Ecosyste.ms: Awesome
An open API service indexing awesome lists of open source software.
https://github.com/siyovushchik1414/natural-language-processing-with-disaster-tweets
NLP из Kaggle
https://github.com/siyovushchik1414/natural-language-processing-with-disaster-tweets
Last synced: 10 days ago
JSON representation
NLP из Kaggle
- Host: GitHub
- URL: https://github.com/siyovushchik1414/natural-language-processing-with-disaster-tweets
- Owner: siyovushchik1414
- Created: 2023-12-25T17:37:34.000Z (about 1 year ago)
- Default Branch: main
- Last Pushed: 2023-12-25T17:38:55.000Z (about 1 year ago)
- Last Synced: 2023-12-25T20:10:11.209Z (about 1 year ago)
- Language: Jupyter Notebook
- Size: 10.7 KB
- Stars: 0
- Watchers: 1
- Forks: 0
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
Awesome Lists containing this project
README
># __Natural Language Processing with Disaster Tweets__

># В чём суть задачи?
Задача обработки естественного языка с использованием твитов о стихийных бедствиях - это тип задачи обработки естественного языка, которая фокусируется на извлечении информации из твитов, связанных со стихийными бедствиями. Эта задача может быть использована для различных целей, таких как мониторинг стихийных бедствий, реагирование на стихийные бедствия и помощь пострадавшим.
Твиты о стихийных бедствиях могут содержать важную информацию о стихийных бедствиях, включая местонахождение стихийного бедствия, тип стихийного бедствия, ущерб, нанесенный стихийным бедствием, и потребности пострадавших. Обработка этих твитов может помочь специалистам по стихийным бедствиям лучше понять ситуацию, чтобы они могли принять более обоснованные решения о мониторинге, реагировании и помощи.
Вот несколько конкретных примеров задач, которые могут быть выполнены с использованием обработки естественного языка с использованием твитов о стихийных бедствиях:
* **Локализация стихийных бедствий:** Твиты о стихийных бедствиях часто содержат информацию о местонахождении стихийного бедствия. Обработка этих твитов может помочь специалистам по стихийным бедствиям определить местоположение стихийного бедствия с большей точностью.
* **Тип стихийных бедствий:** Твиты о стихийных бедствиях часто содержат информацию о типе стихийного бедствия. Обработка этих твитов может помочь специалистам по стихийным бедствиям лучше понять тип стихийного бедствия, чтобы они могли принять более обоснованные решения о мониторинге и реагировании.
* **Ущерб, нанесенный стихийным бедствиями:** Твиты о стихийных бедствиях часто содержат информацию о ущербе, нанесенном стихийным бедствиями. Обработка этих твитов может помочь специалистам по стихийным бедствиям оценить масштаб стихийного бедствия и потребности пострадавших.
* **Потребности пострадавших:** Твиты о стихийных бедствиях часто содержат информацию о потребностях пострадавших. Обработка этих твитов может помочь специалистам по стихийным бедствиям лучше понять потребности пострадавших, чтобы они могли оказать более эффективную помощь.
Обработка естественного языка с использованием твитов о стихийных бедствиях - это относительно новая область исследований. Однако в последние годы был достигнут значительный прогресс в разработке методов обработки естественного языка, которые могут быть использованы для решения этих задач.
># К какому типу задач относится NLP with Disaster Tweets и какие данные предлагает Kaggle?
Задача Natural Language Processing with Disaster Tweets from Kaggle относится к типу задач **классификации**. В данном случае необходимо классифицировать твиты на две категории: **о стихийных бедствиях** и **не о стихийных бедствиях**.
Данные, предложенные для этой задачи, состоят из двух наборов:
* **Тренировочный набор:** содержит 7503 твита, помеченных как о стихийных бедствиях или не о стихийных бедствиях.
* **Тестовый набор:** содержит 3243 твита, которые необходимо классифицировать.
Твиты в обоих наборах содержат следующую информацию:
* **Твит:** текст твита.
* **Тип:** категория твита (о стихийных бедствиях или не о стихийных бедствиях).
Эти данные были собраны из Twitter в период с 2012 по 2019 год.
Задача Natural Language Processing with Disaster Tweets from Kaggle представляет собой реальную задачу, которая может быть использована для мониторинга стихийных бедствий и оказания помощи пострадавшим.
Вот несколько примеров того, как эта задача может быть использована:
* **Мониторинг стихийных бедствий:** Модель может использоваться для отслеживания сообщений о стихийных бедствиях в режиме реального времени. Это может помочь специалистам по стихийным бедствиям лучше понять ситуацию и принять более обоснованные решения о мониторинге и реагировании.
* **Реагирование на стихийные бедствия:** Модель может использоваться для идентификации людей, нуждающихся в помощи. Это может помочь специалистам по стихийным бедствиям скоординировать усилия по оказанию помощи.
* **Помощь пострадавшим:** Модель может использоваться для сбора информации о потребностях пострадавших. Это может помочь специалистам по стихийным бедствиям обеспечить пострадавшим необходимую помощь.
* ># Pipeline задачи
В этом стартовом блокноте используется предварительно обученная модель DistilBERT из KerasNLP.
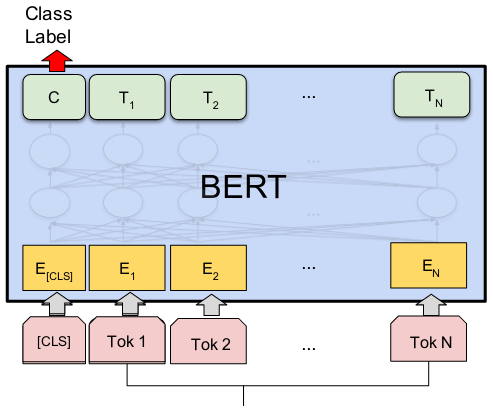
BERT расшифровывается как Bidirectional Encoder Representations from Transformers. BERT и другие архитектуры кодеров-трансформеров добились огромного успеха при решении различных задач в NLP (обработке естественного языка). Они вычисляют векторно-пространственные представления естественного языка, которые подходят для использования в моделях глубокого обучения.
Семейство моделей BERT использует архитектуру кодировщиков Transformer для обработки каждой лексемы входного текста в полном контексте всех лексем до и после нее, отсюда и название: Bidirectional Encoder Representations from Transformers.
BERT-модели обычно предварительно обучаются на большом корпусе текстов, а затем настраиваются под конкретные задачи.
Модель DistilBERT представляет собой дистиллированную форму модели BERT. Размер BERT-модели был уменьшен на 40 % за счет дистилляции знаний на этапе предварительного обучения, при этом она сохранила 97 % своих способностей к пониманию языка и стала на 60 % быстрее.
>Для легкого понимания можно сделать следующее:
Представь, что у тебя есть большой словарь, в котором каждое слово имеет свой уникальный номер. Ты можешь использовать этот словарь, чтобы найти значение любого слова в тексте.
BERT - это модель, которая может делать это автоматически. Она обучается на огромном наборе текстов и языковых моделей. В результате обучения она может понять значение слов в контексте других слов в предложении.
Например, если ты знаешь, что слово "дом" означает здание, в котором живут люди, ты можешь догадаться, что слово "домой" означает возвращение в это здание. BERT может делать такие же выводы, используя свой словарь и понимание контекста.
BERT может использоваться для решения различных задач обработки естественного языка, таких как:
Классификация текста: определение темы или категории текста.
Вопрос-ответ: предоставление ответов на вопросы о тексте.
Синтез текста: создание нового текста, такого как статьи, рассказы или код.
Вот пример того, как BERT можно использовать для решения задачи классификации текста. Представь, что у тебя есть набор текстов о стихийных бедствиях и набор текстов о других событиях. Ты можешь использовать BERT, чтобы обучить модель, которая может различать эти два типа текстов. Затем ты можешь использовать эту модель для классификации новых текстов о стихийных бедствиях или других событиях.
BERT - это мощная модель, которая может быть использована для решения различных задач обработки естественного языка. Она может помочь нам лучше понимать текст и генерировать новый текст.
>1. Загрузка данных Disaster Tweets
>2. Описание данных
>3. Обработка данных
>4. Загрузка DistilBERT из Keras NLP
>5. Обучение собственной модели
>6. Создание submission-файла