https://github.com/rohra-mehak/sciencesync
System for Personalized Google Scholar Alerts Processing and Data Management, and provision of ML based clustering analysis
https://github.com/rohra-mehak/sciencesync
agglomerative-clustering clustering crossref-api customtkinter google-api google-scholar graph-api machine-learning numpy pandas python3 scientific-article-analysis scikit-learn sqlite3
Last synced: 2 months ago
JSON representation
System for Personalized Google Scholar Alerts Processing and Data Management, and provision of ML based clustering analysis
- Host: GitHub
- URL: https://github.com/rohra-mehak/sciencesync
- Owner: rohra-mehak
- Created: 2024-05-25T11:04:29.000Z (about 2 years ago)
- Default Branch: master
- Last Pushed: 2024-06-19T17:48:40.000Z (about 2 years ago)
- Last Synced: 2025-06-21T12:37:27.508Z (about 1 year ago)
- Topics: agglomerative-clustering, clustering, crossref-api, customtkinter, google-api, google-scholar, graph-api, machine-learning, numpy, pandas, python3, scientific-article-analysis, scikit-learn, sqlite3
- Language: Python
- Homepage:
- Size: 9.85 MB
- Stars: 0
- Watchers: 2
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Science Sync
This system is designed to enhance the data management, access and analysis of Google Scholar Alerts sent to emails by integrating several automated processes.
The core functionalities are described below.
## Overview
#### Email Integration:
Gmail and Outlook Connectivity: The system connects to your Gmail or Outlook accounts to retrieve Google Scholar alerts.
#### Alert Retrieval and Parsing
Google Scholar alerts are automatically fetched and parsed using Beautiful Soup and regular expressions: regex to extract relevant information such as titles, authors, publication dates, and links.
#### Data Storage:
The parsed information is stored in an in-memory database using `Sqlite3` for easy access and further processing.
#### Machine Learning-Based Analysis:
#### Clustering:
The system employs clustering algorithms (such as KMeans, KMedoids, and Agglomerative Clustering) to group similar articles.
#### Similarity Metrics:
Jaccard similarity / Euclidean can be used to measure the similarity between different articles based on their references.
#### Interfaces:
Interfaces built using `customtkinter` facilitate communication with the system.
Results Display: The system provides intuitive visualization tools to display clustering results and other analytical insights.
## Pre-Requisites
1. Python 3.10 or higher versions
Official website for download: https://www.python.org/doc/
2. pip (for instaling all related dependencies)
pip installation guide: https://pip.pypa.io/en/stable/installation/
3. your preferred IDE: Visual Studio Code or others.
VS Code download page: https://code.visualstudio.com/Download
(recommended) Python extension in VS Code Market place: https://code.visualstudio.com/docs/editor/extension-marketplace
## How To Run
1. ### a. Clone the repository: ([git](https://git-scm.com/downloads) is required)
```bash
git clone https://github.com/rohra-mehak/ScienceSync.git
```
```bash
cd ScienceSync
```
### b. Alternatively Download the code:
Navigate to: https://github.com/rohra-mehak/ScienceSync
Click the `Code` button.
Select `Download ZIP`.
Extract the ZIP file to your desired location.
2. ### Navigate to the root folder directory:
```bash
cd yourpath/to/ScienceSync
```
On Linux , macOS or Windows
Use the `mkdir` command followed by the name of the directory in the terminal of your IDE.
```bash
mkdir secrets
```
```bash
mkdir database
```
3. ### Configure a virtual environment
In your IDE, make sure you are in the `ScienceSync` directory.
go to the terminal window and run the following commands
Example for VS Code:
Create a virtual env directory called `venv` in the root `ScienceSync` directory
```bash
1. python -m venv venv
```
This Execution Policy command is used in the context of a Windows PowerShell and is not applicable for other OS.
```bash
Set-ExecutionPolicy Unrestricted -Scope Process
```
Activate the Environment
Windows
```bash
2. .\venv\Scripts\activate
```
MacOS / Linux
```bash
2. source venv/bin/activate
```
Once it is activated, you may see the `(venv)` prefix to your command line path.
4. ### Install all dependencies
run the following command and wait for all dependencies to finish
installing.
```bash
pip install -r requirements.txt
```
5. ### Configure the IDE to use the Virtual Environment
To ensure your IDE uses the correct Python interpreter from your virtual environment, you generally need to configure the IDE to recognize and use the virtual environment.
Here’s a generalized approach for VS code
### Visual Studio Code (VS Code)
1. *Open Command Palette:*
- Press Cmd+Shift+P (macOS) or Ctrl+Shift+P (Windows/Linux) to open the command palette.
2. *Select Interpreter:*
- Type Python: Select Interpreter -> Enter Interpreter Path -> Find Interpreter.
3. *Choose Virtual Environment:*
- Select the interpreter located in your virtual environment `(venv)` directory. It will typically look like `./venv/bin/python` or `.\venv\Scripts\python.exe` on Windows.
6. ### Configuring Credentials (GoogleAPI or GraphAPI)
To access your email account, you'll need to obtain your own client ID and client secret tokens. Depending on your email service (Outlook or Gmail), follow the appropriate steps below:
#### a. Accessing Outlook (using MS Graph)
1. **Register Your Application:**
Follow the process outlined in the Microsoft documentation to register your application and obtain the necessary tokens: [Register an app](https://learn.microsoft.com/en-us/entra/identity-platform/quickstart-register-app)). with Mail.Read , Mail.ReadWrite, User.Read API Permissions.
2. **Save Credentials:**
Once you have your application ID and client secret, save them in a file named `credentials_msgraph.json` in the `ScienceSync/secrets` directory. The file should have the following format:
```json
{
"application_id": "your_app_id",
"client_secret": "your_client_secret"
}
```
#### b. Accessing Gmail (using Google API)
1. **Set Up Your Environment:**
Follow the steps mentioned in the Google documentation (Set up your Environment Section only) to register your application and obtain the necessary tokens: [Set up your environment](https://developers.google.com/gmail/api/quickstart/python#set_up_your_environment).
2. **Download and Save Credentials:**
After registering, download the JSON file containing your credentials. Save this file as `credentials.json` in the `ScienceSync/secrets` directory.
Additional resources and information on working with Google APIs can be found here: [Getting started with Google APIs](https://developers.google.com/workspace/guides/get-started#5_steps_to_get_started).
---
By following the above instructions, you will successfully configure your credentials for accessing your email account using either MS Graph or Google API.
7. Navigate to `ScienceSync/app.py`
there are various parameters that can be set before running the program.
However it is recommended to leave the default values as they are.
* `days_ago` (no of days to look back while going through the mailbox)
* `table_name` (the name of the table in your article database which will be created and referred by the system)
* `n_clusters` (number of groups [for clustering articles together] to divide the articles into)
* `method` (the clustering methodology -> KMedoids / KMedoids++ / Agglomerative (average linkage) / Agglomerative (complete linkage))
* `metric` (the similarity metric to use -> dice / jaccard / sokal and sneath)
8. ### Running the main file
**After making sure all steps are successfully completed and all dependencies have been installed,
Make sure you are in the root Science sync directory.
To start the program, run the following command on your terminal**
```bash
python app.py
```
## Sample Snapshots
Arrows are simply illustrative indicators.
### Initial Screen
Depending on the service chosen and whether credentials could be located by the program, this part might be different.

### Redirection to Authorisation

The authorisation continues on your browser and this will depend on the service you chose.
The initial screen keeps updating the user about progress of the system and errors encountered if any.
Logs can be used to identify any problem encountered. They provide the exact line, method and file where some exception or error occured.
Wait for the process to finish executing and for the results interface to load.
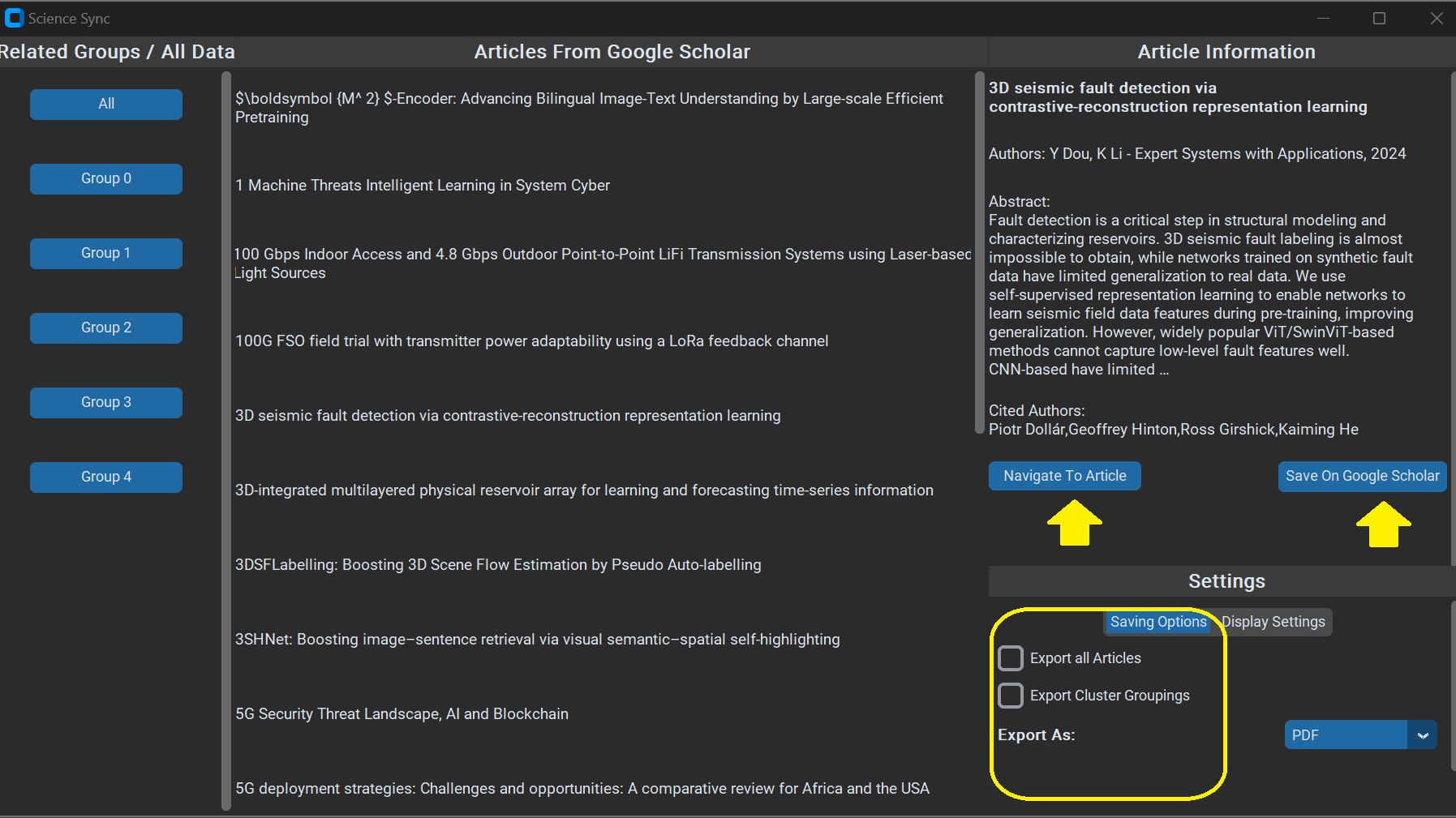
### After finishing up the process -> Click on All Data to view an itemised list of all extracted articles

### Viewing the scrollable itemised list of articles. Click on a single article to view more information

### Article Information on the Right Hand Tab. This includes additional functionalities to Navigate to Article, Save on Google Scholar.
### Additional Export Options below and also Display settings for UI scaling and Themes
### Similarly One can go on to see the article groups and view related articles.