https://github.com/scambier/obsidian-text-extractor
A (companion) plugin to facilitate the extraction of text from images (OCR) and PDFs.
https://github.com/scambier/obsidian-text-extractor
obsidian obsidian-plugin ocr pdf
Last synced: 3 months ago
JSON representation
A (companion) plugin to facilitate the extraction of text from images (OCR) and PDFs.
- Host: GitHub
- URL: https://github.com/scambier/obsidian-text-extractor
- Owner: scambier
- License: gpl-3.0
- Created: 2022-12-20T15:11:27.000Z (over 2 years ago)
- Default Branch: master
- Last Pushed: 2024-07-15T16:50:57.000Z (12 months ago)
- Last Synced: 2024-10-15T07:32:09.292Z (9 months ago)
- Topics: obsidian, obsidian-plugin, ocr, pdf
- Language: TypeScript
- Homepage:
- Size: 342 KB
- Stars: 324
- Watchers: 9
- Forks: 16
- Open Issues: 19
-
Metadata Files:
- Readme: README.md
- Changelog: CHANGELOG.md
- License: LICENSE
Awesome Lists containing this project
README
# Obsidian Text Extractor
[](https://github.com/sponsors/scambier)




---
## ⭐ Looking for contributors ⭐
I unfortunately can't dedicate much time anymore on Text Extractor. It's mostly feature-complete, but there are many improvements and quality of life features that could be implemented.
You're more than welcome to submit PRs, and I will gladly help and mentor :)
> Note: **Text Extractor is NOT abandoned!** This project provides important features to Omnisearch, and I'll continue to support it with bugfixes, dependencies updates, and maybe quick & small features.
---
**Text Extractor** is a "companion" plugin. It's mainly useful when used in conjunction with other plugins (like [Omnisearch](https://github.com/scambier/obsidian-omnisearch)), but you can also use it to quickly extract texts from **images & PDFs**.
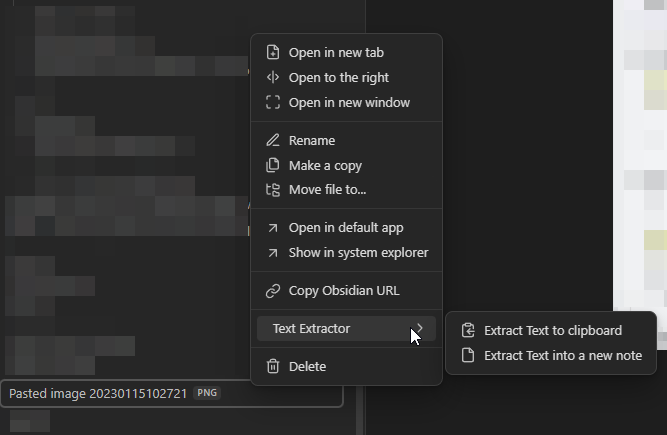
Supported files:
- Images (`.png`, `.jpg`, `.jpeg`, `.webp`, `.gif`, `.bmp`)
- PDFs (`.pdf`)
- Office documents (`.docx`, `.xlsx`)
### Limitations
- The plugin currently uses [Tesseract.js](https://tesseract.projectnaptha.com/) and [pdf-extract](https://github.com/jrmuizel/pdf-extract) to extract texts from images and PDFs. Those libraries are not perfect, and may not work on some files.
- **🟥 PDF files often fail to get their text extracted 🟥**. See [#7](https://github.com/scambier/obsidian-text-extractor/issues/7) and [#21](https://github.com/scambier/obsidian-text-extractor/discussions/21)
- **🟥 Text Extraction does not work on mobile 🟥**. Read the following section for more details.
- Text Extractor needs an Internet connection to work. All the processing is done locally, but the language files needed by the underlying OCR library (Tesseract) are downloaded on demand.
### Cache & Sync
The plugin caches the extracted texts as local small `.json` files inside the plugin directory. Those files can be synced between your devices. Since text extraction does not work on mobile, the plugin will use the synced cached texts if available. If not, an empty string will be returned.
## Installation
Text Extractor is available on the [Obsidian community plugins repository](https://obsidian.md/plugins?search=Text%20Extractor). You can also install it manually by downloading the latest release from the [releases page](https://github.com/scambier/obsidian-text-extractor/releases) or by using the [BRAT plugin manager](https://github.com/TfTHacker/obsidian42-brat).
## Why?
Text extraction is a useful feature, but it is not easy to implement, and consumes a lot of resources.
**With this plugin, I hope to provide a unified way to extract texts from images & PDFs, and make it available to other plugins.** This way, other plugins can use it without having to worry about the implementation details, and without having to needlessly consume resources.
## ⚠️ Work in progress
I'm [dogfooding](https://en.wikipedia.org/wiki/Eating_your_own_dog_food) this plugin with Omnisearch. The API functions likely won't change, but this is still a beta.
## Using Text Extractor as a dependency for your plugin
The exposed API:
```ts
// Add this type somewhere in your code
export type TextExtractorApi = {
extractText: (file: TFile) => Promise
canFileBeExtracted: (filePath: string) => boolean
isInCache: (file: TFile) => Promise
}
// Then, you can just use this function to get the API
export function getTextExtractor(): TextExtractorApi | undefined {
return (app as any).plugins?.plugins?.['text-extractor']?.api
}
// And use it like this
const text = await getTextExtractor()?.extractText(file)
```
Note that Text Extractor only extract texts _on demand_, when you call `extractText()` on a file, to avoid unnecessary resource consumption. Subsequent calls to `extractText()` will return the cached text.
## Development
While this plugin is first developed for Omnisearch, it's totally agnostic and I'd like it to become a community effort. If you wish to submit a PR, please open an issue first so we can discuss the feature.
The plugin is split in two parts:
- The text extraction library, which does the actual work
- The plugin itself, which is a wrapper around the library and exposes some useful options to the user
Each project is in its own folder, and has its own `package.json` and `node_modules`. The library uses Rollup (easier to setup with Wasm and web workers), while the plugin uses esbuild.