https://github.com/robintra/perf-sentinel
Lightweight, polyglot performance anti-pattern detection with built-in carbon-aware scoring.
https://github.com/robintra/perf-sentinel
anti-patterns cli devops devtools green-software greenops microservices n-plus-one observability opentelemetry performance rust sql tracing
Last synced: about 2 months ago
JSON representation
Lightweight, polyglot performance anti-pattern detection with built-in carbon-aware scoring.
- Host: GitHub
- URL: https://github.com/robintra/perf-sentinel
- Owner: robintra
- License: agpl-3.0
- Created: 2026-03-14T10:26:54.000Z (4 months ago)
- Default Branch: main
- Last Pushed: 2026-05-03T21:33:49.000Z (2 months ago)
- Last Synced: 2026-05-03T23:33:26.330Z (2 months ago)
- Topics: anti-patterns, cli, devops, devtools, green-software, greenops, microservices, n-plus-one, observability, opentelemetry, performance, rust, sql, tracing
- Language: Rust
- Homepage:
- Size: 53.1 MB
- Stars: 15
- Watchers: 0
- Forks: 2
- Open Issues: 0
-
Metadata Files:
- Readme: README-FR.md
- Contributing: CONTRIBUTING.md
- License: LICENSE
- Code of conduct: CODE_OF_CONDUCT.md
- Audit: audit.toml
- Codeowners: .github/CODEOWNERS
- Security: SECURITY.md
Awesome Lists containing this project
README








Analyse les traces d'exécution (requêtes SQL, appels HTTP) pour détecter les requêtes N+1, les appels redondants et évalue l'intensité I/O par endpoint (GreenOps).
## Pourquoi perf-sentinel ?
Les anti-patterns de performance comme les requêtes N+1 existent dans toute application qui fait des I/O, monolithes comme microservices. Dans les architectures distribuées, un appel utilisateur cascade sur plusieurs services, chacun avec ses propres I/O et personne n'a de visibilité sur le chemin complet. Les outils existants résolvent chacun une partie du problème : Hypersistence Utils ne couvre que JPA, Datadog et New Relic sont des agents propriétaires lourds qu'on ne veut pas forcément déployer dans tous les pipelines, les détecteurs de Sentry sont solides mais liés à son SDK et à son backend. Aucun ne propose un quality gate CI au niveau protocole qu'on peut auto-héberger.
perf-sentinel adopte une approche différente : **l'analyse au niveau protocole**. Il observe les traces produites par l'application (requêtes SQL, appels HTTP) quel que soit le langage ou l'ORM utilisé. Il n'a pas besoin de comprendre JPA, EF Core ou SeaORM : il voit les requêtes qu'ils génèrent.
## Aperçu rapide
Dans le tableau de bord :
```bash
perf-sentinel report --input traces.json --output report.html
```
...ou dans le terminal :
```bash
perf-sentinel analyze --input traces.json
```

## Comment ça s'insère dans votre infra
Un outil, 2 modes, 4 topologies de déploiement :
**Dev local**

**CI/CD**

**Staging**

**Production**

Plus un angle transversal : GreenOps (estimation énergie et carbone à partir de sources externes temps réel et de données internes en dur, en mode batch ou daemon).

Vue d'ensemble : comment les quatre environnements s'articulent

Le dépôt compagnon [perf-sentinel-simulation-lab](https://github.com/robintra/perf-sentinel-simulation-lab/blob/main/docs/SCENARIOS.md) valide huit modes opérationnels de bout en bout sur un vrai cluster Kubernetes (daemon hybride vers batch HTML, batch sur Tempo, daemon OTLP direct, multi-format Jaeger/Zipkin, calibrate, sidecar, corrélation cross-trace, intégration `pg_stat_statements`). **Chaque scénario fournit un diagramme d'architecture Mermaid, les entrées et sorties exactes, la configuration requise et les pièges rencontrés lors de la validation.**
## Démarrage rapide
### Installation depuis crates.io
```bash
cargo install perf-sentinel
```
### Télécharger un binaire précompilé
Des binaires pour Linux (amd64, arm64), macOS (arm64) et Windows (amd64) sont disponibles sur la page [GitHub Releases](https://github.com/robintra/perf-sentinel/releases). Les binaires Linux sont compilés contre musl en liaison statique totale : ils tournent sur n'importe quelle distribution (Debian, Ubuntu, Alpine, RHEL, etc.) quelle que soit la version de glibc, et fonctionnent dans une image `FROM scratch`. Les Mac Intel peuvent utiliser le binaire arm64 via Rosetta 2.
```bash
# Exemple : Linux amd64
curl -LO https://github.com/robintra/perf-sentinel/releases/latest/download/perf-sentinel-linux-amd64
chmod +x perf-sentinel-linux-amd64
sudo mv perf-sentinel-linux-amd64 /usr/local/bin/perf-sentinel
```
### Lancer avec Docker
```bash
docker run --rm -p 4317:4317 -p 4318:4318 \
ghcr.io/robintra/perf-sentinel:latest watch --listen-address 0.0.0.0
```
Par défaut, le daemon écoute sur `127.0.0.1` pour des raisons de sécurité. Dans un conteneur cette adresse est injoignable depuis l'hôte, donc le quickstart ci-dessus force le bind avec `--listen-address 0.0.0.0`. Le daemon affiche un avertissement non-loopback au démarrage, c'est attendu. Pour un vrai déploiement, placez un reverse proxy (ou une NetworkPolicy sur Kubernetes) devant, ou montez [`examples/perf-sentinel-docker.toml`](examples/perf-sentinel-docker.toml) pour la topologie compose complète.
Pour Kubernetes, un chart Helm est disponible sous [`charts/perf-sentinel/`](charts/perf-sentinel/). Voir [`docs/FR/HELM-DEPLOYMENT-FR.md`](docs/FR/HELM-DEPLOYMENT-FR.md).
### Démo rapide
```bash
perf-sentinel demo
```
### Analyse batch (CI)
```bash
perf-sentinel analyze --input traces.json --ci
```
### Expliquer une trace
```bash
perf-sentinel explain --input traces.json --trace-id abc123
```
### Export SARIF (GitHub/GitLab code scanning)
```bash
perf-sentinel analyze --input traces.json --format sarif
```
### Import depuis Jaeger ou Zipkin
```bash
# Export Jaeger JSON (auto-détecté)
perf-sentinel analyze --input jaeger-export.json
# Zipkin JSON v2 (auto-détecté)
perf-sentinel analyze --input zipkin-traces.json
```
### Analyse pg_stat_statements
```bash
# Analyser un export pg_stat_statements pour détecter les requêtes coûteuses
perf-sentinel pg-stat --input pg_stat.csv
# Référence croisée avec les findings de traces
perf-sentinel pg-stat --input pg_stat.csv --traces traces.json
# Scraper les métriques pg_stat_statements depuis un endpoint Prometheus postgres_exporter
perf-sentinel pg-stat --prometheus http://prometheus:9090
```
### Inspection interactive (TUI)
```bash
perf-sentinel inspect --input traces.json
```
### Ingestion Tempo
```bash
# Analyser une trace depuis Grafana Tempo
perf-sentinel tempo --endpoint http://tempo:3200 --trace-id abc123
# Rechercher et analyser les traces par service
perf-sentinel tempo --endpoint http://tempo:3200 --service order-svc --lookback 1h
```
### Calibration des coefficients
```bash
# Ajuster les coefficients énergie avec des mesures réelles
perf-sentinel calibrate --traces traces.json --measured-energy rapl.csv --output calibration.toml
```
### Dashboard HTML
```bash
# Dashboard HTML single-file pour l'exploration post-mortem dans un navigateur
perf-sentinel report --input traces.json --output report.html
# Embarquer un onglet de ranking pg_stat_statements
perf-sentinel report --input traces.json --pg-stat pg_stat.csv --output report.html
# Ou scrape live depuis postgres_exporter Prometheus
perf-sentinel report --input traces.json --pg-stat-prometheus http://prometheus:9090 --output report.html
# Comparer à une baseline pour review de régression PR
perf-sentinel report --input after.json --before baseline.json --output report.html
# Piper un snapshot daemon live vers le dashboard
curl -s http://daemon:4318/api/export/report | perf-sentinel report --input - --output report.html
```
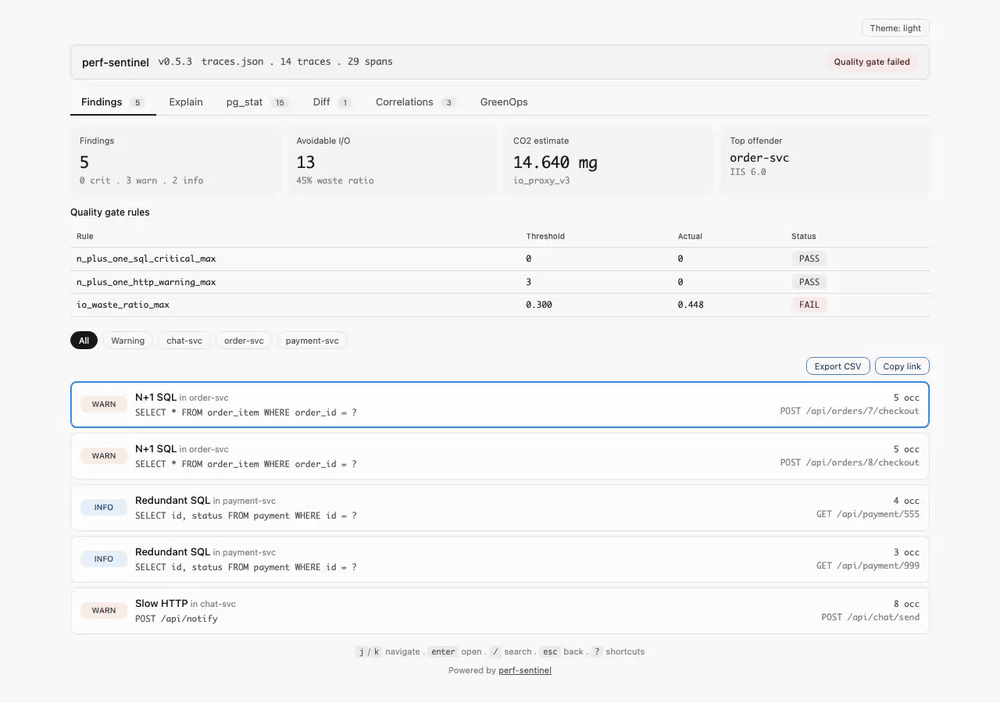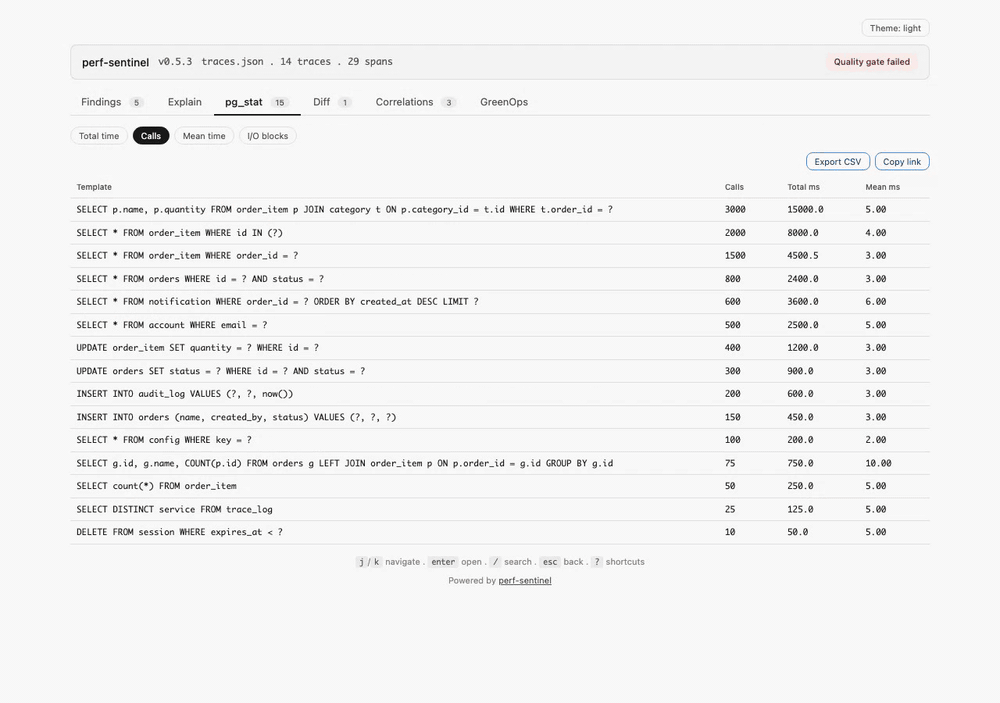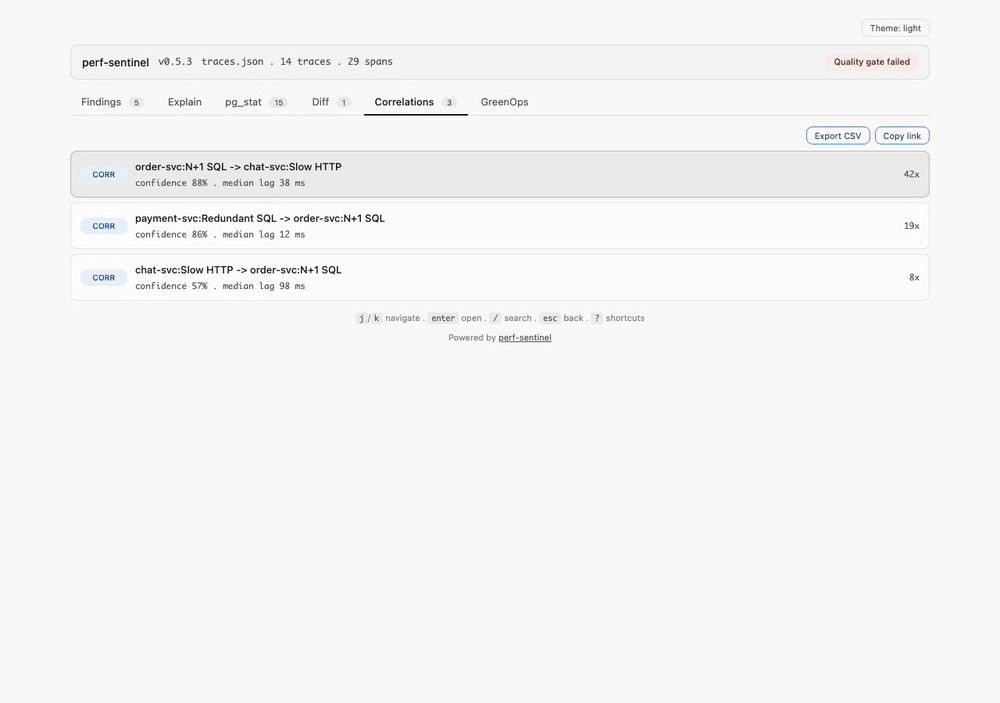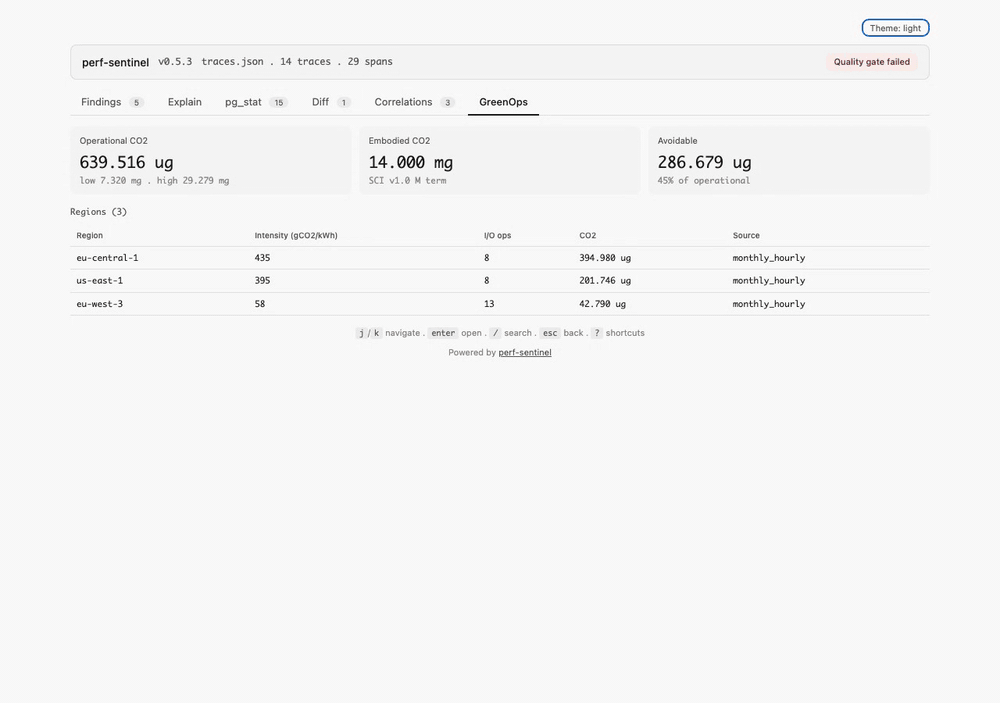
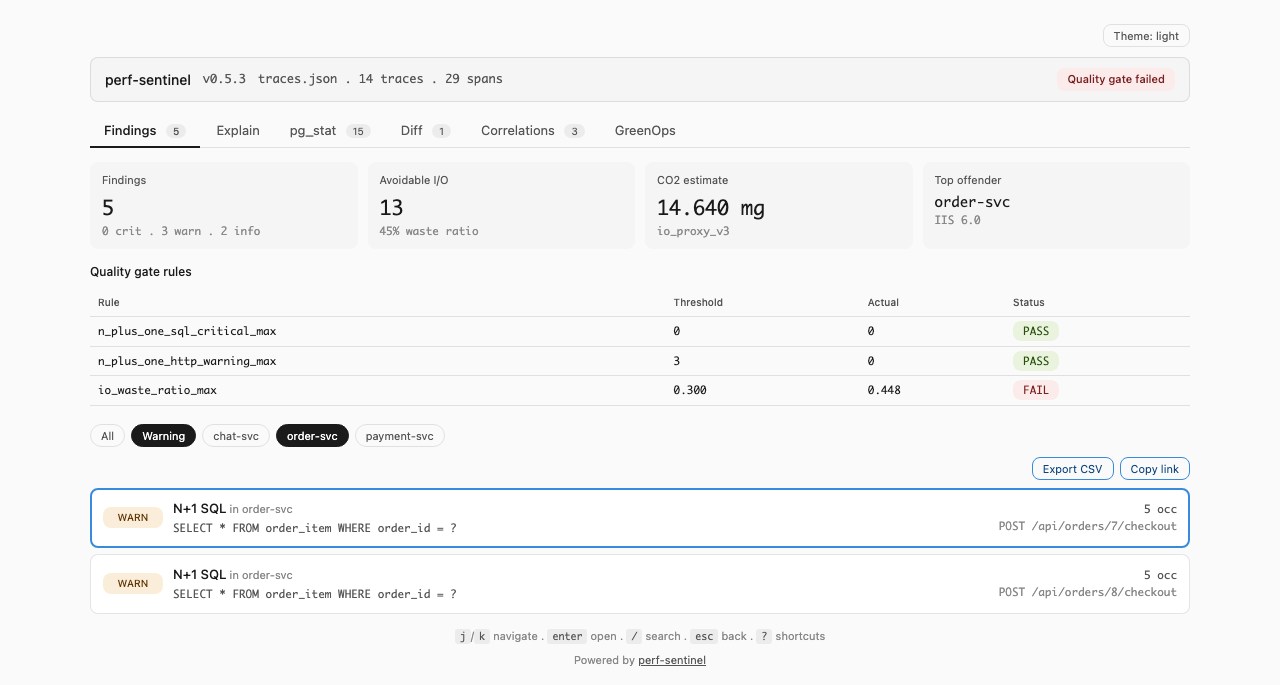
Le dashboard fonctionne offline (`file://`), zéro ressource externe, embarque uniquement les traces avec findings pour rester sous ~5 Mo. Clavier : `j`/`k`/`enter`/`esc` sur la liste Findings, `/` pour la recherche par onglet, `?` pour la cheatsheet complète, `g f`/`g e`/`g p`/`g d`/`g c`/`g r` pour switcher d'onglet style vim. Bouton Export CSV sur les onglets Findings, pg_stat, Diff et Correlations. Le fragment d'URL encode l'onglet actif, la recherche et les puces de filtre pour qu'un lien partagé restaure exactement la même vue.
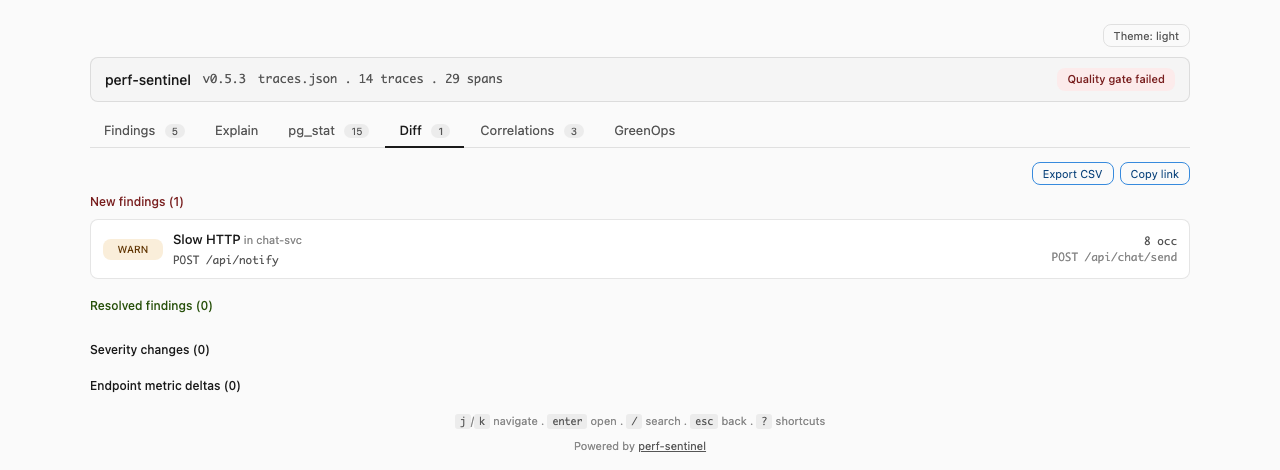
### Diff de régression PR
```bash
# Comparer deux analyses, fait remonter nouveaux findings, résolutions et changements de sévérité
perf-sentinel diff --before base.json --after head.json
# Sortie machine pour CI
perf-sentinel diff --before base.json --after head.json --format json
perf-sentinel diff --before base.json --after head.json --format sarif
```
L'identité pour le matching est `(finding_type, service, source_endpoint, pattern.template)`. Buckets de sortie : `new_findings`, `resolved_findings`, `severity_changes`, `endpoint_metric_deltas`. À utiliser dans un job PR pour attraper les régressions avant qu'elles atterrissent sur la branche principale.
### Interroger un daemon en cours d'exécution
Toutes les sous-actions affichent une sortie colorée par défaut. Utilisez `--format json` pour le scripting.
```bash
# Lister les findings récents (sortie colorée par défaut)
perf-sentinel query findings
perf-sentinel query findings --service order-svc --severity critical
# Expliquer un arbre de trace avec findings en ligne
perf-sentinel query explain --trace-id abc123
# TUI interactif avec les données live du daemon
perf-sentinel query inspect
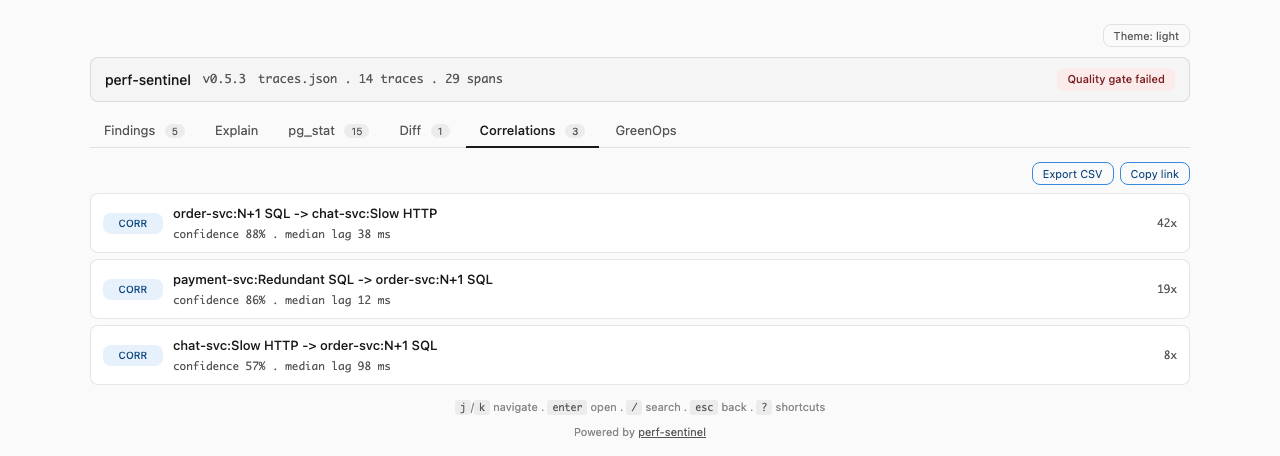
# Afficher les corrélations cross-trace
perf-sentinel query correlations
# Vérifier l'état du daemon
perf-sentinel query status
# Sortie JSON pour le scripting
perf-sentinel query findings --format json
perf-sentinel query status --format json
```
### Mode streaming (daemon)
```bash
perf-sentinel watch
```
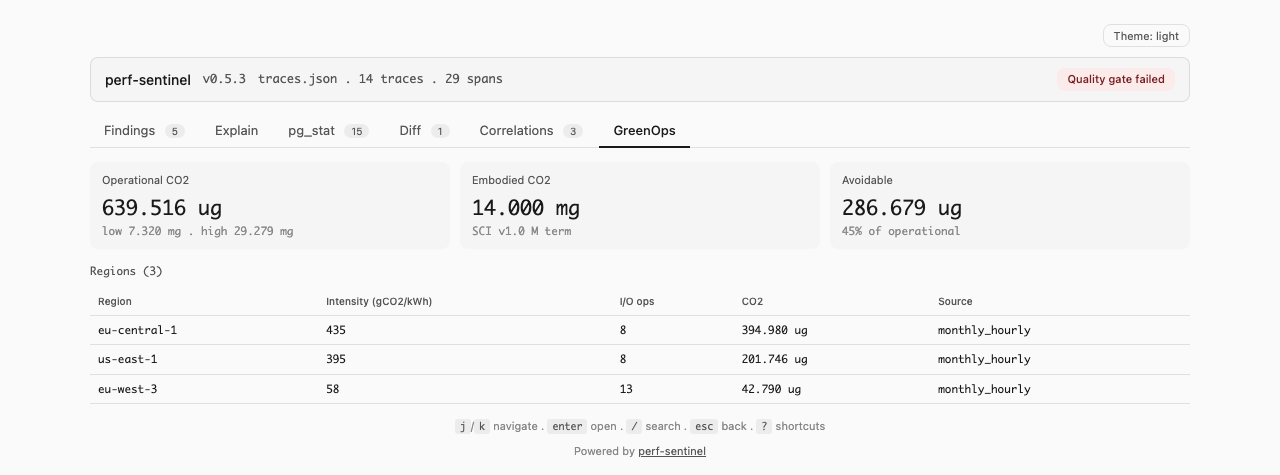
## GreenOps : scoring éco-conception intégré
Chaque finding inclut un **I/O Intensity Score (IIS)** : le nombre d'opérations I/O générées par requête utilisateur pour un endpoint donné. Réduire les I/O inutiles (N+1, appels redondants) améliore les temps de réponse *et* réduit la consommation énergétique : ce ne sont pas des objectifs concurrents.
- **I/O Intensity Score** = opérations I/O totales pour un endpoint / nombre d'invocations
- **I/O Waste Ratio** = opérations I/O évitables (issues des findings) / opérations I/O totales
Aligné avec le modèle **Software Carbon Intensity** ([SCI v1.0 / ISO/IEC 21031:2024](https://github.com/Green-Software-Foundation/sci)) de la Green Software Foundation. Le champ `co2.total` contient le **numérateur SCI** `(E × I) + M` sommé sur les traces analysées, pas le score d'intensité par requête. Le scoring multi-région est automatique quand les spans OTel portent l'attribut `cloud.region`. **Plus de 30 régions cloud** disposent de profils d'intensité carbone horaire intégrés, avec une variation saisonnière (mois x heure) pour FR, DE, GB et US-East. En mode daemon, le coefficient énergétique peut être affiné via [Scaphandre](https://github.com/hubblo-org/scaphandre) (RAPL bare-metal) ou l'estimation cloud-native CPU% + SPECpower pour les VMs AWS/GCP/Azure (section `[green.cloud]`) et l'intensité du réseau électrique peut être récupérée en temps réel via l'**API Electricity Maps**, avec repli automatique sur le modèle proxy I/O. Les utilisateurs peuvent fournir leurs propres profils horaires via `[green] hourly_profiles_file` ou ajuster les coefficients du modèle proxy depuis des mesures terrain via `perf-sentinel calibrate`.
> **Note :** les estimations CO₂ sont **directionnelles**, pas auditables. Chaque estimation porte un intervalle d'incertitude multiplicative `~2×` (`low = mid/2`, `high = mid×2`) car le modèle proxy I/O est approximatif. perf-sentinel est un **compteur de gaspillage**, pas un outil de comptabilité carbone. Ne l'utilisez pas pour le reporting CSRD ou GHG Protocol Scope 3. Voir [docs/FR/LIMITATIONS-FR.md](docs/FR/LIMITATIONS-FR.md#précision-des-estimations-carbone) pour la méthodologie complète.
## Positionnement
La détection d'anti-patterns de performance basée sur les traces existe déjà dans les APM matures et dans plusieurs outils open source. La niche de perf-sentinel est d'être léger, indépendant du runtime, intégré au CI/CD et carbon-aware, pas de remplacer une suite d'observabilité complète.
| Capacité | [Hypersistence Optimizer](https://vladmihalcea.com/hypersistence-optimizer/) | [Datadog APM + DBM](https://www.datadoghq.com/product/apm/) | [New Relic APM](https://newrelic.com/platform/application-monitoring) | [Sentry](https://sentry.io/for/performance/) | [Digma](https://digma.ai/) | [Grafana Pyroscope](https://grafana.com/oss/pyroscope/) | **perf-sentinel** |
|-----------------------------|------------------------------------------------------------------------------|-------------------------------------------------------------|-----------------------------------------------------------------------|----------------------------------------------------|--------------------------------------|-----------------------------------------------------------|---------------------------------------------|
| Détection N+1 SQL | JPA uniquement, en test | Oui, automatique (DBM) | Oui, automatique | Oui, OOTB | Oui, orienté IDE (JVM/.NET) | Non (profileur CPU/mémoire, pas un analyseur de requêtes) | Oui, au niveau protocole, tout runtime OTel |
| Détection N+1 HTTP | Non | Oui, service maps | Oui, corrélation de traces | Oui, détecteur N+1 API Call | Partiel | Non | Oui |
| Support polyglotte | Java uniquement | Agents par langage | Agents par langage | SDK par langage, la plupart | JVM + .NET (Rider beta) | eBPF host-wide + SDKs par langage | Tout runtime instrumenté OTel |
| Corrélation cross-service | Non | Oui | Oui | Oui | Limitée (IDE local) | Trace-vers-profile via exemplars OTel | Via trace ID |
| Scoring GreenOps / SCI v1.0 | Non | Non | Non | Non | Non | Non | Intégré (directionnel) |
| Empreinte runtime | Bibliothèque (sans overhead) | Agent (~100-150 Mo RSS) | Agent (~100-150 Mo RSS) | SDK + backend | Backend local (Docker) | Agent + backend (~50-100 Mo RSS selon le langage) | Binaire standalone (<15 Mo RSS) |
| Quality gate CI/CD natif | Assertions de tests manuelles | Alertes, pas de gate de build | Alertes, pas de gate de build | Alertes, pas de gate de build | Non | Non | Oui (exit 1 sur dépassement de seuil) |
| Licence | Commerciale (Optimizer) | Propriétaire SaaS | Propriétaire SaaS | FSL (bascule Apache-2 après 2 ans) | Freemium, propriétaire | AGPL-3.0 | AGPL-3.0 |
| Tarif / auto-hébergement | Licence unique | SaaS à l'usage (non auto-hébergeable) | SaaS à l'usage (non auto-hébergeable) | Offre gratuite + plans SaaS (non auto-hébergeable) | Freemium SaaS (non auto-hébergeable) | Gratuit, entièrement auto-hébergeable | Gratuit, entièrement auto-hébergeable |
Les empreintes d'agent pour les APM commerciaux sont des ordres de grandeur issus de retours publics de déploiement ; l'overhead réel dépend du périmètre d'instrumentation.
### Ce que perf-sentinel n'est pas
Une comparaison honnête passe par nommer ce que perf-sentinel ne fait pas :
- **Pas un remplacement d'APM complet.** Pas de dashboards, pas d'UI d'alerting, pas de RUM, pas d'agrégation de logs, pas de profiling distribué. Si vous en avez besoin, Datadog, New Relic et Sentry restent les bons outils.
- **Pas un profileur continu.** perf-sentinel observe des patterns d'I/O au niveau protocole ; il ne sample pas le temps on-CPU, les allocations ni les stack traces. Si vous voulez des flame graphs et du profiling CPU/mémoire language-aware, [Grafana Pyroscope](https://grafana.com/oss/pyroscope/) est le pendant open source et se marie bien avec perf-sentinel : Pyroscope vous dit où le temps de calcul est consommé, perf-sentinel vous dit quels patterns d'I/O drivent ce temps.
- **Pas une solution de monitoring temps réel.** Le mode daemon diffuse des findings en streaming, mais le centre de gravité du projet reste le quality gate CI/CD et l'analyse post-hoc de traces, pas l'observabilité live en production.
- **Pas un outil de comptabilité carbone réglementaire.** À utiliser pour chasser le gaspillage, pas pour produire un reporting CSRD ou GHG Protocol Scope 3. Voir la note GreenOps plus haut pour les limites méthodologiques.
- **Pas un remplacement pour l'énergie mesurée.** Le modèle I/O-vers-énergie reste une approximation. Pour de la mesure de puissance par processus précise, utilisez Scaphandre (supporté en entrée) ou les APIs énergie de votre fournisseur cloud.
- **Pas zero-config.** La détection au niveau protocole requiert que vos applications émettent des traces OTel. Si votre stack n'est pas instrumenté, perf-sentinel n'a rien à analyser.
- **Pas un plugin IDE.** Pour du feedback in-IDE pendant que vous codez en JVM/.NET, [Digma](https://digma.ai/) propose une expérience JetBrains bien intégrée.
perf-sentinel est un outil complémentaire centré sur un problème précis : détecter les anti-patterns d'I/O dans les traces, scorer leur impact (y compris carbone) et enforcer des seuils en CI. Utilisez-le à côté de votre stack d'observabilité existante, pas à sa place.
## Que remonte-t-il ?
Pour chaque anti-pattern détecté, perf-sentinel remonte :
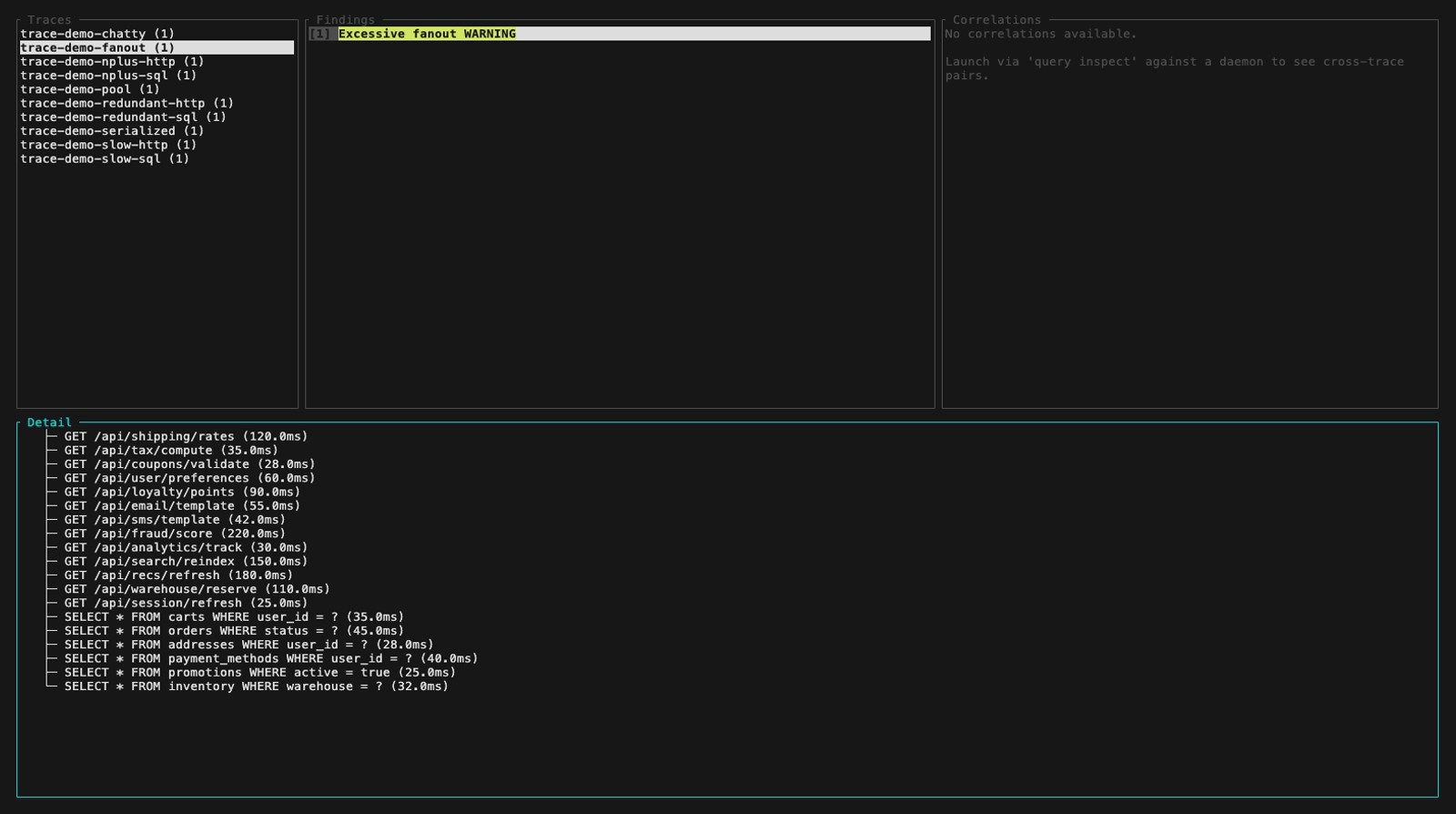
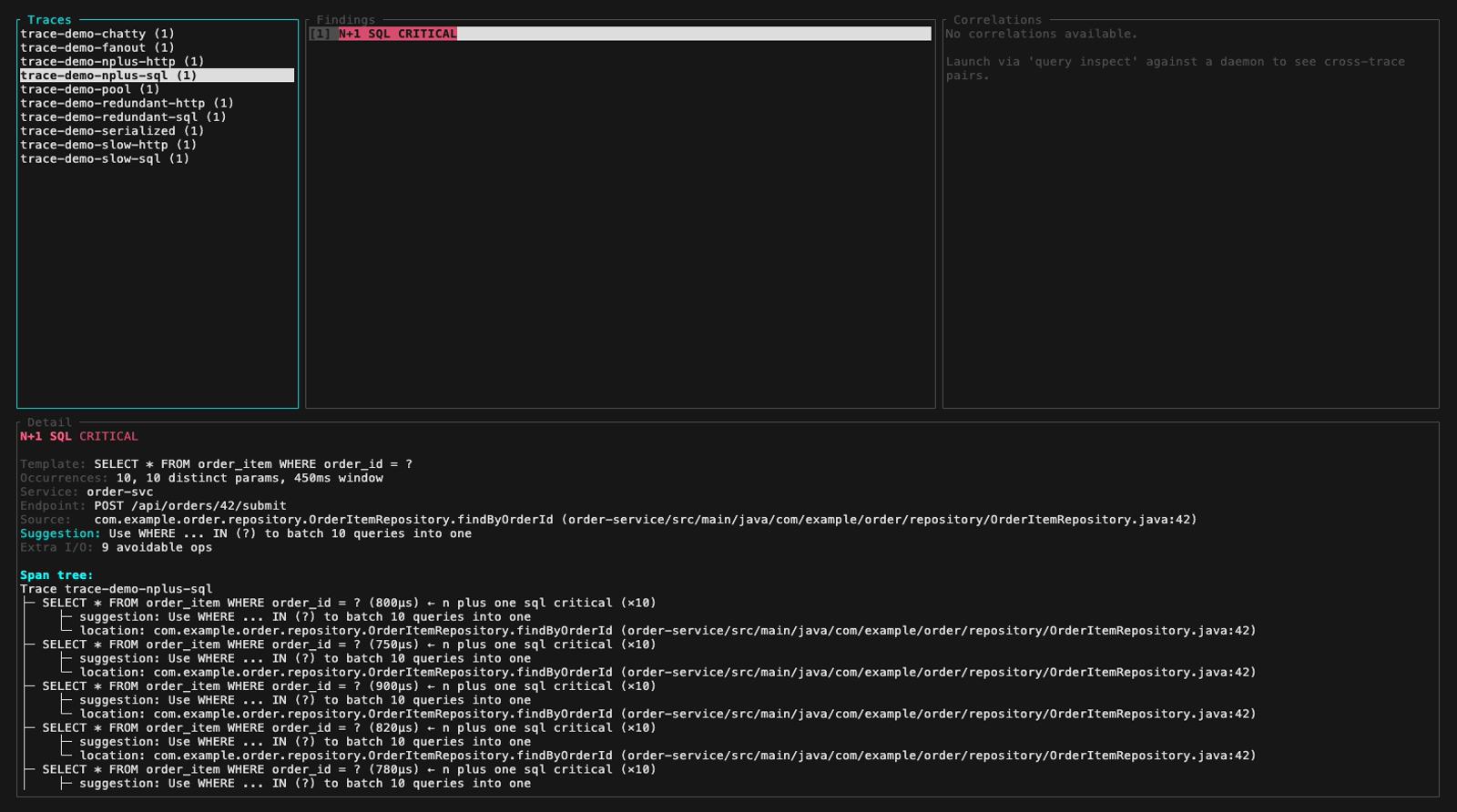
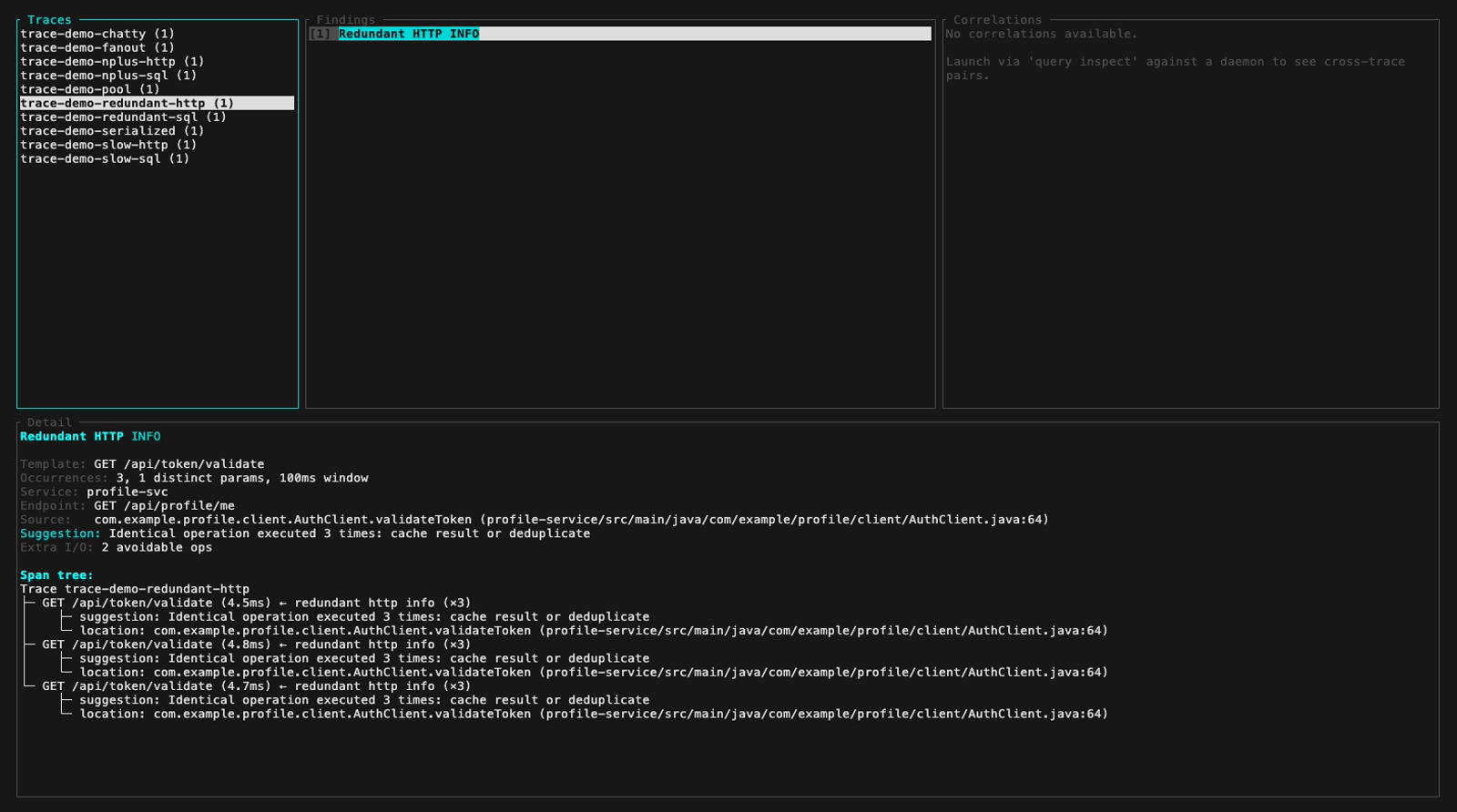
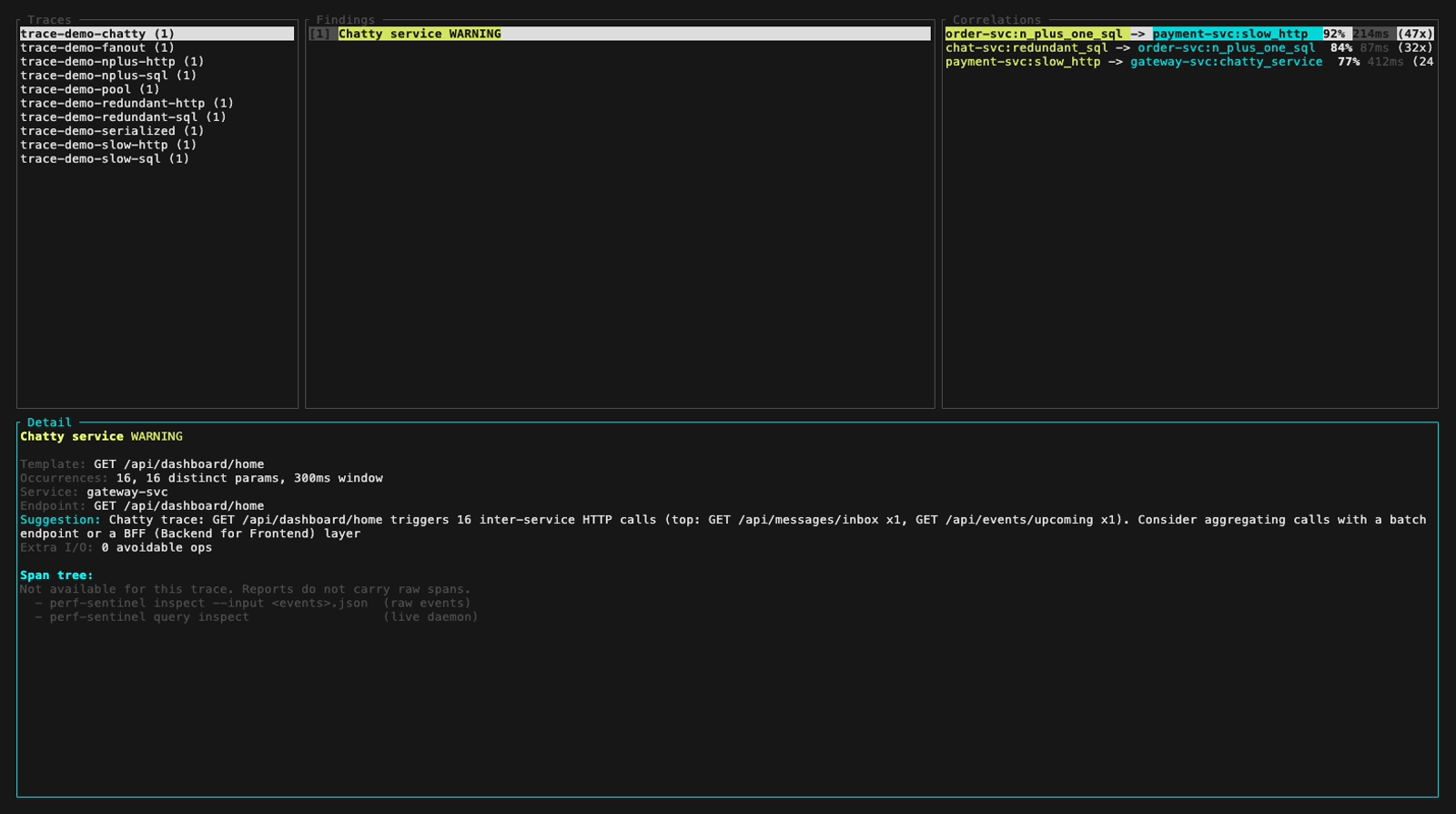
- **Type :** N+1 SQL, N+1 HTTP, requête redondante, SQL lent, HTTP lent, fanout excessif, service bavard (chatty service), saturation du pool de connexions ou appels sérialisés. Les corrélations cross-trace sont aussi remontées en mode daemon
- **Template normalisé :** la requête ou l'URL avec les paramètres remplacés par des placeholders (`?`, `{id}`)
- **Occurrences :** combien de fois le pattern s'est déclenché dans la fenêtre de détection
- **Endpoint source :** quel endpoint applicatif l'a généré (ex : `GET /api/orders`)
- **Suggestion :** par exemple *"batch cette requête"*, *"utilise un batch endpoint"*, *"ajouter un index"*
- **Localisation source :** quand les spans OTel portent les attributs `code.function`, `code.filepath`, `code.lineno`, les findings affichent le fichier source et la ligne d'origine. Les rapports SARIF incluent des `physicalLocations` pour les annotations inline GitHub/GitLab
- **Impact GreenOps :** estimation des I/O évitables, I/O Intensity Score, objet `co2` structuré (`low`/`mid`/`high`, termes opérationnel + embodié SCI v1.0), breakdown par région quand le scoring multi-région est actif
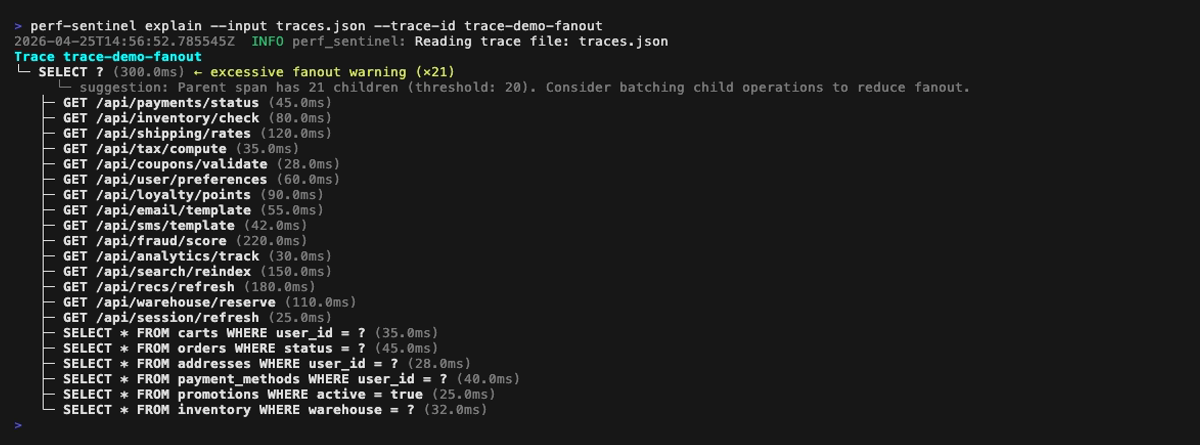
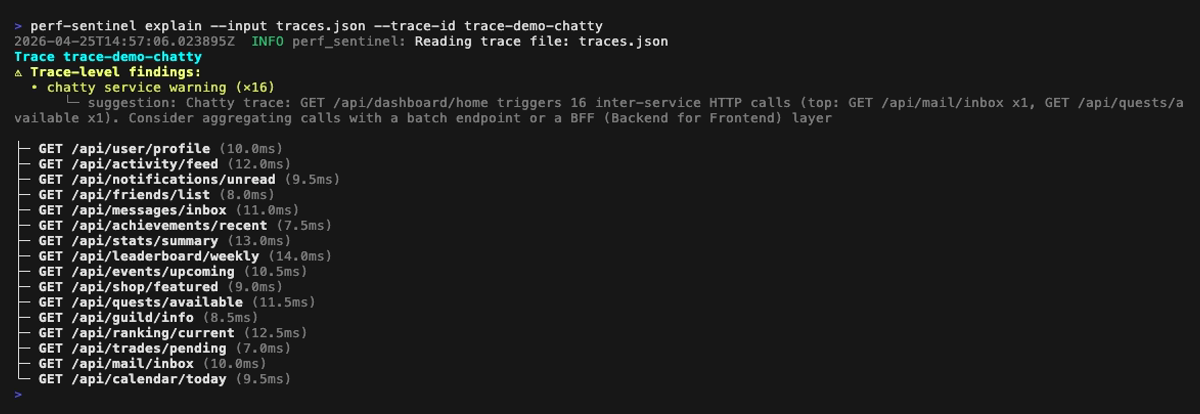
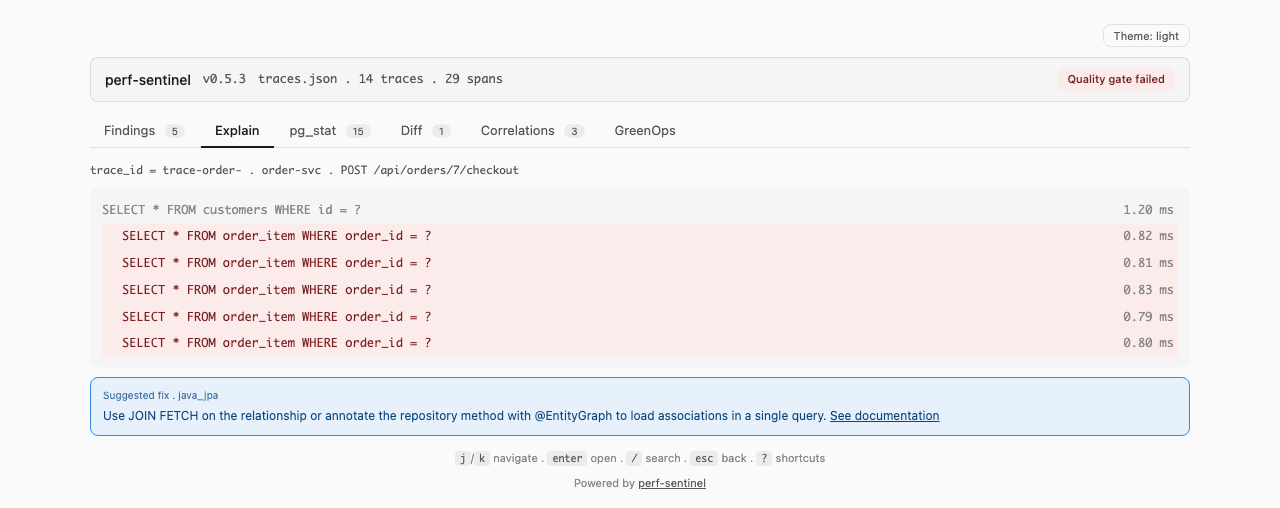
Tu peux aussi explorer une trace unique avec le mode `explain` en arbre, qui annote les findings directement à côté des spans concernés :

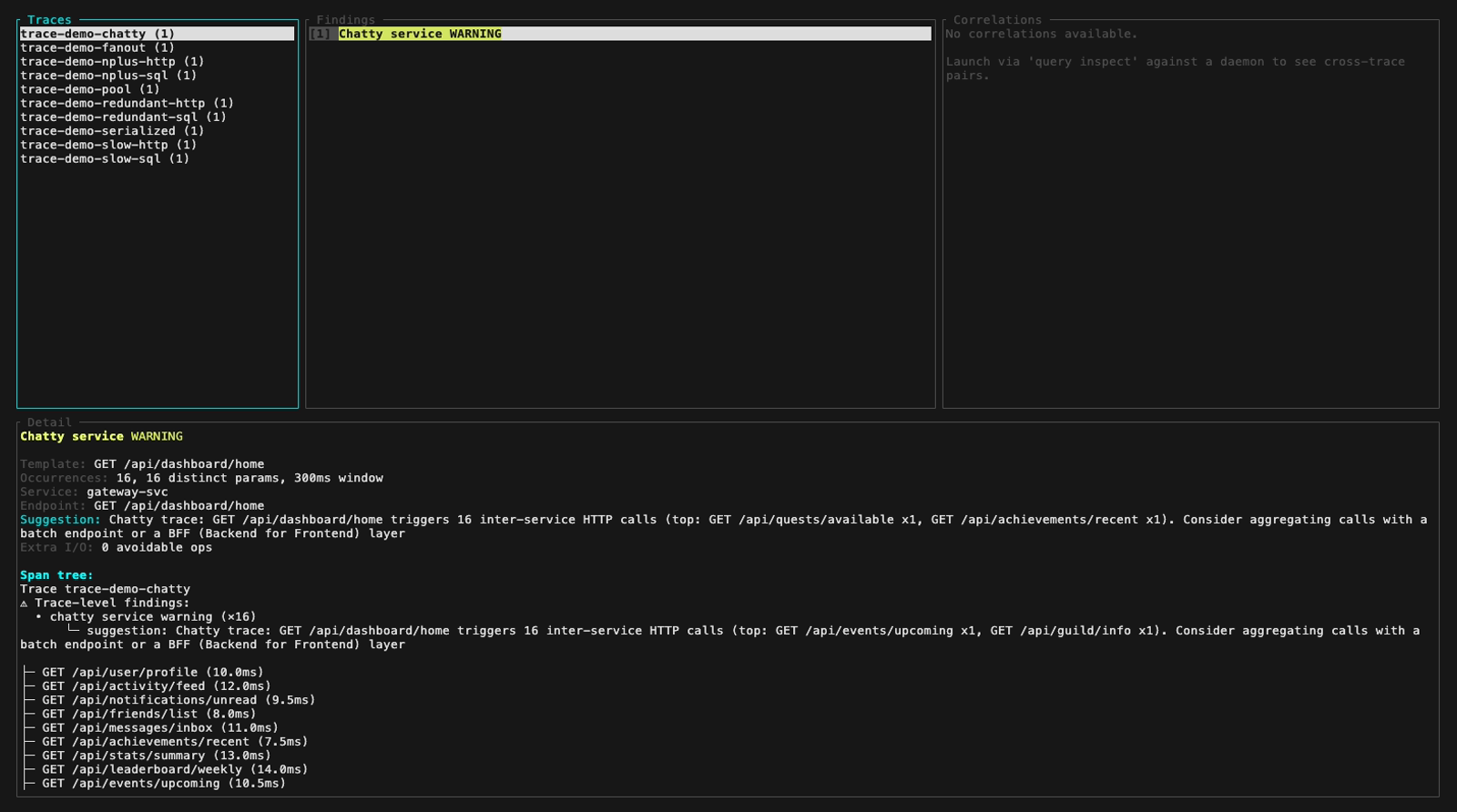
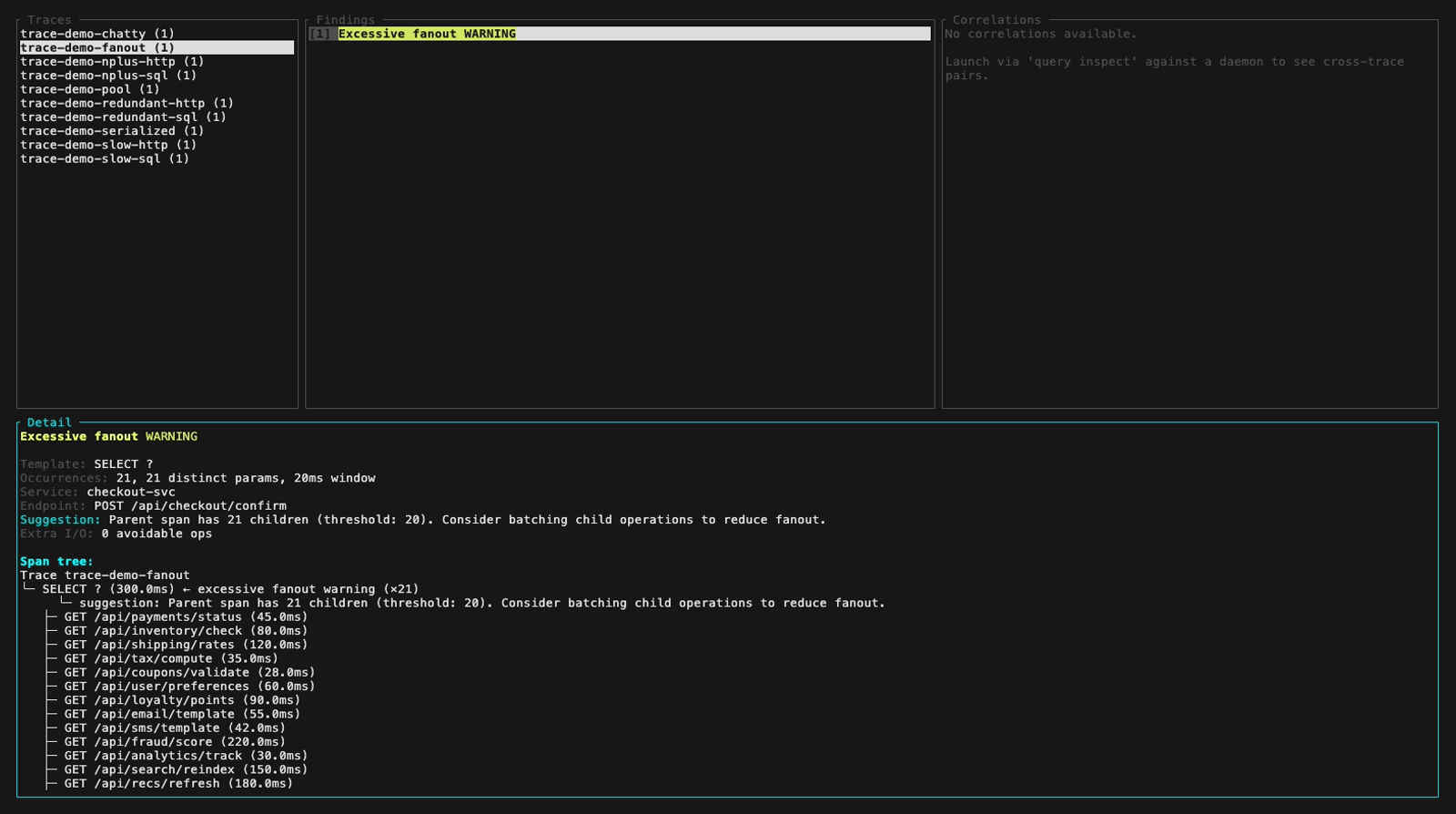
Ou navigue dans les traces, les findings et les arbres de spans de manière interactive avec le TUI `inspect` (3 panneaux, navigation au clavier) :

Ou produis un dashboard HTML single-file avec `report` pour l'exploration post-CI en navigateur. Double-clic pour l'ouvrir hors ligne, clic sur un finding pour sauter à son arbre de trace, bascule dark/light, le tout dans un seul fichier autonome sans ressource externe :
```bash
perf-sentinel report --input traces.json --output report.html
```
Le tour du dashboard est affiché en haut de cette page sous [Aperçu rapide](#aperçu-rapide). Les captures figées par onglet sont dans la section **Captures** en bas.
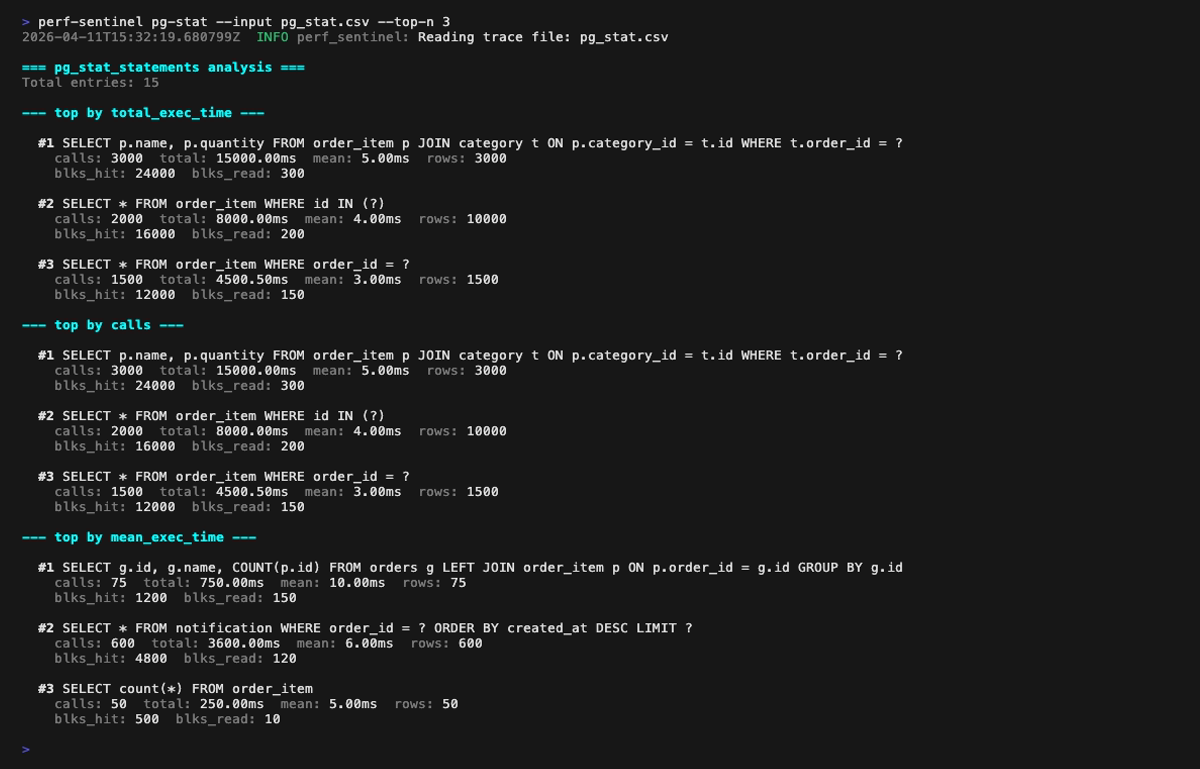
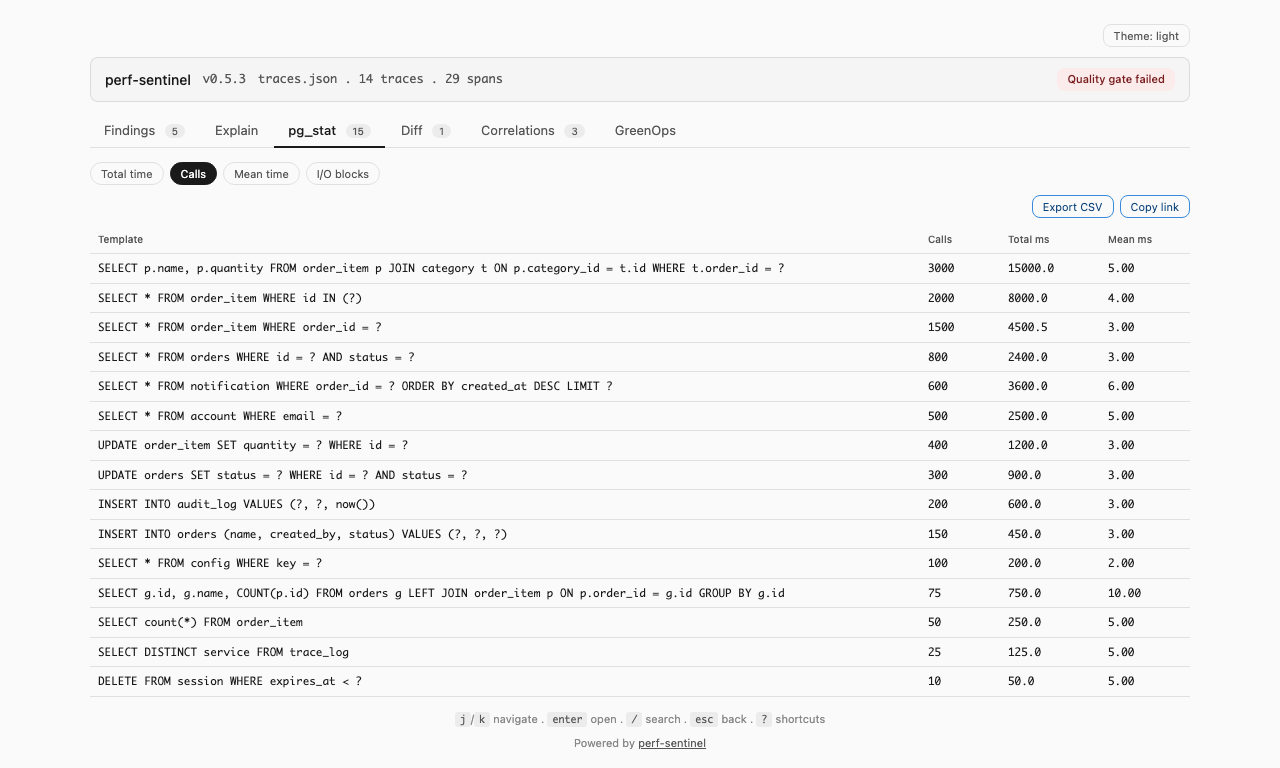
Ou classe les hotspots SQL depuis un export `pg_stat_statements` PostgreSQL avec `pg-stat`. Quatre classements (par temps total, par nombre d'appels, par latence moyenne, par blocs shared-buffer touchés) aident à repérer les requêtes qui dominent la DB sans apparaître dans tes traces, signe d'un trou d'instrumentation :

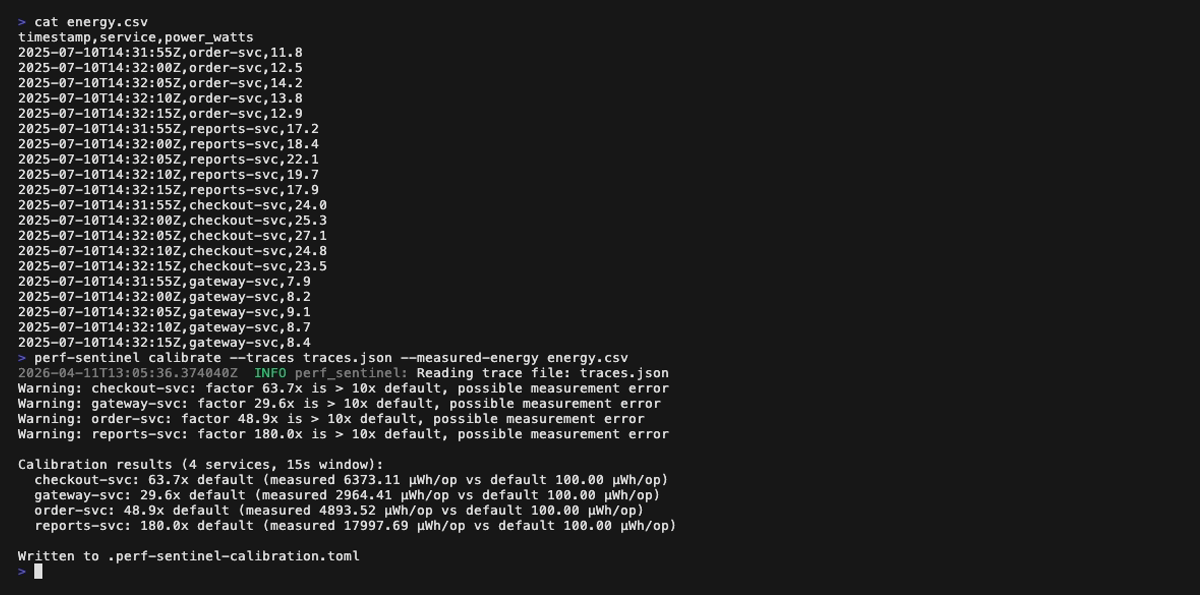
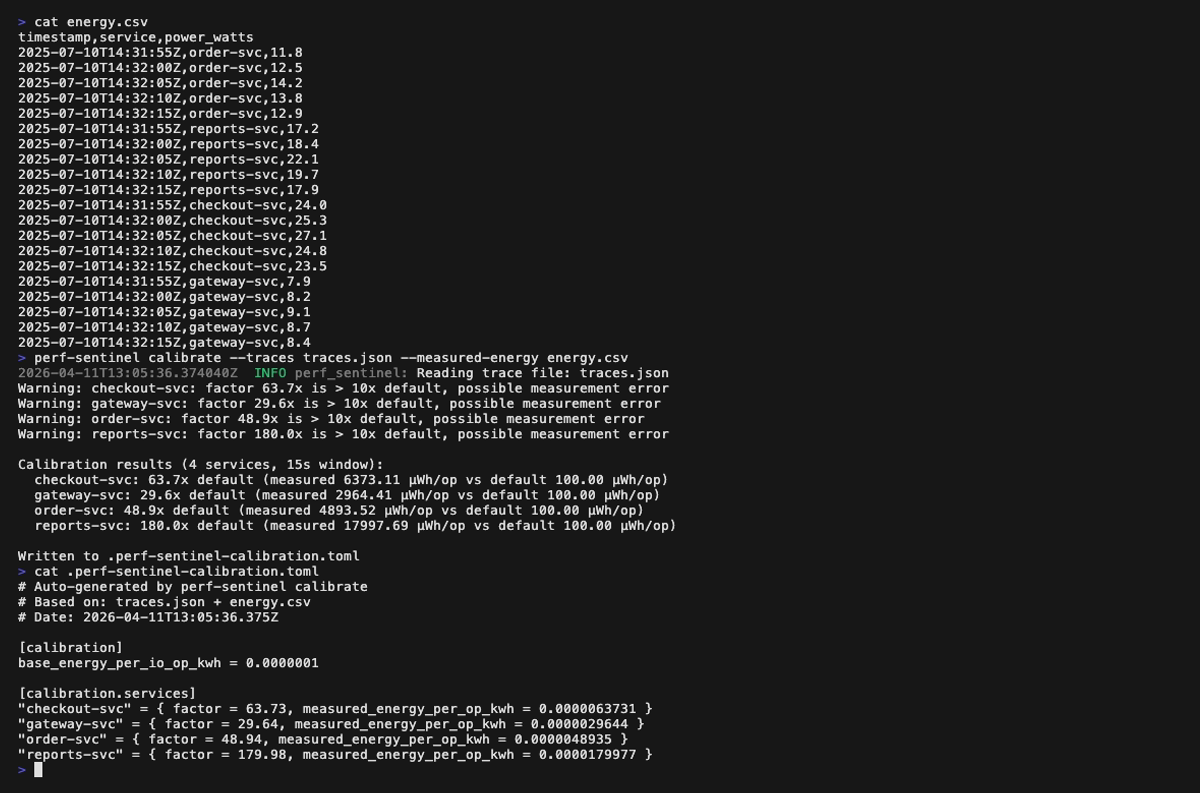
Enfin, ajuste les coefficients I/O-vers-énergie à ton infrastructure réelle avec `calibrate`, qui corrèle un fichier de traces avec des mesures d'énergie (Scaphandre, supervision cloud, etc.) et génère un fichier TOML chargeable via `[green] calibration_file` :

Images fixes
**Configuration** (`.perf-sentinel.toml`) :

**Rapport d'analyse** (le premier GIF ci-dessus défile dans le rapport complet, les quatre images fixes ci-dessous le couvrent page par page, avec un léger recouvrement pour que chaque finding apparaisse en entier sur au moins une page) :
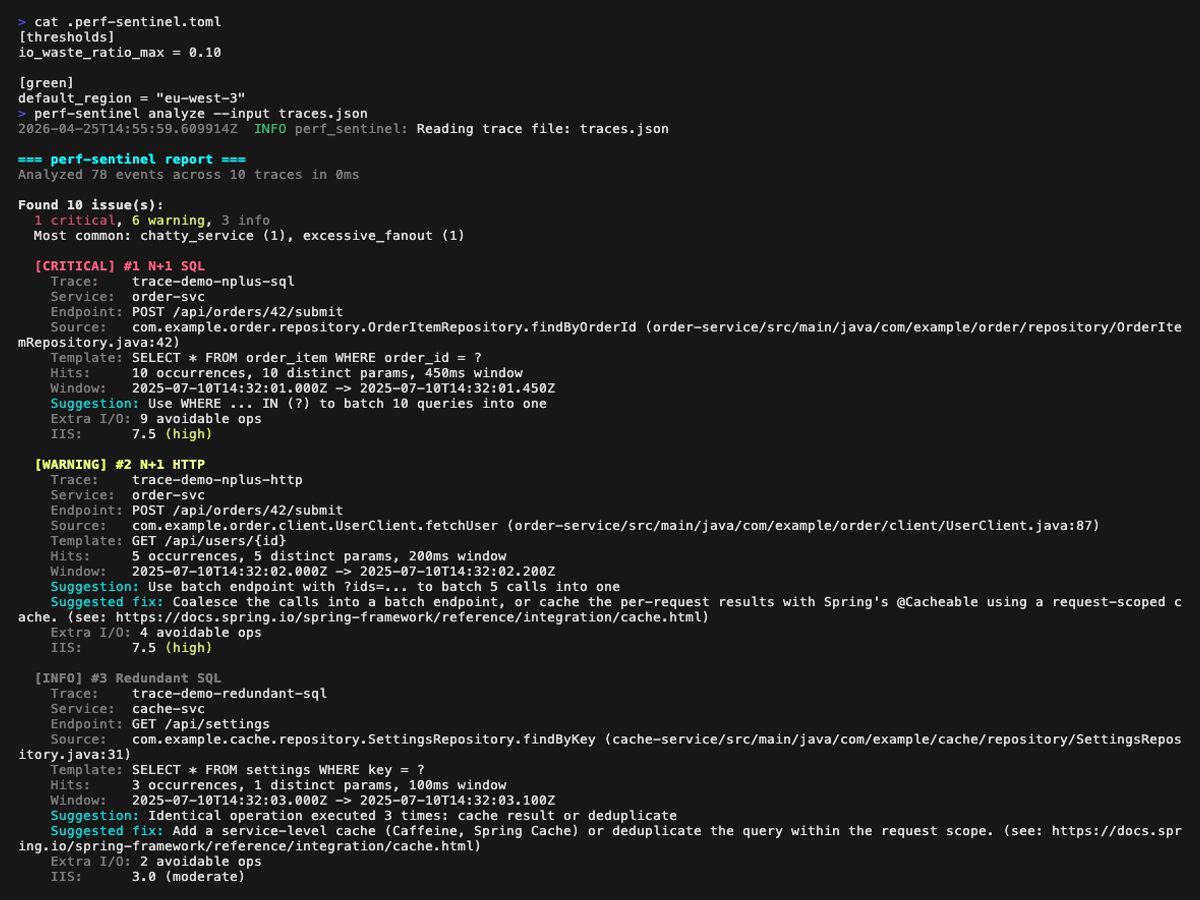
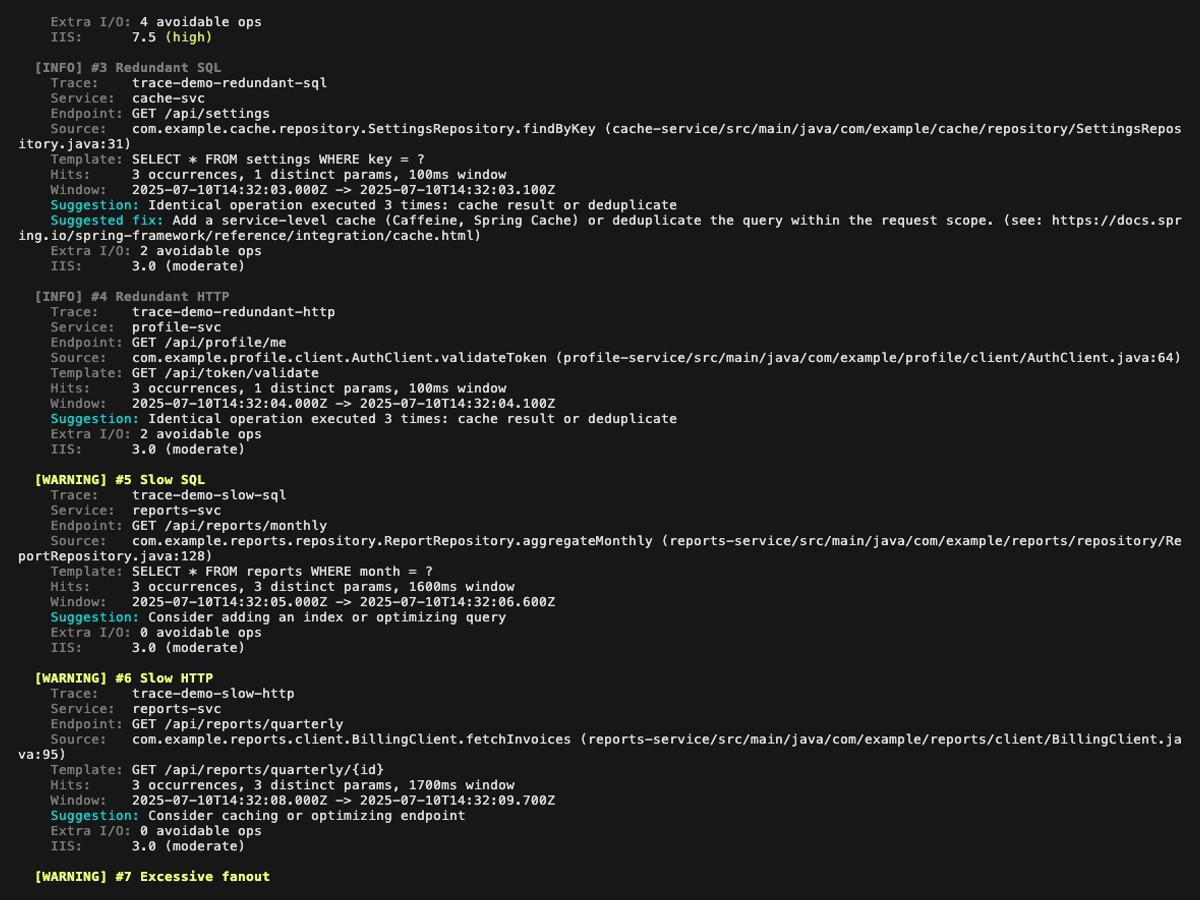
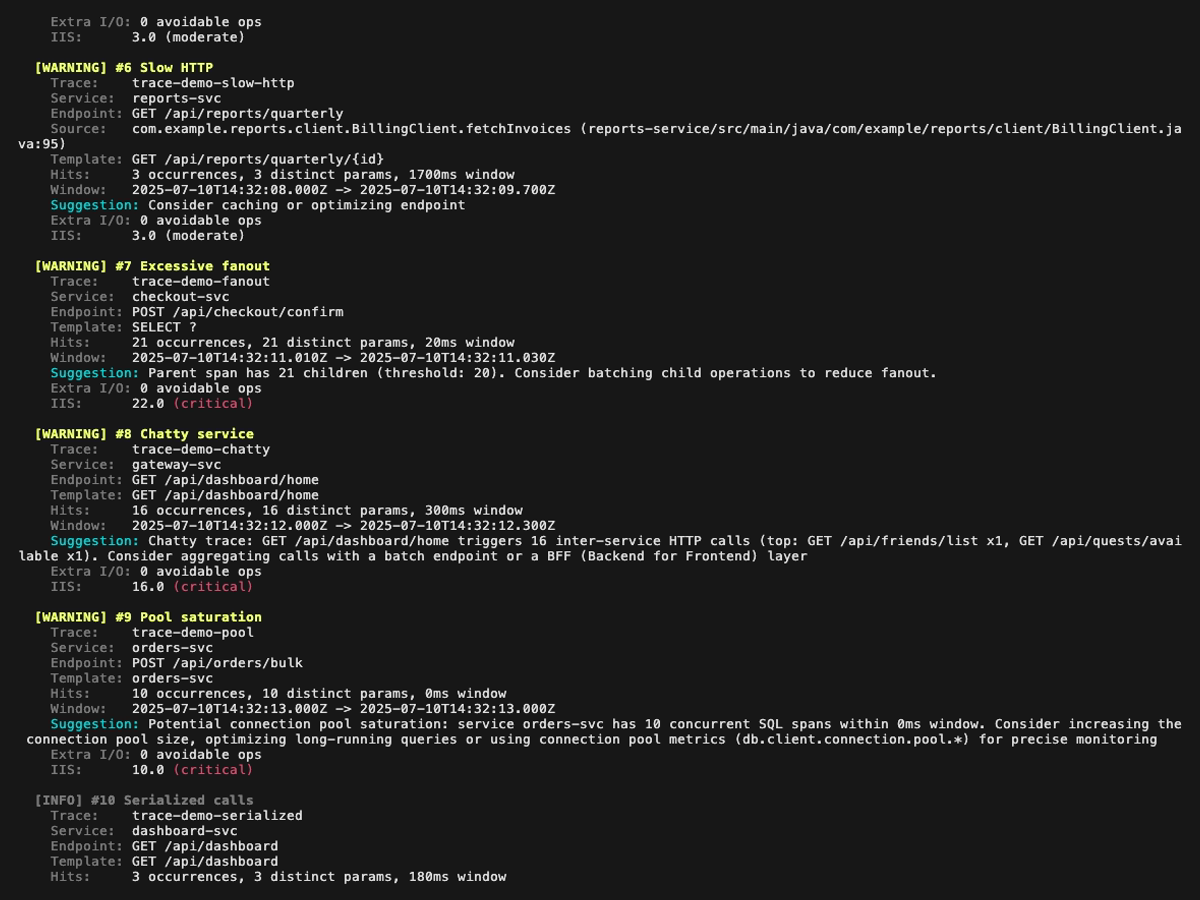
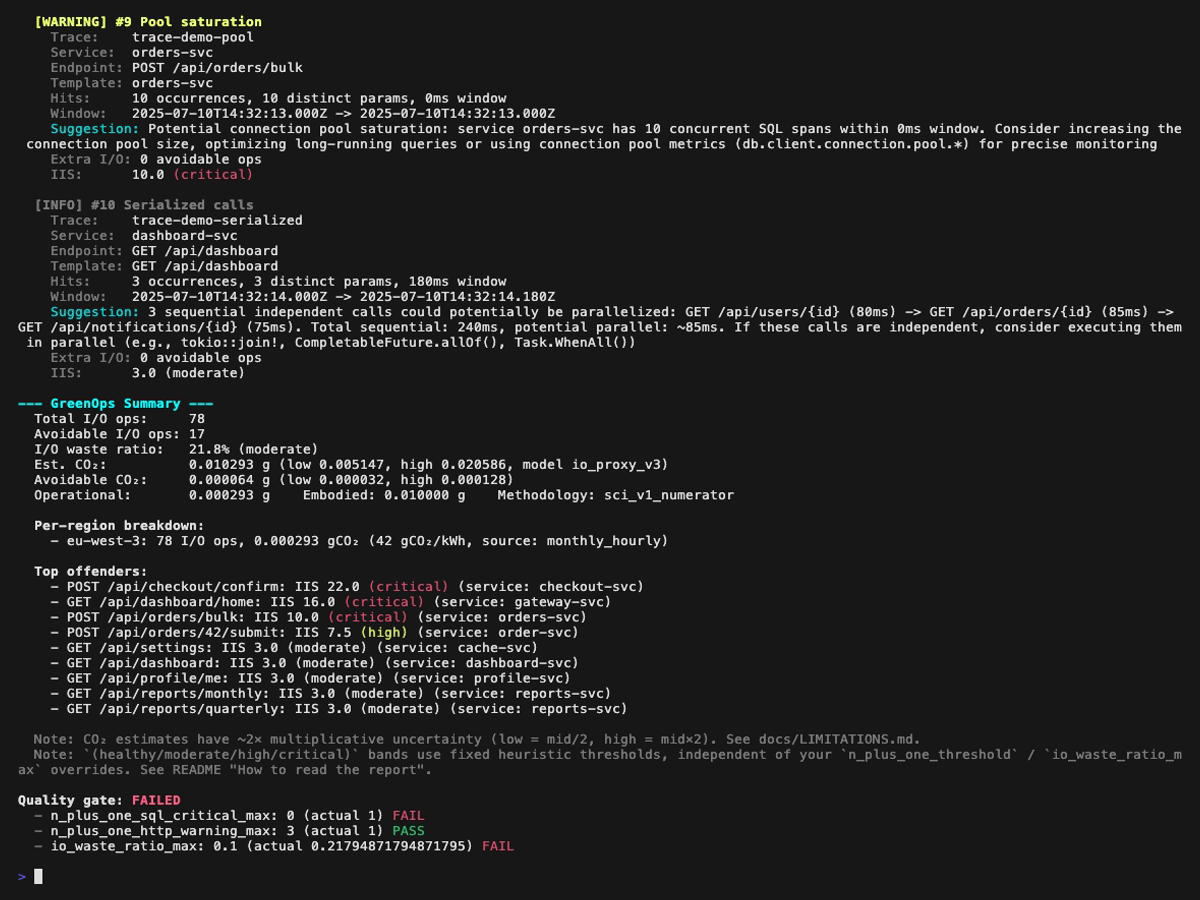
**Mode explain** (vue en arbre d'une trace unique, `perf-sentinel explain --trace-id `). Les findings rattachés à un span (N+1, redondant, lent, fanout) sont affichés inline à côté du span concerné ; les findings de niveau trace (service bavard, saturation du pool, appels sérialisés) sont remontés dans une section dédiée au-dessus de l'arbre :
**Mode inspect** (TUI interactif, `perf-sentinel inspect`). Le header du panneau findings colore chaque finding selon sa sévérité ; les cinq images fixes ci-dessous parcourent la fixture démo à travers les trois niveaux de sévérité plus une vue du panneau détail avec sa fonction de scroll :
`inspect --input` accepte aussi un Report JSON pré-calculé (par exemple un snapshot daemon issu de `/api/export/report`). Les panels Findings et Correlations s'allument complètement, le panel Detail affiche un message qui pointe vers les deux chemins qui portent les vrais spans :
**Mode pg-stat** (`perf-sentinel pg-stat --input `) : classe les requêtes SQL de trois manières (par temps d'exécution total, par nombre d'appels, par latence moyenne). Cross-référence avec tes traces via `--traces` pour repérer les requêtes qui dominent la DB sans apparaître dans ton instrumentation :
**Mode calibrate** (`perf-sentinel calibrate --traces --measured-energy `) :

**Dashboard report** (`perf-sentinel report`) : six captures, une par onglet. Les GIFs plus haut déroulent le tour complet, ces captures figent chaque panneau pour lire les détails au zoom. Chaque `` sert la variante sombre quand le navigateur annonce `prefers-color-scheme: dark` :
En mode CI (`perf-sentinel analyze --ci`), la sortie est un rapport JSON structuré. L'exemple ci-dessous est la forme audit-grade (région résolue avec profil monthly hourly, scoring config Electricity Maps surfacé pour le reporting Scope 2). Reproduisez-le avec :
```bash
cat > /tmp/perf-sentinel-readme.toml <<'EOF'
[green]
default_region = "eu-west-3"
[green.electricity_maps]
endpoint = "https://api.electricitymaps.com/v4"
region_map = { "eu-west-3" = "FR" }
EOF
PERF_SENTINEL_EMAPS_TOKEN=mock-token \
perf-sentinel analyze \
--input tests/fixtures/demo.json \
--config /tmp/perf-sentinel-readme.toml \
--format json
```
Le knob `default_region` mappe chaque span sans attribut `cloud_region` à `eu-west-3`, l'entrée `region_map` la pinne au réseau électrique français, et la variable d'environnement `mock-token` suffit à faire surfacer `green_summary.scoring_config` (le scraper ne tourne pas sur le chemin batch `analyze`, seules les métadonnées de méthodologie sont enregistrées).
Exemple de rapport JSON
```json
{
"analysis": {
"duration_ms": 1,
"events_processed": 78,
"traces_analyzed": 10
},
"findings": [
{
"type": "n_plus_one_sql",
"severity": "critical",
"trace_id": "trace-demo-nplus-sql",
"service": "order-svc",
"source_endpoint": "POST /api/orders/42/submit",
"pattern": {
"template": "SELECT * FROM order_item WHERE order_id = ?",
"occurrences": 10,
"window_ms": 450,
"distinct_params": 10
},
"suggestion": "Use WHERE ... IN (?) to batch 10 queries into one",
"first_timestamp": "2025-07-10T14:32:01.000Z",
"last_timestamp": "2025-07-10T14:32:01.450Z",
"green_impact": {
"estimated_extra_io_ops": 9,
"io_intensity_score": 7.5,
"io_intensity_band": "high"
},
"confidence": "ci_batch",
"code_location": {
"function": "OrderItemRepository.findByOrderId",
"filepath": "order-service/src/main/java/com/example/order/repository/OrderItemRepository.java",
"lineno": 42,
"namespace": "com.example.order.repository"
}
},
{
"type": "n_plus_one_http",
"severity": "warning",
"trace_id": "trace-demo-nplus-http",
"service": "order-svc",
"source_endpoint": "POST /api/orders/42/submit",
"pattern": {
"template": "GET /api/users/{id}",
"occurrences": 5,
"window_ms": 200,
"distinct_params": 5
},
"suggestion": "Use batch endpoint with ?ids=... to batch 5 calls into one",
"first_timestamp": "2025-07-10T14:32:02.000Z",
"last_timestamp": "2025-07-10T14:32:02.200Z",
"green_impact": {
"estimated_extra_io_ops": 4,
"io_intensity_score": 7.5,
"io_intensity_band": "high"
},
"confidence": "ci_batch",
"code_location": {
"function": "UserClient.fetchUser",
"filepath": "order-service/src/main/java/com/example/order/client/UserClient.java",
"lineno": 87,
"namespace": "com.example.order.client"
},
"suggested_fix": {
"pattern": "n_plus_one_http",
"framework": "java_generic",
"recommendation": "Coalesce the calls into a batch endpoint, or cache the per-request results with Spring's @Cacheable using a request-scoped cache.",
"reference_url": "https://docs.spring.io/spring-framework/reference/integration/cache.html"
}
}
],
"green_summary": {
"total_io_ops": 78,
"avoidable_io_ops": 17,
"io_waste_ratio": 0.218,
"io_waste_ratio_band": "moderate",
"top_offenders": [
{ "endpoint": "POST /api/checkout/confirm", "service": "checkout-svc", "io_intensity_score": 22.0, "io_intensity_band": "critical" },
{ "endpoint": "GET /api/dashboard/home", "service": "gateway-svc", "io_intensity_score": 16.0, "io_intensity_band": "critical" },
{ "endpoint": "POST /api/orders/bulk", "service": "orders-svc", "io_intensity_score": 10.0, "io_intensity_band": "critical" },
{ "endpoint": "POST /api/orders/42/submit", "service": "order-svc", "io_intensity_score": 7.5, "io_intensity_band": "high" }
],
"co2": {
"total": { "low": 0.005147, "mid": 0.010293, "high": 0.020586, "model": "io_proxy_v3", "methodology": "sci_v1_numerator" },
"avoidable": { "low": 0.000032, "mid": 0.000064, "high": 0.000128, "model": "io_proxy_v3", "methodology": "sci_v1_operational_ratio" },
"operational_gco2": 0.000293,
"embodied_gco2": 0.01
},
"regions": [
{
"status": "known",
"region": "eu-west-3",
"grid_intensity_gco2_kwh": 42.0,
"pue": 1.135,
"io_ops": 78,
"co2_gco2": 0.000293,
"intensity_source": "monthly_hourly"
}
],
"scoring_config": {
"api_version": "v4",
"emission_factor_type": "lifecycle",
"temporal_granularity": "hourly"
}
},
"quality_gate": {
"passed": false,
"rules": [
{ "rule": "n_plus_one_sql_critical_max", "threshold": 0.0, "actual": 1.0, "passed": false },
{ "rule": "n_plus_one_http_warning_max", "threshold": 3.0, "actual": 1.0, "passed": true },
{ "rule": "io_waste_ratio_max", "threshold": 0.3, "actual": 0.218, "passed": true }
]
},
"per_endpoint_io_ops": [
{ "service": "checkout-svc", "endpoint": "POST /api/checkout/confirm", "io_ops": 22 },
{ "service": "gateway-svc", "endpoint": "GET /api/dashboard/home", "io_ops": 16 },
{ "service": "order-svc", "endpoint": "POST /api/orders/42/submit", "io_ops": 15 }
]
}
```
Le run demo complet émet 11 findings, 9 `top_offenders` et 9 entrées `per_endpoint_io_ops`. Le bloc ci-dessus garde un sous-ensemble représentatif pour la lisibilité. Les consommateurs pre-0.5.x restent forward-compatibles parce que chaque champ récent est additif : `code_location`, `suggested_fix`, `scoring_config`, `regions[].intensity_estimated`, `correlations` et `transport_gco2` utilisent tous `#[serde(skip_serializing_if)]`, ils sont donc omis quand absents.
### Lecture du rapport
La CLI affiche un qualificatif `(healthy / moderate / high / critical)` à côté du I/O Intensity Score et du I/O waste ratio. La même classification est émise comme champs siblings dans le rapport JSON (`io_intensity_band`, `io_waste_ratio_band`), pour que les outils downstream (convertisseurs SARIF, dashboards Grafana, extensions IDE) puissent consommer nos heuristiques ou appliquer leurs propres sur les nombres bruts.
| IIS | Band | Ancrage |
|-----------|------------|------------------------------------------------------|
| < 2.0 | `healthy` | baseline CRUD simple (≤ 2 I/O par requête) |
| 2.0 - 4.9 | `moderate` | au-dessus de la baseline, à surveiller (heuristique) |
| 5.0 - 9.9 | `high` | seuil de détection du N+1 (5 occurrences) |
| ≥ 10.0 | `critical` | escalade CRITICAL du détecteur N+1 |
| I/O waste ratio | Band | Ancrage |
|-----------------|------------|-----------------------------------------------|
| < 10% | `healthy` | |
| 10 - 29% | `moderate` | |
| 30 - 49% | `high` | `[thresholds] io_waste_ratio_max` par défaut |
| ≥ 50% | `critical` | la majorité de l'I/O analysée est du gaspi |
**Contrat de stabilité JSON :** les valeurs d'enum ci-dessus (`healthy` / `moderate` / `high` / `critical`) sont stables entre versions. Les seuils numériques qui les déclenchent sont versionnés avec le binaire et peuvent évoluer. Les consommateurs qui veulent une classification indépendante de la version doivent lire les champs bruts `io_intensity_score` et `io_waste_ratio` et appliquer leurs propres bandes.
Pour la sévérité par finding (`Critical` / `Warning` / `Info` sur chaque type de détecteur), voir [`docs/FR/design/04-DETECTION-FR.md`](docs/FR/design/04-DETECTION-FR.md). Pour le rationale complet des bandes d'interprétation, voir [`docs/FR/LIMITATIONS-FR.md`](docs/FR/LIMITATIONS-FR.md#interprétation-des-scores).
### Acquitter les findings connus
Posez `.perf-sentinel-acknowledgments.toml` à la racine du repo pour taire les findings que l'équipe a acceptés comme connus et intentionnels. Les findings acquittés sont retirés de la sortie CLI (`analyze`, `report`, `inspect`, `diff`) et ne pèsent plus sur la quality gate.
```toml
[[acknowledged]]
signature = "redundant_sql:order-service:POST__api_orders:cafebabecafebabecafebabecafebabe"
acknowledged_by = "alice@example.com"
acknowledged_at = "2026-05-02"
reason = "Pattern d'invalidation de cache, intentionnel. Voir ADR-0042."
expires_at = "2026-12-31" # Optionnel, omettre pour rendre l'ack permanent.
```
Récupérez la signature d'un finding via `perf-sentinel analyze --format json | jq '.findings[].signature'`. Utilisez `--show-acknowledged` pour les faire réapparaître dans la sortie, ou `--no-acknowledgments` pour un audit complet. Référence détaillée dans [`docs/FR/ACKNOWLEDGMENTS-FR.md`](docs/FR/ACKNOWLEDGMENTS-FR.md).
## Architecture

## Topologies de déploiement
perf-sentinel supporte trois modèles de déploiement. Choisissez celui qui correspond à votre environnement.
### 1. Analyse batch CI (point de départ recommandé)
Analysez des fichiers de traces pré-collectés dans votre pipeline CI/CD. Le processus retourne le code 1 si le quality gate échoue.
```bash
# Dans votre job CI :
perf-sentinel analyze --ci --input traces.json --config .perf-sentinel.toml
```
Créez un `.perf-sentinel.toml` à la racine de votre projet :
```toml
[thresholds]
n_plus_one_sql_critical_max = 0 # zéro tolérance pour les N+1 SQL
io_waste_ratio_max = 0.30 # max 30% d'I/O évitables
[detection]
n_plus_one_min_occurrences = 5
slow_query_threshold_ms = 500
[green]
enabled = true
default_region = "eu-west-3" # optionnel : active la conversion en gCO2eq
embodied_carbon_per_request_gco2 = 0.001 # terme M SCI v1.0, défaut 0,001 g/req
# Surcharges optionnelles par service pour les déploiements multi-région
# (utilisées quand cloud.region OTel est absent des spans) :
# [green.service_regions]
# "order-svc" = "us-east-1"
# "chat-svc" = "ap-southeast-1"
```
Formats de sortie : `--format text` (coloré, par défaut), `--format json` (structuré), `--format sarif` (GitHub/GitLab code scanning).
### 2. Collector central (recommandé pour la production)
Un [OpenTelemetry Collector](https://opentelemetry.io/docs/collector/) reçoit les traces de tous les services et les transmet à perf-sentinel. Zéro modification de code dans vos services.
```
app-1 --\
app-2 ---+--> OTel Collector --> perf-sentinel (watch)
app-3 --/
```
Des fichiers prêts à l'emploi sont fournis dans [`examples/`](examples/) :
```bash
# Démarrer le collector + perf-sentinel
docker compose -f examples/docker-compose-collector.yml up -d
# Pointez vos apps vers le collector :
# OTEL_EXPORTER_OTLP_ENDPOINT=http://otel-collector:4317
```
perf-sentinel diffuse les findings en NDJSON sur stdout et expose des métriques Prometheus avec [Grafana Exemplars](docs/FR/INTEGRATION-FR.md) sur `/metrics` (port 4318). Un endpoint `GET /health` de liveness est exposé sur le même port pour les sondes Kubernetes ou load-balancer. Depuis 0.5.19, `/metrics` expose aussi les métriques standard du process collector (`process_resident_memory_bytes`, `process_open_fds`, ...) sur Linux et un compteur `perf_sentinel_otlp_rejected_total{reason}` pour diagnostiquer la backpressure d'ingestion. Le payload JSON du report porte un champ `warning_details` structuré (warnings côté opérateur tels que `cold_start` et `ingestion_drops`) à côté du champ legacy `warnings`. Voir [docs/FR/METRICS-FR.md](docs/FR/METRICS-FR.md) et la section "Lire les warnings du Report" de [docs/FR/RUNBOOK-FR.md](docs/FR/RUNBOOK-FR.md).
Voir [`examples/otel-collector-config.yaml`](examples/otel-collector-config.yaml) pour la config complète du collector avec les options de sampling et filtrage.
### 3. Sidecar (diagnostic par service)
perf-sentinel tourne à côté d'un service unique, partageant son namespace réseau. Utile pour du debug isolé.
```bash
docker compose -f examples/docker-compose-sidecar.yml up -d
```
L'app envoie les traces à `localhost:4317` (pas de saut réseau). Voir [`examples/docker-compose-sidecar.yml`](examples/docker-compose-sidecar.yml).
---
Pour une vue d'ensemble de bout en bout et les quatre topologies supportées, voir [docs/FR/INTEGRATION-FR.md](docs/FR/INTEGRATION-FR.md). Pour l'instrumentation OTLP par langage (Java, Quarkus, .NET, Rust), voir [docs/FR/INSTRUMENTATION-FR.md](docs/FR/INSTRUMENTATION-FR.md). Pour les recettes d'intégration CI (GitHub Actions, GitLab CI, Jenkins) et la sous-commande `diff` pour la détection de régressions sur PR, voir [docs/FR/CI-FR.md](docs/FR/CI-FR.md). Pour la référence complète de configuration, voir [docs/FR/CONFIGURATION-FR.md](docs/FR/CONFIGURATION-FR.md). Pour l'API HTTP de requêtage du daemon (findings, explain, corrélations, status), voir [docs/FR/QUERY-API-FR.md](docs/FR/QUERY-API-FR.md). Pour le workflow post-mortem quand une trace est plus ancienne que la fenêtre live du daemon, voir [docs/FR/RUNBOOK-FR.md](docs/FR/RUNBOOK-FR.md). Pour la documentation de conception détaillée, voir [docs/FR/design/](docs/FR/design/00-INDEX-FR.md).
## Normes et sources de données
Les estimations carbone de perf-sentinel reposent sur une chaîne auditable de normes publiques, de jeux de données de référence et de méthodologie revue par les pairs. La liste d'autorité des citations par référence se trouve dans [`crates/sentinel-core/src/score/carbon.rs`](crates/sentinel-core/src/score/carbon.rs) (docstring de module) et dans [`crates/sentinel-core/src/score/carbon_profiles.rs`](crates/sentinel-core/src/score/carbon_profiles.rs) (commentaires de source par région sur chaque entrée de profil). Cette section est son complément narratif.
### Norme / spécification
- [Software Carbon Intensity v1.0 (ISO/IEC 21031:2024)](https://sci-guide.greensoftware.foundation/), Green Software Foundation. `co2.total` est le numérateur SCI v1.0 `(E × I) + M + T`, pas l'intensité par R. Discussion complète dans [docs/FR/design/05-GREENOPS-AND-CARBON-FR.md](docs/FR/design/05-GREENOPS-AND-CARBON-FR.md).
### Jeux de données de référence
- [Cloud Carbon Footprint (CCF)](https://www.cloudcarbonfootprint.org/) : intensité carbone annuelle par région cloud, valeurs PUE par fournisseur (AWS 1,135, GCP 1,10, Azure 1,185, générique 1,2) et les tables de coefficients SPECpower (~180 types d'instances) qui alimentent le backend énergie `cloud_specpower`.
- [Electricity Maps](https://www.electricitymaps.com/) : intensités annuelles moyennes pour plus de 30 régions (2023-2024) utilisées comme référence `io_proxy_v1`, plus l'API temps réel (backend `electricity_maps_api`, opt-in via `[green.electricity_maps]`).
- [ENTSO-E Transparency Platform](https://transparency.entsoe.eu/) : données horaires de production et de consommation utilisées pour dériver les profils mois x heure des zones de marché européennes (FR, DE, GB, IE, NL, SE, BE, FI, IT, ES, PL, NO).
- Gestionnaires de réseau nationaux : [RTE eCO2mix](https://www.rte-france.com/en/eco2mix) (France), [Fraunhofer ISE energy-charts.info](https://www.energy-charts.info/?l=fr&c=DE) (Allemagne), [National Grid ESO Carbon Intensity API](https://carbonintensity.org.uk/) (Royaume-Uni), [EIA Open Data API](https://www.eia.gov/opendata/) pour les balancing authorities américaines (PJM, CAISO, BPA), [rapports annuels Hydro-Québec](https://www.hydroquebec.com/sustainable-development/) (Canada), [AEMO NEM](https://www.aemo.com.au/) / [OpenNEM](https://opennem.org.au/) (Australie).
- [Scaphandre](https://github.com/hubblo-org/scaphandre) : mesure de puissance par processus via RAPL Intel / AMD, scrapée depuis son endpoint Prometheus quand la section `[green.scaphandre]` est configurée.
### Méthodologie académique
- Xu et al., *Energy-Efficient Query Processing*, VLDB 2010. Benchmark énergétique par opération DBMS fondamental qui motive les multiplicateurs `SELECT 0,5x` / `INSERT 1,5x` / `UPDATE 1,5x` / `DELETE 1,2x` du modèle proxy.
- Tsirogiannis et al., *Analyzing the Energy Efficiency of a Database Server*, SIGMOD 2010. Benchmark compagnon qui établit les coefficients par verbe.
- Siddik et al., *DBJoules: Towards Understanding the Energy Consumption of Database Management Systems*, 2023. Confirme une variance inter-opérations de 7 à 38 % entre verbes, cross-validation pour la feature `per_operation_coefficients`.
- Guo et al., *Energy-efficient Database Systems: A Systematic Survey*, ACM Computing Surveys 2022. Panorama du domaine.
- IDEAS 2025 : framework d'estimation énergétique temps réel pour les requêtes SQL, référencé comme direction de travail pour les futures évolutions de `calibrate`.
- Mytton, Lunden & Malmodin, *Estimating electricity usage of data transmission networks*, Journal of Industrial Ecology 2024. Source du défaut 0,04 kWh/GB sur le terme optionnel `include_network_transport` ; la plage 0,03-0,06 kWh/GB du papier est à l'origine du champ configurable `network_energy_per_byte_kwh`.
- [API Boavizta](https://www.boavizta.org/en/) / HotCarbon 2024 : modèle bottom-up du cycle de vie carbone embodied d'un serveur, référencé pour le calibrage par défaut de `embodied_per_request_gco2`.
## Supply chain
Les entrées CI sont pinnées pour la reproductibilité : chaque GitHub Action est référencée par un commit SHA de 40 caractères (avec le tag semver en commentaire trailing), l'image de production est `FROM scratch`, `Cargo.lock` est commité et audité quotidiennement par `cargo audit`, et les permissions `GITHUB_TOKEN` des workflows ont par défaut `contents: read` avec des scopes plus larges opt-in par job. Dependabot ouvre des PRs groupées hebdomadaires pour les bumps d'actions. La politique complète et les commandes de vérification sont dans [docs/FR/SUPPLY-CHAIN-FR.md](docs/FR/SUPPLY-CHAIN-FR.md).
## Licence
Ce projet est sous licence [GNU Affero General Public License v3.0](LICENSE).