https://github.com/sap-samples/acl2022-self-contrastive-decorrelation
Source code for ACL 2022 paper "Self-contrastive Decorrelation for Sentence Embeddings".
https://github.com/sap-samples/acl2022-self-contrastive-decorrelation
ai nlp research research-paper sample self-contrastive self-contrastive-decorrelation self-supervised-learning sentence-embeddings
Last synced: 6 months ago
JSON representation
Source code for ACL 2022 paper "Self-contrastive Decorrelation for Sentence Embeddings".
- Host: GitHub
- URL: https://github.com/sap-samples/acl2022-self-contrastive-decorrelation
- Owner: SAP-samples
- License: apache-2.0
- Created: 2022-03-01T17:32:33.000Z (over 3 years ago)
- Default Branch: main
- Last Pushed: 2025-03-10T14:53:59.000Z (7 months ago)
- Last Synced: 2025-03-27T05:51:11.137Z (7 months ago)
- Topics: ai, nlp, research, research-paper, sample, self-contrastive, self-contrastive-decorrelation, self-supervised-learning, sentence-embeddings
- Language: Python
- Homepage:
- Size: 278 KB
- Stars: 24
- Watchers: 8
- Forks: 7
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# SCD: Self-Contrastive Decorrelation of Sentence Embeddings
[](#python)
[](https://opensource.org/licenses/Apache-2.0)
[](https://api.reuse.software/info/github.com/SAP-samples/acl2022-self-contrastive-decorrelation)
#### News
- **03/23/2022:** :confetti_ball: Source code provided :tada:
- 03/16/2022: Added arXiv pre-print, provided models for download
## Description
This repository contains the source code for our paper [**SCD: Self-Contrastive Decorrelation of Sentence Embeddings**](http://arxiv.org/abs/2203.07847) to be presented at [ACL2022](https://www.2022.aclweb.org/). The code is in parts based on the code from [Huggingface Tranformers](https://github.com/huggingface/transformers) and the paper [SimCSE: Simple Contrastive Learning of Sentence Embeddings](https://github.com/princeton-nlp/SimCSE).
### Abstract
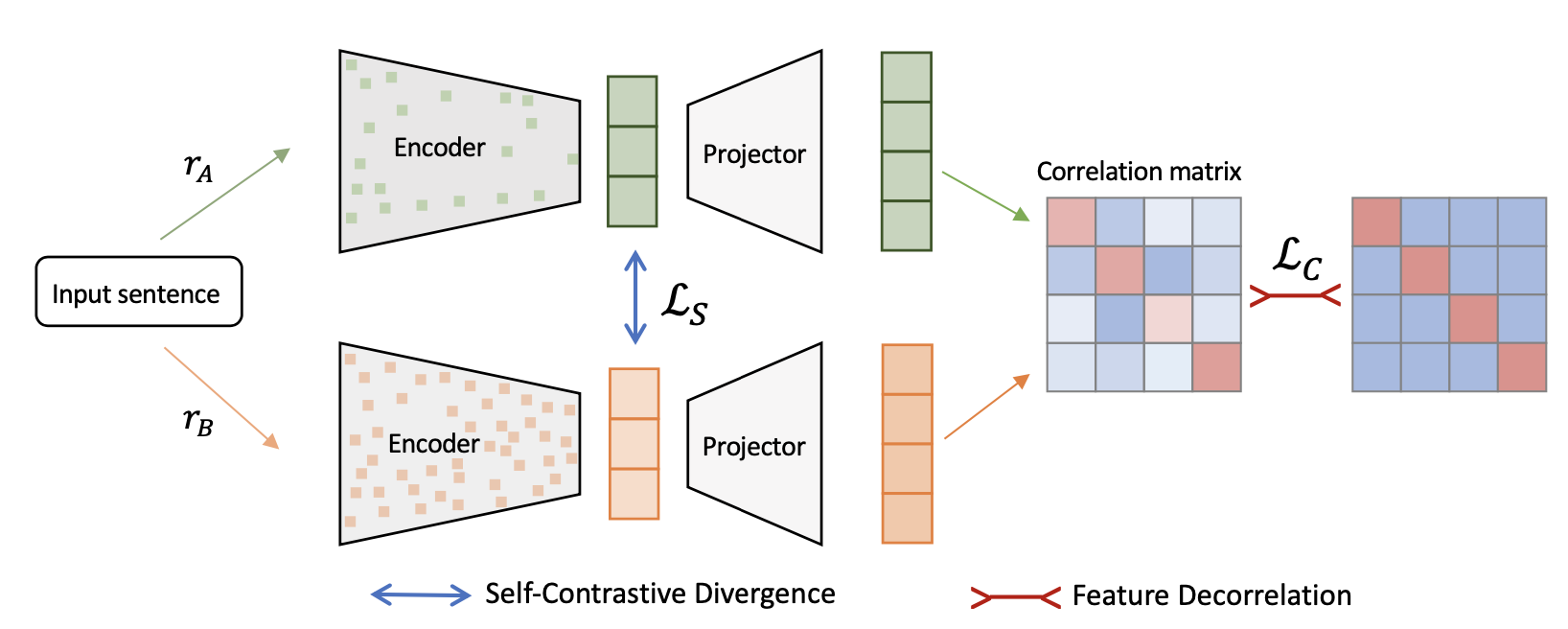
In this paper, we propose Self-Contrastive Decorrelation, a self-supervised approach, which takes an input sentence and optimizes a joint self-contrastive and decorrelation objective, with only standard dropout. This simple method works surprisingly well, achieves comparable results with state-of-the-art methods on multiple benchmarks without using contrastive pairs. This study opens up avenues for efficient self-supervised learning methods that are more resilient to train on a small batch regime than current contrastive methods.
#### Authors:
- [Tassilo Klein](https://tjklein.github.io/)
- [Moin Nabi](https://moinnabi.github.io/)
## Requirements
- [Python](https://www.python.org/) (version 3.6 or later)
- [PyTorch](https://pytorch.org/)
## Related work
[](https://arxiv.org/abs/2211.04928) [](https://huggingface.co/sap-ai-research/miCSE)
Check out the pre-print of latest work for sentence similarity that facilitates learning embeddings even with minimal amounts of data: "_**miCSE**: Mutual Information Contrastive Learning for Low-shot Sentence Embeddings_"
## Download and Installation
1. Clone this repository
```
git clone https://github.com/SAP-samples/acl2022-self-contrastive-decorrelation scd
cd scd
```
2. Install the requirements
```
pip install -r requirements.txt
```
3. Download training data
```
cd data
sh download_wiki.sh
cd ..
```
4. Download evaluation dataset
```
cd SentEval/data/downstream/
sh download_dataset.sh
cd ../../../
```
5. :fire: Patching transformers :fire:
Leveraging **multi-dropout** for SCD requires patching the language model of Huggingface transformers. Doing is is rather simple. The portions of the code that have to be changed have been indicated with ```# SCD``` in the source code. Basically, you need to change the following modules in the specific language model file (with code links for the BERT language model):
- Embedding(nn.Module)
https://github.com/SAP-samples/acl2022-self-contrastive-decorrelation/blob/6dc4a006b87313f5f2dcc521cc53d3808eace782/transformers_v4.10/src/transformers/models/bert/modeling_bert.py#L193
https://github.com/SAP-samples/acl2022-self-contrastive-decorrelation/blob/6dc4a006b87313f5f2dcc521cc53d3808eace782/transformers_v4.10/src/transformers/models/bert/modeling_bert.py#L251
- SelfAttention(nn.Module)
https://github.com/SAP-samples/acl2022-self-contrastive-decorrelation/blob/6dc4a006b87313f5f2dcc521cc53d3808eace782/transformers_v4.10/src/transformers/models/bert/modeling_bert.py#L288
https://github.com/SAP-samples/acl2022-self-contrastive-decorrelation/blob/6dc4a006b87313f5f2dcc521cc53d3808eace782/transformers_v4.10/src/transformers/models/bert/modeling_bert.py#L390
- SelfOutput(nn.Module)
https://github.com/SAP-samples/acl2022-self-contrastive-decorrelation/blob/6dc4a006b87313f5f2dcc521cc53d3808eace782/transformers_v4.10/src/transformers/models/bert/modeling_bert.py#L427
https://github.com/SAP-samples/acl2022-self-contrastive-decorrelation/blob/6dc4a006b87313f5f2dcc521cc53d3808eace782/transformers_v4.10/src/transformers/models/bert/modeling_bert.py#L440
- BertOutput(nn.Module)
https://github.com/SAP-samples/acl2022-self-contrastive-decorrelation/blob/6dc4a006b87313f5f2dcc521cc53d3808eace782/transformers_v4.10/src/transformers/models/bert/modeling_bert.py#L529
https://github.com/SAP-samples/acl2022-self-contrastive-decorrelation/blob/6dc4a006b87313f5f2dcc521cc53d3808eace782/transformers_v4.10/src/transformers/models/bert/modeling_bert.py#L544
To activate training with multi-dropout a couple of flags have to be set in the training script:
https://github.com/SAP-samples/acl2022-self-contrastive-decorrelation/blob/6824cffb99202b0eb6cdc5cad5eeede9f9da74e3/train.py#L430
The source code provided is compatible with version 4.10.0. Later versions should be pretty much identical in what needs to be adapted. In order to avoid complications, I recommend creating your existing environment, such that the modifications of transformer code have no effect on other projects (although, technically there should not be any issue). Information on cloning your environment with conda can be found [here](https://docs.conda.io/projects/conda/en/latest/user-guide/tasks/manage-environments.html).
5.1. Clone Hugging Face transformers v.4.10.0 to the folder 'scd_transformers'
```
git clone -b v4.10.0 https://github.com/huggingface/transformers.git scd_transformers
```
5.2. Copy the files from the scd/transformers_v4.10 folder to the corresponding folder in scd_transformers (you might want to make a backup of the files that overwritten in scd_transformers)
```
cp transformers_v4.10/src/transformers/models/bert/modeling_bert.py ~/scd_transformers/src/transformers/models/bert/
cp transformers_v4.10/src/transformers/models/roberta/modeling_roberta.py ~/scd_transformers/src/transformers/models/roberta/
```
5.3. Install transformers
```
cd scd_transformers
pip install -e .
```
## Training and Evaluation
1. Training BERT with settings as in paper
```
python train.py --do_train --load_best_model_at_end --fp16 --overwrite_output_dir --description=SCD --eval_steps=250 --evaluation_strategy=steps --hidden_dropout_prob=0.05 --hidden_dropout_prob_noise=0.155 --learning_rate=3e-05 --max_seq_length=32 --metric_for_best_model=sickr_spearman --model_name_or_path=bert-base-uncased --num_train_epochs=1 --output_dir=result --per_device_train_batch_size=192 --report_to=wandb --save_total_limit=0 --task_alpha=1 --task_beta=0.005225 --task_lambda=0.012 --temp=0.05 --train_file=data/wiki1m_for_simcse.txt
```
**Note**: If you want to use a language model that has a different embedding dimensionality as BERT-base-uncased/RoBERTa-base (=784), you also need to change the projector input dimensionality accordingly using the argument: ```--embedding_dim```
2. Convert model to Huggingface format
```
python scd_to_huggingface.py --path result/
```
3. Evaluate the model
```
python evaluation.py --pooler cls_before_pooler --task_set sts --mode test --model_name_or_path result/
```
or if you also want the transfer tasks to be evaluated (takes a bit of time)
```
python evaluation.py --pooler cls_before_pooler --task_set full --mode test --model_name_or_path result/
```
## Language Models
Language models trained for which the performance is reported in the paper are available at the [Huggingface Model Repository](https://huggingface.co/models):
- [BERT-base-uncased: sap-ai-research/BERT-base-uncased-SCD-ACL2022](https://huggingface.co/sap-ai-research/BERT-base-uncased-SCD-ACL2022)
- [RoBERTa-base: sap-ai-research/RoBERTa-base-SCD-ACL2022](https://huggingface.co/sap-ai-research/RoBERTa-base-SCD-ACL2022)
Loading the model in Python. Just place in the model name as indicated above, e.g., sap-ai-research/BERT-base-uncased-SCD-ACL2022.
```shell
tokenizer = AutoTokenizer.from_pretrained("sap-ai-research/<----Enter Model Name---->")
model = AutoModelWithLMHead.from_pretrained("sap-ai-research/<----Enter Model Name---->")
```
With these models one should be able to reproduce the results on the benchmarks are reported in the paper:
For BERT-base-uncased:
```shell
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
| STS12 | STS13 | STS14 | STS15 | STS16 | STSBenchmark | SICKRelatedness | Avg. |
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
| 66.94 | 78.03 | 69.89 | 78.73 | 76.23 | 76.30 | 73.18 | 74.19 |
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
+-------+-------+-------+-------+-------+-------+-------+-------+
| MR | CR | SUBJ | MPQA | SST2 | TREC | MRPC | Avg. |
+-------+-------+-------+-------+-------+-------+-------+-------+
| 79.26 | 84.85 | 93.57 | 89.13 | 85.23 | 83.60 | 74.84 | 84.35 |
+-------+-------+-------+-------+-------+-------+-------+-------+
```
For RoBERTa-base:
```shell
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
| STS12 | STS13 | STS14 | STS15 | STS16 | STSBenchmark | SICKRelatedness | Avg. |
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
| 63.53 | 77.79 | 69.79 | 80.21 | 77.29 | 76.55 | 72.10 | 73.89 |
+-------+-------+-------+-------+-------+--------------+-----------------+-------+
+-------+-------+-------+-------+-------+-------+-------+-------+
| MR | CR | SUBJ | MPQA | SST2 | TREC | MRPC | Avg. |
+-------+-------+-------+-------+-------+-------+-------+-------+
| 82.17 | 87.76 | 93.67 | 85.69 | 88.19 | 83.40 | 76.23 | 85.30 |
+-------+-------+-------+-------+-------+-------+-------+-------+
```
## Citations
If you use this code in your research or want to refer to our work, please cite:
```
@inproceedings{klein2022scd,
title={SCD: Self-Contrastive Decorrelation for Sentence Embeddings},
author = "Klein, Tassilo and
Nabi, Moin",
booktitle = "Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics",
month = may,
year = "2022",
publisher = "Association for Computational Linguistics (ACL)",
}
```
## How to obtain support
[Create an issue](https://github.com/SAP-samples//issues) in this repository if you find a bug or have questions about the content.
For additional support, [ask a question in SAP Community](https://answers.sap.com/questions/ask.html).
## Contributing
If you wish to contribute code, offer fixes or improvements, please send a pull request. Due to legal reasons, contributors will be asked to accept a DCO when they create the first pull request to this project. This happens in an automated fashion during the submission process. SAP uses [the standard DCO text of the Linux Foundation](https://developercertificate.org/).
## License
Copyright (c) 2022 SAP SE or an SAP affiliate company. All rights reserved. This project is licensed under the Apache Software License, version 2.0 except as noted otherwise in the [LICENSE](LICENSES/Apache-2.0.txt) file.