https://github.com/ranfysvalle02/summwebsite
This repository is not intended to serve as the next 'library' for text summarization. Instead, it is designed to be an educational resource, providing insights into the inner workings of text summarization.
https://github.com/ranfysvalle02/summwebsite
ai azure context-length large-text llm map-reduce openai parallel-computing parallel-processing python summaries summarization summarizer
Last synced: 2 months ago
JSON representation
This repository is not intended to serve as the next 'library' for text summarization. Instead, it is designed to be an educational resource, providing insights into the inner workings of text summarization.
- Host: GitHub
- URL: https://github.com/ranfysvalle02/summwebsite
- Owner: ranfysvalle02
- Created: 2024-08-26T03:01:18.000Z (almost 2 years ago)
- Default Branch: main
- Last Pushed: 2024-08-26T03:49:03.000Z (almost 2 years ago)
- Last Synced: 2025-01-29T15:12:07.204Z (over 1 year ago)
- Topics: ai, azure, context-length, large-text, llm, map-reduce, openai, parallel-computing, parallel-processing, python, summaries, summarization, summarizer
- Language: Python
- Homepage:
- Size: 72.3 KB
- Stars: 0
- Watchers: 2
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
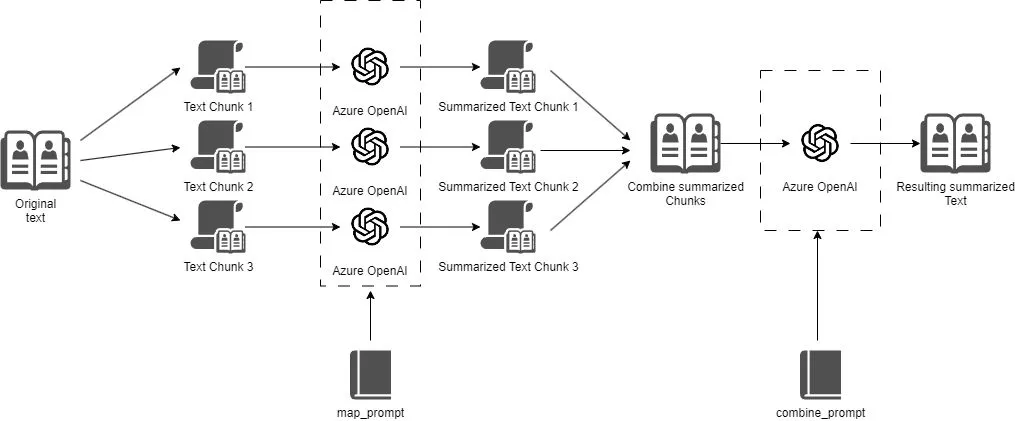
**How do you summarize 14,921 tokens of content using an LLM with a maximum context length is 4096 tokens?**
**Tired of your language model struggling to grasp the big picture?** Small context windows, like a tiny viewing port, limit its ability to see the entire forest. This is especially frustrating when trying to summarize long, complex texts.
Text summarization is a critical task that involves condensing a large volume of text into a concise summary. This blog post will delve into a Python code snippet that employs a map-reduce strategy to summarize web content using a large language model.
Whether you're a researcher, a student, or a professional, the ability to quickly extract and summarize relevant information is a valuable skill. With the help of Python and Azure OpenAI, we can automate this process and save time.
**Overcoming the Context Window Limitation**
In this example, we'll be summarizing the famous paper that started it all: ["Attention is all you need"](https://arxiv.org/html/1706.03762v7).
It contains ~30+k characters, ~14,921 tokens.
We'll be summarizing it using `gpt-3.5-turbo` which has a context window limitation of **4096**
The output is below:
```
total tokens: 14921
6
Starting to process chunk at index 0; chunk_size=2218
Starting to process chunk at index 1; chunk_size=2691
Starting to process chunk at index 4; chunk_size=2684
Starting to process chunk at index 3; chunk_size=3488
Starting to process chunk at index 2; chunk_size=2981
Starting to process chunk at index 5; chunk_size=865
Finished processing chunk at index 4
Finished processing chunk at index 5
Finished processing chunk at index 1
Finished processing chunk at index 0
Finished processing chunk at index 3
Finished processing chunk at index 2
summary_of_summaries:
- The Transformer is a neural network model architecture that relies solely on attention mechanisms to draw global dependencies between input and output, dispensing with recurrence and convolutions entirely.
- The model is composed of a stack of identical encoder and decoder layers that employ either multi-head self-attention or a simple, position-wise fully connected feed-forward network.
- The model achieves state-of-the-art results on English-to-German and English-to-French machine translation tasks and generalizes well to other tasks like English constituency parsing.
- Self-attention layers are faster and more parallelizable than recurrent layers for sequence transduction tasks.
- The model uses position-wise feed-forward networks and sinusoidal positional encoding for token conversion and sequence order encoding, respectively.
- The Transformer model is superior in quality and time efficiency compared to previous state-of-the-art sequence transduction models and is able to utilize parallel computation.
- The authors demonstrate the effectiveness of pre-training the model on large amounts of monolingual data before fine-tuning it on smaller supervised tasks.
- The models are optimized and trained using batching, Adam optimizer with residual dropout and label smoothing techniques.
- The Transformer architecture has had a significant impact in the field of natural language processing.
- The Transformer model achieved a BLEU score of 28.4 on the English-to-German and 41.0 on the English-to-French translation tasks, surpassing all previously published models and ensembles.
```
**Map-Reduce for Text Summarization**
Map-Reduce is a programming model that processes large data sets in parallel. In the context of text summarization, we can break down the task into two steps:
1. **Map:** Divide the input text into smaller chunks, and summarize each chunk individually.
2. **Reduce:** Combine the invidual summaries of these chunks into a final summary.
**Limitations of MapReduce for Text Summarization**
While MapReduce is an effective approach for summarizing large texts, it does have its limitations:
* **Context Loss:** Breaking down text into smaller chunks can lead to loss of context, as each chunk may not contain enough information to fully understand the overall meaning.
* **Overreliance on LLM:** The quality of the summary ultimately depends on the capabilities of the LLM used for summarization. If the LLM is not able to effectively capture the key points of the text, the summary will be suboptimal.
* **Potential for Redundancy:** When combining summaries from different chunks, there may be some redundancy or overlap in the information presented.
**Gearing Up for the Adventure**
Before we set off, let's gather our supplies:
1. **Python:** Make sure you have Python installed on your system.
2. **Python Libraries:** We'll need some helpful libraries:
- `json` and `requests` (standard Python libraries)
- `concurrent.futures` (for parallel processing)
- `BeautifulSoup` (for parsing HTML)
- `openai` (for interacting with Azure OpenAI)
- `nltk` (for text processing)
3. **Azure OpenAI API Key:** Sign up for an Azure OpenAI account to obtain your own key.
**Unraveling the Code**
Let's dissect the code step-by-step:
**Import Libraries:**
```python
import json
import requests
import concurrent.futures
from bs4 import BeautifulSoup
from openai import AzureOpenAI
import tiktoken
```
We begin by importing the necessary libraries. Familiar faces like `json` and `requests` join the crew, along with `concurrent.futures` for multitasking, `BeautifulSoup` for navigating the HTML landscape, `openai` for communication with Azure OpenAI, and `nltk` for text processing.
**Laying the Groundwork:**
```python
# Initialize the tokenizer
tokenizer = tiktoken.get_encoding("cl100k_base")
# Define constants
AZURE_OPENAI_ENDPOINT = ""
AZURE_OPENAI_API_KEY = ""
az_client = AzureOpenAI(azure_endpoint=AZURE_OPENAI_ENDPOINT,api_version="2023-07-01-preview",api_key=AZURE_OPENAI_API_KEY)
```
**The Extraction Expedition:**
```python
r = requests.get('https://thenewstack.io/devs-slash-years-of-work-to-days-with-genai-magic/')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
RAW_HTML = soup.get_text()
# Break the text into chunks (adjust chunk size as needed)
chunk_size = 10000
# check status code for response received
# success code - 200
print(r)
print("total tokens: " + str(len(tokenizer.encode(RAW_HTML))))
chunks = [RAW_HTML[i:i+chunk_size] for i in range(0, len(RAW_HTML), chunk_size)]
print(len(chunks))
```
We use `requests.get()` to fetch the content of the target webpage and then leverage BeautifulSoup's expertise to parse it. The extracted text is then divided into manageable chunks for efficient processing.
**The Art of Summarization:**
```python
# Define function to summarize each chunk
def summarize_chunk(chunk):
print(f"Starting to process chunk at index {chunks.index(chunk)}; chunk_size=" + str(len(tokenizer.encode(chunk))))
msgs2send = [
{"role": "system", "content": "You are a helpful assistant that summarizes the CONTENT of SCRAPED HTML."},
{"role": "user", "content": """=
Your main objective is to summarize the content in such a way that the user does not have to visit the website.
Please provide a bullet list (-) summary to the best of your ability of the CONTENT in this WEBSITE:
IMPORTANT: PAY CLOSE ATTENTION TO THE CONTENT OF THE WEBSITE. IGNORE THINGS LIKE NAVIGATION, ADS, ETC.
REMEMBER! YOUR GOAL IS TO SUMMARIZE THE CONTENT OF THE WEBSITE IN A WAY THAT THE USER DOES NOT HAVE TO VISIT THE WEBSITE.
[web_content]
"""},
{"role": "user", "content": str(chunk)},
{"role": "user", "content": """
[response format]
should be in bullet list, valid markdown format. IMPORTANT! must be valid markdown string!
Max. 3 sentences per bullet point.
Max. 10 bullet points.
Min. 5 bullet points.
[sample_response]
- bullet_point_1
- bullet_point_2
...
- bullet_point_n
"""}
]
ai_response = az_client.chat.completions.create(
model="gpt-35-turbo",
messages=msgs2send,
)
tmp_sum = str(ai_response.choices[0].message.content.strip())
print(f"Finished processing chunk at index {chunks.index(chunk)}")
return tmp_sum
```
This function takes a chunk of text as input, sends it to the LLM for processing, and extracts the returned summary.
**Harnessing the Power of Parallel Processing:**
```python
# Use ThreadPoolExecutor to parallelize the summarization
with concurrent.futures.ThreadPoolExecutor() as executor:
summaries = list(executor.map(summarize_chunk, chunks))
```
We leverage the `ThreadPoolExecutor` from `concurrent.futures` to parallelize the summarization process across multiple chunks.
This significantly speeds things up, especially for lengthy webpages.
**Piecing it All Together:**
```python
# Summarize the summaries
summary_of_summaries = az_client.chat.completions.create(
model="gpt-35-turbo",
messages=[
{"role":"system", "content":"You are a helpful assistant who can strategically summarize multiple summaries together into one coherent summary."},
{"role": "user", "content": "[summaries]"},
{"role": "user", "content": str(summaries)},
{"role": "user", "content": """
[response format]
Summary should be in bullet list, valid markdown format. IMPORTANT! must be valid markdown string!
Max. 3 sentences per bullet point.
Max. 10 bullet points.
Min. 5 bullet points.
[sample_response]
- bullet_point_1
- bullet_point_2
...
- bullet_point_n
[task]
- Please provide a complete, comprehensive summary using the individual summaries provided in [summaries]
"""}
],
)
print("summary_of_summaries:")
print(
summary_of_summaries.choices[0].message.content.strip()
)
```
Now that we have individual summaries for each chunk, it's time to assemble the bigger picture. We send the list of summaries to the LLM, and it returns a final, comprehensive summary that captures the essence of the entire webpage.
**The Complete Blueprint**
For your reference, here's the complete code:
```python
import json
import requests
import concurrent.futures
from bs4 import BeautifulSoup
from openai import AzureOpenAI
import tiktoken
# Initialize the tokenizer
tokenizer = tiktoken.get_encoding("cl100k_base")
# Define constants
AZURE_OPENAI_ENDPOINT = ""
AZURE_OPENAI_API_KEY = ""
az_client = AzureOpenAI(azure_endpoint=AZURE_OPENAI_ENDPOINT,api_version="2023-07-01-preview",api_key=AZURE_OPENAI_API_KEY)
r = requests.get('https://arxiv.org/html/1706.03762v7')
# Parsing the HTML
soup = BeautifulSoup(r.content, 'html.parser')
RAW_HTML = soup.get_text()
# Break the text into chunks (adjust chunk size as needed)
chunk_size = 10000
# check status code for response received
# success code - 200
print(r)
print("total tokens: " + str(len(tokenizer.encode(RAW_HTML))))
chunks = [RAW_HTML[i:i+chunk_size] for i in range(0, len(RAW_HTML), chunk_size)]
print(len(chunks))
# Define function to summarize each chunk
def summarize_chunk(chunk):
print(f"Starting to process chunk at index {chunks.index(chunk)}; chunk_size=" + str(len(tokenizer.encode(chunk))))
msgs2send = [
{"role": "system", "content": "You are a helpful assistant that summarizes the CONTENT of SCRAPED HTML."},
{"role": "user", "content": """=
Your main objective is to summarize the content in such a way that the user does not have to visit the website.
Please provide a bullet list (-) summary to the best of your ability of the CONTENT in this WEBSITE:
IMPORTANT: PAY CLOSE ATTENTION TO THE CONTENT OF THE WEBSITE. IGNORE THINGS LIKE NAVIGATION, ADS, ETC.
REMEMBER! YOUR GOAL IS TO SUMMARIZE THE CONTENT OF THE WEBSITE IN A WAY THAT THE USER DOES NOT HAVE TO VISIT THE WEBSITE.
[web_content]
"""},
{"role": "user", "content": str(chunk)},
{"role": "user", "content": """
[response format]
should be in bullet list, valid markdown format. IMPORTANT! must be valid markdown string!
Max. 3 sentences per bullet point.
Max. 10 bullet points.
Min. 5 bullet points.
[sample_response]
- bullet_point_1
- bullet_point_2
...
- bullet_point_n
"""}
]
ai_response = az_client.chat.completions.create(
model="gpt-35-turbo",
messages=msgs2send,
)
tmp_sum = str(ai_response.choices[0].message.content.strip())
print(f"Finished processing chunk at index {chunks.index(chunk)}")
return tmp_sum
# Use ThreadPoolExecutor to parallelize the summarization
with concurrent.futures.ThreadPoolExecutor() as executor:
summaries = list(executor.map(summarize_chunk, chunks))
# Summarize the summaries
summary_of_summaries = az_client.chat.completions.create(
model="gpt-35-turbo",
messages=[
{"role":"system", "content":"You are a helpful assistant who can strategically summarize multiple summaries together into one coherent summary."},
{"role": "user", "content": "[summaries]"},
{"role": "user", "content": str(summaries)},
{"role": "user", "content": """
[response format]
Summary should be in bullet list, valid markdown format. IMPORTANT! must be valid markdown string!
Max. 3 sentences per bullet point.
Max. 10 bullet points.
Min. 5 bullet points.
[sample_response]
- bullet_point_1
- bullet_point_2
...
- bullet_point_n
[task]
- Please provide a complete, comprehensive summary using the individual summaries provided in [summaries]
"""}
],
)
print("summary_of_summaries:")
print(
summary_of_summaries.choices[0].message.content.strip()
)
```
**Navigating Potential Hurdles**
If you encounter any roadblocks during your journey, check these points:
1. **Double-check your Azure OpenAI API key.** Ensure it's correct and has the necessary permissions.
2. **Verify library installations.** Make sure all the required Python libraries are installed on your system.
3. **Scrutinize the webpage URL.** Ensure the URL you're trying to scrape is valid and accessible.
**Further Reading**
* [Python Documentation](https://docs.python.org/3/)
* [BeautifulSoup Documentation](https://www.crummy.com/software/BeautifulSoup/bs4/doc/)
* [Azure OpenAI Documentation](https://learn.microsoft.com/en-us/azure/ai-services/openai/)
* [concurrent.futures Documentation](https://docs.python.org/3/library/concurrent.futures.html)