https://github.com/sandergi/sentimentanalysisapi
A simple API that takes English text and provides a predicted sentiment (positive/negative) for it
https://github.com/sandergi/sentimentanalysisapi
challenge logistic-regression naive-bayes-classifier nlp sentiment-analysis
Last synced: about 1 year ago
JSON representation
A simple API that takes English text and provides a predicted sentiment (positive/negative) for it
- Host: GitHub
- URL: https://github.com/sandergi/sentimentanalysisapi
- Owner: SanderGi
- License: mit
- Created: 2022-07-18T05:46:00.000Z (almost 4 years ago)
- Default Branch: main
- Last Pushed: 2022-07-23T01:28:11.000Z (almost 4 years ago)
- Last Synced: 2025-03-25T10:01:45.853Z (about 1 year ago)
- Topics: challenge, logistic-regression, naive-bayes-classifier, nlp, sentiment-analysis
- Language: Jupyter Notebook
- Homepage:
- Size: 1.21 MB
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# Sentiment Analysis API
A simple API that takes English text and provides a predicted sentiment (positive/negative) for it. It is a python server using Fast API that predicts sentiments using logistic regression. The documentation uses Swagger UI (mostly the default Fast API stuff, but also some custom descriptions etc.).
## How to Use
* First download the files and uvicorn (to host the Fast API server locally)
* Install dependencies (can be found in requirements.txt and installed using pip)
* Then run "uvicorn main:app" from the terminal to start the local server (from the directory of the files in this github)
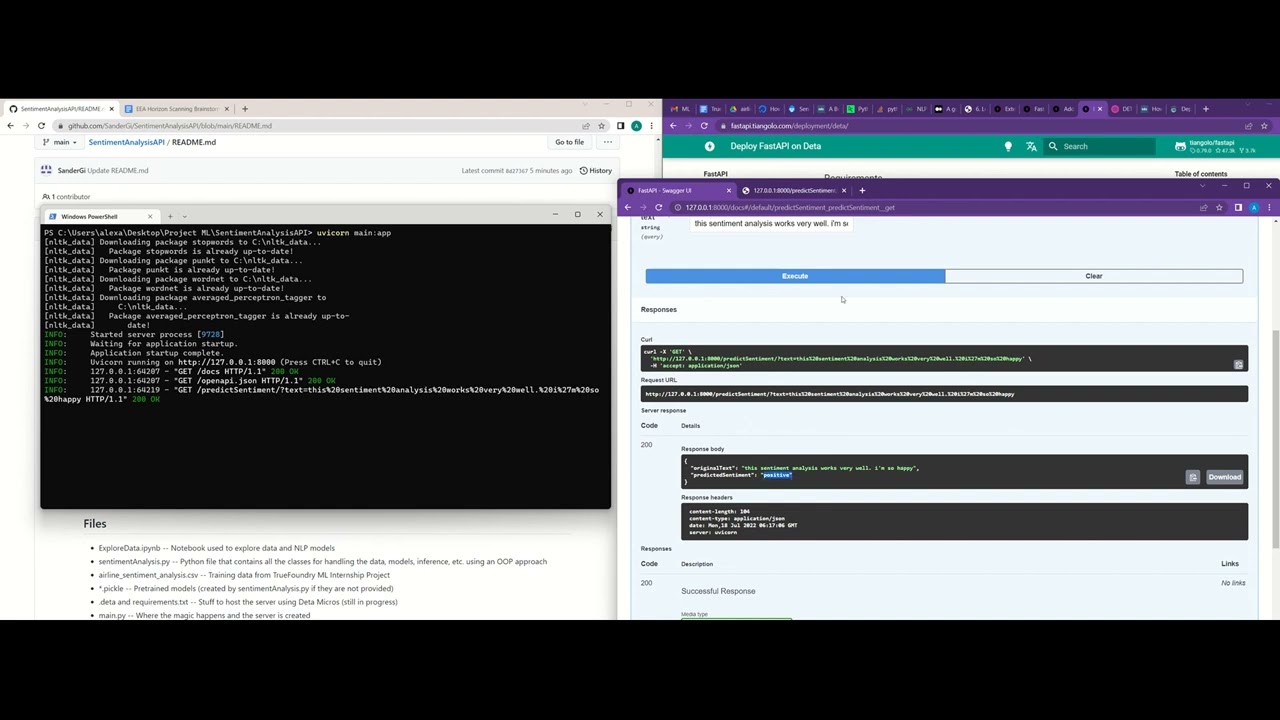
* Documentation can be found here when hosted locally: http://127.0.0.1:8000/docs#/
* GET requests can then be made to "http://127.0.0.1:8000/predictSentiment/" where the "text" query parameter is the url encoded english text to get a predicted sentiment of (response is json):

* The "predictedSentiment" can either be "positive" or "negative"
## Demo Video
[](https://youtu.be/bcV2_wZw4FA)
## Files
* ExploreData.ipynb -- Notebook used to explore data and NLP models
* sentimentAnalysis.py -- Python file that contains all the classes for handling the data, models, inference, etc. using an OOP approach
* airline_sentiment_analysis.csv -- Training data from TrueFoundry ML Internship Project
* *.pickle -- Pretrained models (created by sentimentAnalysis.py if they are not provided)
* .deta and requirements.txt -- Stuff to host the server using Deta Micros (still in progress)
* main.py -- Where the magic happens and the server is created
## Next steps
* Host using Deta or Heroku -- I am currently in the process of hosting a public endpoint for the API but ran into problems with incompatible dependencies for Deta and haven't had time to fix this yet
* Make it possible to choose different models with a query parameter
* Possibly a "feature importance" feature that highlights what words and phrases in the given english text contributed in what ways to the predicted sentiment (NaiveBayes model is useful for this since it is probabilistic)
* More advanced models (e.g. deeplearning) and a better model evaluation framework (e.g. k-fold cross validation) for better hyperparameter tuning