https://github.com/salesforce/TabularSemanticParsing
Translating natural language questions to a structured query language
https://github.com/salesforce/TabularSemanticParsing
database natural-language-interface natural-language-processing pytorch semantic-parsing text-to-sql
Last synced: 12 months ago
JSON representation
Translating natural language questions to a structured query language
- Host: GitHub
- URL: https://github.com/salesforce/TabularSemanticParsing
- Owner: salesforce
- License: bsd-3-clause
- Created: 2020-12-01T00:15:32.000Z (over 5 years ago)
- Default Branch: main
- Last Pushed: 2023-06-12T21:28:21.000Z (about 3 years ago)
- Last Synced: 2024-12-10T08:41:55.775Z (over 1 year ago)
- Topics: database, natural-language-interface, natural-language-processing, pytorch, semantic-parsing, text-to-sql
- Language: Jupyter Notebook
- Homepage: https://arxiv.org/abs/2012.12627
- Size: 1.06 MB
- Stars: 223
- Watchers: 10
- Forks: 51
- Open Issues: 24
-
Metadata Files:
- Readme: README.md
- License: LICENSE
- Code of conduct: CODE_OF_CONDUCT.md
- Codeowners: CODEOWNERS
- Security: SECURITY.md
Awesome Lists containing this project
- Awesome-Text2SQL - [code
README
# Bridging Textual and Tabular Data for Cross-Domain Text-to-SQL Semantic Parsing
This is the official code release of the following paper:
Xi Victoria Lin, Richard Socher and Caiming Xiong. [Bridging Textual and Tabular Data for Cross-Domain Text-to-SQL Semantic Parsing](https://arxiv.org/abs/2012.12627). Findings of EMNLP 2020.
## Overview
Cross-domain tabular semantic parsing (X-TSP) is the task of predicting the executable structured query language given a natural language question issued to some database. The model may or may not have seen the target database during training.
This library implements
- A strong sequence-to-sequence based cross-domain text-to-SQL semantic parser that achieved state-of-the-art performance on two widely used benchmark datasets: [Spider](https://yale-lily.github.io/spider) and [WikiSQL](https://github.com/salesforce/WikiSQL).
- A set of [SQL processing tools](moz_sp) for parsing, tokenizing and validating SQL queries, adapted from the [Moz SQL Parser](https://github.com/mozilla/moz-sql-parser).
The parser can be adapted to learn mappings from text to other structured query languages such as [SOQL](https://developer.salesforce.com/docs/atlas.en-us.soql_sosl.meta/soql_sosl/sforce_api_calls_soql.htm) by modifying the formal langauge pre-processing and post-processing modules.
## Model
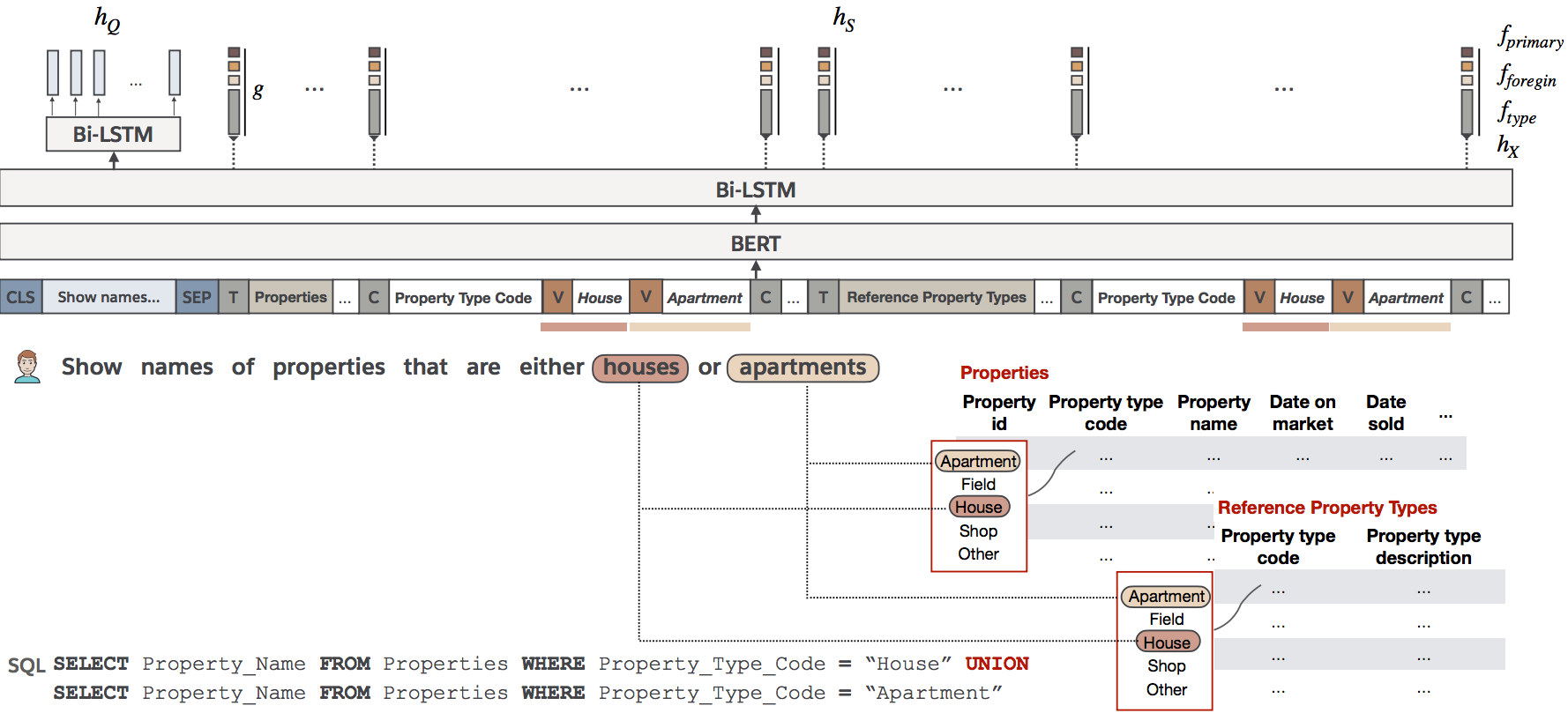
Our model takes a natural language utterance and a database (schema + field picklists) as input, and generates SQL queries as token sequences. We apply schema-guided decoding and post-processing to make sure the final output is executable.
- **Preprocessing:** We concatenate the serialized database schema with the utterance to form a tagged sequence. A [fuzzy string matching algorithm](src/common/content_encoder.py) is used to identify picklist items mentioned in the utterance. The mentioned picklist items are appended to the corresponding field name in the tagged sequence.
- **Translating:** The hybrid sequence is passed through the BRIDGE model, which output raw program sequences with probability scores via beam search.
- **Postprocessing:** The raw program sequences are passed through a SQL checker, which verifies its syntactical correctness and schema consistency. Sequences that failed to pass the checker are discarded from the output.
## Quick Start
### Install Dependencies
Our implementation has been tested using Pytorch 1.7 and Cuda 11.0 with a single GPU.
```
git clone https://github.com/salesforce/TabularSemanticParsing
cd TabularSemanticParsing
pip install torch torchvision
python3 -m pip install -r requirements.txt
```
### Set up Environment
```
export PYTHONPATH=`pwd` && python -m nltk.downloader punkt
```
### Process Data
#### Spider
Download the [official data release](https://drive.google.com/u/1/uc?export=download&confirm=pft3&id=1_AckYkinAnhqmRQtGsQgUKAnTHxxX5J0) and unzip the folder. Manually merge `spider/train_spider.json` with `spider/train_others.json` into a single file `spider/train.json`.
```
mv spider data/
# Data Repair (more details in section 4.3 of paper)
python3 data/spider/scripts/amend_missing_foreign_keys.py data/spider
./experiment-bridge.sh configs/bridge/spider-bridge-bert-large.sh --process_data 0
```
#### WikiSQL
Download the [official data release](https://github.com/salesforce/WikiSQL/blob/master/data.tar.bz2).
```
wget https://github.com/salesforce/WikiSQL/raw/master/data.tar.bz2
tar xf data.tar.bz2 -C data && mv data/data data/wikisql1.1
./experiment-bridge.sh configs/bridge/wikisql-bridge-bert-large.sh --process_data 0
```
The processed data will be stored in a separate pickle file.
### Train
Train the model using the following commands. The checkpoint of the best model will be stored in a directory [specified by the hyperparameters](https://github.com/salesforce/TabularSemanticParsing/blob/25b154d3dc0e25922822433400c453274d38b8c8/src/data_processor/path_utils.py#L309) in the configuration file.
#### Spider
```
./experiment-bridge.sh configs/bridge/spider-bridge-bert-large.sh --train 0
```
#### WikiSQL
```
./experiment-bridge.sh configs/bridge/wikisql-bridge-bert-large.sh --train 0
```
### Inference
Decode SQL predictions from pre-trained models. The following commands run inference with the checkpoints stored in the directory specified by the hyperparameters in the configuration file.
#### Spider
```
./experiment-bridge.sh configs/bridge/spider-bridge-bert-large.sh --inference 0
```
#### WikiSQL
```
./experiment-bridge.sh configs/bridge/wikisql-bridge-bert-large.sh --inference 0
```
**Note:**
1. Add the `--test` flag to the above commands to obtain the test set evaluation results on the corresponding dataset. This flag is invalid for Spider, as its test set is hidden.
2. Add the `--checkpoint_path [path_to_checkpoint_tar_file]` flag to decode using a checkpoint that's not stored in the default location.
3. Evaluation metrics will be printed out at the end of decoding. The WikiSQL evaluation takes some time because it computes execution accuracy.
### Inference with Model Ensemble
To decode with model ensemble, first list the checkpoint directories of the individual models in the [ensemble model configuration file](src/semantic_parser/ensemble_configs.py), then run the following command(s).
#### Spider
```
./experiment-bridge.sh configs/bridge/spider-bridge-bert-large.sh --ensemble_inference 0
```
### Commandline Demo
You can interact with a pre-trained checkpoint through the commandline using the following commands:
#### Spider
```
./experiment-bridge.sh configs/bridge/spider-bridge-bert-large.sh --demo 0 --demo_db [db_name] --checkpoint_path [path_to_checkpoint_tar_file]
```
### Hyperparameter Changes
To change the hyperparameters and other experiment set up, start from the [configuration files](configs).
## Pre-trained Checkpoints
#### Spider
Download pre-trained checkpoints here:
URL
E-SM
EXE
https://drive.google.com/file/d/1dlrUdGMLvvvfR3kNVy76H12rR7gr4DXI/view?usp=sharing
70.1
68.2
```
mv bridge-spider-bert-large-ems-70-1-exe-68-2.tar.gz model
gunzip model/bridge-spider-bert-large-ems-70-1-exe-68-2.tar.gz
```
Download cached SQL execution order to normal order mappings:
URL
https://drive.google.com/file/d/1vk14iR4V_f5x4e17MAaL_L8T9wgjcKCy/view?usp=sharing
**Why this cache?** The overhead of converting thousands of SQL queries from execution order to normal order is large, so we cached the conversion for Spider dev set in our experiments. Without using the cache inference on the dev set will be slow. The model still runs fast for individual queries without using a cache.
```
mv dev.eo.pred.restored.pkl.gz data/spider
gunzip data/spider/dev.eo.pred.restored.pkl.gz
```
## Citation
If you find the resource in this repository helpful, please cite
```
@inproceedings{LinRX2020:BRIDGE,
author = {Xi Victoria Lin and Richard Socher and Caiming Xiong},
title = {Bridging Textual and Tabular Data for Cross-Domain Text-to-SQL Semantic Parsing},
booktitle = {Proceedings of the 2020 Conference on Empirical Methods in Natural
Language Processing: Findings, {EMNLP} 2020, November 16-20, 2020},
year = {2020}
}
```
## Related Links
The parser has been integrated in the Photon web demo: http://naturalsql.com/. Please visit our website to test it live and try it on your own databases!