https://github.com/sandergi/hmc_ml_challenge
Technical challenge for Machine Learning research position with the HMC Research Lab
https://github.com/sandergi/hmc_ml_challenge
challenge pytorch
Last synced: about 1 year ago
JSON representation
Technical challenge for Machine Learning research position with the HMC Research Lab
- Host: GitHub
- URL: https://github.com/sandergi/hmc_ml_challenge
- Owner: SanderGi
- License: mit
- Created: 2022-12-21T20:49:10.000Z (over 3 years ago)
- Default Branch: main
- Last Pushed: 2022-12-21T20:55:49.000Z (over 3 years ago)
- Last Synced: 2025-03-25T10:01:45.888Z (about 1 year ago)
- Topics: challenge, pytorch
- Language: Jupyter Notebook
- Homepage:
- Size: 3.63 MB
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# HMC_ML_Challenge
Technical challenge for Machine Learning research position with the HMC Research Lab. The challenge prompt was creating a machine learning based program (so not a hardcoded algorithm) to convert text based numbers from 0-9999 (inclusive) to numerical numbers.
My model is a fully connected neural network with two hidden layers (120 and 100 neurons respectively) using the relu activation function and the sigmoid function for the output layer. I treat the problem as a classification task (with one class for each number 0-9999) using the cross entropy loss to go with the sigmoid function (picking the maximum output for predictions). One nice property of this problem that I noticed early on is that there is no need for generalization as the output space is limited to 0-9999. This allows me to make a number of simplifications since I don't have to worry about overfitting etc:
1. I can use the training loss on its own (no need for cross validation or a test set) -- the model is essentially allowed to just memorize the training data
2. I can add as many layers and neurons as I want with the only trade off being training time
3. No regularization or other measures need to be taken
My approach was then to randomly generate numbers from 0-9999 and convert them to word based numbers using a rule based approach. Then the model can be trained to reverse this (go from word based numbers to numerical numbers). For encoding the input, I just needed a representation that would be unique for each number since the idea was to memorize the training data (there was no need to do any excessive feature engineering to encourage generalization etc). I therefore opted to have 6 times 30 input neurons with each group of 30 representing a text-based number (twent, hundred, one, etc.) and the groups being filled in in the order of the input text. In other words, if the text is "one hundred twenty", then the first group of 30 would have the one-hot encoded neuron corresponding to "one" active, the second group would have the neuron corresponding to "hundred" and so on. Unimportant words like "and" are simply ignored by the model when making predictions for robustness. This simplistic approach of encoding position (since our number system is position based) in 6 groups, does not work perfectly and doesn't generalize nicely beyond 9999. For instance "one hundred" and "one thousand" would be encoded into the same position/groups. However, again, since all I needed was to memorize the data, the encoding just needed to be unique.
In the end, my model cross entropy loss decreased from 9.21 to 8.226 and was still decreasing steadily when I stopped the training (so more training time would have yielded a better model). A few improvements I can think of to make this model better in the future:
1. A better positional encoding (perhaps something similar to some large language transformers that use sine based frequency encoding or possibly simpler, just make each group of 30 neurons correspond to a specific place value (ones, tens, hundreds, etc.)).
2. Experiment more with the hidden layer sizes to speed up training (120*100 = 12000 neurons is definitely overkill for 10000 classes).
3. Try a regression approach instead of a classification approach since the classes are ordered 0-9999 and giving the model that connection might yield better results (it'll be better able to get "close" to the right answer)
The final model was successfully able to get within the right 1000 of the correct number most of the time:
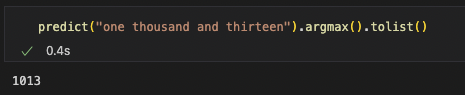
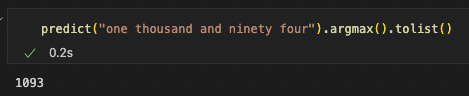
And sometimes closer than that, but was also clearly ignoring parts of the input (like the last digit being treated like a 3).
For all the numbers (0-9999), the model predicted 1448 numbers exactly and was on average within 1157.3018 of the correct number. Which is much better than random guessing (which gets 0-2 numbers correctly and on average is 3375.6591 from the correct number) but still leaves lots of room for improvement.