Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/roboflow/multimodal-maestro
Effective prompting for Large Multimodal Models like GPT-4 Vision, LLaVA or CogVLM. 🔥
https://github.com/roboflow/multimodal-maestro
cross-modal gpt-4 gpt-4-vision instance-segmentation llava lmm multimodality object-detection prompt-engineering segment-anything vision-language-model visual-prompting
Last synced: about 2 months ago
JSON representation
Effective prompting for Large Multimodal Models like GPT-4 Vision, LLaVA or CogVLM. 🔥
- Host: GitHub
- URL: https://github.com/roboflow/multimodal-maestro
- Owner: roboflow
- License: mit
- Created: 2023-11-24T13:28:57.000Z (10 months ago)
- Default Branch: develop
- Last Pushed: 2024-02-13T17:59:33.000Z (7 months ago)
- Last Synced: 2024-07-08T17:22:37.081Z (2 months ago)
- Topics: cross-modal, gpt-4, gpt-4-vision, instance-segmentation, llava, lmm, multimodality, object-detection, prompt-engineering, segment-anything, vision-language-model, visual-prompting
- Language: Python
- Homepage: https://maestro.roboflow.com
- Size: 5.12 MB
- Stars: 994
- Watchers: 14
- Forks: 71
- Open Issues: 9
-
Metadata Files:
- Readme: README.md
- Contributing: CONTRIBUTING.md
- License: LICENSE
- Citation: CITATION.cff
Awesome Lists containing this project
- awesome-ChatGPT-repositories - multimodal-maestro - Effective prompting for Large Multimodal Models like GPT-4 Vision, LLaVA or CogVLM. 🔥 (Prompts)
README
multimodal-maestro
[](https://badge.fury.io/py/maestro)
[](https://github.com/roboflow/multimodal-maestro/blob/main/LICENSE)
[](https://badge.fury.io/py/maestro)
[](https://huggingface.co/spaces/Roboflow/SoM)
[](https://colab.research.google.com/github/roboflow/multimodal-maestro/blob/develop/cookbooks/multimodal_maestro_gpt_4_vision.ipynb)
## 👋 hello
Multimodal-Maestro gives you more control over large multimodal models to get the
outputs you want. With more effective prompting tactics, you can get multimodal models
to do tasks you didn't know (or think!) were possible. Curious how it works? Try our
[HF space](https://huggingface.co/spaces/Roboflow/SoM)!
## 💻 install
⚠️ Our package has been renamed to `maestro`. Install the package in a
[**3.11>=Python>=3.8**](https://www.python.org/) environment.
```bash
pip install maestro
```
## 🔌 API
🚧 The project is still under construction. The redesigned API is coming soon.
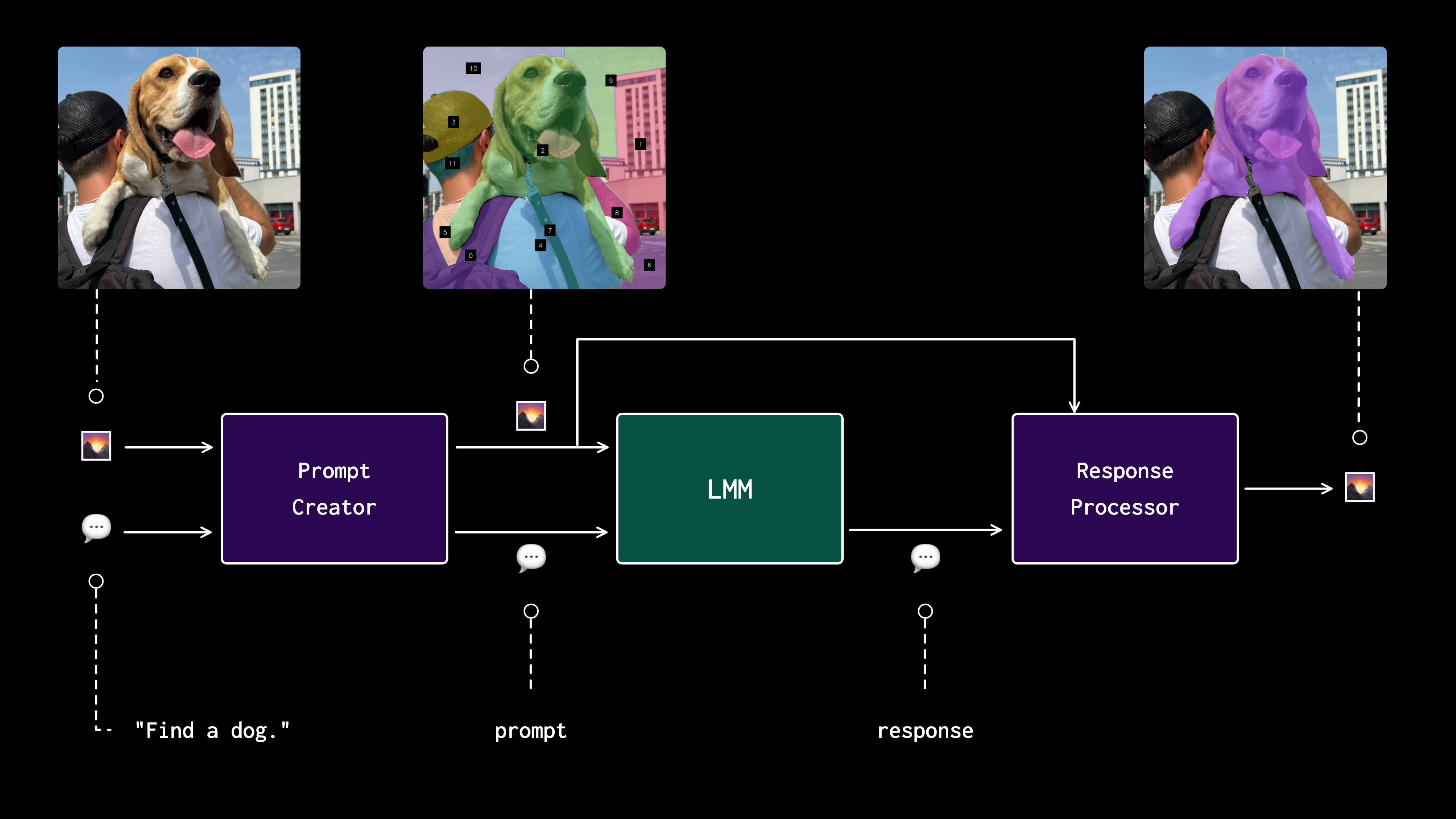
## 🧑🍳 prompting cookbooks
| Description | Colab |
|:----------------------------------------------------------------|:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------:|
| Prompt LMMs with Multimodal Maestro | [](https://colab.research.google.com/github/roboflow/multimodal-maestro/blob/develop/cookbooks/multimodal_maestro_gpt_4_vision.ipynb) |
| Manually annotate ONE image and let GPT-4V annotate ALL of them | [](https://colab.research.google.com/github/roboflow/multimodal-maestro/blob/develop/cookbooks/grounding_dino_and_gpt4_vision.ipynb) |
## 🚀 example
```
Find dog.
>>> The dog is prominently featured in the center of the image with the label [9].
```
👉 read more
- **load image**
```python
import cv2
image = cv2.imread("...")
```
- **create and refine marks**
```python
import maestro
generator = maestro.SegmentAnythingMarkGenerator(device='cuda')
marks = generator.generate(image=image)
marks = maestro.refine_marks(marks=marks)
```
- **visualize marks**
```python
mark_visualizer = maestro.MarkVisualizer()
marked_image = mark_visualizer.visualize(image=image, marks=marks)
```

- **prompt**
```python
prompt = "Find dog."
response = maestro.prompt_image(api_key=api_key, image=marked_image, prompt=prompt)
```
```
>>> "The dog is prominently featured in the center of the image with the label [9]."
```
- **extract related marks**
```python
masks = maestro.extract_relevant_masks(text=response, detections=refined_marks)
```
```
>>> {'6': array([
... [False, False, False, ..., False, False, False],
... [False, False, False, ..., False, False, False],
... [False, False, False, ..., False, False, False],
... ...,
... [ True, True, True, ..., False, False, False],
... [ True, True, True, ..., False, False, False],
... [ True, True, True, ..., False, False, False]])
... }
```

## 🚧 roadmap
- [ ] Rewriting the `maestro` API.
- [ ] Update [HF space](https://huggingface.co/spaces/Roboflow/SoM).
- [ ] Documentation page.
- [ ] Add GroundingDINO prompting strategy.
- [ ] CovVLM demo.
- [ ] Qwen-VL demo.
## 💜 acknowledgement
- [Set-of-Mark Prompting Unleashes Extraordinary Visual Grounding
in GPT-4V](https://arxiv.org/abs/2310.11441) by Jianwei Yang, Hao Zhang, Feng Li, Xueyan
Zou, Chunyuan Li, Jianfeng Gao.
- [The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision)](https://arxiv.org/abs/2309.17421)
by Zhengyuan Yang, Linjie Li, Kevin Lin, Jianfeng Wang, Chung-Ching Lin, Zicheng Liu,
Lijuan Wang
## 🦸 contribution
We would love your help in making this repository even better! If you noticed any bug,
or if you have any suggestions for improvement, feel free to open an
[issue](https://github.com/roboflow/multimodal-maestro/issues) or submit a
[pull request](https://github.com/roboflow/multimodal-maestro/pulls).