https://github.com/shrut2702/upasak
UI-based Fine-Tuning for Large Language Models (LLMs)
https://github.com/shrut2702/upasak
gemma gemma3 largelanguagemodels llm llm-training nlp no-code-framework open-source pii-detection transformers
Last synced: 8 days ago
JSON representation
UI-based Fine-Tuning for Large Language Models (LLMs)
- Host: GitHub
- URL: https://github.com/shrut2702/upasak
- Owner: shrut2702
- License: mit
- Created: 2025-12-03T19:23:06.000Z (6 months ago)
- Default Branch: main
- Last Pushed: 2025-12-04T17:51:51.000Z (6 months ago)
- Last Synced: 2026-05-03T06:12:31.247Z (about 1 month ago)
- Topics: gemma, gemma3, largelanguagemodels, llm, llm-training, nlp, no-code-framework, open-source, pii-detection, transformers
- Language: Python
- Homepage:
- Size: 483 KB
- Stars: 20
- Watchers: 1
- Forks: 1
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
- Roadmap: ROADMAP.md
Awesome Lists containing this project
README
# Upasak - UI-based Fine-Tuning for Large Language Models (LLMs)
**Upasak** is a flexible, mindful to privacy, no-code/low-code framework for fine-tuning large language models, built around [Hugging Face Transformers](https://huggingface.co/docs/transformers/en/index).
It features an easy-to-use Streamlit-based interface, multi-format dataset support, built-in PII and sensitive information sanitization, and a customizable training process.
Whether you're experimenting, researching, or performing internal fine-tuning tasks, Upasak makes it easily accessible and compliant.



## **Key Features**
### **LLM Fine-Tuning**
* Developed on top of Hugging Face's Transformers library.
* Supports Text-only models of Gemma-3 LLM family for instruction-tuning or domain adaptation.
* Full-parameter fine-tuning or LoRA (Parameter-Efficient Fine-Tuning).
* Future support planned for image-text-to-text Gemma-3 models, LLaMA, Qwen, Phi, Mixtral.
### **Flexible Dataset Handling**
Upload or import datasets in multiple file formats:
* `.json`
* `.jsonl`
* `.csv`
* `.zip` (containing `.txt`)
Or select datasets directly from the **Hugging Face Hub**.
### **Auto-Detection of Dataset Schema**
Upasak intelligently identifies and structures your dataset into training-ready format.
Supported schemas:
| Schema | Format | Notes |
| ------------------- | -------------------------------------------------- | ------------------------------------------- |
| **DAPT** | `[{"text":"..."}]` or `text` column | Document Adaptation / continued pretraining |
| **ALPACA** | `[{"instruction":"...", "output":"..."}]` (+ optional `"input"`) or `instruction`, `output`, `input` (optional) columns | Converted to user → assistant turns |
| **CHATML** | `[{"messages":[{"role":"...", "content":"..."}]}]` or `messages` column | Supports role/content pairs |
| **SHARE_GPT** | `[{"conversations":[{"from":"...", "value":"..."}]}]` or `conversations` column | Converts human ↔ model to user ↔ assistant |
| **PROMPT_RESPONSE** | `[{"prompt":"...", "response":"..."}]` or `prompt`, `response` columns | Simple instruction → answer |
| **QA** | `[{"question":"", "answer":""}]` or `question`, `answer` columns | Q&A format |
| **QLA** | `[{"question":"...", "long_answer":"..."}]` or `question`, `long_answer` columns | Long-form generation |
### **Built-In PII & Sensitive Information Sanitization**
Upasak ensures privacy compliance by:
* Automatically detecting and redacting/masking PII
* Using placeholder tokens to preserve dataset utility
* Offering AI-assisted detection with manual review loops, which uses [GLiNER](https://huggingface.co/urchade/gliner_multi_pii-v1) (Named Entity Recognition) model.
* Logging sanitization results for auditability
Upasak automatically detects and redacts:
* Personal names
* Emails / phone numbers
* IP addresses, IMEI
* Credit card / bank details
* National IDs (Aadhaar, PAN, Voter ID)
* API keys
* GitHub/GitLab tokens
* Database credentials
* Residential & workplace addresses
Two sanitization modes:
1. **Rule-Based** (default)
2. **Hybrid (Rule-Based + NER-based)**
* Optional human review
* Configure HITL ratio & max samples for human review
* Accept/reject uncertain detections directly in the UI
* Preview sanitized sample before training
---
## **Streamlit UI – No-Code Training Workflow**
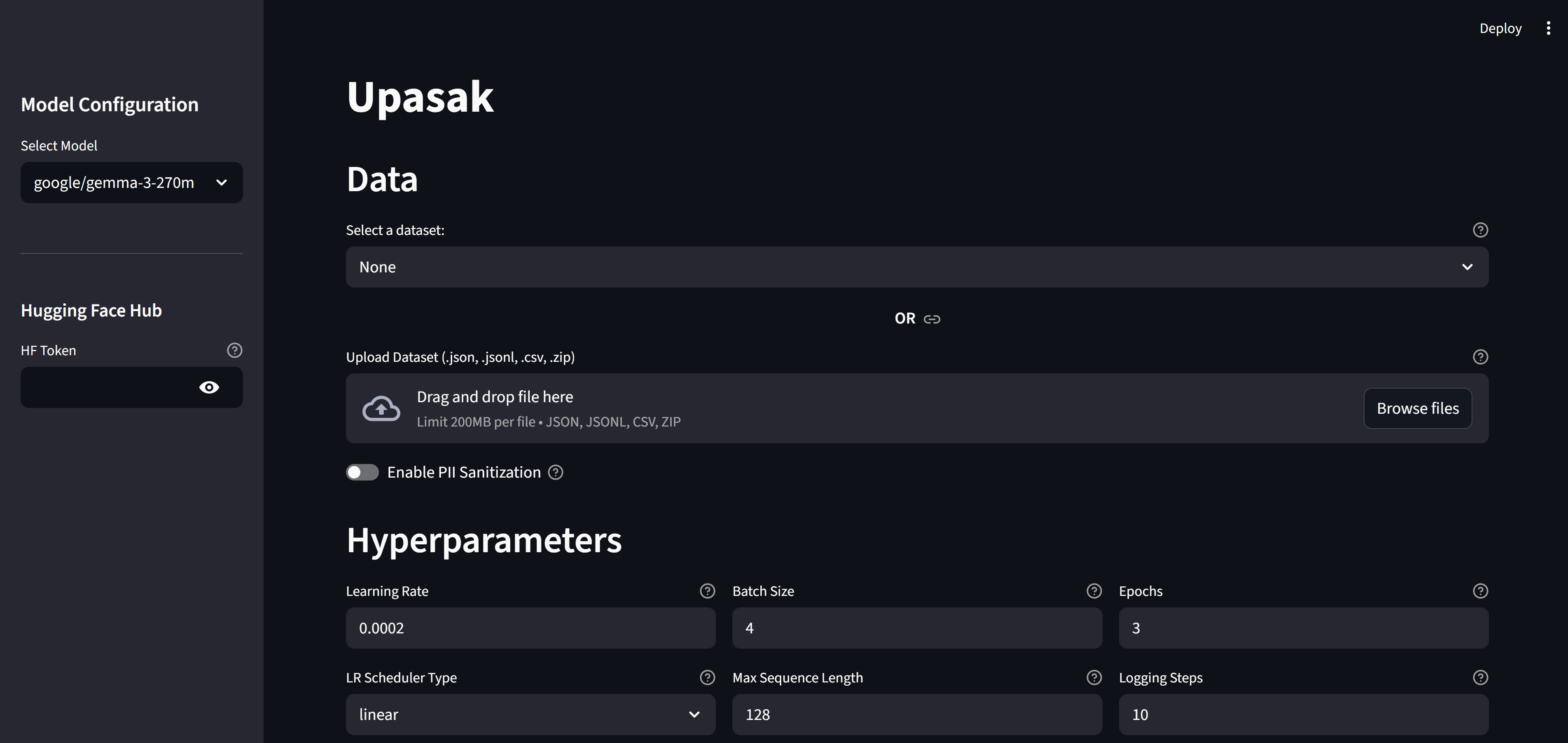
The visual interface provides fully interactive control:
### **1. Model Selection**
Choose supported base models (currently Gemma-3 text-only).
Future updates will include LLaMA, Mixtral, Phi, Qwen and multimodal variants.
### **2. HF Token Handling**
* Read token for pulling models
* Write token for pushing fine-tuned models back to HF Hub
### **3. Dataset Input**
* Upload dataset files
* Or load from Hugging Face dataset list
### **4. PII Sanitization Panel**
* Enable/disable sanitization
* Select detection method (rule-based / hybrid)
* Enable Human Review & configure ratios
* View uncertain detections and choose actions
* Preview sanitized sample before training
### **5. Hyperparameter Controls**
#### **Basic Hyperparameters**
* Learning rate
* Batch size
* Epochs
* Max sequence length
* Logging steps
* LR scheduler
#### **Advanced Hyperparameters**
* Gradient accumulation
* Gradient clipping
* LR warmup ratio
* Weight decay
* Checkpoint save strategy
* Evaluation strategy + steps
* Validation split
* Model tracker platform (Comet / WandB / none)
* Tracker API keys
### **6. LoRA Configuration**
* LoRA rank
* LoRA alpha
* LoRA dropout
* Target modules
* Optional merging of LoRA adapters
### **7. Training Control**
* Start / Stop training
* Live training metrics inside the app:
* Training loss
* Validation loss
* Token-level curves
* Optional external tracking (Comet / WandB)
### **8. Inference Script Generation**
After training completes, Upasak automatically generates a customized inference.py script tailored to your training configuration.
* **LoRA support** – Handles both scenarios:
* **LoRA + merged adapters** – Loads the fully merged model.
* **LoRA + unmerged adapters** – Loads base model + applies LoRA adapters at runtime.
* **Full fine-tune** – Standard model loading
* **Ready to use** - Access it in your output directory
**Usage**
```bash
cd path_to_output_dir
python inference.py
```
### **9. Export & Push**
* Output directory for checkpoints, final model, and merged model
* Push to HF Hub (when write-enabled token is provided)
---
# **Installation**
### **Install from PyPI (recommended)**
```bash
pip install upasak
```
### **Or install from source**
```bash
# Clone this repo
git clone https://github.com/shrut2702/upasak
cd upasak
```
```bash
# optional
## For Windows
python -m venv vir_env
./vir_env/scripts/activate
## For macOS
python -m venv vir_env
source vir_env/bin/activate
```
```bash
# Install required dependencies
pip install -r requirements.txt
```
---
## **Usage**
Upasak is used as a Python-triggered Streamlit app.
### **After installing the package:**
#### **1. Create a Python launcher file**
For example: `run_upasak.py`
```python
from upasak import main
if __name__ == "__main__":
main()
```
#### **2. Launch the Streamlit application**
```bash
streamlit run run_upasak.py
```
or
```bash
streamlit run run_upasak.py --server.maxUploadSize=1024 # for configuring upload file size limit in MB
```
This opens the Upasak UI in your browser.
### **After installing from source**
#### **1. Launch `app.py`**
```bash
streamlit run app.py
```
or
```bash
streamlit run app.py --server.maxUploadSize=1024 # for configuring upload file size limit in MB
```
### **Reusability of Upasak Modules**
Although Upasak provides a full end-to-end UI, **every internal component is designed to be reusable in isolation**.
You can import and use modules such as:
* `TokenizerWrapper` → standalone tokenization
* `TrainingEngine` + `TrainerConfig` → run full or LoRA fine-tuning programmatically
* `PIISanitizer` → rule-based or hybrid PII detection/sanitization
You can refer to [examples](https://github.com/shrut2702/upasak/tree/f4252b2e2072aad9e878005108abc564d8b670a0/examples) to more details.
This allows you to integrate Upasak **directly into custom pipelines**, backend services, notebooks, or data-processing workflows — **without launching the Streamlit UI**.
---
# **Use Cases**
* Educational fine-tuning demonstrations
* Rapid prototyping in quick-shipping environments
* Dataset preparation and anonymization workflows
* Internal LLM finetuning on sensitive or regulated data
* Developers with no domain expertise who wants LLM in their application
---
# **Contributing**
Contributions are welcome!
Please open an issue or submit a pull request for bug fixes, features, documentation, or dataset schema support.
---
# **Support**
For issues, questions, or feature requests:
Create a GitHub issue in this repository.
---