https://github.com/shashikg/whispers2t
An Optimized Speech-to-Text Pipeline for the Whisper Model Supporting Multiple Inference Engine
https://github.com/shashikg/whispers2t
asr deep-learning speech-recognition speech-to-text tensorrt tensorrt-llm vad voice-activity-detection whisper
Last synced: over 1 year ago
JSON representation
An Optimized Speech-to-Text Pipeline for the Whisper Model Supporting Multiple Inference Engine
- Host: GitHub
- URL: https://github.com/shashikg/whispers2t
- Owner: shashikg
- License: mit
- Created: 2023-12-16T18:09:16.000Z (over 2 years ago)
- Default Branch: main
- Last Pushed: 2024-08-27T04:34:15.000Z (almost 2 years ago)
- Last Synced: 2025-04-04T00:05:47.208Z (over 1 year ago)
- Topics: asr, deep-learning, speech-recognition, speech-to-text, tensorrt, tensorrt-llm, vad, voice-activity-detection, whisper
- Language: Jupyter Notebook
- Homepage:
- Size: 1.16 MB
- Stars: 382
- Watchers: 15
- Forks: 46
- Open Issues: 35
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
WhisperS2T ⚡
An Optimized Speech-to-Text Pipeline for the Whisper Model Supporting Multiple Inference Engine!




WhisperS2T is an optimized lightning-fast open-sourced **Speech-to-Text** (ASR) pipeline. It is tailored for the whisper model to provide faster whisper transcription. It's designed to be exceptionally fast than other implementation, boasting a **2.3X speed improvement over [WhisperX](https://github.com/m-bain/whisperX/tree/main) and a 3X speed boost compared to [HuggingFace Pipeline](https://huggingface.co/openai/whisper-large-v2) with FlashAttention 2 ([Insanely Fast Whisper](https://github.com/Vaibhavs10/insanely-fast-whisper))**. Moreover, it includes several heuristics to enhance transcription accuracy.
[**Whisper**](https://github.com/openai/whisper) is a general-purpose speech recognition model developed by OpenAI and not me. It is trained on a large dataset of diverse audio and is also a multitasking model that can perform multilingual speech recognition, speech translation, and language identification.
## Release Notes
* [Feb 25, 2024]: Added prebuilt docker images and transcript exporter to `txt, json, tsv, srt, vtt`. (Check complete [release note](https://github.com/shashikg/WhisperS2T/releases/tag/v1.3.1))
* [Jan 28, 2024]: Added support for TensorRT-LLM backend.
* [Dec 23, 2023]: Added support for word alignment for CTranslate2 backend (check [benchmark](https://github.com/shashikg/WhisperS2T/releases/tag/v1.2.0)).
* [Dec 19, 2023]: Added support for Whisper-Large-V3 and Distil-Whisper-Large-V2 (check [benchmark](https://github.com/shashikg/WhisperS2T/releases/tag/v1.1.0)).
* [Dec 17, 2023]: Released WhisperS2T!
## Quickstart
Checkout the Google Colab notebooks provided here: [notebooks](notebooks)
## Future Roadmaps
- [x] Ready to use docker container.
- [ ] WhisperS2T-Server: Optimized end-to-end deployment ready server codebase.
- [ ] In depth documentation, use github pages to host it.
- [ ] Explore possibility of integrating Meta's SeamlessM4T model.
- [ ] Add more datasets for WER benchmarking.
## Benchmark and Technical Report
Stay tuned for a technical report comparing WhisperS2T against other whisper pipelines. Meanwhile, check some quick benchmarks on A30 GPU. See `scripts/` directory for the benchmarking scripts that I used.
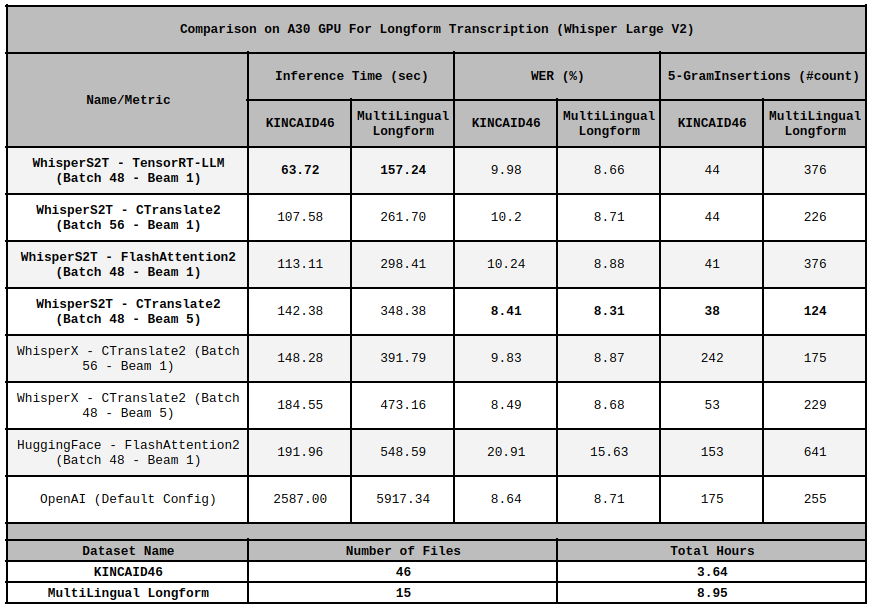
**NOTE:** I conducted all the benchmarks using the `without_timestamps` parameter set as `True`. Adjusting this parameter to `False` may enhance the Word Error Rate (WER) of the HuggingFace pipeline but at the expense of increased inference time. Notably, the improvements in inference speed were achieved solely through a **superior pipeline design**, without any specific optimization made to the backend inference engines (such as CTranslate2, FlashAttention2, etc.). For instance, WhisperS2T (utilizing FlashAttention2) demonstrates significantly superior inference speed compared to the HuggingFace pipeline (also using FlashAttention2), despite both leveraging the same inference engine—HuggingFace whisper model with FlashAttention2. Additionally, there is a noticeable difference in the WER as well.
## Features
- 🔄 **Multi-Backend Support:** Support for various Whisper model backends including Original OpenAI Model, HuggingFace Model with FlashAttention2, and CTranslate2 Model.
- 🎙️ **Easy Integration of Custom VAD Models:** Seamlessly add custom Voice Activity Detection (VAD) models to enhance control and accuracy in speech recognition.
- 🎧 **Effortless Handling of Small or Large Audio Files:** Intelligently batch smaller speech segments from various files, ensuring optimal performance.
- ⏳ **Streamlined Processing for Large Audio Files:** Asynchronously loads large audio files in the background while transcribing segmented batches, notably reducing loading times.
- 🌐 **Batching Support with Multiple Language/Task Decoding:** Decode multiple languages or perform both transcription and translation in a single batch for improved versatility and transcription time. (Best support with CTranslate2 backend)
- 🧠 **Reduction in Hallucination:** Optimized parameters and heuristics to decrease repeated text output or hallucinations. (Some heuristics works only with CTranslate2 backend)
- ⏱️ **Dynamic Time Length Support (Experimental):** Process variable-length inputs in a given input batch instead of fixed 30 seconds, providing flexibility and saving computation time during transcription. (Only with CTranslate2 backend)
## Getting Started
### From Docker Container
#### Prebuilt containers
```sh
docker pull shashikg/whisper_s2t:dev-trtllm
```
Dockerhub repo: [https://hub.docker.com/r/shashikg/whisper_s2t/tags](https://hub.docker.com/r/shashikg/whisper_s2t/tags)
#### Building your own container
Build from `main` branch.
```sh
docker build --build-arg WHISPER_S2T_VER=main --build-arg SKIP_TENSORRT_LLM=1 -t whisper_s2t:main .
```
Build from specific release `v1.3.0`.
```sh
git checkout v1.3.0
docker build --build-arg WHISPER_S2T_VER=v1.3.0 --build-arg SKIP_TENSORRT_LLM=1 -t whisper_s2t:1.3.0 .
```
To build the container with TensorRT-LLM support:
```sh
docker build --build-arg WHISPER_S2T_VER=main -t whisper_s2t:main-trtllm .
```
### Local Installation
Install audio packages required for resampling and loading audio files.
#### For Ubuntu
```sh
apt-get install -y libsndfile1 ffmpeg
```
#### For MAC
```sh
brew install ffmpeg
```
#### For Ubuntu/MAC/Windows/AnyOther With Conda for Python
```sh
conda install conda-forge::ffmpeg
```
To install or update to the latest released version of WhisperS2T use the following command:
```sh
pip install -U whisper-s2t
```
Or to install from latest commit in this repo:
```sh
pip install -U git+https://github.com/shashikg/WhisperS2T.git
```
**NOTE:** If your CUDNN and CUBLAS installation is done using pip wheel, you can run the following to add CUDNN path to `LD_LIBRARY_PATH`:
```sh
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:`python3 -c 'import os; import nvidia.cublas.lib; import nvidia.cudnn.lib; print(os.path.dirname(nvidia.cublas.lib.__file__) + ":" + os.path.dirname(nvidia.cudnn.lib.__file__))'`
```
**To use TensorRT-LLM Backend**
For TensortRT-LLM backend, you will need to install TensorRT and TensorRT-LLM.
```sh
bash /install_tensorrt.sh
```
For most of the debian system the given bash script should work, if it doesn't/other system please follow the official TensorRT-LLM instructions [here](https://github.com/NVIDIA/TensorRT-LLM/tree/main).
### Usage
#### CTranslate2 Backend
```py
import whisper_s2t
model = whisper_s2t.load_model(model_identifier="large-v2", backend='CTranslate2')
files = ['data/KINCAID46/audio/1.wav']
lang_codes = ['en']
tasks = ['transcribe']
initial_prompts = [None]
out = model.transcribe_with_vad(files,
lang_codes=lang_codes,
tasks=tasks,
initial_prompts=initial_prompts,
batch_size=32)
print(out[0][0]) # Print first utterance for first file
"""
[Console Output]
{'text': "Let's bring in Phil Mackie who is there at the palace. We're looking at Teresa and Philip May. Philip, can you see how he's being transferred from the helicopters? It looks like, as you said, the beast. It's got its headlights on because the sun is beginning to set now, certainly sinking behind some clouds. It's about a quarter of a mile away down the Grand Drive",
'avg_logprob': -0.25426941679184695,
'no_speech_prob': 8.147954940795898e-05,
'start_time': 0.0,
'end_time': 24.8}
"""
```
To use word alignment load the model using this:
```py
model = whisper_s2t.load_model("large-v2", asr_options={'word_timestamps': True})
```
#### TensorRT-LLM Backend
```py
import whisper_s2t
model = whisper_s2t.load_model(model_identifier="large-v2", backend='TensorRT-LLM')
files = ['data/KINCAID46/audio/1.wav']
lang_codes = ['en']
tasks = ['transcribe']
initial_prompts = [None]
out = model.transcribe_with_vad(files,
lang_codes=lang_codes,
tasks=tasks,
initial_prompts=initial_prompts,
batch_size=24)
print(out[0][0]) # Print first utterance for first file
"""
[Console Output]
{'text': "Let's bring in Phil Mackie who is there at the palace. We're looking at Teresa and Philip May. Philip, can you see how he's being transferred from the helicopters? It looks like, as you said, the beast. It's got its headlights on because the sun is beginning to set now, certainly sinking behind some clouds. It's about a quarter of a mile away down the Grand Drive",
'start_time': 0.0,
'end_time': 24.8}
"""
```
Check this [Documentation](docs.md) for more details.
**NOTE:** For first run the model may give slightly slower inference speed. After 1-2 runs it will give better inference speed. This is due to the JIT tracing of the VAD model.
## Acknowledgements
- [**OpenAI Whisper Team**](https://github.com/openai/whisper): Thanks to the OpenAI Whisper Team for open-sourcing the whisper model.
- [**HuggingFace Team**](https://huggingface.co/docs/transformers/model_doc/whisper): Thanks to the HuggingFace Team for their integration of FlashAttention2 and the Whisper model in the transformers library.
- [**CTranslate2 Team**](https://github.com/OpenNMT/CTranslate2/): Thanks to the CTranslate2 Team for providing a faster inference engine for Transformers architecture.
- [**NVIDIA NeMo Team**](https://github.com/NVIDIA/NeMo): Thanks to the NVIDIA NeMo Team for their contribution of the open-source VAD model used in this pipeline.
- [**NVIDIA TensorRT-LLM Team**](https://github.com/NVIDIA/TensorRT-LLM/): Thanks to the NVIDIA TensorRT-LLM Team for their awesome LLM inference optimizations.
## License
This project is licensed under MIT License - see the [LICENSE](LICENSE) file for details.