https://github.com/ryujaehun/alexnet
custom implementation alexnet with tensorflow
https://github.com/ryujaehun/alexnet
alexnet cnn convolutional-neural-networks imagenet tensorflow
Last synced: 4 months ago
JSON representation
custom implementation alexnet with tensorflow
- Host: GitHub
- URL: https://github.com/ryujaehun/alexnet
- Owner: ryujaehun
- License: mit
- Created: 2017-10-12T12:37:43.000Z (almost 9 years ago)
- Default Branch: master
- Last Pushed: 2017-10-17T16:18:40.000Z (over 8 years ago)
- Last Synced: 2025-06-07T00:36:48.901Z (about 1 year ago)
- Topics: alexnet, cnn, convolutional-neural-networks, imagenet, tensorflow
- Language: Python
- Size: 1.8 MB
- Stars: 20
- Watchers: 1
- Forks: 8
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# alexnet
___
## about
>AlexNet is the name of a [convolutional neural](https://en.wikipedia.org/wiki/Convolutional_neural_network) network, originally written with [CUDA](https://en.wikipedia.org/wiki/CUDA) to run with [GPU](https://en.wikipedia.org/wiki/GPU) support, which competed in the [ImageNet Large Scale Visual Recognition Challenge](https://en.wikipedia.org/wiki/ImageNet_Large_Scale_Visual_Recognition_Challenge) in 2012. The network achieved a top-5 error of 15.3%, more than 10.8 percentage points ahead of the runner up. AlexNet was designed by the SuperVision group, consisting of Alex Krizhevsky, Geoffrey Hinton, and Ilya Sutskever. -wikipedia
## architecture
The neural network, which has 60 million parameters and 650,000 neurons, consists
of five convolutional layers, some of which are followed by max-pooling layers,
and three fully-connected layers with a final 1000-way softmax. To make training
faster, we used non-saturating neurons and a very efficient GPU implementation
of the convolution operation. To reduce overfitting in the fully-connected
layers we employed a recently-developed regularization method called “dropout”
that proved to be very effective.
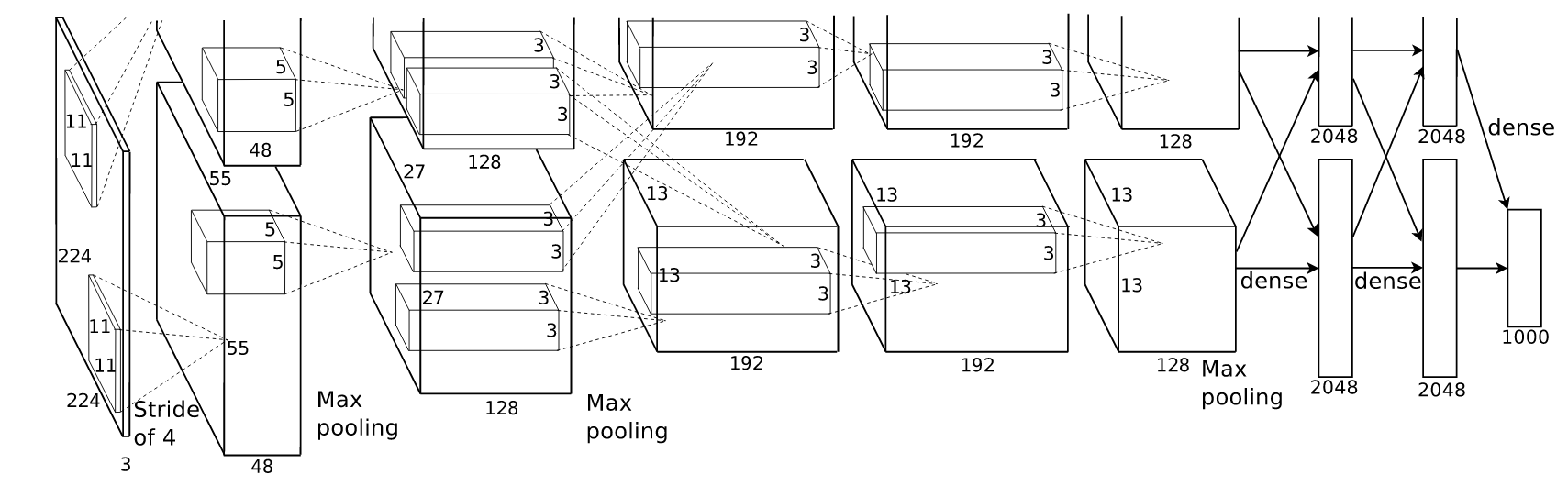
## batch normaliztion
[batch normaliztion](https://arxiv.org/abs/1502.03167)is decreasing technical skill,Gradient Vanishing & Gradient Exploding

### k=2,n=5,α=10−4,β=0.75k=2,n=5,α=10−4,β=0.75


## optimizer
Apply AdamOptimizer



## requirement
* tensorflow-gpu (ver.1.3.1)
* cv2 (ver.3.3.0)
* numpy (ver 1.13.3)
* scipy (ver 0.19.1)
## Usage
1. Download the image file from the link below.(LSVRC2012 train,val,test,Development kit (Task 1))
1. untar.(There is a script in `etc`)
1. Modify `IMAGENET_PATH` in train.py hyperparameter(maybe you need).
## train
___
#### From the beginning
```
python3 train.py
```
#### resume training
```
python3 train.py -resume
```
## test
```
python3 test.py
```
## Classify
```
python classify.py image
```
## tensorboard
```
tensorboard --logdir path/to/summary/train/
```

## TODO
* ~~apply another optimizer ~~
* ~~apply tensorboard ~~
* ~~Fit to a GPU~~
* ~~Application of the technique to the paper~~
* Eliminate bottlenecks
## file_architecture
```
ILSVRC 2012 training set folder should be srtuctured like this:
ILSVRC2012_img_train
|_n01440764
|_n01443537
|_n01484850
|_n01491361
|_ ...
```
#### you must untar training file `untar.sh`
## download
[download LSVRC 2012 image data file](http://www.image-net.org/challenges/LSVRC/2012/nonpub-downloads)
## Remove log
If you do not want to see the log at startup
train.py line 97, remove `allow_soft_placement=True, log_device_placement=True`
## references
[optimizer](http://ruder.io/optimizing-gradient-descent/)
[AlexNet training on ImageNet LSVRC 2012](https://github.com/dontfollowmeimcrazy/imagenet)
[Tensorflow Models](https://github.com/tensorflow/models)
[Tensorflow API](https://www.tensorflow.org/versions/r1.2/api_docs/)
## Licence
[MIT Licence](LICENSE)