https://github.com/ranfysvalle02/q-learning-101
see how ducklings, children on bikes, and a simple "agent" in a maze all share this pattern of learning: exploring the world, dealing with rewards or penalties, and gradually building a mental map of what works.
https://github.com/ranfysvalle02/q-learning-101
Last synced: 7 months ago
JSON representation
see how ducklings, children on bikes, and a simple "agent" in a maze all share this pattern of learning: exploring the world, dealing with rewards or penalties, and gradually building a mental map of what works.
- Host: GitHub
- URL: https://github.com/ranfysvalle02/q-learning-101
- Owner: ranfysvalle02
- Created: 2025-01-18T05:42:39.000Z (9 months ago)
- Default Branch: main
- Last Pushed: 2025-01-19T05:24:15.000Z (9 months ago)
- Last Synced: 2025-01-19T06:18:55.816Z (9 months ago)
- Language: Python
- Homepage:
- Size: 205 KB
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Learning to Navigate: A Q-Learning Adventure
*Breaking free from your [“river of thinking”](https://medium.com/@hihellosura/daring-to-be-different-how-to-get-out-of-your-river-of-thinking-and-come-up-with-winning-idea-268cc28a6f89) by exploring new paths.*

---
## Introduction: Caught in the Same Old Routine?
Have you ever felt stuck in a routine—like you’re floating along in the same “river of thinking,” doing the same things over and over just because they *work*? It’s comfortable to do what you already know—go to the same coffee shop, cook the same meals, watch the same shows. But imagine if you never tried a new restaurant, never tested a different route to work, never explored a new hobby. You’d miss out on so many possibilities!
This is where **epsilon** (in Q-learning) comes in. Think of it as the little voice nudging you to step out of your comfort zone every once in a while. You might discover a fantastic café on the next block—or you might find out it’s closed. Either way, you learn something new.
**Reinforcement Learning (RL)**, and specifically **Q-learning**, mimics this balancing act between “sticking to what we know” (exploitation) and “trying out fresh ideas” (exploration). In the story below, we’ll see how ducklings, children on bikes, and a simple coding agent in a maze all share this pattern of learning: exploring the world, dealing with rewards or penalties, and gradually building a mental map of what works.
Think of your brain as a sponge or a flexible roadmap. Each time you practice something new, like drawing a picture, the sponge reshapes, or the roadmap updates with shortcuts. The more you practice, the stronger and clearer the paths become. For a neural network, this reshaping is like updating its "weights" — tiny rules it learns to better understand and make decisions.
### Reinforcement Learning
Reinforcement learning is like a video game:
- You, the player, start without knowing much.
- Every time you do something good (like defeating an enemy or collecting a coin), the game rewards you with points.
- If you make a mistake (falling into a pit), you get no points or lose points.
- Over time, you figure out the best ways to play, using rewards to guide you to win more often.
For a computer, the rewards help it adjust its "behavior" step by step. Instead of points, it uses math to update how it decides what to do.
---
## The "Agent"
In Q-learning, the **agent** is the decision-maker or learner.
- **Duckling Version**: A freshly hatched duckling that follows its mother, learns to avoid predators, and searches for food.
- **Child-on-a-Bike Version**: A child who’s wobbling around, sometimes falling, sometimes zooming happily forward.
- **In Our Code**: A small program figuring out how to move **up**, **down**, **left**, or **right** in a grid in order to achieve a goal.
All these “agents” have one key thing in common: they learn through trial and error, storing knowledge in a **Q-table** (or “mental map”) that tells them which actions are good and which to avoid.
---
## The Tools (Resources, Knowledge & Parameters)
Just like we have instincts and advice from friends or family, an RL agent has **hyperparameters** that shape how it learns:
1. **Alpha – Learning Rate**
Think of it as how fast you absorb new information. Too high, and you overreact to every outcome; too low, and you might ignore valuable lessons.
2. **Gamma – Discount Factor**
This decides whether you’re focused on the short term or the long haul. A high gamma values future rewards (like the duckling learning to find a big pond later), while a low gamma chases tiny, quick wins.
3. **Epsilon – Exploration Rate**
This is your willingness to break out of your “river of thinking” and try something new. Maybe you try a different coffee shop or a new route home. Sure, it might not always work out—but sometimes, it leads to something amazing.
The epsilon-greedy algorithm is a technique used in reinforcement learning to balance exploration and exploitation.
* **Exploration** involves trying new actions, even if they seem less promising, to discover potentially better options.
* **Exploitation** involves consistently choosing the action that has historically yielded the best rewards.
## Epsilon-Greedy
Epsilon-greedy introduces a controlled amount of randomness into the decision-making process.
* A small probability, called epsilon (ε), is defined.
* With probability ε, the algorithm chooses a random action, encouraging exploration.
* With probability (1 - ε), the algorithm chooses the action that currently appears to have the highest expected reward, favoring exploitation.
By carefully adjusting the value of epsilon, the algorithm can strike a balance between discovering new opportunities and maximizing immediate rewards. This allows the agent to learn effectively and adapt to changing environments.
---
## The Environment (The World Around You)
The **environment** is everything that’s not the agent—basically the setting where you learn:
- **In the Duckling’s World**: A pond filled with lily pads, reeds, and the occasional predator.
- **For the Child on a Bike**: Sidewalks, roads, or a bike park with smooth paths (positive experiences) and potholes (negative rewards).
- **In Our Q-Learning Code**: A simple grid with walls (`0`), open paths (`1`), and a goal (`9`).
Just as a duckling learns which parts of the pond are safe, our agent learns which parts of the grid to avoid.
---
## Q-Learning (How It All Comes Together)
**Q-Learning** is an iterative process:
1. **Observe**: The agent sees what’s around (like a duckling spotting food or danger).
2. **Decide**: Based on its Q-table and epsilon-greedy strategy, it chooses to either exploit what it knows or explore something new.
3. **Experience**: It gets a **reward** (or penalty) for what just happened.
4. **Update**: The agent revises its Q-table—akin to the duckling updating its “mental map”: “this area is safe,” or “that direction leads to trouble.”
5. **Repeat**: Over many tries (episodes), the agent’s decisions get better and more informed.
Ultimately, the agent learns to identify what’s **similar** in different scenarios (e.g., all these open paths with no walls around might be good) and what’s **dissimilar** (e.g., that corner with a predator or a dead-end is definitely not the same).
---
## Episodes (A Series of Repetitions)
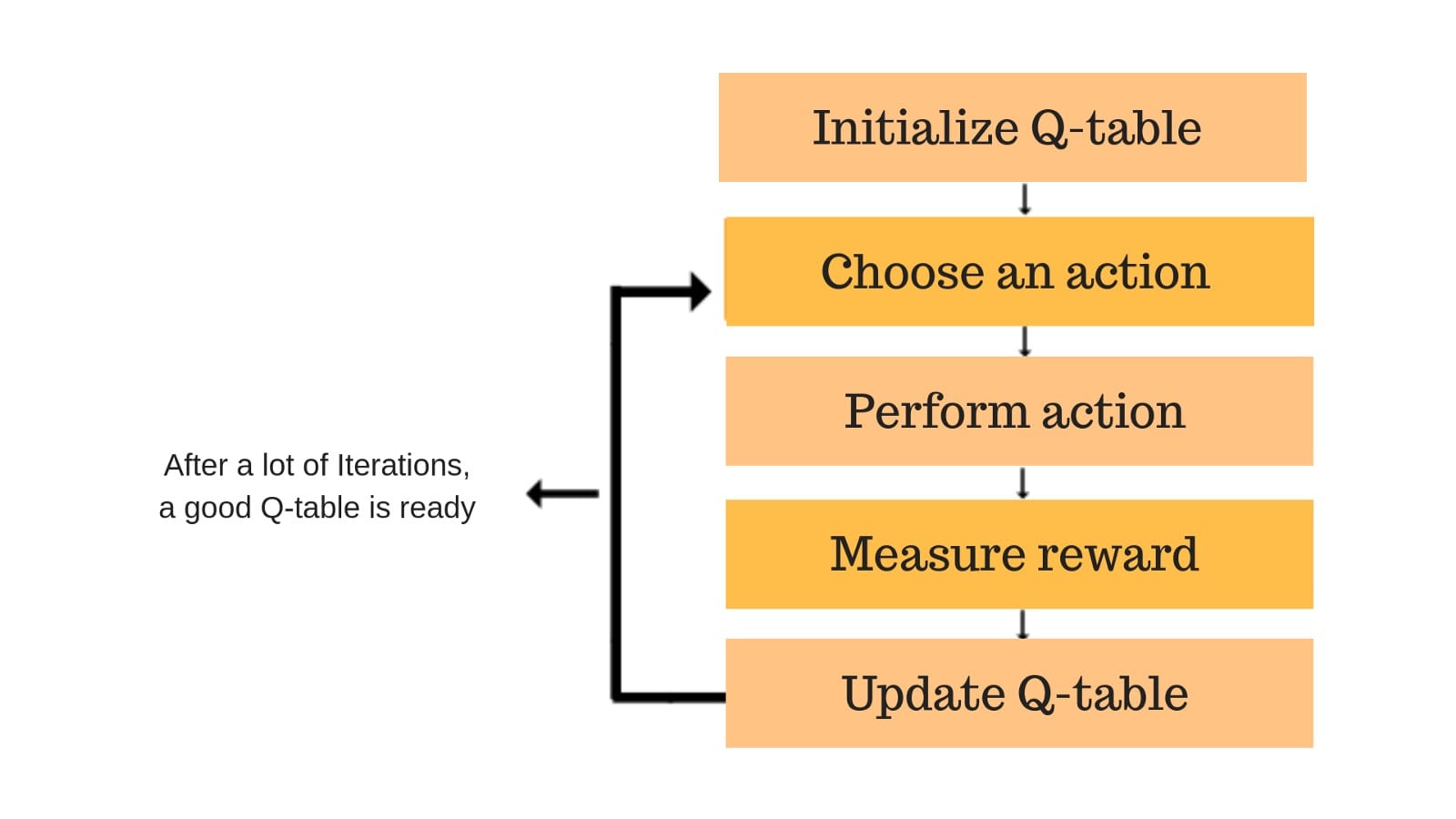
An **episode** is one full run—start at some position, act until you reach the goal or get stuck, then reset.
- **Duckling**: Each day, waking up, searching for food, encountering obstacles, returning to safety. Next day, same process but a little wiser.
- **Child on a Bike**: Each attempt at riding is an episode—some successes, some wipeouts, but lessons get learned each time.
- **Maze Agent**: We place our agent at `(1,1)`, let it navigate until it finds `9` or gets trapped. Then we reset and try again.
This repetition refines the knowledge stored in the Q-table (or the duckling’s instincts, or the biker’s balance).
---
## An Ultra-Simple Q-Learning Maze Example

In a minimal coding setup:
1. We define a **maze** (the environment).
2. We initialize a **Q-table** (the agent’s memory).
3. We set our **hyperparameters** (alpha, gamma, epsilon).
4. Through **episodes**, the agent explores, collects rewards, and updates its Q-table.
5. After many trials, it reliably finds the goal.
Just as the duckling grows from clumsy waddles to smooth swimming, the Q-learning agent evolves from random moves to a purposeful strategy.
---
### The Code Walkthrough
If you’ve ever watched a duckling swim across a pond, you know how quick they are to learn what works and what doesn’t. One day, they might discover where the tasty treats lie, the next they’re charting new courses to get there faster. In **Reinforcement Learning (RL)**, we strive to replicate this kind of trial-and-error learning in a computational way.
Below is a high-level view of the main components in `demo.py`:
1. **Environment Setup**
- A NumPy array `POND` specifies the layout (rocks, water, and treat).
- A starting position `START_POS` is defined.
2. **Possible Actions**
- We encode the actions as numeric keys (0=up, 1=right, 2=down, 3=left).
- We map each action to row/column changes like `(-1, 0)` for up or `(0, 1)` for right.
3. **Helper Functions**
- `is_valid_position(pos)`: Checks if the new position is within the grid and not a rock.
- `get_next_position(current_pos, action)`: Calculates the duckling’s next position. If invalid, it stays put.
- `get_reward(pos)`: Returns +10 if the duckling reaches the treat, otherwise -0.1.
- `is_goal(pos)`: Checks if the duckling is on the cell with the tasty treat.
4. **Q-Table Initialization**
- We maintain a dictionary `Q_table` keyed by `(row, col)`, where each value is a list of Q-values for each action.
- If a state doesn’t exist in `Q_table` yet, we initialize it with `[0.0, 0.0, 0.0, 0.0]`.
5. **Training Loop**
- We run the Q-learning for `NUM_EPISODES` episodes, each with a maximum number of steps.
- For each step:
1. **Epsilon-Greedy Action Selection**:
- With probability `EPSILON`, choose a random action.
- Otherwise, choose the action with the highest Q-value.
2. **State Transition**:
- Calculate `next_pos` and determine `reward`.
3. **Q-value Update**:
- Update the Q-values using the Q-learning rule.
4. **Check Goal**:
- If the duckling reaches the treat, end the episode.
6. **Epsilon Decay (Optional)**
- After each episode, `EPSILON` is slightly reduced so that the duckling explores less over time.
7. **Demonstration**
- Finally, the script shows a “greedy” run, where the duckling always picks the best-known action from the learned Q-table.
- It prints the path taken in this demonstration.
### The Pond Environment
The environment is a 2D grid where each cell represents one part of the pond:
```
Row\Col 0 1 2 3 4
0 [0, 1, 1, 1, 1]
1 [1, 1, 0, 1, 9]
2 [1, 0, 1, 1, 1]
3 [1, 1, 1, 1, 1]
```
In this grid:
- `0` represents a **rock** (impassable; the duckling cannot swim there).
- `1` represents **water** (the duckling can swim freely).
- `9` represents the **tasty treat** (the goal).
Our duckling starts at position `(0,1)`—it’s in water, so it’s safe. The duckling can move **up, right, down**, or **left**, and we use an **epsilon-greedy** strategy to decide whether to explore or exploit.
---
### Observing the Duckling’s Learning
During training, you’ll see console output indicating whether the duckling is *exploring* or *exploiting*, which action it takes, and eventually celebrating when it finds the treat. Over multiple episodes, the duckling refines its internal Q-values, leading to a more direct route to the treat.
---
### Why This Matters
This little example—though simplistic—beautifully illustrates how **trial-and-error** plus **incremental updates** help an agent learn an optimal or near-optimal strategy. Many real-world problems, from robot navigation to game-playing AI, can be tackled with the same underlying Q-learning concepts.
---
## Final Thoughts: Break Free From Your River of Thinking
If you ever feel stuck in life, doing everything the same way simply because it’s comfortable, remember **epsilon**—that little spark of curiosity prompting you to see what else is out there. Learning happens when we challenge our biases and update our internal “map” of the world.
1. **Imprinting & Bias**: We tend to latch onto the first lesson or experience we have. Be mindful of that initial “imprint,” because it can skew how you see future opportunities.
2. **Similar vs. Dissimilar**: By exploring, you discover which situations really do mirror past ones—and which are unique enough to justify a new approach.
3. **Exploration vs. Exploitation**: Balancing the comfort of what you know with the thrill of the unknown is how you grow—whether you’re a duckling, a coder, or a café-hopper.
4. **Rewards**: Be clear about what “success” looks like.
So go ahead, **dip your feet into new waters** — step out of your routine, explore, learn from it, and watch your internal Q-table become richer and wiser. After all, life’s greatest discoveries often happen when you steer away from your usual path, letting a bit of “epsilon” guide you toward something new.
---
---
## **Appendix: The Foundations of Q-Learning**
### **States, Actions, and Rewards Simplified**
Imagine you're deciding what to eat for dinner. Your current situation—maybe it's a weeknight, you're hungry, and you have certain ingredients at home—is your **state**. Your choices—cook pasta, order pizza, or dine out—are your **actions**. The outcome of each choice—the satisfaction of a delicious meal, the hassle of cleaning up, or the wait for delivery—is your **reward**.
In Q-learning, an agent (like you making dinner decisions) interacts with its environment by being in different states, taking actions, and receiving rewards based on those actions. Over time, the agent learns which actions yield the best rewards in each state, helping it make smarter decisions in the future.
### **Understanding the Q-Table**
At the heart of Q-learning lies the **Q-table**, a tool that helps the agent remember the value of taking certain actions in specific states. Think of the Q-table as your personal recipe book:
- **Rows** represent different meal scenarios (states).
- **Columns** represent possible dinner choices (actions).
- **Cells** hold ratings for each choice based on past experiences (Q-values).
Initially, your recipe book is empty. As you try different meals and experience the outcomes, you start filling in the Q-values. For example, you might learn that cooking pasta often leads to a satisfying meal (+10 points) while ordering pizza sometimes results in a long delivery wait (-2 points). Over time, this helps you choose the best option quickly without second-guessing.
### **Introducing the Bellman Equation**
Now, let's explore a key component that powers the Q-table updates: the **Bellman Equation**. Don't let the name intimidate you—it's simply a way to help the agent decide the best action by considering both immediate rewards and future possibilities.
### **Real-World Analogy: Planning a Road Trip**
Imagine you're planning a road trip and trying to decide the best route to maximize fun and minimize delays.
- **Immediate Reward:** Choosing a scenic route might offer beautiful views (+10 fun points) but takes longer (-5 time points).
- **Future Reward:** A slightly longer scenic route today might lead you to a fantastic attraction tomorrow (+15 fun points), compared to a quicker but less interesting route.
**Using the Bellman Equation:**
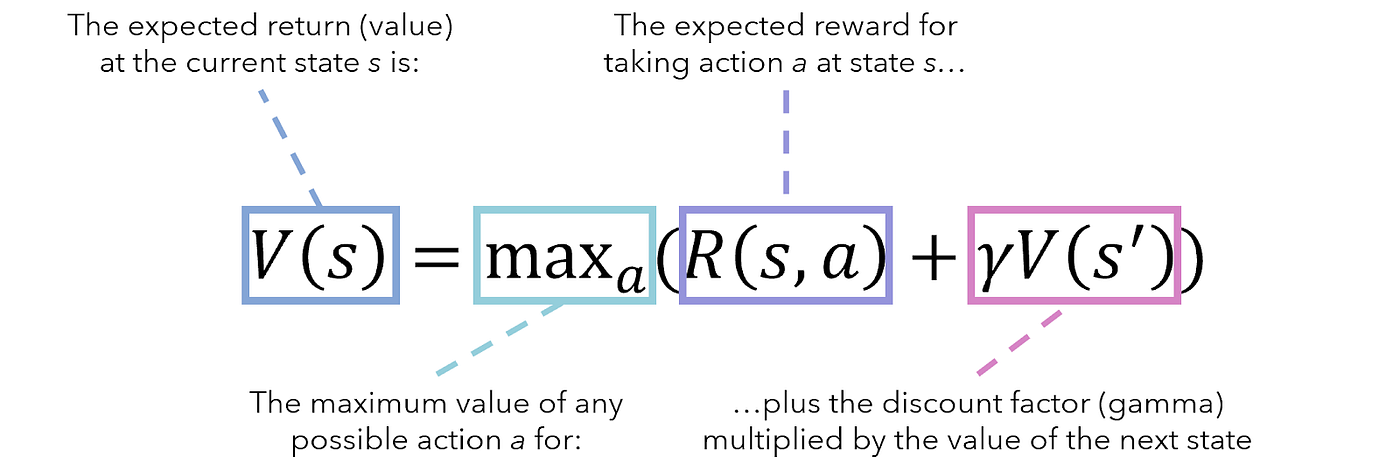
1. **Evaluate Current Choice:**
- Assess the immediate benefits and drawbacks of each route.
2. **Predict Future Benefits:**
- Estimate the potential rewards from future attractions based on today's choice.
3. **Combine Both:**
- Decide which route offers the best balance between immediate enjoyment and future opportunities.
By continuously evaluating both immediate and future rewards, you make informed decisions that optimize your overall road trip experience.
### **How the Bellman Equation Guides Learning**
By continuously applying the Bellman Equation, the agent learns to:
- **Learn from Experience:** Update Q-values based on new actions and rewards.
- **Make Better Decisions:** Choose actions that maximize both immediate and future rewards.
- **Adapt Over Time:** Refine its strategy as it gathers more information about the environment.
Just as you adjust your road trip plans based on new attractions you discover, the Q-learning agent updates its Q-table to navigate the environment more effectively.
### **Visualizing the Bellman Equation**
Imagine your Q-table as a living map that evolves with each decision:
- **Initial State:** Your map has no information, and all paths are unknown.
- **After Actions:** Each time you make a choice, you update the map with new Q-values based on the rewards received.
- **Optimized Map:** Over time, your map highlights the best routes to maximize rewards, guiding you efficiently to your goals.
The Bellman Equation is the tool that transforms your initial, blank map into a detailed guide for successful navigation.
### **Summary of Key Points**
- **Q-Learning Foundations:** Grasping states, actions, rewards, and the Q-table is essential.
- **Bellman Equation Simplified:** It balances immediate rewards with future benefits to update Q-values.
- **Continuous Learning:** The agent improves its strategy by repeatedly applying the Bellman Equation based on new experiences.
---
# FULL CODE
```python
#!/usr/bin/env python3
"""
demo.py
A fun Q-learning demo featuring our curious "duckling" navigating a simple pond
environment. The duckling learns through trial and error, balancing exploration
and exploitation to find a 'tasty treat' in the grid.
"""
import numpy as np
import random
# -----------------------------------------------------------------------------
# POND DEFINITION
# -----------------------------------------------------------------------------
# We'll represent the pond as a 2D grid:
# 0 = Rock (impassable; can't swim through)
# 1 = Water (free to swim)
# 9 = Tasty treat (goal)
#
# The duckling starts at (0,1) and tries to reach the cell with '9'.
#
# Row\Col 0 1 2 3 4
# 0 [0, 1, 1, 1, 1]
# 1 [1, 1, 0, 1, 9]
# 2 [1, 0, 1, 1, 1]
# 3 [1, 1, 1, 1, 1]
#
# The duckling can't move into '0' cells. The '9' cell is the special goal.
# -----------------------------------------------------------------------------
POND = np.array([
[0, 1, 1, 1, 1],
[1, 1, 0, 1, 9],
[1, 0, 1, 1, 1],
[1, 1, 1, 1, 1]
])
# Starting position for our duckling (row, col).
START_POS = (0, 1) # This is water, so the duckling can start here safely.
# Define possible actions: up, right, down, left.
# We'll map each action to a delta (row_change, col_change).
ACTIONS = {
0: (-1, 0), # Up
1: (0, +1), # Right
2: (+1, 0), # Down
3: (0, -1) # Left
}
# -----------------------------------------------------------------------------
# HYPERPARAMETERS (Learn Rate, Discount Factor, Exploration Rate)
# -----------------------------------------------------------------------------
ALPHA = 0.1 # Learning rate (0 < ALPHA <= 1)
GAMMA = 0.9 # Discount factor (0 <= GAMMA <= 1)
EPSILON = 0.3 # Initial exploration rate (0 <= EPSILON <= 1)
NUM_EPISODES = 50 # How many times the duckling tries (episodes)
MAX_STEPS_PER_EPISODE = 50 # Max steps per episode to prevent endless loops
# -----------------------------------------------------------------------------
# UTILITY FUNCTIONS
# -----------------------------------------------------------------------------
def is_valid_position(pos):
"""
Check if a position in the pond is valid for swimming (not out of bounds
and not a rock).
"""
r, c = pos
# Check if (r, c) is inside the pond array.
if (0 <= r < POND.shape[0]) and (0 <= c < POND.shape[1]):
# Ensure it's not a rock (0).
return POND[r, c] != 0
return False
def get_next_position(current_pos, action):
"""
Given the current position (row, col) and an action (0,1,2,3),
compute the next position. If it's invalid or blocked, stay put.
"""
dr, dc = ACTIONS[action]
new_pos = (current_pos[0] + dr, current_pos[1] + dc)
# If the new position is invalid, we don't move.
if not is_valid_position(new_pos):
return current_pos
return new_pos
def get_reward(pos):
"""
Define the reward for swimming into a particular position.
- If position has '9' (tasty treat), +10
- Otherwise, small negative reward (-0.1) to encourage efficient paths
"""
r, c = pos
if POND[r, c] == 9:
return 10.0
else:
return -0.1
def is_goal(pos):
"""
Check if the current position is the 'tasty treat' goal.
"""
r, c = pos
return POND[r, c] == 9
# -----------------------------------------------------------------------------
# MAIN Q-LEARNING LOGIC
# -----------------------------------------------------------------------------
def main():
# We'll store the duckling's Q-values in a dictionary:
# Q_table[(row, col)] = [Q_up, Q_right, Q_down, Q_left]
# If a position hasn't been encountered yet, it will be initialized later.
Q_table = {}
def get_Q_values(state):
"""
Retrieve Q-values for all actions from 'Q_table'. If the state (row,col)
isn't in the table, initialize it with 0.0 for each possible action.
"""
if state not in Q_table:
Q_table[state] = [0.0, 0.0, 0.0, 0.0] # Up, Right, Down, Left
return Q_table[state]
global EPSILON # We'll modify EPSILON over time (optional decay).
# -------------------------------
# TRAINING LOOP
# -------------------------------
for episode in range(NUM_EPISODES):
# Start each episode at the initial position (our duckling's start).
current_pos = START_POS
print(f"\n=== EPISODE {episode+1}/{NUM_EPISODES} ===")
print("Duckling wakes up, stretches its wings, and prepares to explore...")
for step in range(MAX_STEPS_PER_EPISODE):
# 1. Observe the current state (position).
state = current_pos
# 2. Choose an action using epsilon-greedy strategy.
if random.random() < EPSILON:
# Explore (pick a random action).
action = random.choice(list(ACTIONS.keys()))
print(f"[Exploring] Duckling tries action {action}")
else:
# Exploit (pick best known action from Q-table).
q_values = get_Q_values(state)
action = int(np.argmax(q_values))
print(f"[Exploiting] Duckling chooses action {action} with Q-values {q_values}")
# 3. Perform the action to get the next position.
next_pos = get_next_position(current_pos, action)
# 4. Get a reward for moving into 'next_pos'.
reward = get_reward(next_pos)
# 5. Update Q-values (Q-learning update).
old_q_values = get_Q_values(state) # Q-values for the current state
old_q = old_q_values[action] # Q-value for the chosen action
next_q_values = get_Q_values(next_pos) # Q-values for the next state
max_next_q = max(next_q_values) # Best future Q-value
# Q-learning formula:
# Q_new = Q_old + ALPHA * (reward + GAMMA * max_next_q - Q_old)
new_q = old_q + ALPHA * (reward + GAMMA * max_next_q - old_q)
old_q_values[action] = new_q # Update the Q-table
# 6. Move the duckling to the next position.
current_pos = next_pos
# Check if we've reached the goal (the tasty treat).
if is_goal(current_pos):
print(">>> Hooray! The duckling found the TASTY TREAT!")
break # End this episode early if goal is reached.
# (Optional) Decay epsilon so that the duckling explores less over time.
EPSILON_decay = 0.99
EPSILON *= EPSILON_decay
# -------------------------------
# DEMONSTRATION
# -------------------------------
print("\n=== DEMONSTRATION: Duckling uses its learned Q-table to find the treat! ===")
# We'll do one final run in "greedy" mode (no random exploration).
demo_pos = START_POS
path_taken = [demo_pos]
steps = 0
while not is_goal(demo_pos) and steps < MAX_STEPS_PER_EPISODE:
q_vals = get_Q_values(demo_pos)
best_action = int(np.argmax(q_vals)) # Choose the best action from Q-table
demo_pos = get_next_position(demo_pos, best_action)
path_taken.append(demo_pos)
steps += 1
# Print out the final path our duckling takes.
if is_goal(demo_pos):
print("Quack! The duckling successfully reached the TASTY TREAT.")
print("Path taken (row, col):")
for p in path_taken:
print(p)
else:
print("The duckling couldn't reach the goal in the demonstration.")
print("Path taken (row, col):")
for p in path_taken:
print(p)
# -----------------------------------------------------------------------------
# Run the script
# -----------------------------------------------------------------------------
if __name__ == "__main__":
main()
```