https://github.com/roedoejet/convertextract
Extract and find/replace text based on arbitrary correspondences while preserving original file formatting. This library is a fork from the Textract library by Dean Malmgren.
https://github.com/roedoejet/convertextract
Last synced: 5 months ago
JSON representation
Extract and find/replace text based on arbitrary correspondences while preserving original file formatting. This library is a fork from the Textract library by Dean Malmgren.
- Host: GitHub
- URL: https://github.com/roedoejet/convertextract
- Owner: roedoejet
- License: mit
- Created: 2016-10-14T19:43:37.000Z (over 9 years ago)
- Default Branch: master
- Last Pushed: 2023-09-08T22:23:02.000Z (almost 3 years ago)
- Last Synced: 2025-11-22T20:16:08.910Z (7 months ago)
- Language: HTML
- Homepage:
- Size: 58.3 MB
- Stars: 11
- Watchers: 1
- Forks: 3
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- Changelog: changelog.md
- License: LICENSE
Awesome Lists containing this project
- low-resource-languages - convertextract - Convert Excel, Word and PowerPoint files with non-Unicode text (like text requiring SIL fonts) into Unicode, while preserving original file's formatting. (Software / Utilities)
README
# convertextract
========
[](https://travis-ci.org/roedoejet/textract)
[](https://warehouse.python.org/project/convertextract/)
[](https://coveralls.io/github/roedoejet/textract?branch=master)
Extract and find/replace text based on arbitrary correspondences. This library is a fork from the Textract library by Dean Malmgren. https://github.com/deanmalmgren/textract
# Documentation
## Installation
To install, you must have Python 3.4+ and pip installed.
```{r, engine='python', count_lines}
pip install convertextract
```
Some source libraries need to be installed for different operating systems to support various file formats. Visit for documentation.
=========
## Basic CLI Use
Some basic Textract functions are preserved. Please visit for documentation.
#### Converting a file based on pre-existing Mappings in the G2P library
Under the hood, convertextract uses the [g2p](https://github.com/roedoejet/g2p) library to do conversions. There are many mappings available through that library. For a list of all possible mappings, please visit .
For this type of call, convertextract requires three arguments:
1. A file containing text to convert (as of Version 1.0.4, this includes **.pptx**, **.docx**, **.xlsx**, and **.txt**)
2. A code corresponding to the input language of the text.
3. A code corresponding to the desired output language of the text.
Running the command:
```{r, engine='python', count_lines}
convertextract path/to/foo.docx -il eng-ipa -ol eng-arpabet
```
Will produce a new file `path/to/foo_converted.docx` which will contain the same content as `path/to/foo.docx` but with find/replace performed for all correspondences listed in the mapping between English IPA (eng-ipa) and English Arpabet (eng-arpabet).
#### Converting a file based on custom mapping
If the mapping you want is not supported by g2p, you should make a pull request there to have it included! Otherwise, you can use a custom file.
Running the command:
```{r, engine='python', count_lines}
convertextract path/to/foo.docx -m path/to/rules.csv
```
Will produce a new file `path/to/foo_converted.docx` which will contain the same content as `path/to/foo.docx` but with find/replace performed for all correspondences listed in the mapping at `path/to/rules.csv`.
#### Creating an .xlsx/.csv/.psv/.tsv correspondence sheet
Your correspondence sheet must be set up as follows:
| in | out |
|:-:|:-:|
| aa| å|
| oe| ø|
| ae| æ|
Here, this correspondence sheet (do not include headers like "replace with" or "find") would replace all instances of aa, oe, or ae in a given file with å, ø, or æ respectively.
#### Supported conversions
As of Version 3.0, any mappings that are valid in the g2p library are supported. Here are a few:
* Heiltsuk Doulos Font -> Unicode
```{r, engine='python', count_lines}
convertextract path/to/foo.docx -il hei -ol hei-doulos
```
* Heiltsuk Times Font -> Unicode
```{r, engine='python', count_lines}
convertextract path/to/foo.docx -il hei -ol hei-times
```
* Tsilhqot'in Doulos Font -> Unicode
```{r, engine='python', count_lines}
convertextract path/to/foo.docx -il clc -ol clc-doulos
```
* Navajo Times Font -> Unicode
```{r, engine='python', count_lines}
convertextract path/to/foo.docx -il nav -ol nav-times
```
#### Using Regular Expressions
As of Version 1.5, there is support for Regular Expressions. If you do not need to use context-sensitive conversions, you do not need to include them. However, if you do, you should set up your correspondence sheet as follows:
| in | out | context_before | context_after |
|:-:|:-:|:-:|:-:|
| aa| å|[k,d]|$|
| aa| æ|t|$|
| aa| a:|||
For more information on how the g2p is acutally processed, please visit .
#### Use as Python package
You can use the package in a Python script, which returns converted text, but without formatting. Running the script will still create a `foo_converted.docx` file.
```python
import convertextract
text = convertextract.process('foo.docx', mapping='bar.xlsx')
```
You can also use convertextract to just convert text in Python using `process_text`.
```python
import convertextract
text = convertextract.process_text('test', mapping=[{'in': 't', 'out': 'p', 'context_before': '^', 'context_after': 'e'}])
```
## Use with GUI (Graphical User Interface)
Convertextract can also run in a GUI (for Mac 10.14.6 or higher **only**)
### Installing the GUI
To download the app, go to [https://github.com/roedoejet/convertextract/releases](https://github.com/roedoejet/convertextract/releases) and select the most recent version.
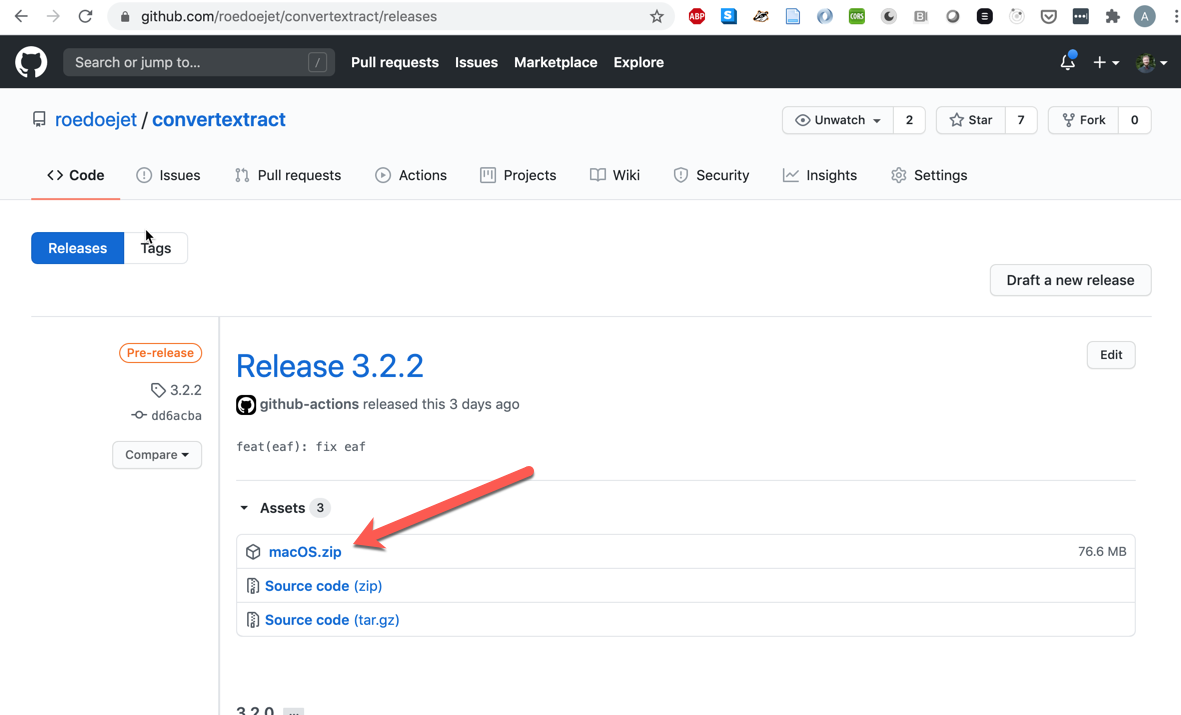
Click to unzip the file, and then *right-click* and select `open`. You must *right-click* or the Mac permissions will not allow you to open the app.

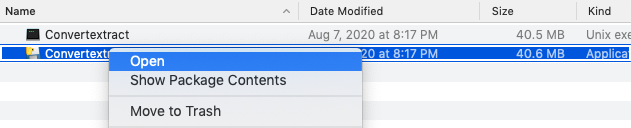
### Using the GUI
The Convertextract app has four arguments:
1. A file containing text to convert (As of version 3.2.2 **.csv**,
**.psv**, **.tsv**, **.doc**, **.docx**, **.txt**, **.eaf**, **.json**, **.pptx**, **.html**, **.xls**, **.xlsx** are supported).
2. A code that specifies the desired encoding, for example `UTF-8`.
3. A code corresponding to the input language of the text.
4. A code corresponding to the desired output language of the text.
There is also the option for custom g2p lookup tables if your mapping is not already in the [g2p](https://github.com/roedoejet/g2p) library.
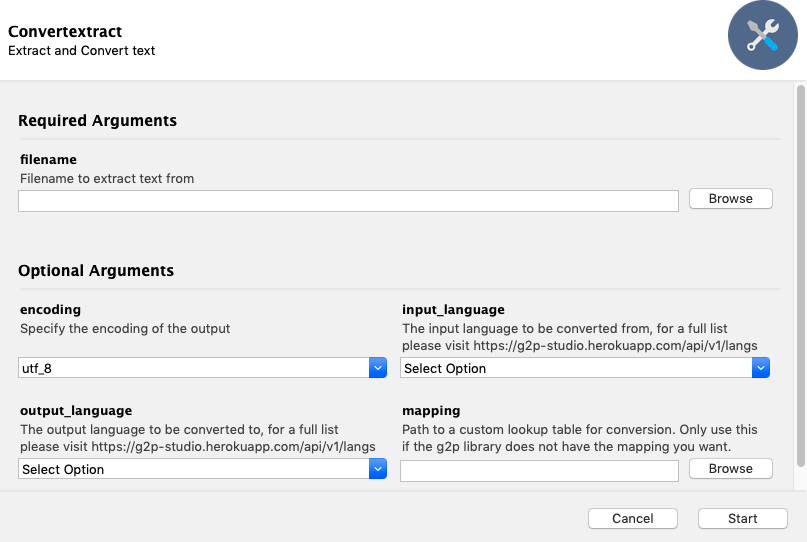
The GUI will produce a new file `path/to/foo_converted.docx` which will contain the same content as `path/to/foo.docx` but with find/replace performed for all correspondences listed in the mapping. The file format will remain the same as the input file.
# Citation
If you use convertextract in published work, please cite it. To cite this work, please use the following (APA):
Pine, A., & Turin, M. (2018). Seeing the Heiltsuk orthography from font encoding through to Unicode: A case study using convertextract. In Proceedings of the LREC 2018 Workshop “CCURL 2018–Sustaining knowledge diversity in the digital age” (pp. 27-30). European Language Resources Association.
or BibTex:
```
@inproceedings{pine2018convertextract,
title={{Seeing the Heiltsuk orthography from font encoding through to Unicode: A case study using convertextract}},
author={Pine, Aidan and Turin, Mark},
booktitle={{Proceedings of the LREC 2018 Workshop “CCURL 2018--Sustaining knowledge diversity in the digital age”}},
pages={27--30},
year={2018},
organization={{European Language Resources Association}}
}
```