https://github.com/saforem2/llm-tutorial
Simple tutorial on creating Small(-ish) LLMs
https://github.com/saforem2/llm-tutorial
llm quarto reveal-js
Last synced: 5 months ago
JSON representation
Simple tutorial on creating Small(-ish) LLMs
- Host: GitHub
- URL: https://github.com/saforem2/llm-tutorial
- Owner: saforem2
- Created: 2023-11-23T15:05:29.000Z (over 2 years ago)
- Default Branch: main
- Last Pushed: 2024-09-10T14:51:55.000Z (almost 2 years ago)
- Last Synced: 2025-03-18T22:57:49.645Z (about 1 year ago)
- Topics: llm, quarto, reveal-js
- Language: TeX
- Homepage: https://saforem2.github.io/LLM-tutorial/
- Size: 17 MB
- Stars: 1
- Watchers: 1
- Forks: 1
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
# Creating Small(-ish) LLMs
Sam Foreman
2023-11-30
# Creating Small(-ish) LLMs[^1]
LLM Tutorial /
Workshop
Argonne National Laboratory
Building 240, Room 1501
Sam
Foreman
2023-11-30
brettin/llm_tutorial
-
saforem2/
-
nanoGPT
(GitHub)
-
LLM-tutorial (slides)
# Emergent Abilities

[Emergent abilities of Large Language
Models](https://arxiv.org/abs/2206.07682) Yao et al. (2023)
# Training LLMs

Figure 1: Visualization from Yang et al. (2023)

# Life-Cycle of the LLM
Data collection + preprocessing
-
Pre-training
- Architecture decisions:
{model_size, hyperparameters,
parallelism, lr_schedule, ...}
-
Supervised Fine-Tuning
- Instruction Tuning
- Alignment
Deploy (+ monitor, re-evaluate, etc.)
Figure from The
Illustrated Transformer↩︎
# Forward Pass
Figure 3: Language Model trained for causal language modeling. Video
from: [🤗 Generation with
LLMs](https://huggingface.co/docs/transformers/main/en/llm_tutorial)
# Generating Text
Figure 4: Language Model trained for causal language modeling. Video
from: [🤗 Generation with
LLMs](https://huggingface.co/docs/transformers/main/en/llm_tutorial)
# Life-Cycle of the LLM: Pre-training
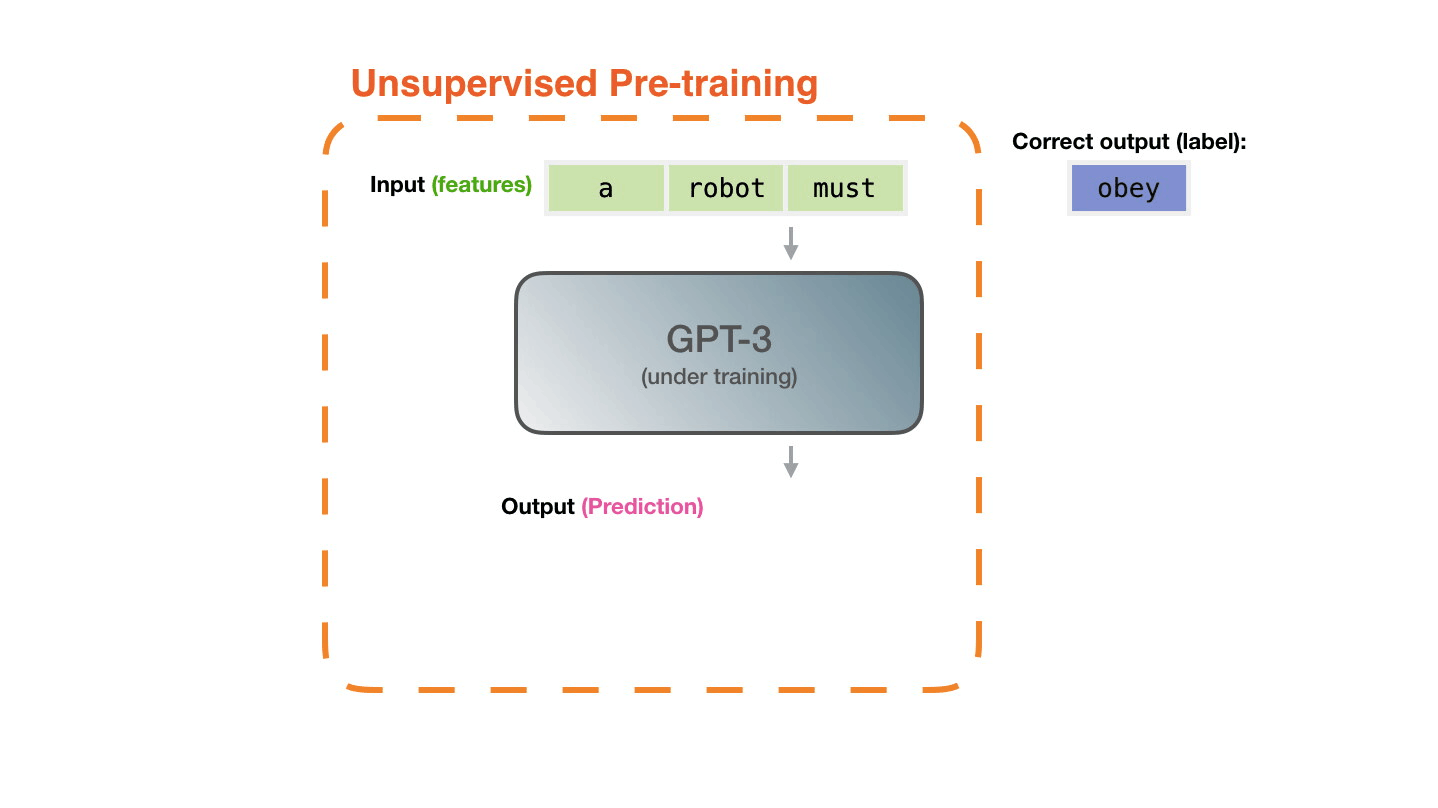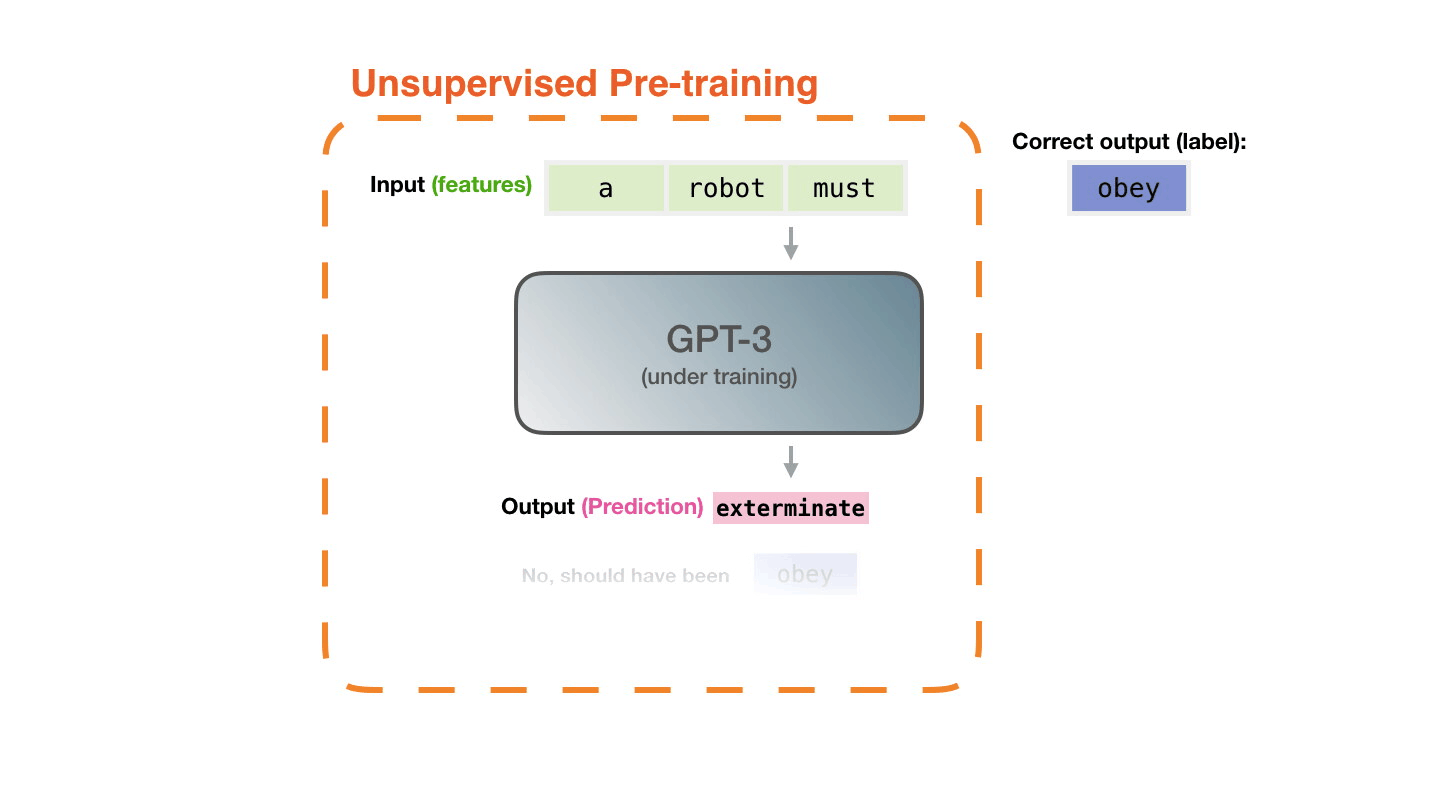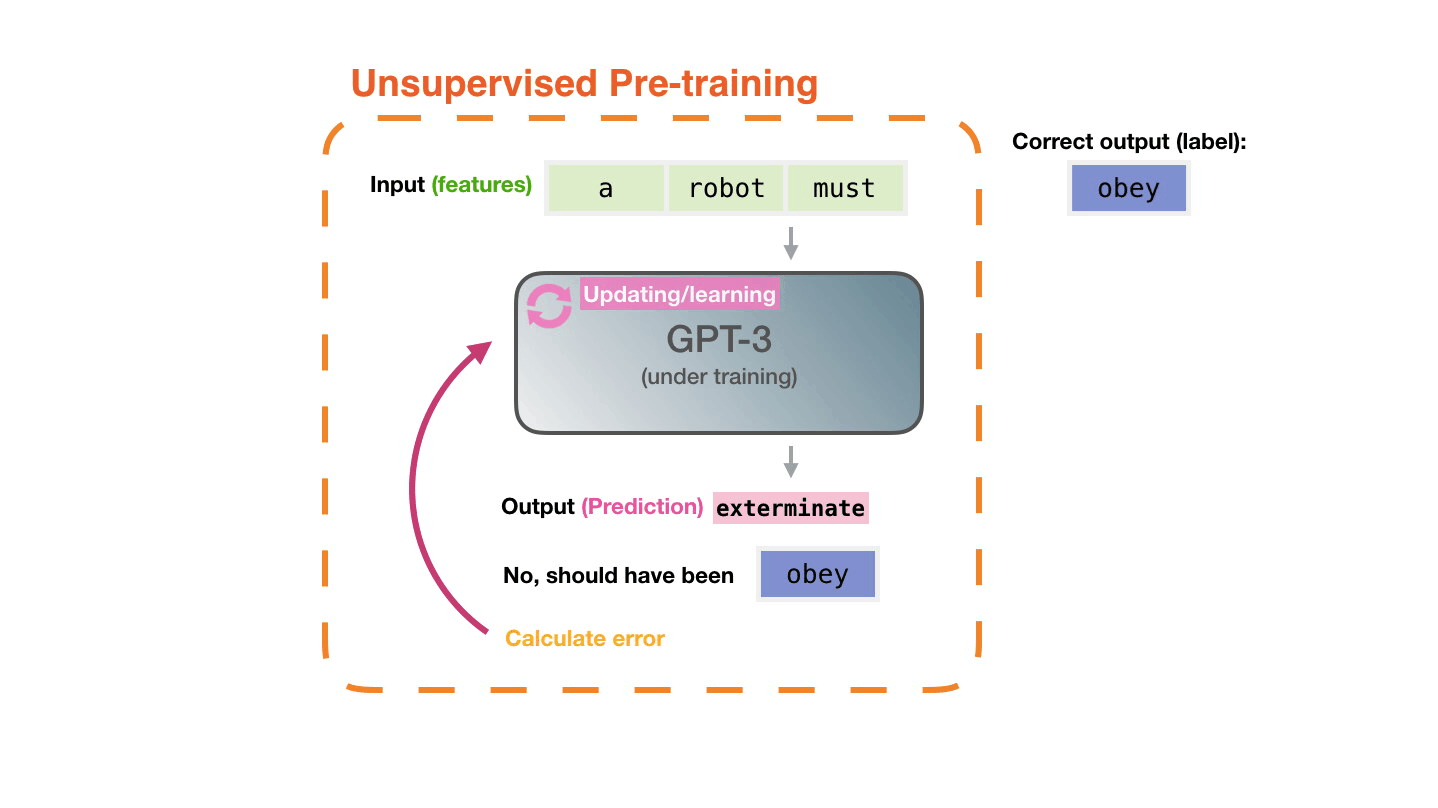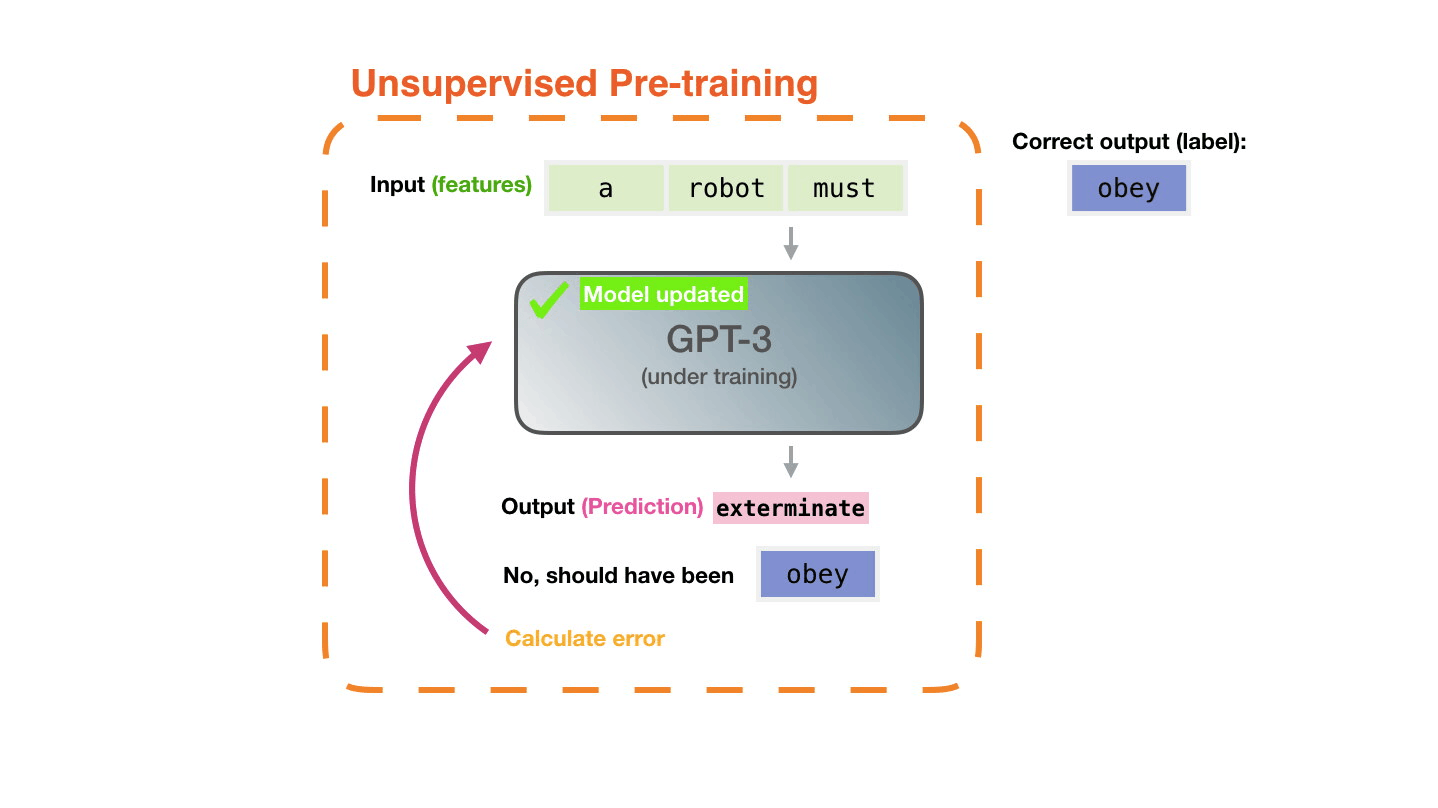
Figure 5: **Pre-training**: Virtually all of the compute used during
pretraining phase
# Life-Cycle of the LLM: Fine-Tuning
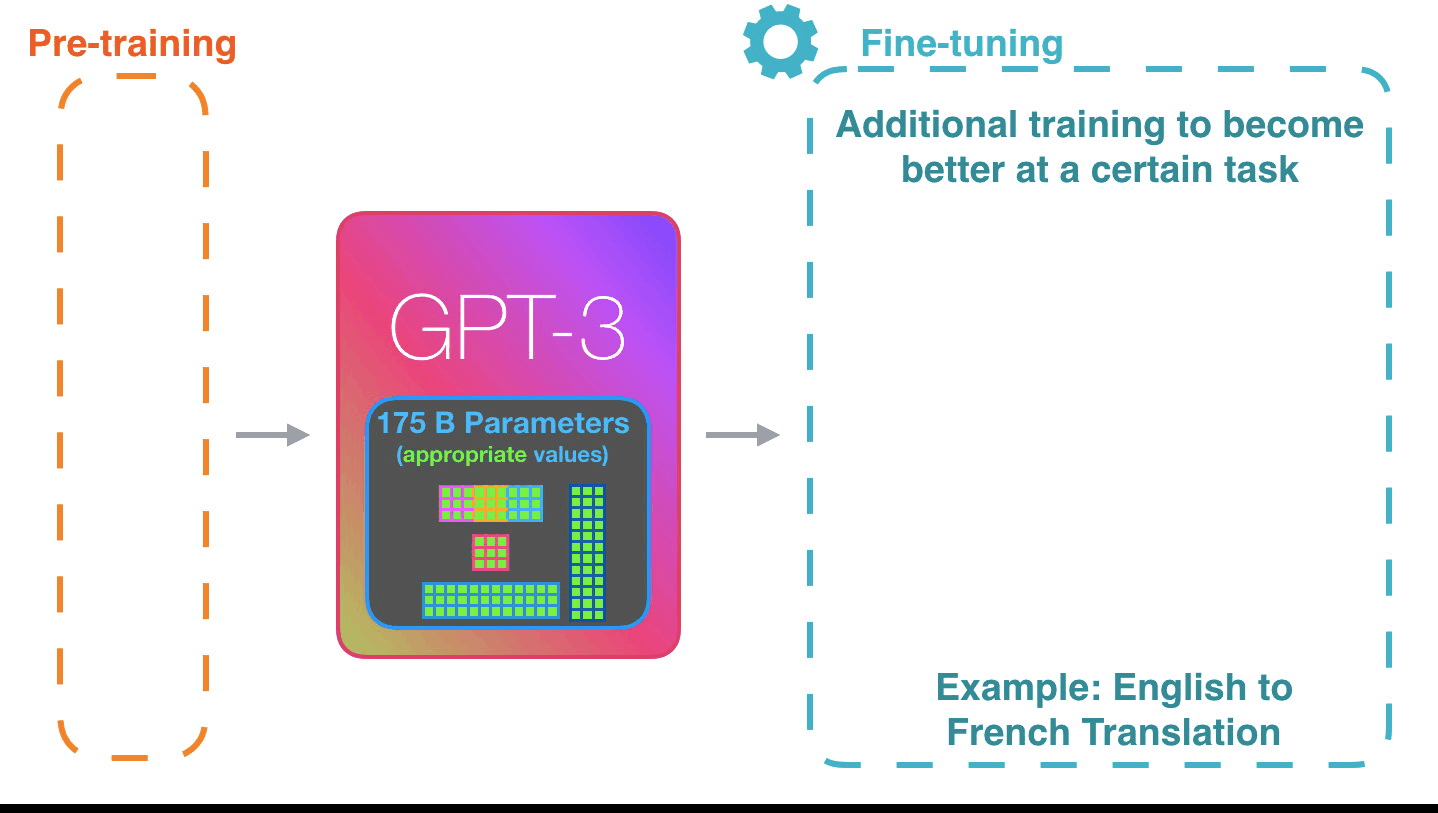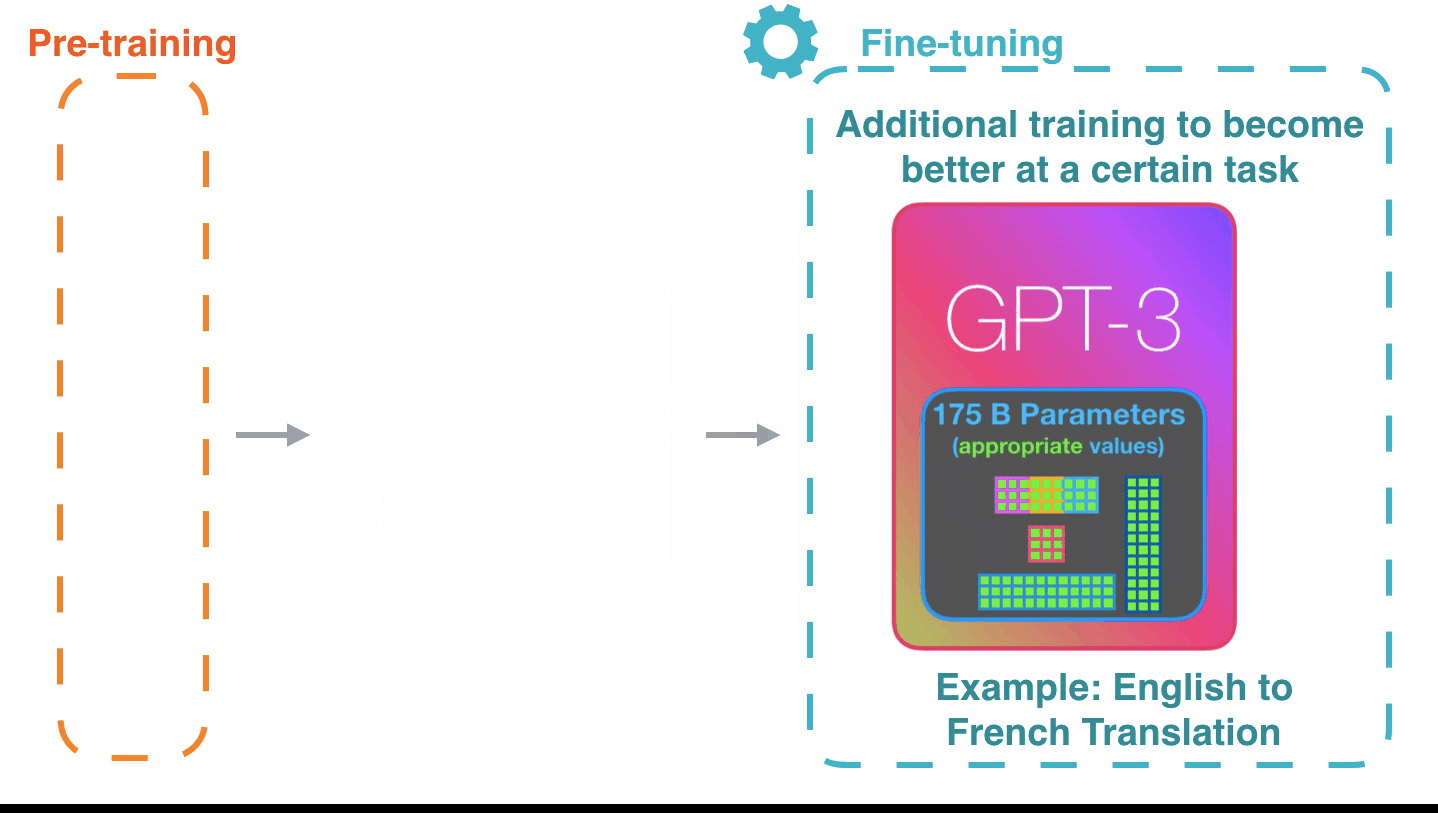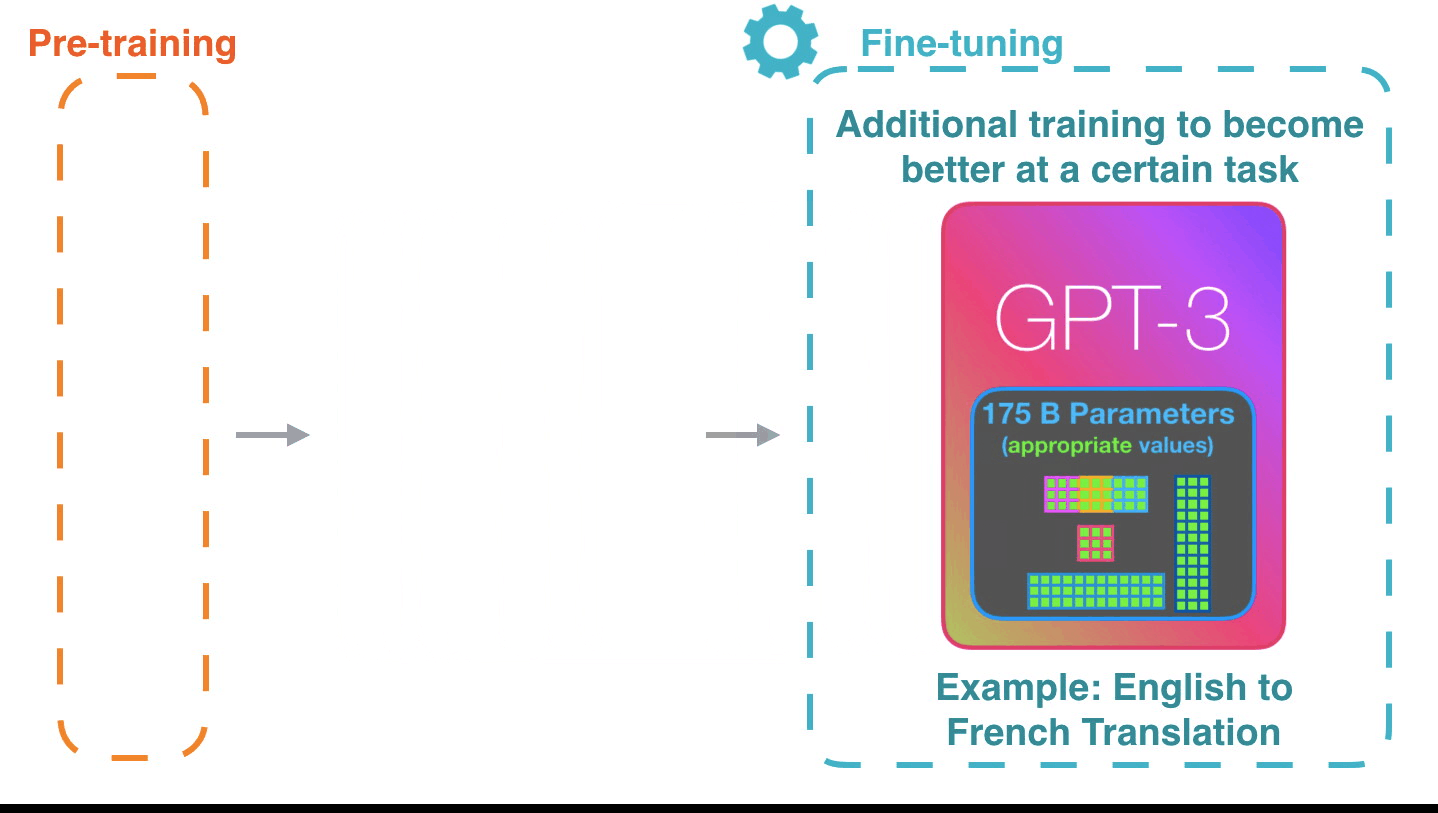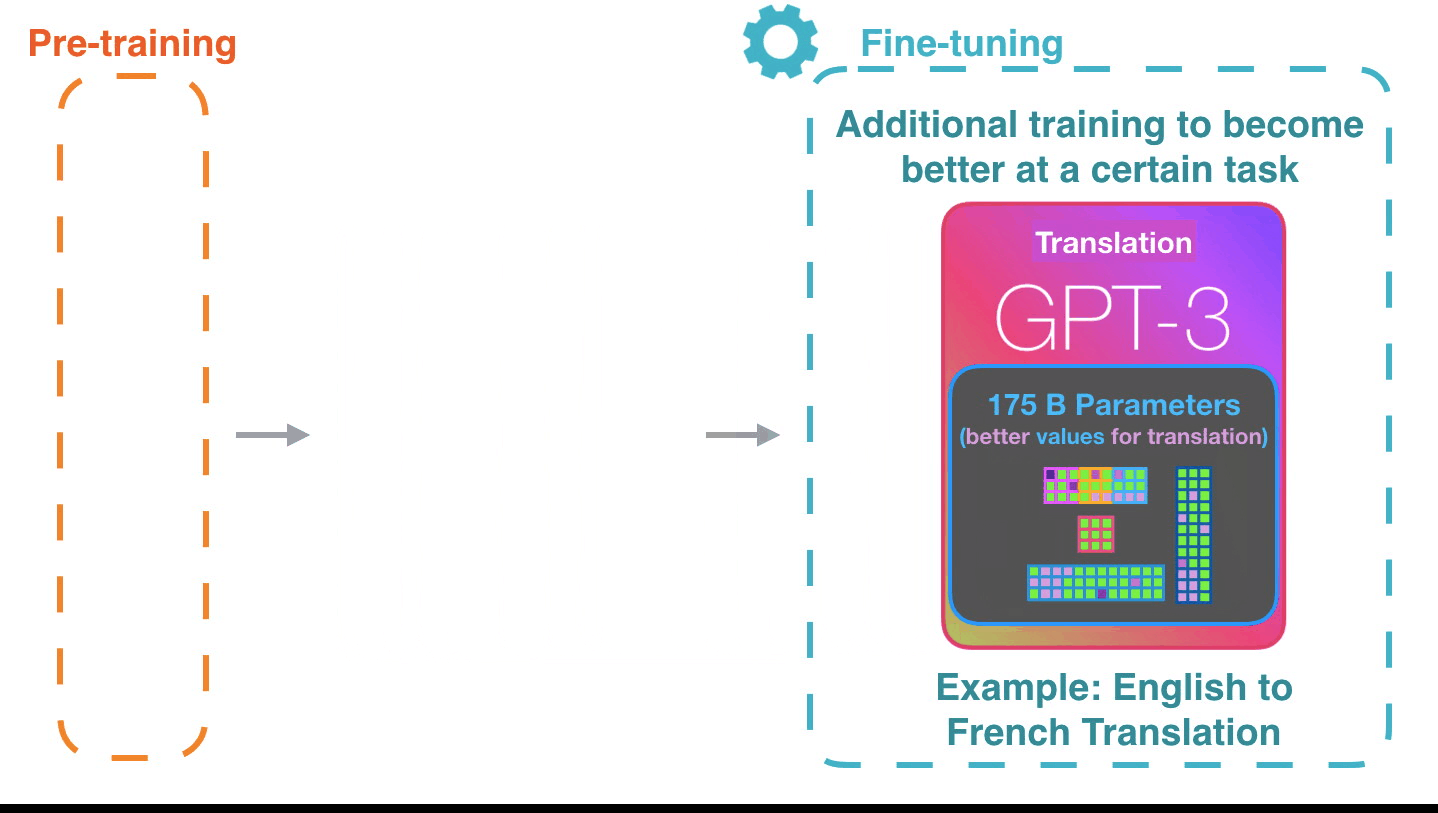
Figure 6: **Fine-tuning**[^2]: Fine-tuning actually updates the model’s
weights to make the model better at a certain task.
# Assistant Models

# [`saforem2/nanoGPT`](https://github.com/saforem2/nanoGPT)
- Fork of Andrej Karpathy’s `nanoGPT`

Figure 7: The simplest, fastest repository for training / finetuning GPT
based models.
# Install
``` bash
git clone https://github.com/saforem2/nanoGPT
cd nanoGPT
mkdir -p venv
python3 -m venv venv --system-site-packages
source venv/bin/activate
python3 -m pip install -e .
python3 -c 'import ngpt; print(ngpt.__file__)'
# ./nanoGPT/src/ngpt/__init__.py
```
# Dependencies
- [`transformers`](https://github.com/huggingface/transformers) for
transformers (to load `GPT-2` checkpoints)
- [`datasets`](https://github.com/huggingface/datasets) for datasets (if
you want to use OpenWebText)
- [`tiktoken`](https://github.com/openai/tiktoken) for OpenAI’s fast BPE
code
- [`wandb`](https://wandb.ai) for optional logging
- [`tqdm`](https://github.com/tqdm/tqdm) for progress bars
# Quick Start
- We start with training a character-level GPT on the works of
Shakespeare.
1. Downloading the data (~ 1MB) file
2. Convert raw text to one large stream of integers
``` bash
python3 data/shakespeare_char/prepare.py
```
This will create `data/shakespeare_char/{train.bin, val.bin}`.
# [ `model.py`](https://github.com/saforem2/nanoGPT/blob/master/src/ngpt/model.py)
### `GPT`
``` python
class GPT(nn.Module):
def __init__(self, config: ModelConfig):
super().__init__()
assert config.vocab_size is not None
assert config.block_size is not None
self.config = config
self.transformer = nn.ModuleDict(dict(
wte = nn.Embedding(config.vocab_size, config.n_embd),
wpe = nn.Embedding(config.block_size, config.n_embd),
drop = nn.Dropout(config.dropout),
h = nn.ModuleList([Block(config) for _ in range(config.n_layer)]),
ln_f = LayerNorm(config.n_embd, bias=config.bias),
))
self.lm_head = nn.Linear(config.n_embd, config.vocab_size, bias=False)
# with weight tying when using torch.compile() some warnings get generated:
# "UserWarning: functional_call was passed multiple values for tied weights.
# This behavior is deprecated and will be an error in future versions"
# not 100% sure what this is, so far seems to be harmless. TODO investigate
self.transformer.wte.weight = self.lm_head.weight # https://paperswithcode.com/method/weight-tying
# init all weights
self.apply(self._init_weights)
# apply special scaled init to the residual projections, per GPT-2 paper
for pn, p in self.named_parameters():
if pn.endswith('c_proj.weight'):
torch.nn.init.normal_(p, mean=0.0, std=0.02/math.sqrt(2 * config.n_layer))
# report number of parameters
log.info("number of parameters: %.2fM" % (self.get_num_params()/1e6,))
def get_num_params(self, non_embedding=True):
"""
Return the number of parameters in the model.
For non-embedding count (default), the position embeddings get subtracted.
The token embeddings would too, except due to the parameter sharing these
params are actually used as weights in the final layer, so we include them.
"""
n_params = sum(p.numel() for p in self.parameters())
if non_embedding:
n_params -= self.transformer.wpe.weight.numel()
return n_params
def _init_weights(self, module):
if isinstance(module, nn.Linear):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
if module.bias is not None:
torch.nn.init.zeros_(module.bias)
elif isinstance(module, nn.Embedding):
torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)
def forward(self, idx, targets=None):
device = idx.device
b, t = idx.size()
assert t <= self.config.block_size, f"Cannot forward sequence of length {t}, block size is only {self.config.block_size}"
pos = torch.arange(0, t, dtype=torch.long, device=device) # shape (t)
# forward the GPT model itself
tok_emb = self.transformer.wte(idx) # token embeddings of shape (b, t, n_embd)
pos_emb = self.transformer.wpe(pos) # position embeddings of shape (t, n_embd)
x = self.transformer.drop(tok_emb + pos_emb)
for block in self.transformer.h:
x = block(x)
x = self.transformer.ln_f(x)
if targets is not None:
# if we are given some desired targets also calculate the loss
logits = self.lm_head(x)
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1)
else:
# inference-time mini-optimization: only forward the lm_head on the very last position
logits = self.lm_head(x[:, [-1], :]) # note: using list [-1] to preserve the time dim
loss = None
return logits, loss
def crop_block_size(self, block_size):
# model surgery to decrease the block size if necessary
# e.g. we may load the GPT2 pretrained model checkpoint (block size 1024)
# but want to use a smaller block size for some smaller, simpler model
assert block_size <= self.config.block_size
self.config.block_size = block_size
self.transformer.wpe.weight = nn.Parameter(self.transformer.wpe.weight[:block_size])
for block in self.transformer.h:
if hasattr(block.attn, 'bias'):
block.attn.bias = block.attn.bias[:,:,:block_size,:block_size]
@classmethod
def from_pretrained(cls, model_type, override_args=None):
assert model_type in {'gpt2', 'gpt2-medium', 'gpt2-large', 'gpt2-xl'}
override_args = override_args or {} # default to empty dict
# only dropout can be overridden see more notes below
assert all(k == 'dropout' for k in override_args)
from transformers import GPT2LMHeadModel
log.info("loading weights from pretrained gpt: %s" % model_type)
# n_layer, n_head and n_embd are determined from model_type
config_args = {
'gpt2': dict(n_layer=12, n_head=12, n_embd=768), # 124M params
'gpt2-medium': dict(n_layer=24, n_head=16, n_embd=1024), # 350M params
'gpt2-large': dict(n_layer=36, n_head=20, n_embd=1280), # 774M params
'gpt2-xl': dict(n_layer=48, n_head=25, n_embd=1600), # 1558M params
}[model_type]
log.info("forcing vocab_size=50257, block_size=1024, bias=True")
config_args['vocab_size'] = 50257 # always 50257 for GPT model checkpoints
config_args['block_size'] = 1024 # always 1024 for GPT model checkpoints
config_args['bias'] = True # always True for GPT model checkpoints
# we can override the dropout rate, if desired
if 'dropout' in override_args:
log.info(f"overriding dropout rate to {override_args['dropout']}")
config_args['dropout'] = override_args['dropout']
# create a from-scratch initialized minGPT model
config = ModelConfig(**config_args)
model = GPT(config)
sd = model.state_dict()
sd_keys = sd.keys()
sd_keys = [k for k in sd_keys if not k.endswith('.attn.bias')] # discard this mask / buffer, not a param
# init a huggingface/transformers model
model_hf = GPT2LMHeadModel.from_pretrained(model_type)
sd_hf = model_hf.state_dict()
# copy while ensuring all of the parameters are aligned and match in names and shapes
sd_keys_hf = sd_hf.keys()
sd_keys_hf = [k for k in sd_keys_hf if not k.endswith('.attn.masked_bias')] # ignore these, just a buffer
sd_keys_hf = [k for k in sd_keys_hf if not k.endswith('.attn.bias')] # same, just the mask (buffer)
transposed = ['attn.c_attn.weight', 'attn.c_proj.weight', 'mlp.c_fc.weight', 'mlp.c_proj.weight']
# basically the openai checkpoints use a "Conv1D" module, but we only want to use a vanilla Linear
# this means that we have to transpose these weights when we import them
assert len(sd_keys_hf) == len(sd_keys), f"mismatched keys: {len(sd_keys_hf)} != {len(sd_keys)}"
for k in sd_keys_hf:
if any(k.endswith(w) for w in transposed):
# special treatment for the Conv1D weights we need to transpose
assert sd_hf[k].shape[::-1] == sd[k].shape
with torch.no_grad():
sd[k].copy_(sd_hf[k].t())
else:
# vanilla copy over the other parameters
assert sd_hf[k].shape == sd[k].shape
with torch.no_grad():
sd[k].copy_(sd_hf[k])
return model
def configure_optimizers(self, weight_decay, learning_rate, betas, device_type):
# start with all of the candidate parameters
param_dict = {pn: p for pn, p in self.named_parameters()}
# filter out those that do not require grad
param_dict = {pn: p for pn, p in param_dict.items() if p.requires_grad}
# create optim groups. Any parameters that is 2D will be weight decayed, otherwise no.
# i.e. all weight tensors in matmuls + embeddings decay, all biases and layernorms don't.
decay_params = [p for n, p in param_dict.items() if p.dim() >= 2]
nodecay_params = [p for n, p in param_dict.items() if p.dim() < 2]
optim_groups = [
{'params': decay_params, 'weight_decay': weight_decay},
{'params': nodecay_params, 'weight_decay': 0.0}
]
num_decay_params = sum(p.numel() for p in decay_params)
num_nodecay_params = sum(p.numel() for p in nodecay_params)
log.info(f"num decayed parameter tensors: {len(decay_params)}, with {num_decay_params:,} parameters")
log.info(f"num non-decayed parameter tensors: {len(nodecay_params)}, with {num_nodecay_params:,} parameters")
# Create AdamW optimizer and use the fused version if it is available
fused_available = 'fused' in inspect.signature(torch.optim.AdamW).parameters
use_fused = fused_available and device_type == 'cuda'
extra_args = dict(fused=True) if use_fused else dict()
optimizer = torch.optim.AdamW(optim_groups, lr=learning_rate, betas=betas, **extra_args)
log.info(f"using fused AdamW: {use_fused}")
return optimizer
def estimate_mfu(self, fwdbwd_per_iter, dt):
""" estimate model flops utilization (MFU) in units of A100 bfloat16 peak FLOPS """
# first estimate the number of flops we do per iteration.
# see PaLM paper Appendix B as ref: https://arxiv.org/abs/2204.02311
N = self.get_num_params()
cfg = self.config
L, H, Q, T = cfg.n_layer, cfg.n_head, cfg.n_embd//cfg.n_head, cfg.block_size
flops_per_token = 6*N + 12*L*H*Q*T
flops_per_fwdbwd = flops_per_token * T
flops_per_iter = flops_per_fwdbwd * fwdbwd_per_iter
# express our flops throughput as ratio of A100 bfloat16 peak flops
flops_achieved = flops_per_iter * (1.0/dt) # per second
flops_promised = 312e12 # A100 GPU bfloat16 peak flops is 312 TFLOPS
mfu = flops_achieved / flops_promised
return mfu
@torch.no_grad()
def generate(self, idx, max_new_tokens, temperature=1.0, top_k=None):
"""
Take a conditioning sequence of indices idx (LongTensor of shape (b,t)) and complete
the sequence max_new_tokens times, feeding the predictions back into the model each time.
Most likely you'll want to make sure to be in model.eval() mode of operation for this.
"""
for _ in range(max_new_tokens):
# if the sequence context is growing too long we must crop it at block_size
idx_cond = idx if idx.size(1) <= self.config.block_size else idx[:, -self.config.block_size:]
# forward the model to get the logits for the index in the sequence
logits, _ = self(idx_cond)
# pluck the logits at the final step and scale by desired temperature
logits = logits[:, -1, :] / temperature
# optionally crop the logits to only the top k options
if top_k is not None:
v, _ = torch.topk(logits, min(top_k, logits.size(-1)))
logits[logits < v[:, [-1]]] = -float('Inf')
# apply softmax to convert logits to (normalized) probabilities
probs = F.softmax(logits, dim=-1)
# sample from the distribution
idx_next = torch.multinomial(probs, num_samples=1)
# append sampled index to the running sequence and continue
idx = torch.cat((idx, idx_next), dim=1)
return idx
```
### `LayerNorm`
``` python
class LayerNorm(nn.Module):
""" LayerNorm but with an optional bias. PyTorch doesn't support simply bias=False """
def __init__(self, ndim, bias):
super().__init__()
self.weight = nn.Parameter(torch.ones(ndim))
self.bias = nn.Parameter(torch.zeros(ndim)) if bias else None
def forward(self, input):
return F.layer_norm(input, self.weight.shape, self.weight, self.bias, 1e-5)
```
### `CausalSelfAttention`
``` python
class CausalSelfAttention(nn.Module):
def __init__(self, config: ModelConfig):
super().__init__()
assert config.n_embd % config.n_head == 0
# key, query, value projections for all heads, but in a batch
self.c_attn = nn.Linear(config.n_embd, 3 * config.n_embd, bias=config.bias)
# output projection
self.c_proj = nn.Linear(config.n_embd, config.n_embd, bias=config.bias)
# regularization
self.attn_dropout = nn.Dropout(config.dropout)
self.resid_dropout = nn.Dropout(config.dropout)
self.n_head = config.n_head
self.n_embd = config.n_embd
self.dropout = config.dropout
# flash attention make GPU go brrrrr but support is only in PyTorch >= 2.0
self.flash = hasattr(torch.nn.functional, 'scaled_dot_product_attention')
# if self.flash and RANK == 0:
# log.warning(f'Using torch.nn.functional.scaled_dot_product_attention (Flash Attn)')
if not self.flash:
log.warning("WARNING: using slow attention. Flash Attention requires PyTorch >= 2.0")
# causal mask to ensure that attention is only applied to the left in the input sequence
self.register_buffer(
"bias",
torch.tril(
torch.ones(
config.block_size,
config.block_size
)
).view(1, 1, config.block_size, config.block_size)
)
def forward(self, x):
B, T, C = x.size() # batch size, sequence length, embedding dimensionality (n_embd)
# calculate query, key, values for all heads in batch and move head forward to be the batch dim
q, k, v = self.c_attn(x).split(self.n_embd, dim=2)
k = k.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
q = q.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
v = v.view(B, T, self.n_head, C // self.n_head).transpose(1, 2) # (B, nh, T, hs)
# causal self-attention; Self-attend: (B, nh, T, hs) x (B, nh, hs, T) -> (B, nh, T, T)
if self.flash:
# efficient attention using Flash Attention CUDA kernels
y = torch.nn.functional.scaled_dot_product_attention(q, k, v, attn_mask=None, dropout_p=self.dropout if self.training else 0, is_causal=True)
else:
# manual implementation of attention
att = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
att = att.masked_fill(self.bias[:,:,:T,:T] == 0, float('-inf'))
att = F.softmax(att, dim=-1)
att = self.attn_dropout(att)
y = att @ v # (B, nh, T, T) x (B, nh, T, hs) -> (B, nh, T, hs)
y = y.transpose(1, 2).contiguous().view(B, T, C) # re-assemble all head outputs side by side
# output projection
y = self.resid_dropout(self.c_proj(y))
return y
```
### `MLP`
``` python
class MLP(nn.Module):
def __init__(self, config: ModelConfig):
super().__init__()
self.c_fc = nn.Linear(config.n_embd, 4 * config.n_embd, bias=config.bias)
self.gelu = nn.GELU()
self.c_proj = nn.Linear(4 * config.n_embd, config.n_embd, bias=config.bias)
self.dropout = nn.Dropout(config.dropout)
def forward(self, x):
x = self.c_fc(x)
x = self.gelu(x)
x = self.c_proj(x)
x = self.dropout(x)
return x
class Block(nn.Module):
def __init__(self, config: ModelConfig):
super().__init__()
self.ln_1 = LayerNorm(config.n_embd, bias=config.bias)
self.attn = CausalSelfAttention(config)
self.ln_2 = LayerNorm(config.n_embd, bias=config.bias)
self.mlp = MLP(config)
def forward(self, x):
x = x + self.attn(self.ln_1(x))
x = x + self.mlp(self.ln_2(x))
return x
```
# [ `trainer.py`](https://github.com/saforem2/nanoGPT/blob/master/src/ngpt/trainer.py)
### `get_batch`
``` python
def get_batch(self, split: str) -> tuple[torch.Tensor, torch.Tensor]:
data = self.config.train_data if split == 'train' else self.config.val_data
ix = torch.randint(
len(data) - self.config.model.block_size,
(self.config.model.batch_size,)
)
block_size = self.config.model.block_size
x = torch.stack(
[
torch.from_numpy((data[i:i+block_size]).astype(np.int64))
for i in ix
]
)
y = torch.stack(
[
torch.from_numpy((data[i+1:i+1+block_size]).astype(np.int64))
for i in ix
]
)
if self.config.device_type == 'cuda':
x = x.pin_memory().to(self.config.device_type, non_blocking=True)
y = y.pin_memory().to(self.config.device_type, non_blocking=True)
else:
x = x.to(self.config.device_type)
y = y.to(self.config.device_type)
return x, y
```
### `estimate_loss`
``` python
@torch.no_grad()
def estimate_loss(self):
out = {}
self.model.eval()
for split in ['train', 'val']:
losses = torch.zeros(self.config.train.eval_iters)
for k in range(self.config.train.eval_iters):
x, y = self.get_batch(split)
with self.config.ctx:
_, loss = self.model(x, y)
losses[k] = loss.item()
out[split] = losses.mean()
self.model.train()
return out
```
### `_forward_step`
``` python
def _forward_step(self, x: torch.Tensor, y: torch.Tensor) -> dict:
t0 = time.perf_counter()
with self.config.ctx:
logits, loss = self.model(x, y)
return {
'logits': logits,
'loss': loss,
'dt': time.perf_counter() - t0
}
```
### `_backward_step`
``` python
def _backward_step(
self,
loss: torch.Tensor,
propagate_grads: bool = False,
) -> float:
t0 = time.perf_counter()
self.scaler.scale(loss).backward() # pyright: ignore
if propagate_grads:
if self.config.optimizer.grad_clip != 0.0:
self.scaler.unscale_(self.optimizer)
torch.nn.utils.clip_grad_norm_( # pyright: ignore
self.model.parameters(),
self.config.optimizer.grad_clip
)
self.scaler.step(self.optimizer)
self.scaler.update()
self.optimizer.zero_grad(set_to_none=True)
return time.perf_counter() - t0
```
### `train_step`
``` python
def train_step(
self,
x: torch.Tensor,
y: torch.Tensor,
) -> dict:
lr = (
self.get_lr(self.config.iter_num)
if self.config.optimizer.decay_lr
else self._lr
)
for param_group in self.optimizer.param_groups:
param_group['lr'] = lr
dtf = []
dtb = []
dt = []
loss = torch.tensor(0.0)
for micro_step in range(self._gas):
is_last_micro_step = (micro_step == self._gas - 1)
# NOTE: -----------------------------------------------------------
# In DDP training we only need to sync gradients at the last micro
# step. the official way to do this is with model.no_sync() context
# manager, but I really dislike that this bloats the code and
# forces us to repeat code looking at the source of that context
# manager, it just toggles this variable
# -----------------------------------------------------------------
_ = (
self.model.require_backward_grad_sync
if (is_last_micro_step and WORLD_SIZE > 1)
else None
)
fout = self._forward_step(x, y)
# immediately async prefetch next batch while model is doing the forward pass on the GPU
x, y = self.get_batch('train')
loss = fout['loss'] / self._gas
dtf.append(fout['dt'])
dtb_ = self._backward_step(loss, propagate_grads=is_last_micro_step)
dtb.append(dtb_)
dt.append(dtf + dtb)
timers = {
'iter': self.config.iter_num,
'dt': np.array(dt),
'dt_tot': np.sum(dt),
'dt_avg': np.mean(dt),
'dtf': np.array(dtf),
'dtf_tot': np.sum(dtf),
'dtf_avg': np.mean(dtf),
'dtb': np.array(dtb),
'dtb_tot': np.sum(dtb),
'dtb_avg': np.mean(dtb)
}
metrics = {
'iter': self.config.iter_num,
'loss': loss,
'lr': lr,
}
self.config.iter_num += 1
return {
'metrics': metrics,
'timers': timers,
'x': x,
'y': y,
}
```
# Hands-on Tutorial
#### 📒 Shakespeare
- [](https://colab.research.google.com/github/saforem2/nanoGPT/blob/master/notebooks/ngpt-shakespeare.ipynb)
- [Web
Version](https://saforem2.github.io/nanoGPT/quarto/shakespeare.html)
- [`ngpt-shakespeare.ipynb`](https://github.com/saforem2/nanoGPT/blob/master/notebooks/ngpt-shakespeare.ipynb)
#### 📒 GPT-2 Small
- [](https://colab.research.google.com/github/saforem2/nanoGPT/blob/master/notebooks/ngpt-gpt2-yelp.ipynb)
- [`ngpt-gpt2-yelp.ipynb`](https://github.com/saforem2/nanoGPT/blob/master/notebooks/ngpt-gpt2-yelp.ipynb)
- Uses `yelp_review_full` dataset
#### 📒 GPT-2 Medium
- [](https://colab.research.google.com/github/saforem2/nanoGPT/blob/master/notebooks/ngpt-gpt2.ipynb)
- [Web
Version](https://saforem2.github.io/nanoGPT/quarto/gpt2-medium.html)
- [`ngpt-gpt2.ipynb`](https://github.com/saforem2/nanoGPT/blob/master/notebooks/ngpt-gpt2.ipynb)
#### 📒 GPT-2 XL
- [](https://colab.research.google.com/github/saforem2/nanoGPT/blob/master/notebooks/ngpt-gpt2-xl.ipynb)
- [Web Version](https://saforem2.github.io/nanoGPT/quarto/gpt2-xl.html)
- [`ngpt-gpt2-xl.ipynb`](https://github.com/saforem2/nanoGPT/blob/master/notebooks/ngpt-gpt2-xl.ipynb)
#### 🔗 Links
- 📊
[Slides](https://saforem2.github.io/LLM-tutorial/#/llms-tutorial-workshop)
- 🏡
[Project Website](https://saforem2.github.io/nanoGPT)
- 💻
[`saforem2/nanoGPT`](https://github.com/saforem2/nanoGPT)
#
# Links
1. [
Hannibal046/Awesome-LLM](https://github.com/Hannibal046/Awesome-LLM/blob/main/README.md)
[](https://awesome.re)
2. [
Mooler0410/LLMsPracticalGuide](https://github.com/Mooler0410/LLMsPracticalGuide)
3. [Large Language Models (in
2023)](https://docs.google.com/presentation/d/1636wKStYdT_yRPbJNrf8MLKpQghuWGDmyHinHhAKeXY/edit#slide=id.g238b2698243_0_734https://docs.google.com/presentation/d/1636wKStYdT_yRPbJNrf8MLKpQghuWGDmyHinHhAKeXY/edit#slide=id.g238b2698243_0_734)
4. [The Illustrated
Transformer](http://jalammar.github.io/illustrated-transformer/)
5. [Generative AI Exists because of the
Transformer](https://ig.ft.com/generative-ai/)
6. [GPT in 60 Lines of
Numpy](https://jaykmody.com/blog/gpt-from-scratch/)
7. [Better Language Models and their
Implications](https://openai.com/research/better-language-models)
8. [Progress / Artefacts / Outcomes
from 🌸 Bloom
BigScience](https://bigscience.notion.site/ebe3760ae1724dcc92f2e6877de0938f?v=2faf85dc00794321be14bc892539dd4f)
> **Acknowledgements**
>
> This research used resources of the Argonne Leadership Computing
> Facility,
> which is a DOE Office of Science User Facility supported under
> Contract DE-AC02-06CH11357.
# References
Yang, Jingfeng, Hongye Jin, Ruixiang Tang, Xiaotian Han, Qizhang Feng,
Haoming Jiang, Bing Yin, and Xia Hu. 2023. “Harnessing the Power of LLMs
in Practice: A Survey on ChatGPT and Beyond.”
.
Yao, Shunyu, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths,
Yuan Cao, and Karthik Narasimhan. 2023. “Tree of Thoughts: Deliberate
Problem Solving with Large Language Models.”
.
[^1]: [`saforem2/LLM-tutorial`](https://github.com/saforem2/LLM-tutorial)
[^2]: Figure from [The Illustrated
Transformer](http://jalammar.github.io/illustrated-transformer/)


