAISS for efficient vector search.
"""
# Constants for easy tweaking
MODEL_NAME = "models/vosk-model-small-en-us-0.15" # Vosk model directory
CHANNELS = 1 # Number of audio channels (mono)
FRAME_DURATION_MS = 30 # Frame size in milliseconds
VAD_AGGRESSIVENESS = 2 # VAD aggressiveness (0-3)
ME_THRESHOLD = 0.7 # Similarity threshold for 'Me' classification
NOT_ME_THRESHOLD = 0.6 # Similarity threshold for 'Not Me' speaker identification
MIN_SEGMENT_DURATION = 1.0 # Minimum duration of a segment in seconds
def __init__(self):
# Adjust sample rate based on the default input device
try:
default_input_device = sd.query_devices(kind='input')
default_sample_rate = int(default_input_device['default_samplerate'])
self.sample_rate = default_sample_rate if default_sample_rate else 16000
except Exception as e:
logger.error(f"Could not determine default sample rate: {e}")
self.sample_rate = 16000
if self.sample_rate != 16000:
logger.warning(f"Default sample rate is {self.sample_rate} Hz. Adjusting to match the microphone's capabilities.")
# Initialize Vosk model
if not os.path.exists(self.MODEL_NAME):
logger.error(f"Vosk model '{self.MODEL_NAME}' not found. Please download and place it in the script directory.")
sys.exit(1)
logger.info("Loading Vosk model...")
self.model = Model(self.MODEL_NAME)
logger.info("Vosk model loaded.")
# Initialize the voice encoder using SpeechBrain's ECAPA-TDNN model
logger.info("Initializing voice encoder...")
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.encoder = EncoderClassifier.from_hparams(
source="speechbrain/spkrec-ecapa-voxceleb",
savedir="models/spkrec-ecapa-voxceleb",
run_opts={"device": self.device},
)
logger.info("Voice encoder initialized.")
# Determine the embedding dimension
self.embedding_dim = self.get_embedding_dim()
logger.info(f"Embedding dimension: {self.embedding_dim}")
# Initialize FAISS index for 'Me' embeddings collected during enrollment
self.me_index = faiss.IndexFlatIP(self.embedding_dim)
self.me_embeddings = []
self.me_labels = []
# Initialize FAISS index for 'Not Me' embeddings
self.not_me_index = faiss.IndexFlatIP(self.embedding_dim)
self.not_me_id_to_label = {}
self.next_speaker_id = 1 # For 'Not Me' speakers
# Initialize WebRTC VAD
self.vad = webrtcvad.Vad(self.VAD_AGGRESSIVENESS)
# Buffer to hold audio frames
self.audio_queue = queue.Queue()
self.running = True
# For timestamp calculations
self.recording_start_time = None
# List to store transcribed segments
self.transcript_segments = []
# Thread for VAD collector
self.vad_thread = None
def get_embedding_dim(self):
"""
Determines the embedding dimension by running a dummy input through the encoder.
"""
# Create a dummy audio tensor
dummy_audio = torch.zeros((1, 16000)).to(self.device) # 1 second of silence at 16kHz
with torch.no_grad():
embeddings = self.encoder.encode_batch(dummy_audio)
embedding_dim = embeddings.shape[-1]
return embedding_dim
def record_enrollment(self, num_samples=3, duration=5):
"""
Records multiple audio samples for enrollment and stores 'Me' embeddings in FAISS index.
"""
for i in range(num_samples):
logger.info(f"Recording enrollment sample {i + 1}/{num_samples} for {duration} seconds...")
try:
audio_data = sd.rec(int(duration * self.sample_rate),
samplerate=self.sample_rate,
channels=self.CHANNELS,
dtype='int16')
sd.wait()
audio_data = np.squeeze(audio_data)
# Extract voiced audio using VAD
voiced_audio = self.extract_voiced_audio(audio_data)
# Check if voiced audio is sufficient
if len(voiced_audio) < self.sample_rate * self.MIN_SEGMENT_DURATION:
logger.warning("Voiced audio segment is too short. Try speaking clearly into the microphone.")
continue
# Create embedding from voiced audio
embedding = self.create_embedding(voiced_audio)
if embedding is not None:
# Add the embedding to the list
self.me_embeddings.append(embedding)
# Add embedding to 'Me' FAISS index
self.add_embedding_to_me_index(embedding)
except Exception as e:
logger.error(f"Error during enrollment recording: {e}")
sys.exit(1)
if self.me_embeddings:
logger.info(f"{len(self.me_embeddings)} enrollment embeddings created and added to 'Me' FAISS index.")
else:
logger.error("No embeddings were created during enrollment.")
sys.exit(1)
def extract_voiced_audio(self, audio_data):
"""
Extracts voiced frames from the audio data using VAD.
"""
frame_size = int(self.FRAME_DURATION_MS / 1000 * self.sample_rate) # Frame size in samples
frames = [audio_data[i:i + frame_size] for i in range(0, len(audio_data), frame_size)]
voiced_frames = []
for frame in frames:
if len(frame) < frame_size:
# Pad the frame if it's shorter than the expected frame size
frame = np.pad(frame, (0, frame_size - len(frame)), mode='constant')
frame_bytes = frame.tobytes()
is_speech = self.vad.is_speech(frame_bytes, self.sample_rate)
if is_speech:
voiced_frames.extend(frame)
voiced_audio = np.array(voiced_frames, dtype=np.int16)
return voiced_audio
def create_embedding(self, audio_data):
"""
Creates a voice embedding from audio data using SpeechBrain's encoder.
"""
# Check if the audio data is long enough
if len(audio_data) < self.sample_rate * self.MIN_SEGMENT_DURATION:
logger.debug("Audio segment is too short for embedding.")
return None
# Convert audio data to float32 numpy array and normalize
audio_float32 = audio_data.astype(np.float32) / 32768.0
# Convert numpy array to PyTorch tensor and add batch dimension
audio_tensor = torch.from_numpy(audio_float32).unsqueeze(0).to(self.device)
# Generate the embedding
with torch.no_grad():
embeddings = self.encoder.encode_batch(audio_tensor)
embedding = embeddings.squeeze().cpu().numpy()
# Normalize the embedding
embedding = embedding / np.linalg.norm(embedding)
return embedding
def add_embedding_to_me_index(self, embedding):
"""
Adds a 'Me' embedding to the 'Me' FAISS index.
"""
# Reshape embedding to 2D array for FAISS
embedding = embedding.reshape(1, -1)
# Add to 'Me' FAISS index
self.me_index.add(embedding)
logger.info(f"Added new 'Me' embedding to FAISS index. Total 'Me' embeddings: {self.me_index.ntotal}")
def add_embedding_to_not_me_index(self, embedding, label):
"""
Adds a 'Not Me' embedding to the 'Not Me' FAISS index and updates the id_to_label mapping.
"""
# Reshape embedding to 2D array for FAISS
embedding = embedding.reshape(1, -1)
# Add to 'Not Me' FAISS index
self.not_me_index.add(embedding)
# The index ID of the added embedding
index_id = self.not_me_index.ntotal - 1
# Update id_to_label mapping
self.not_me_id_to_label[index_id] = label
logger.info(f"Added new embedding to 'Not Me' FAISS index with label '{label}'. Total 'Not Me' embeddings: {self.not_me_index.ntotal}")
def vad_collector(self):
"""
Collects voiced frames from the audio queue using VAD.
"""
frame_duration = self.FRAME_DURATION_MS / 1000.0
num_padding_frames = int(0.5 / frame_duration) # 0.5 seconds of padding
ring_buffer = []
triggered = False
voiced_frames = []
start_time = None # Initialize start_time
while self.running or not self.audio_queue.empty():
try:
frame = self.audio_queue.get(timeout=1)
except queue.Empty:
if not self.running and self.audio_queue.empty():
break
else:
continue
is_speech = self.vad.is_speech(frame, self.sample_rate)
current_time = time.time()
if not triggered:
ring_buffer.append((frame, is_speech, current_time))
num_voiced = len([f for f, speech, _ in ring_buffer if speech])
if num_voiced > 0.9 * len(ring_buffer):
triggered = True
voiced_frames.extend([f for f, _, _ in ring_buffer])
start_time = ring_buffer[0][2]
ring_buffer = []
elif len(ring_buffer) > num_padding_frames:
ring_buffer.pop(0)
else:
voiced_frames.append(frame)
ring_buffer.append((frame, is_speech, current_time))
num_unvoiced = len([f for f, speech, _ in ring_buffer if not speech])
if num_unvoiced > 0.9 * len(ring_buffer):
end_time = ring_buffer[-1][2]
triggered = False
self.process_segment(voiced_frames, start_time, end_time)
start_time = None # Reset start_time
ring_buffer = []
voiced_frames = []
elif len(ring_buffer) > num_padding_frames:
ring_buffer.pop(0)
# Process any remaining frames regardless of triggered state
if voiced_frames and start_time is not None:
end_time = time.time()
self.process_segment(voiced_frames, start_time, end_time)
else:
logger.debug("No valid segment to process on exit.")
def process_segment(self, frames, start_time, end_time):
"""
Processes a voiced segment: speaker identification and transcription.
"""
# Initialize recording start time if not set
if self.recording_start_time is None:
self.recording_start_time = start_time
# Convert frames to numpy array
segment = b''.join(frames)
segment_audio = np.frombuffer(segment, dtype=np.int16)
# Ignore short segments
duration = end_time - start_time if start_time else 0
audio_duration = len(segment_audio) / self.sample_rate
if duration < self.MIN_SEGMENT_DURATION or audio_duration < self.MIN_SEGMENT_DURATION:
logger.debug("Segment duration is too short, skipping.")
return
# Transcription
transcript = self.transcribe_audio(segment_audio).strip()
# Ignore segments with empty transcripts
if not transcript:
logger.debug("Transcription is empty, skipping segment.")
return
# Speaker identification
try:
# Create an embedding for the current segment
segment_embedding = self.create_embedding(segment_audio)
if segment_embedding is None:
logger.debug("Embedding not created due to short audio segment.")
return
# Normalize embedding
segment_embedding = segment_embedding / np.linalg.norm(segment_embedding)
# Compare to 'Me' embeddings collected during enrollment
me_similarity = self.compare_to_me(segment_embedding)
# Log the similarity score
logger.info(f"Similarity to 'Me': {me_similarity:.4f}")
if me_similarity >= self.ME_THRESHOLD:
speaker_label = "Me"
# Do not add new 'Me' embeddings during runtime
else:
# Not 'Me' speaker
speaker_label = self.identify_not_me_speaker(segment_embedding)
except Exception as e:
logger.error(f"Error during speaker identification: {e}")
speaker_label = "Unknown"
# Display the result
relative_start_time = start_time - self.recording_start_time
relative_end_time = end_time - self.recording_start_time
start_td = str(timedelta(seconds=int(relative_start_time)))
end_td = str(timedelta(seconds=int(relative_end_time)))
logger.info(f"[{start_td} - {end_td}] [{speaker_label}] {transcript}")
# Collect the segment for the final transcript
self.transcript_segments.append({
'start_time': relative_start_time,
'end_time': relative_end_time,
'speaker_label': speaker_label,
'transcript': transcript
})
def compare_to_me(self, segment_embedding):
"""
Computes the maximum similarity between the segment embedding and 'Me' embeddings.
"""
if self.me_index.ntotal == 0:
return 0.0 # No 'Me' embeddings to compare
# Reshape embedding for FAISS
segment_embedding = segment_embedding.reshape(1, -1)
# Search 'Me' index
D, _ = self.me_index.search(segment_embedding, 1)
similarity = D[0][0]
return similarity
def identify_not_me_speaker(self, segment_embedding):
"""
Identifies the speaker among 'Not Me' speakers or assigns a new speaker label.
"""
# Reshape embedding for FAISS
segment_embedding = segment_embedding.reshape(1, -1)
# Avoid adding multiple embeddings for the same speaker unless confident
if self.not_me_index.ntotal == 0:
# No 'Not Me' speakers yet
speaker_label = f"Speaker {self.next_speaker_id}"
self.add_embedding_to_not_me_index(segment_embedding, speaker_label)
logger.info(f"Assigned new speaker label: {speaker_label}")
self.next_speaker_id += 1
return speaker_label
# Search 'Not Me' index
D, I = self.not_me_index.search(segment_embedding, 1)
similarity = D[0][0]
index_id = I[0][0]
# Log the similarity score
logger.info(f"Similarity to closest 'Not Me' speaker: {similarity:.4f}")
if similarity >= self.NOT_ME_THRESHOLD:
# Assign the existing speaker label
speaker_label = self.not_me_id_to_label[index_id]
# Optionally, do not add new embeddings to prevent vector space pollution
else:
# New 'Not Me' speaker
speaker_label = f"Speaker {self.next_speaker_id}"
self.add_embedding_to_not_me_index(segment_embedding, speaker_label)
logger.info(f"Assigned new speaker label: {speaker_label}")
self.next_speaker_id += 1
return speaker_label
def transcribe_audio(self, audio_data):
"""
Transcribes audio data using Vosk.
"""
rec = KaldiRecognizer(self.model, self.sample_rate)
rec.SetWords(True)
audio_bytes = audio_data.tobytes()
rec.AcceptWaveform(audio_bytes)
res = rec.Result()
res_json = json.loads(res)
transcript = res_json.get('text', '')
return transcript
def audio_callback(self, indata, frames, time_info, status):
"""
Callback function for real-time audio processing.
"""
if status:
logger.warning(f"Audio status: {status}")
# Convert audio input to bytes and put into the queue
self.audio_queue.put(indata.tobytes())
def start_listening(self):
"""
Starts the real-time audio stream and voice activity detection.
"""
self.running = True
logger.info("Starting real-time processing. Press Ctrl+C to stop.")
# Start VAD collector in a separate thread
self.vad_thread = threading.Thread(target=self.vad_collector)
self.vad_thread.daemon = True
self.vad_thread.start()
# Start audio stream
try:
with sd.InputStream(
samplerate=self.sample_rate,
channels=self.CHANNELS,
dtype='int16',
blocksize=int(self.sample_rate * (self.FRAME_DURATION_MS / 1000.0)),
callback=self.audio_callback
):
while self.running:
time.sleep(0.1)
except Exception as e:
logger.error(f"Error during audio streaming: {e}")
self.running = False
# Wait for the audio queue to empty
while not self.audio_queue.empty():
time.sleep(0.1)
self.vad_thread.join()
def wait_for_completion(self):
"""
Waits for the VAD collector thread to finish.
"""
if self.vad_thread and self.vad_thread.is_alive():
self.vad_thread.join()
def print_final_transcript(self):
"""
Prints the final transcript collected during the session.
"""
logger.info("\nFinal Transcript:\n")
for segment in self.transcript_segments:
if segment['transcript'].strip(): # Only print if transcript is not empty
start_td = str(timedelta(seconds=int(segment['start_time'])))
end_td = str(timedelta(seconds=int(segment['end_time'])))
print(f"[{start_td} - {end_td}] [{segment['speaker_label']}] {segment['transcript']}")
def main():
speaker_id = SpeakerIdentifier()
try:
speaker_id.record_enrollment(num_samples=3, duration=5)
speaker_id.start_listening()
except KeyboardInterrupt:
logger.info("Interrupted by user.")
speaker_id.running = False # Ensure all threads exit
except Exception as e:
logger.error(f"An error occurred: {e}")
finally:
speaker_id.wait_for_completion()
speaker_id.print_final_transcript()
if __name__ == "__main__":
main()
"""
INFO:__main__:Voice encoder initialized.
INFO:__main__:Embedding dimension: 192
INFO:__main__:Recording enrollment sample 1/3 for 5 seconds...
INFO:__main__:Added new 'Me' embedding to FAISS index. Total 'Me' embeddings: 1
INFO:__main__:Recording enrollment sample 2/3 for 5 seconds...
INFO:__main__:Added new 'Me' embedding to FAISS index. Total 'Me' embeddings: 2
INFO:__main__:Recording enrollment sample 3/3 for 5 seconds...
INFO:__main__:Added new 'Me' embedding to FAISS index. Total 'Me' embeddings: 3
INFO:__main__:3 enrollment embeddings created and added to 'Me' FAISS index.
INFO:__main__:Starting real-time processing. Press Ctrl+C to stop.
INFO:__main__:Similarity to 'Me': 0.8749
INFO:__main__:[0:00:00 - 0:00:07] [Me] hi my name is fabian can you keep track of this voice for have more than five minutes
INFO:__main__:Similarity to 'Me': 0.4935
INFO:__main__:Added new embedding to 'Not Me' FAISS index with label 'Speaker 1'. Total 'Not Me' embeddings: 1
INFO:__main__:Assigned new speaker label: Speaker 1
INFO:__main__:[0:00:24 - 0:00:29] [Speaker 1] eight ten answers to questions
INFO:__main__:Similarity to 'Me': 0.3721
INFO:__main__:Similarity to closest 'Not Me' speaker: 0.7559
INFO:__main__:[0:00:29 - 0:00:33] [Speaker 1] then we wrapped us all into a dataset
INFO:__main__:Similarity to 'Me': 0.2664
INFO:__main__:Similarity to closest 'Not Me' speaker: 0.6841
INFO:__main__:[0:00:33 - 0:00:35] [Speaker 1] the we have the dataset
INFO:__main__:Similarity to 'Me': 0.3929
INFO:__main__:Similarity to closest 'Not Me' speaker: 0.7553
INFO:__main__:[0:00:35 - 0:00:39] [Speaker 1] you're able to start thinking about using rigas
INFO:__main__:Similarity to 'Me': 0.3921
INFO:__main__:Similarity to closest 'Not Me' speaker: 0.7829
INFO:__main__:[0:00:40 - 0:00:58] [Speaker 1] so the way that we're going to do this is by having this create rag as dataset option because remember our answers that we have are considered the ground truth answers but we need to evaluate our l lens answers to these questions right so we have a god truth truth truth through
INFO:__main__:Similarity to 'Me': 0.7118
INFO:__main__:[0:01:01 - 0:01:06] [Me] what about this do you know who's speaking now based on my profile
INFO:__main__:Similarity to 'Me': 0.8236
INFO:__main__:[0:01:14 - 0:01:20] [Me] pretty cool that you can keep track now without having to pollute that factors space
INFO:__main__:Similarity to 'Me': 0.4327
INFO:__main__:Similarity to closest 'Not Me' speaker: 0.7026
INFO:__main__:[0:01:29 - 0:01:36] [Speaker 1] helper function that we are built above ever gonna pass in this specific retriever and that's all we have to do
^CINFO:__main__:Interrupted by user.
INFO:__main__:Similarity to 'Me': 0.3581
INFO:__main__:Similarity to closest 'Not Me' speaker: 0.6591
INFO:__main__:[0:01:37 - 0:01:42] [Speaker 1] we could ask a question what is rag and we rag says virtual
INFO:__main__:
Final Transcript:
[0:00:00 - 0:00:07] [Me] hi my name is fabian can you keep track of this voice for have more than five minutes
[0:00:24 - 0:00:29] [Speaker 1] eight ten answers to questions
[0:00:29 - 0:00:33] [Speaker 1] then we wrapped us all into a dataset
[0:00:33 - 0:00:35] [Speaker 1] the we have the dataset
[0:00:35 - 0:00:39] [Speaker 1] you're able to start thinking about using rigas
[0:00:40 - 0:00:58] [Speaker 1] so the way that we're going to do this is by having this create rag as dataset option because remember our answers that we have are considered the ground truth answers but we need to evaluate our l lens answers to these questions right so we have a god truth truth truth through
[0:01:01 - 0:01:06] [Me] what about this do you know who's speaking now based on my profile
[0:01:14 - 0:01:20] [Me] pretty cool that you can keep track now without having to pollute that factors space
[0:01:29 - 0:01:36] [Speaker 1] helper function that we are built above ever gonna pass in this specific retriever and that's all we have to do
[0:01:37 - 0:01:42] [Speaker 1] we could ask a question what is rag and we rag says virtual
"""
```