https://github.com/shubhamahobia/lstm-hamlet
The LSTM Next Word Prediction project trains a model on Hamlet to predict the next word in a sequence. After preprocessing the text, an LSTM network learns patterns in the language. The trained model can then generate text by predicting the next word in a given sequence, with its accuracy evaluated to ensure it effectively models the language.
https://github.com/shubhamahobia/lstm-hamlet
deep-learning github hamlet lstm lstm-neural-network lstm-neural-networks machine-learning neural-network nltk numpy pandas pickle python
Last synced: 3 months ago
JSON representation
The LSTM Next Word Prediction project trains a model on Hamlet to predict the next word in a sequence. After preprocessing the text, an LSTM network learns patterns in the language. The trained model can then generate text by predicting the next word in a given sequence, with its accuracy evaluated to ensure it effectively models the language.
- Host: GitHub
- URL: https://github.com/shubhamahobia/lstm-hamlet
- Owner: ShubhaMahobia
- Created: 2024-08-26T09:32:37.000Z (almost 2 years ago)
- Default Branch: main
- Last Pushed: 2024-08-26T09:41:53.000Z (almost 2 years ago)
- Last Synced: 2024-11-07T05:12:47.546Z (over 1 year ago)
- Topics: deep-learning, github, hamlet, lstm, lstm-neural-network, lstm-neural-networks, machine-learning, neural-network, nltk, numpy, pandas, pickle, python
- Language: Jupyter Notebook
- Homepage: https://lstm-hamlet-ntk6xvyx48gfumb2aurksb.streamlit.app/
- Size: 12.6 MB
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
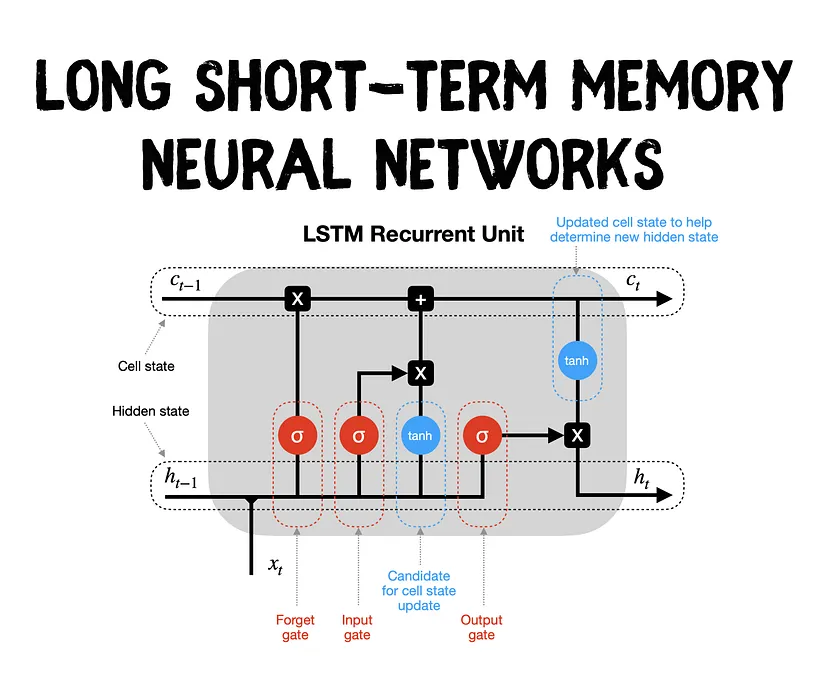
# LSTM - Neural Network - Hamlet Dataset
The LSTM Next Word Prediction project trained on the Hamlet dataset involves building a deep learning model that predicts the next word in a sequence of text. The project typically follows these steps:
1. Data Preprocessing: The text of Shakespeare's Hamlet is cleaned and processed, converting it into a sequence of tokens (words). The text is then split into input-output pairs, where the input is a sequence of words, and the output is the next word in the sequence.
2. Model Architecture: A Long Short-Term Memory (LSTM) network, which is a type of Recurrent Neural Network (RNN), is used due to its ability to learn long-term dependencies in sequential data. The LSTM model is typically designed with an embedding layer, followed by one or more LSTM layers, and a dense output layer with a softmax activation to predict the probability distribution of the next word.
3. Training: The model is trained on the Hamlet text, with the goal of minimizing the loss, typically using categorical cross-entropy. The training process involves feeding sequences of words into the model and adjusting the weights to improve the accuracy of the next word prediction.
4. Prediction: Once trained, the model can generate text by predicting the next word in a sequence. Given a starting phrase or sequence of words from Hamlet, the model predicts the most likely next word, which can then be fed back into the model to generate further text.
5. Evaluation: The model's performance is evaluated based on its accuracy in predicting the correct next word in the sequence. Metrics like perplexity might be used to assess the model's efficiency in language modeling tasks.
This project showcases how LSTM networks can be applied to natural language processing tasks, specifically for generating text and predicting sequences based on historical data.
## Live Deployment
This project is hosted on - https://lstm-hamlet-ntk6xvyx48gfumb2aurksb.streamlit.app/
## Run Locally
1. Clone this repo into your system.
2. Create virtual environment using the command -
```bash
conda create -p myenv python==3.9.0
```
3. Now install all the packages which are listed in requirements.txt
```bash
pip install -r requirements.txt
```
4. Now run all the cell in the Experiments.ipynb And Prediction.ipynb as per your need.
5. To run on streamlit -
```bash
streamlit run app.py
```
## Tech Stack
**Frontend Client:** Streamlit Services
**Model Used:** RNN-LSTM (Long Short Term Memory) Neural Network
**Dataset Used:** NLTK Hamlet Dataset
## Feedback
If you have any feedback or just to say Hi!, please reach out to me at mahobiashubham4@gmail.com