https://github.com/richzhang/splitbrainauto
Split-Brain Autoencoders: Unsupervised Learning by Cross-Channel Prediction. In CVPR, 2017.
https://github.com/richzhang/splitbrainauto
autoencoder caffe unsupervised-learning
Last synced: about 1 year ago
JSON representation
Split-Brain Autoencoders: Unsupervised Learning by Cross-Channel Prediction. In CVPR, 2017.
- Host: GitHub
- URL: https://github.com/richzhang/splitbrainauto
- Owner: richzhang
- License: mit
- Created: 2016-11-27T23:22:13.000Z (over 9 years ago)
- Default Branch: master
- Last Pushed: 2018-06-25T22:43:53.000Z (almost 8 years ago)
- Last Synced: 2024-07-05T14:13:25.312Z (almost 2 years ago)
- Topics: autoencoder, caffe, unsupervised-learning
- Language: Shell
- Homepage: http://richzhang.github.io/splitbrainauto
- Size: 10.9 MB
- Stars: 138
- Watchers: 10
- Forks: 31
- Open Issues: 3
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
- awesome-self-supervised-learning - [code
- awesome-self-supervised-learning - [code
README
## Split-Brain Autoencoders: Unsupervised Learning by Cross-Channel Prediction [[Project Page]](http://richzhang.github.io/splitbrainauto/) ##
[Richard Zhang](https://richzhang.github.io/), [Phillip Isola](http://web.mit.edu/phillipi/), [Alexei A. Efros](http://www.eecs.berkeley.edu/~efros/). In CVPR, 2017. (hosted on [ArXiv](https://arxiv.org/abs/1611.09842))
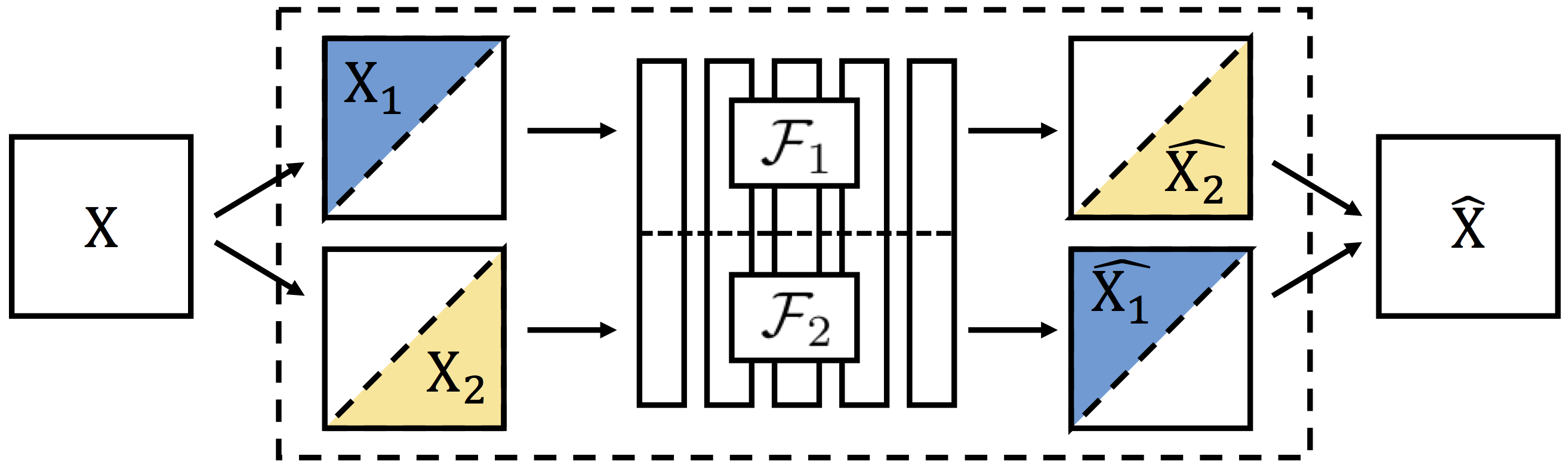
### Overview ###
This repository contains a pre-trained Split-Brain Autoencoder network. The network achieves state-of-the-art results on several large-scale unsupervised representation learning benchmarks.
### Clone this repository ###
Clone the master branch of the respository using `git clone -b master --single-branch https://github.com/richzhang/splitbrainauto.git`
### Dependencies ###
This code requires a working installation of [Caffe](http://caffe.berkeleyvision.org/). For guidelines and help with installation of Caffe, consult the [installation guide](http://caffe.berkeleyvision.org/) and [Caffe users group](https://groups.google.com/forum/#!forum/caffe-users).
### Test-Time Usage ###
**(1)** Run `./resources/fetch_models.sh`. This will load model `model_splitbrainauto_clcl.caffemodel`. It will also load model `model_splitbrainauto_clcl_rs.caffemodel`, which is the model with the rescaling method from [Krähenbühl et al. ICLR 2016](https://github.com/philkr/magic_init) applied. The rescaling method has been shown to improve fine-tuning performance in some models, and we use it for the PASCAL tests in Table 4 in the paper. Alternatively, download the models from [here](https://people.eecs.berkeley.edu/~rich.zhang/projects/2017_splitbrain/files/models/) and put them in the `models` directory.
**(2)** To extract features, you can (a) use the main branch of Caffe and do color conversion outside of the network or (b) download and install a modified Caffe and not worry about color conversion.
**(a)** **Color conversion outside of prototxt** To extract features with the main branch of [Caffe](http://caffe.berkeleyvision.org/):
**(i)** Load the downloaded weights with model definition file `deploy_lab.prototxt` in the `models` directory. The input is blob `data_lab`, which is an ***image in Lab colorspace***. You will have to do the Lab color conversion pre-processing outside of the network.
**(b)** **Color conversion in prototxt** You can also extract features with in-prototxt color version with a modified Caffe.
**(i)** Run `./resources/fetch_caffe.sh`. This will load a modified Caffe into directory `./caffe-colorization`.
**(ii)** Install the modified Caffe. For guidelines and help with installation of Caffe, consult the [installation guide](http://caffe.berkeleyvision.org/) and [Caffe users group](https://groups.google.com/forum/#!forum/caffe-users).
**(iii)** Load the downloaded weights with model definition file `deploy.prototxt` in the `models` directory. The input is blob `data`, which is a ***non mean-centered BGR image***.
### Citation ###
If you find this model useful for your resesarch, please use this [bibtex](http://richzhang.github.io/index_files/bibtex_cvpr2017_splitbrain.txt) to cite.