https://github.com/shyamsn97/hyper-nn
Easy Hypernetworks in Pytorch and Jax
https://github.com/shyamsn97/hyper-nn
flax hypernetworks jax machine-learning neural-networks pytorch
Last synced: 11 months ago
JSON representation
Easy Hypernetworks in Pytorch and Jax
- Host: GitHub
- URL: https://github.com/shyamsn97/hyper-nn
- Owner: shyamsn97
- License: mit
- Created: 2022-03-01T21:19:56.000Z (over 4 years ago)
- Default Branch: main
- Last Pushed: 2023-01-27T00:22:39.000Z (over 3 years ago)
- Last Synced: 2024-12-09T18:48:07.823Z (over 1 year ago)
- Topics: flax, hypernetworks, jax, machine-learning, neural-networks, pytorch
- Language: Jupyter Notebook
- Homepage:
- Size: 10.4 MB
- Stars: 96
- Watchers: 4
- Forks: 6
- Open Issues: 2
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# hyper-nn -- Easy Hypernetworks in Pytorch and Flax
[](https://pypi.org/project/hyper-nn)
**Note: This library is experimental and currently under development - the flax implementations in particular are far from perfect and can be improved. If you have any suggestions on how to improve this library, please open a github issue or feel free to reach out directly!**
`hyper-nn` gives users with the ability to create easily customizable [Hypernetworks](https://arxiv.org/abs/1609.09106) for almost any generic `torch.nn.Module` from [Pytorch](https://pytorch.org/docs/stable/generated/torch.nn.Module.html) and `flax.linen.Module` from [Flax](https://flax.readthedocs.io/en/latest/flax.linen.html). Our Hypernetwork objects are also `torch.nn.Modules` and `flax.linen.Modules`, allowing for easy integration with existing systems. For Pytorch, we make use of the amazing library [`functorch`](https://github.com/pytorch/functorch)
Generating Policy Weights for Lunar Lander

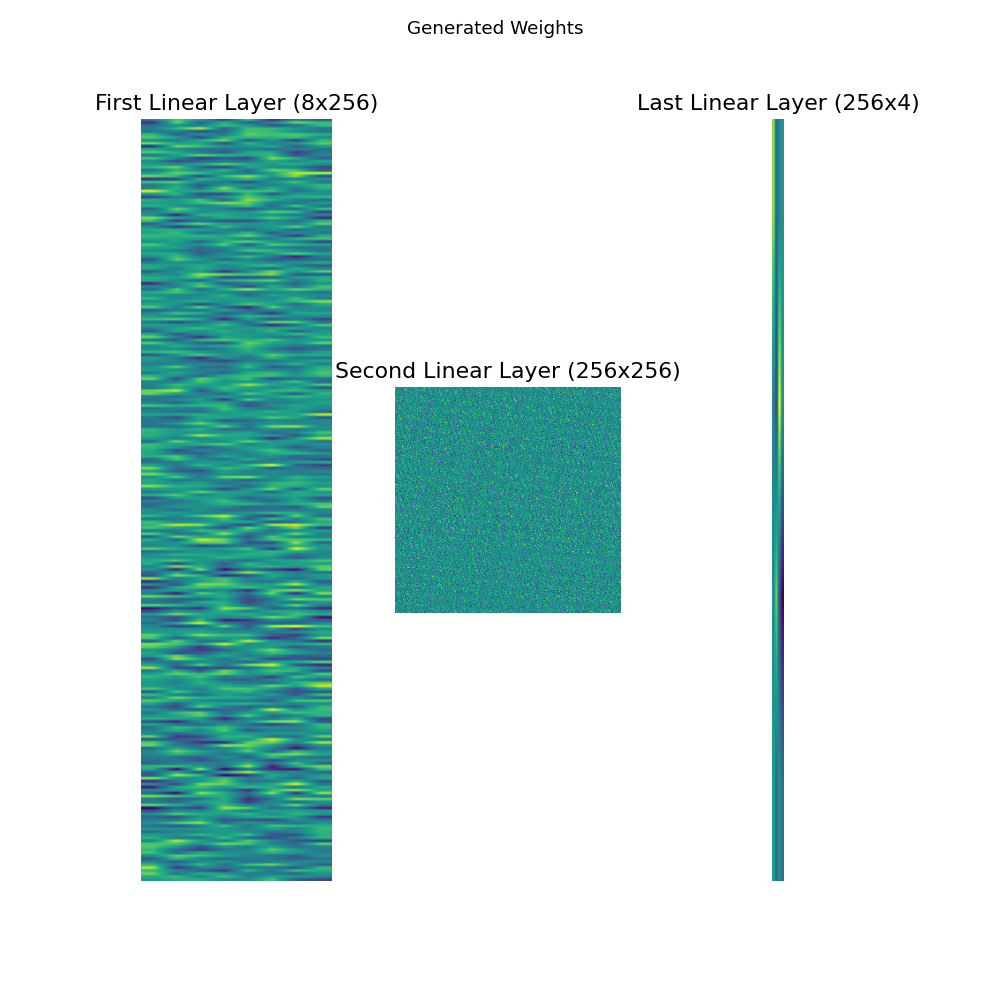
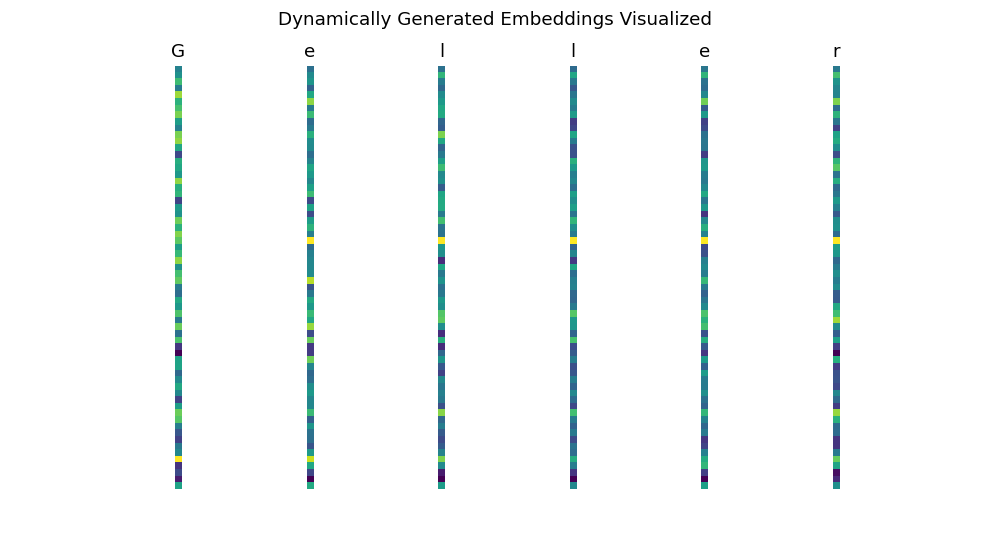
Dynamic Weights for each character in a name generator
---
## Install
`hyper-nn` tested on python 3.8+
#### Installing with pip
```bash
$ pip install hyper-nn
```
#### Installing from source
```bash
$ git clone git@github.com:shyamsn97/hyper-nn.git
$ cd hyper-nn
$ python setup.py install
```
For gpu functionality with Jax, you will need to follow the instructions [here](https://github.com/google/jax#installation)
---
## What are Hypernetworks?
[Hypernetworks](https://arxiv.org/abs/1609.09106), simply put, are neural networks that generate parameters for another neural network. They can be incredibly powerful, being able to represent large networks while using only a fraction of their parameters.
Hypernetworks generally come in two variants, static or dynamic. Static Hypernetworks have a fixed or learned embedding and weight generator that outputs the target networks’ weights deterministically. Dynamic Hypernetworks instead receive inputs and use them to generate dynamic weights.

`hyper-nn` allows you to design Hypernetworks with flexibility and ease, all you have to do is implement the `generate_params` method, which outputs a parameter vector. We also include basic versions of this, composed of two linear components:
- `embedding_module` that holds information about layers(s) in the target network, or more generally a chunk of the target networks weights. By default this outputs a matrix of size `num_embeddings x embedding_dim`
- `weight_generator`, which takes in the embedding and outputs a flat parameter vector for the target network. By default this module outputs chunks in the size of `weight_chunk_dim`, which is calculated automatically as `num_target_parameters // num_embeddings`.
Both `embedding_module` and `weight_generator` are represented as `torch.nn.Module` and `flax.linen.Module` objects. a `Module` can be passed in as `custom_embedding_module` or `custom_weight_generator`, or it can be defined in the methods `make_embedding_module` or `make_weight_generator`.
The `generate_params` method feeds the output from `embedding_module` into `weight_generator` to output the target parameters.
The `forward` method takes in a list of inputs and uses the generated parameters to calculate the output. This method acts as the main method for both jax and torch hypernetworks
### [Torch Hypernetwork](hypernn/torch/hypernet.py#L81)
```python
...
def make_embedding_module(self) -> nn.Module:
return nn.Embedding(self.num_embeddings, self.embedding_dim)
def make_weight_generator(self) -> nn.Module:
return nn.Linear(self.embedding_dim, self.weight_chunk_dim)
def generate_params(self, *args, **kwargs) -> Tuple[torch.Tensor, Dict[str, Any]]:
embedding = self.embedding_module(
torch.arange(self.num_embeddings, device=self.device)
)
generated_params = self.weight_generator(embedding).view(-1)
return generated_params, {"embedding": embedding}
def target_forward(
self,
*args,
generated_params: torch.Tensor,
assert_parameter_shapes: bool = True,
**kwargs,
) -> torch.Tensor:
if assert_parameter_shapes:
self.assert_parameter_shapes(generated_params)
return self.target_network(generated_params, *args, **kwargs)
def forward(
self,
*args,
generated_params: Optional[torch.Tensor] = None,
has_aux: bool = False,
assert_parameter_shapes: bool = True,
generate_params_kwargs: Dict[str, Any] = {},
**kwargs,
):
"""
Main method for creating / using generated parameters and passing in input into the target network
Args:
generated_params (Optional[torch.Tensor], optional): Generated parameters of the target network. If not provided, the hypernetwork will generate the parameters. Defaults to None.
has_aux (bool, optional): If True, return the auxiliary output from generate_params method. Defaults to False.
assert_parameter_shapes (bool, optional): If True, raise an error if generated_params does not have shape (num_target_parameters,). Defaults to True.
generate_params_kwargs (Dict[str, Any], optional): kwargs to be passed to generate_params method
*args, *kwargs, arguments to be passed into the target network (also gets passed into generate_params)
Returns:
output (torch.Tensor) | (torch.Tensor, Dict[str, torch.Tensor]): returns output from target network and optionally auxiliary output.
"""
aux_output = {}
if generated_params is None:
generated_params, aux_output = self.generate_params(
*args, **kwargs, **generate_params_kwargs
)
if has_aux:
return (
self.target_forward(
*args,
generated_params=generated_params,
assert_parameter_shapes=assert_parameter_shapes,
**kwargs,
),
generated_params,
aux_output,
)
return self.target_forward(
*args,
generated_params=generated_params,
assert_parameter_shapes=assert_parameter_shapes,
**kwargs,
)
...
```
### [Flax Hypernetwork](hypernn/jax/hypernet.py#L76)
```python
...
def make_embedding_module(self):
return nn.Embed(
self.num_embeddings,
self.embedding_dim,
embedding_init=jax.nn.initializers.uniform(),
)
def make_weight_generator(self):
return nn.Dense(self.weight_chunk_dim)
def generate_params(self, *args, **kwargs) -> Tuple[jnp.array, Dict[str, Any]]:
embedding = self.embedding_module(jnp.arange(0, self.num_embeddings))
generated_params = self.weight_generator(embedding).reshape(-1)
return generated_params, {"embedding": embedding}
def target_forward(
self,
*args,
generated_params: jnp.array,
assert_parameter_shapes: bool = True,
**kwargs,
) -> jnp.array:
if assert_parameter_shapes:
self.assert_parameter_shapes(generated_params)
param_tree = create_param_tree(
generated_params, self.target_weight_shapes, self.target_treedef
)
return self.target_network.apply(param_tree, *args, **kwargs)
def forward(
self,
*args,
generated_params: Optional[jnp.array] = None,
has_aux: bool = False,
assert_parameter_shapes: bool = True,
generate_params_kwargs: Dict[str, Any] = {},
**kwargs,
) -> Tuple[jnp.array, List[jnp.array]]:
"""
Main method for creating / using generated parameters and passing in input into the target network
Args:
generated_params (Optional[jnp.array], optional): Generated parameters of the target network. If not provided, the hypernetwork will generate the parameters. Defaults to None.
has_aux (bool, optional): If True, return the auxiliary output from generate_params method. Defaults to False.
assert_parameter_shapes (bool, optional): If True, raise an error if generated_params does not have shape (num_target_parameters,). Defaults to True.
generate_params_kwargs (Dict[str, Any], optional): kwargs to be passed to generate_params method
Returns:
output (torch.Tensor) | (jnp.array, Dict[str, jnp.array]): returns output from target network and optionally auxiliary output.
"""
aux_output = {}
if generated_params is None:
generated_params, aux_output = self.generate_params(
*args, **kwargs, **generate_params_kwargs
)
if has_aux:
return (
self.target_forward(
*args,
generated_params=generated_params,
assert_parameter_shapes=assert_parameter_shapes,
**kwargs,
),
generated_params,
aux_output,
)
return self.target_forward(
*args,
generated_params=generated_params,
assert_parameter_shapes=assert_parameter_shapes,
**kwargs,
)
...
```
---
## Quick Usage
for detailed examples see [notebooks](notebooks/)
- [Generating weights for a CNN on MNIST](notebooks/mnist/)
- [Lunar Lander Reinforce (Vanilla Policy Gradient)](notebooks/reinforce/)
- [Dynamic Hypernetworks for name generation](notebooks/dynamic_hypernetworks/)
The main classes to use are `TorchHyperNetwork` and `JaxHyperNetwork` and those that inherit them. Instead of constructing them directly, use the `from_target` method, shown below. After this you can use the hypernetwork exactly like any other `nn.Module`!
`hyper-nn` also makes it easy to create Dynamic Hypernetworks that use inputs to create target weights. Basic implementations (both < 100 lines) are provided with `JaxDynamicHyperNetwork` and `TorchDynamicHyperNetwork`, which use an rnn and current input to generate weights.
To create hypernetworks, its easier to use the `from_target` method instead of instantiating it directly because some parameters are calculated automatically for you.
### Pytorch
```python
import torch
import torch.nn as nn
from hypernn.torch import TorchHyperNetwork, TorchLinearHyperNetwork, TorchDynamicHyperNetwork
# any module
target_network = nn.Sequential(
nn.Linear(32, 64),
nn.ReLU(),
nn.Linear(64, 32)
)
EMBEDDING_DIM = 4
NUM_EMBEDDINGS = 32
hypernetwork = TorchLinearHyperNetwork(
target_network = target_network,
embedding_dim = EMBEDDING_DIM,
num_embeddings = NUM_EMBEDDINGS
)
# now we can use the hypernetwork like any other nn.Module
inp = torch.zeros((1, 32))
# by default we only output what we'd expect from the target network
output = hypernetwork(inp)
# return aux_output
output, generated_params, aux_output = hypernetwork(inp, has_aux=True)
# generate params separately
generated_params, aux_output = hypernetwork.generate_params()
output = hypernetwork(inp, generated_params=generated_params)
### Dynamic Hypernetwork
dynamic_hypernetwork = TorchDynamicHyperNetwork(
input_dim = 32,
target_network = target_network,
embedding_dim = EMBEDDING_DIM,
num_embeddings = NUM_EMBEDDINGS
)
output = dynamic_hypernetwork(inp, generate_params_kwargs=dict(x=inp))
# by default we only output what we'd expect from the target network
output = dynamic_hypernetwork(inp, generate_params_kwargs=dict(x=inp, hidden_state=torch.zeros((1,32))))
```
### Jax
```python
import flax.linen as nn
import jax.numpy as jnp
from jax import random
from hypernn.jax import JaxHyperNetwork, JaxLinearHyperNetwork, JaxDynamicHyperNetwork
# any module
target_network = nn.Sequential(
[
nn.Dense(64),
nn.relu,
nn.Dense(32)
]
)
EMBEDDING_DIM = 4
NUM_EMBEDDINGS = 32
hypernetwork = JaxLinearHyperNetwork.from_target(
target_network = target_network,
embedding_dim = EMBEDDING_DIM,
num_embeddings = NUM_EMBEDDINGS,
inputs=jnp.zeros((1, 32)) # jax needs this to initialize target weights
)
# now we can use the hypernetwork like any other nn.Module
inp = jnp.zeros((1, 32))
key = random.PRNGKey(0)
hypernetwork_params = hypernetwork.init(key, inp) # flax needs to initialize hypernetwork parameters first
# by default we only output what we'd expect from the target network
output = hypernetwork.apply(hypernetwork_params, inp)
# return aux_output
output, generated_params, aux_output = hypernetwork.apply(hypernetwork_params, inp, has_aux=True)
# generate params separately
generated_params, aux_output = hypernetwork.apply(hypernetwork_params, method=hypernetwork.generate_params)
output = hypernetwork.apply(hypernetwork_params, inp, generated_params=generated_params)
### Dynamic Hypernetwork
dynamic_hypernetwork = JaxDynamicHyperNetwork.from_target(
input_dim = 32,
target_network = target_network,
embedding_dim = EMBEDDING_DIM,
num_embeddings = NUM_EMBEDDINGS,
inputs=jnp.zeros((1, 32)) # jax needs this to initialize target weights
)
dynamic_hypernetwork_params = dynamic_hypernetwork.init(key, inp, generate_params_kwargs=dict(x=inp, hidden_state=jnp.zeros((1,32)))) # flax needs to initialize hypernetwork parameters first
# by default we only output what we'd expect from the target network
output = dynamic_hypernetwork.apply(dynamic_hypernetwork_params, inp, generate_params_kwargs=dict(x=inp, hidden_state=jnp.zeros((1,32))))
# by default we only output what we'd expect from the target network
output = dynamic_hypernetwork.apply(dynamic_hypernetwork_params, inp, generate_params_kwargs=dict(x=inp, hidden_state=jnp.zeros((1,32))))
```
## Customizing Hypernetworks
`hyper-nn` makes it easy to customize and create more complex hypernetworks.
The main components to modify are the methods `generate_params`. This allows for complete control over how the hypernetwork generates parameters
For example, here we extend the linear hypernetwork which uses components `embedding_module` and `weight_generator`. We implement a hypernetwork that could be useful in a multi task setting, where a one hot encoded class embedding is concatenated to every row in the embedding matrix outputted by the `embedding_module`. In addition, we override both our `make_embedding_module` and `make_weight_generator` methods to output customized modules. This whole class implementation is under 50 lines of code!
```python
from typing import Optional, Iterable, Any, Tuple, Dict
import torch
import torch.nn as nn
# static hypernetwork
from hypernn.torch import TorchHyperNetwork
from hypernn.torch.utils import get_weight_chunk_dims
class MultiTaskHypernetwork(TorchHyperNetwork):
def __init__(
self,
num_tasks: int,
target_network: nn.Module,
num_target_parameters: Optional[int] = None,
embedding_dim: int = 100,
num_embeddings: int = 3,
weight_chunk_dim: Optional[int] = None,
):
super().__init__(
target_network = target_network,
num_target_parameters = num_target_parameters,
)
self.num_tasks = num_tasks
self.embedding_dim = embedding_dim
self.num_embeddings = num_embeddings
self.weight_chunk_dim = weight_chunk_dim
if weight_chunk_dim is None:
self.weight_chunk_dim = get_weight_chunk_dims(
self.num_target_parameters, num_embeddings
)
self.embedding_module = self.make_embedding_module()
self.weight_generator = self.make_weight_generator()
def make_embedding_module(self) -> nn.Module:
embedding = nn.Embedding(self.num_embeddings, 8)
return nn.Sequential(
embedding,
nn.Tanh(),
nn.Linear(8, self.embedding_dim),
nn.Tanh(),
)
def make_weight_generator(self) -> nn.Module:
return nn.Sequential(
nn.Linear(self.embedding_dim + self.num_tasks, 32),
nn.Tanh(),
nn.Linear(32, self.weight_chunk_dim)
)
def generate_params(
self, one_hot_task_embedding: torch.Tensor
) -> Tuple[torch.Tensor, Dict[str, Any]]:
embedding = self.embedding_module(
torch.arange(self.num_embeddings, device=self.device)
)
one_hot_task_embedding = one_hot_task_embedding.repeat(self.num_embeddings, 1) # repeat to concat to embedding
concatenated = torch.cat((embedding, one_hot_task_embedding), dim=-1)
generated_params = self.weight_generator(concatenated).view(-1)
return generated_params, {"embedding": embedding}
# usage
target_network = nn.Sequential(
nn.Linear(32, 64),
nn.ReLU(),
nn.Linear(64, 32)
)
NUM_TASKS = 4
EMBEDDING_DIM = 4
NUM_EMBEDDINGS = 32
hypernetwork = MultiTaskHypernetwork(
num_tasks = NUM_TASKS,
target_network = target_network,
embedding_dim = EMBEDDING_DIM,
num_embeddings = NUM_EMBEDDINGS
)
inp = torch.zeros((1, 32))
one_hot_task_embedding = torch.tensor([0.0,0.0,1.0,0.0]).view((1,4))
out = hypernetwork(inp, generate_params_kwargs=dict(one_hot_task_embedding=one_hot_task_embedding))
```
---
## Advanced: Using vmap for batching operations
This is useful when dealing with dynamic hypernetworks that generate different params depending on inputs.
### Pytorch
```python
import torch.nn as nn
from functorch import vmap
# dynamic hypernetwork
from hypernn.torch import TorchDynamicHyperNetwork
# any module
target_network = nn.Sequential(
nn.Linear(8, 256),
nn.ReLU(),
nn.Linear(256, 32)
)
EMBEDDING_DIM = 4
NUM_EMBEDDINGS = 32
# conditioned on input to generate param vector
hypernetwork = TorchDynamicHyperNetwork(
target_network = target_network,
embedding_dim = EMBEDDING_DIM,
num_embeddings = NUM_EMBEDDINGS,
input_dim = 8
)
# batch of 10 inputs
inp = torch.randn((10, 1, 8))
# use with a for loop
outputs = []
for i in range(10):
outputs.append(hypernetwork(inp[i], generate_params_kwargs=dict(x=inp[i])))
outputs = torch.stack(outputs)
assert outputs.size() == (10, 1, 32)
# using vmap
from typing import Dict, Any
def forward(
generated_params,
*args,
has_aux: bool = False,
assert_parameter_shapes: bool = True,
generate_params_kwargs: Dict[str, Any] = {},
**kwargs
):
return hypernetwork.forward(*args,
generated_params=generated_params,
has_aux=has_aux,
assert_parameter_shapes=assert_parameter_shapes,
generate_params_kwargs=generate_params_kwargs,
**kwargs)
generated_vmap_params, aux_output = vmap(hypernetwork.generate_params)(inp)
outputs = vmap(forward)(generated_vmap_params, inp)
assert outputs.size() == (10, 1, 32)
```
## Future Plans
Here's a list of some stuff that will hopefully be added to the library. If anyone has other suggestions, please reach out / create an issue!
- [x] MNIST example
- [x] Lunar Lander Example
- [x] Dynamic Hypernetwork Example
- [x] Multi-task Hypernetwork Example
- [ ] Dedicated documentation website
- [ ] Efficient batching for DynamicJaxHypernetwork
- [ ] Implementation of [HyperTransformer](https://arxiv.org/abs/2201.04182)
- [ ] Implementation of [Recomposing the Reinforcement Learning Building Blocks with Hypernetworks](https://arxiv.org/abs/2106.06842)
- [ ] Implementation of [Goal-Conditioned Generators of Deep Policies
](https://arxiv.org/abs/2207.01570)
---
## Citing hyper-nn
If you use this software in your publications, please cite it by using the following BibTeX entry.
```bibtex
@misc{sudhakaran2022,
author = {Sudhakaran, Shyam Sudhakaran},
title = {hyper-nn},
howpublished = {\url{https://github.com/shyamsn97/hyper-nn}},
year = {2022},
}
```