https://github.com/ranfysvalle02/txtsumm-ai
https://github.com/ranfysvalle02/txtsumm-ai
Last synced: 7 months ago
JSON representation
- Host: GitHub
- URL: https://github.com/ranfysvalle02/txtsumm-ai
- Owner: ranfysvalle02
- Created: 2024-11-26T04:45:52.000Z (11 months ago)
- Default Branch: main
- Last Pushed: 2024-12-07T04:29:19.000Z (10 months ago)
- Last Synced: 2025-01-26T07:08:56.009Z (9 months ago)
- Language: Python
- Size: 75.2 KB
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# txtsumm-ai
---
In today’s digital landscape, where information is abundant and attention spans are short, the ability to distill lengthy texts into concise summaries is more valuable than ever. Whether you're a researcher sifting through academic papers, a professional managing extensive reports, or simply someone who wants to stay informed without getting bogged down by details, an efficient text summarizer can be a game-changer. Let’s explore how you can build a robust, open-source text summarizer using **LangChain**, **Critical Vectors**, and Python's multiprocessing capabilities.
### Versatile Summarization Strategies
`TextSummAI` offers multiple strategies to suit different needs:
- **Map-Reduce**: Splits the text, summarizes each chunk (optionally in parallel), and combines the results.
- **None**: Summarizes the entire text in one go without chunking.
- **Critical Vectors**: Selects the most relevant chunks using clustering before summarization.
This flexibility ensures that you can adapt the summarizer to various types of texts and requirements.
```python
class TextSummAI:
def __init__(self, strategy='map_reduce', parallelization=True):
# Initialization code...
pass
def summarize_text(self, text, chunk_size=1000, chunk_overlap=0):
if self.strategy == 'map_reduce':
# Map-Reduce strategy
pass
elif self.strategy == 'none':
# No chunking
pass
elif self.strategy == 'critical_vectors':
# Critical Vectors strategy
pass
```
## A Seamless and Open Approach
One of the standout features of this setup is its open nature. By leveraging open-source libraries like LangChain and Critical Vectors, you’re not tied to any specific vendor. This ensures that your summarizer remains flexible, customizable, and free from vendor lock-in, allowing you to switch out components or integrate new ones as your needs evolve.
## Introducing TextSummAI
`TextSummAI` is an open-source text summarizer designed to handle lengthy texts and distill them into concise summaries. Leveraging the power of **LangChain**, **Critical Vectors**, and Python's multiprocessing, `TextSummAI` offers flexibility, scalability, and efficiency.
### Why Choose an Open-Source Summarizer?
Opting for an open-source solution like `TextSummAI` ensures:
- **Flexibility**: Customize and adapt the summarizer to your specific needs.
- **No Vendor Lock-In**: Freedom to switch out components or integrate new ones as required.
- **Community Support**: Benefit from contributions and improvements from the open-source community.
---
## Versatile Summarization Strategies
One of the standout features of `TextSummAI` is its ability to employ multiple summarization strategies, catering to diverse requirements and text types.
### Summarization Strategies Offered by TextSummAI
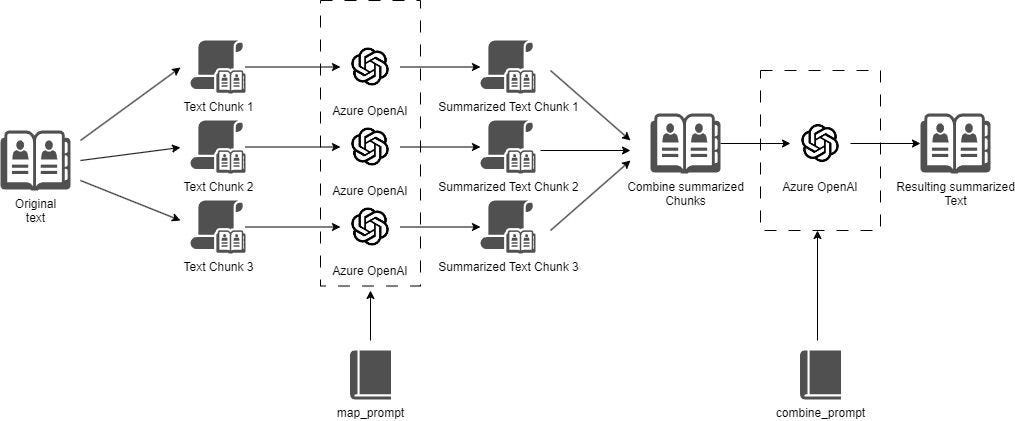
1. **Map-Reduce**:
- **Process**: Splits the text into manageable chunks, summarizes each chunk (optionally in parallel), and combines the results.
- **Use Case**: Ideal for very long texts where parallel processing can significantly speed up summarization.
2. **None**:
- **Process**: Summarizes the entire text in one go without any chunking.
- **Use Case**: Suitable for shorter texts where splitting isn't necessary.
3. **Critical Vectors**:
- **Process**: Selects the most relevant chunks using clustering before summarization.
- **Use Case**: Best for texts where certain sections are more critical than others, ensuring the summary focuses on the most important parts.
This flexibility ensures that `TextSummAI` can adapt to various types of texts and specific summarization requirements, making it a versatile tool in your arsenal.
```python
class TextSummAI:
def __init__(self, strategy='map_reduce', parallelization=True):
# Initialization code...
pass
def summarize_text(self, text, chunk_size=1000, chunk_overlap=0):
if self.strategy == 'map_reduce':
# Map-Reduce strategy
pass
elif self.strategy == 'none':
# No chunking
pass
elif self.strategy == 'critical_vectors':
# Critical Vectors strategy
pass
```
---
### Initializing Critical Vectors
```python
def init_critical_vectors():
"""
Initialize the critical vectors selector.
"""
return CriticalVectors(
strategy='kmeans',
num_clusters='auto',
chunk_size=10000,
chunks_per_cluster=1, # Set the desired number of chunks per cluster here
split_method='sentences',
max_tokens_per_chunk=3000, # Adjust as needed
use_faiss=True # Enable FAISS if desired
)
```
**Critical Vectors** help in selecting the most relevant chunks from the text, ensuring the summary focuses on key information.
### Initializing the Language Model (LLM)
```python
def initialize_llm():
"""
Initialize the preferred LLM instance.
This function is called within each worker process.
"""
return AzureChatOpenAI( # or OllamaLLM or whatever you prefer
openai_api_version=AZURE_API_VERSION,
azure_deployment=AZURE_DEPLOYMENT,
temperature=0.0,
max_tokens=150
)
```
You can choose between different LLMs like AzureChatOpenAI or OllamaLLM based on your preference and requirements.
### Worker Function for Parallel Processing
```python
def worker_map_func(doc_content, map_prompt_template):
"""
Worker function to generate a summary for a single document.
This function is picklable and initializes its own LLM instance.
"""
try:
# Initialize LLM within the worker
llm = initialize_llm()
# Create the map chain
map_chain = map_prompt_template | llm | StrOutputParser()
# Invoke the chain with the document content
summary = map_chain.invoke({"context": doc_content})
return summary
except Exception as e:
print(f"Error in process {current_process().name}: {e}")
return ""
```
This function handles the summarization of individual text chunks. By initializing the LLM within each worker, we ensure thread safety and optimal resource utilization.
### The `TextSummAI` Class
```python
class TextSummAI:
def __init__(self, strategy='map_reduce', parallelization=True):
self.allowed_strategies = ['map_reduce','none','critical_vectors']
if strategy not in self.allowed_strategies:
raise Exception(f"Strategy {strategy} is not allowed. Allowed strategies: {self.allowed_strategies}")
self.strategy = strategy
if not isinstance(parallelization, bool):
raise ValueError("parallelization must be a boolean value")
self.parallelization = parallelization
# Define map and reduce prompts
self.map_prompt = ChatPromptTemplate.from_messages([
("human", "Write a concise summary of the following:\n\n{context}")
])
self.reduce_prompt = ChatPromptTemplate.from_messages([
("human", "Combine these summaries into a final summary:\n\n{summaries}")
])
# Initialize reduce chain (single process)
self.reduce_llm = initialize_llm()
self.reduce_chain = self.reduce_prompt | self.reduce_llm | StrOutputParser()
# Initialize critical vectors selector (single process)
if self.strategy == 'critical_vectors':
self.critical_vectors = init_critical_vectors()
print(f"TextSummAI initialized with strategy: {self.strategy}, parallelization: {self.parallelization}")
def summarize_text(self, text, chunk_size=1000, chunk_overlap=0):
if self.strategy == 'map_reduce':
# Split the text into chunks
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=chunk_size, chunk_overlap=chunk_overlap
)
docs = text_splitter.create_documents([text])
# Prepare the map function with the map_prompt
map_func = partial(worker_map_func, map_prompt_template=self.map_prompt)
# Generate summaries using parallel or sequential processing
if self.parallelization:
with Pool() as p:
summaries = p.map(map_func, [doc.page_content for doc in docs])
else:
summaries = [map_func(doc.page_content) for doc in docs]
# Combine the summaries into a final summary
final_summary = self.reduce_chain.invoke({"summaries": "\n\n".join(summaries)})
return final_summary
elif self.strategy == 'none':
# Return the original text, summarized with no chunking
# Prepare the map function with the map_prompt
map_func = partial(worker_map_func, map_prompt_template=self.map_prompt)
return map_func(str(text))
elif self.strategy == 'critical_vectors':
# Use the critical vectors selector
if self.critical_vectors is None:
raise Exception("CriticalVectors selector is not initialized.")
relevant_chunks, first_part, last_part = self.critical_vectors.get_relevant_chunks(str(text))
map_func = partial(worker_map_func, map_prompt_template=self.map_prompt)
return map_func(f"""
[first part]
{first_part}
[/first part]
[context]
{str(relevant_chunks)}
[/context]
[last part]
{last_part}
[/last part]
""")
```
**Key Components**:
- **Initialization**:
- Validates the chosen summarization strategy.
- Sets up the prompt templates for both mapping (summarizing chunks) and reducing (combining summaries).
- Initializes the `CriticalVectors` selector if the chosen strategy is `critical_vectors`.
- **Summarize Text**:
- **Map-Reduce Strategy**:
- Splits the text into chunks.
- Summarizes each chunk, either in parallel or sequentially.
- Combines the individual summaries into a final summary.
- **None Strategy**:
- Summarizes the entire text without splitting.
- **Critical Vectors Strategy**:
- Selects the most relevant chunks using clustering.
- Summarizes the selected chunks, ensuring the summary focuses on key information.
### Running the Summarizer
```python
if __name__ == "__main__":
# Ensure that the multiprocessing code runs only when the script is executed directly
# Initialize the summarizer with parallelization enabled
summarizer_parallel = TextSummAI(strategy='map_reduce', parallelization=True)
# Initialize the summarizer with parallelization disabled (sequential processing)
summarizer_sequential = TextSummAI(strategy='map_reduce', parallelization=False)
# Initialize the summarizer with no strategy
summarizer_none = TextSummAI(strategy='none')
# Example with CriticalVectors
summarizer_cv = TextSummAI(strategy='critical_vectors')
# load text file as string variable
long_text = f"""
hello world
"""
# Using parallel processing
summary_parallel = summarizer_cv.summarize_text(long_text)
print("Final Summary:")
print(summary_parallel)
```
**Usage**:
1. **Initialization**: Choose the summarization strategy and whether to enable parallel processing.
2. **Summarization**: Pass the text you wish to summarize to the `summarize_text` method.
3. **Output**: The final summary is printed out.
**Example**:
```python
# Using CriticalVectors strategy
summarizer_cv = TextSummAI(strategy='critical_vectors')
long_text = """
Your lengthy text goes here...
"""
summary = summarizer_cv.summarize_text(long_text)
print("Final Summary:")
print(summary)
```
---
## Conclusion
While `TextSummAI` offers a powerful and flexible solution for summarizing lengthy texts, it's essential to approach summaries with a discerning eye. Summarization inherently involves reducing information, which can lead to the loss of nuanced details and subtle context. This "lossy" nature means that not all original content can be perfectly preserved, and critical insights might be inadvertently omitted.
As you leverage `TextSummAI` for your summarization needs, consider the following:
- **Purpose Matters**: Understand why you're summarizing a text. Whether it's for a quick overview, highlighting key points, or extracting specific information, tailoring your approach ensures the summary serves its intended purpose effectively.
- **Review and Refine**: Always review generated summaries to ensure they capture the essence of the original content. Automated tools are incredibly helpful, but human oversight can catch nuances that machines might miss.
- **Balance is Key**: Strive for a balance between brevity and completeness. While concise summaries save time, overly condensed versions might omit important details. Adjust the chunk sizes and summarization strategies in `TextSummAI` to find the sweet spot for your specific needs.
- **Be Aware of Limitations**: Recognize that no summarization tool is perfect. Factors like the complexity of the text, the quality of the input, and the chosen summarization strategy can influence the outcome. Being aware of these limitations helps set realistic expectations and guides better usage of the tool.
By thoughtfully integrating `TextSummAI` into your workflow and being mindful of the potential for information loss, you can harness its capabilities to enhance your information processing without compromising on the quality and integrity of the content you rely on.
Embrace the power of automated summarization, but remember to complement it with your judgment and expertise. This balanced approach ensures that while you benefit from efficiency and scalability, the depth and richness of your information remain intact.
---
# Appendix-A: A Simple Processing Chain
A **processing chain** is like a special assembly line where different helper toys work together to solve a problem.
## What is a Processing Chain?
A processing chain is a way to break down a big, complicated task into smaller, easier steps. Think of it like making a sandwich:
- First, you get the bread (input)
- Then you add butter (first step)
- Next, you put cheese (second step)
- Finally, you add some yummy toppings (final output)
## How Does a Processing Chain Work?
In LangChain, a processing chain connects different **magical helpers**:
- **Prompt Template**: Tells the computer what to do
- **Language Model**: The brain that thinks and creates answers
- **Output Parser**: Helps make the answer neat and tidy
## Simple Example
```python
# Imagine telling the computer: "Help me name a company that makes sheets!"
chain = prompt | llm | output_parser
result = chain.invoke({"product": "Queen Size Sheet Set"})
```
The chain takes your input, thinks about a cool company name, and gives you an answer - just like magic! 🪄
Each **link** in the chain does a small job, and together they solve big problems easily and smoothly.