https://github.com/skalskip/top-cvpr-2025-papers
About This repository is a curated collection of the most exciting and influential CVPR 2025 papers. 🔥 [Paper + Code + Demo]
https://github.com/skalskip/top-cvpr-2025-papers
computer-vision cvpr cvpr2025 image-segmentation multimodal object-detection paper transformers vision-and-language vision-language-model
Last synced: 12 months ago
JSON representation
About This repository is a curated collection of the most exciting and influential CVPR 2025 papers. 🔥 [Paper + Code + Demo]
- Host: GitHub
- URL: https://github.com/skalskip/top-cvpr-2025-papers
- Owner: SkalskiP
- License: cc0-1.0
- Created: 2025-05-31T17:29:47.000Z (about 1 year ago)
- Default Branch: master
- Last Pushed: 2025-06-16T18:47:21.000Z (about 1 year ago)
- Last Synced: 2025-07-30T19:32:14.128Z (12 months ago)
- Topics: computer-vision, cvpr, cvpr2025, image-segmentation, multimodal, object-detection, paper, transformers, vision-and-language, vision-language-model
- Language: Python
- Homepage:
- Size: 164 KB
- Stars: 735
- Watchers: 12
- Forks: 42
- Open Issues: 2
-
Metadata Files:
- Readme: README.md
- Contributing: CONTRIBUTING.md
- License: LICENSE
Awesome Lists containing this project
README


## 👋 hello
Computer Vision and Pattern Recognition is a massive conference. In **2025** alone,
**13,008** papers were submitted, and **2,878** were accepted. I created this repository
to help you search for crème de la crème of CVPR publications. If the paper you are
looking for is not on my short list, take a peek at the full
[list](https://cvpr.thecvf.com/Conferences/2025/AcceptedPapers) of accepted papers.
## 🗞️ papers and posters
*🔥 - highlighted papers*
### 3d vision

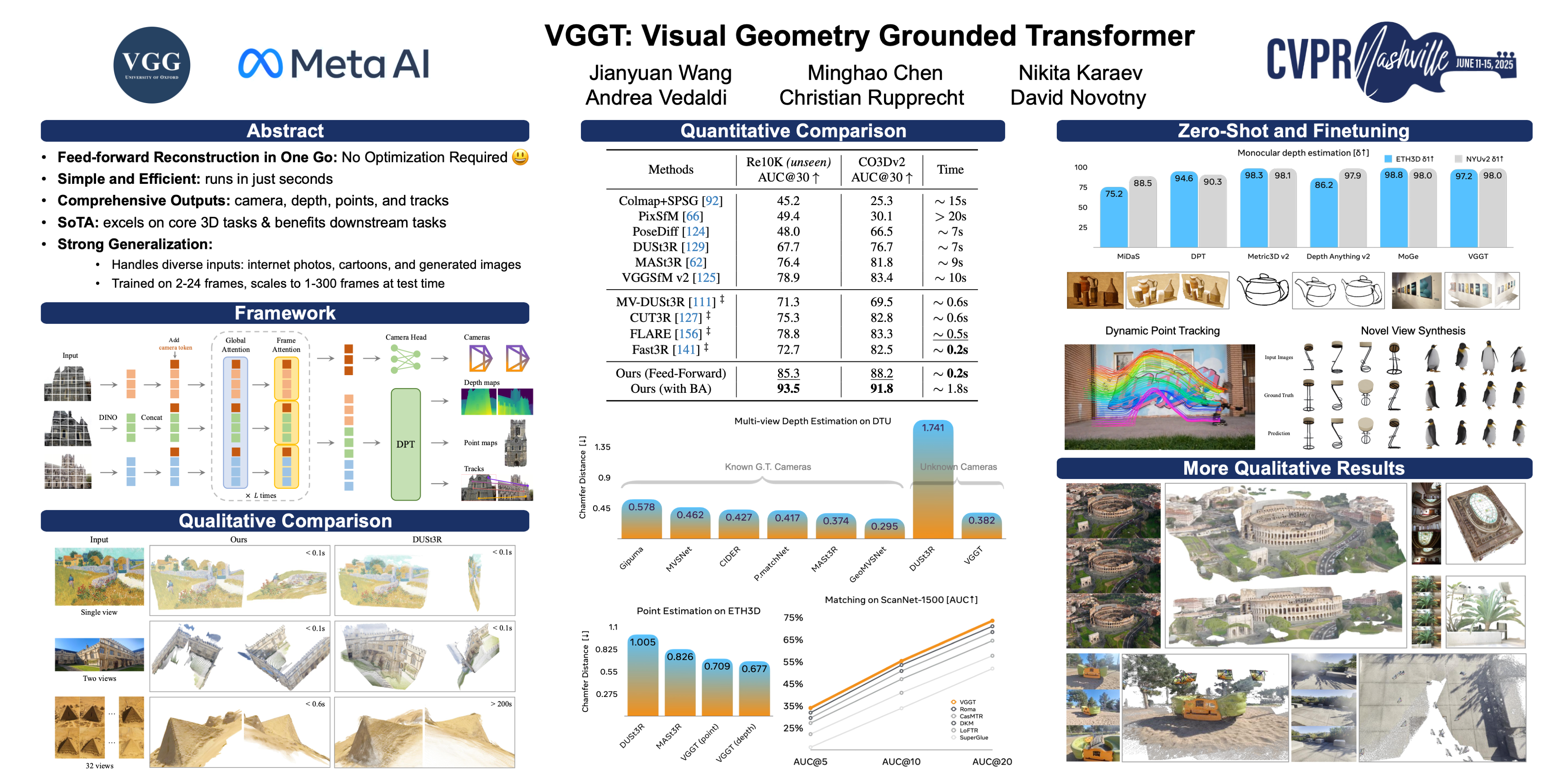
🔥 VGGT: Visual Geometry Grounded Transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, David Novotny
[paper] [code] [video] [demo]
Topic: 3D Vision
Session: Fri 13 Jun 2 p.m. PDT — 4 p.m. PDT Poster Session 2 #86

🔥 MASt3R-SLAM: Real-Time Dense SLAM with 3D Reconstruction Priors
Riku Murai, Eric Dexheimer, Andrew J. Davison
[paper] [code] [video]
Topic: 3D Vision
Session: Sat 14 Jun 3 p.m. PDT — 5 p.m. PDT Poster Session 4 #83

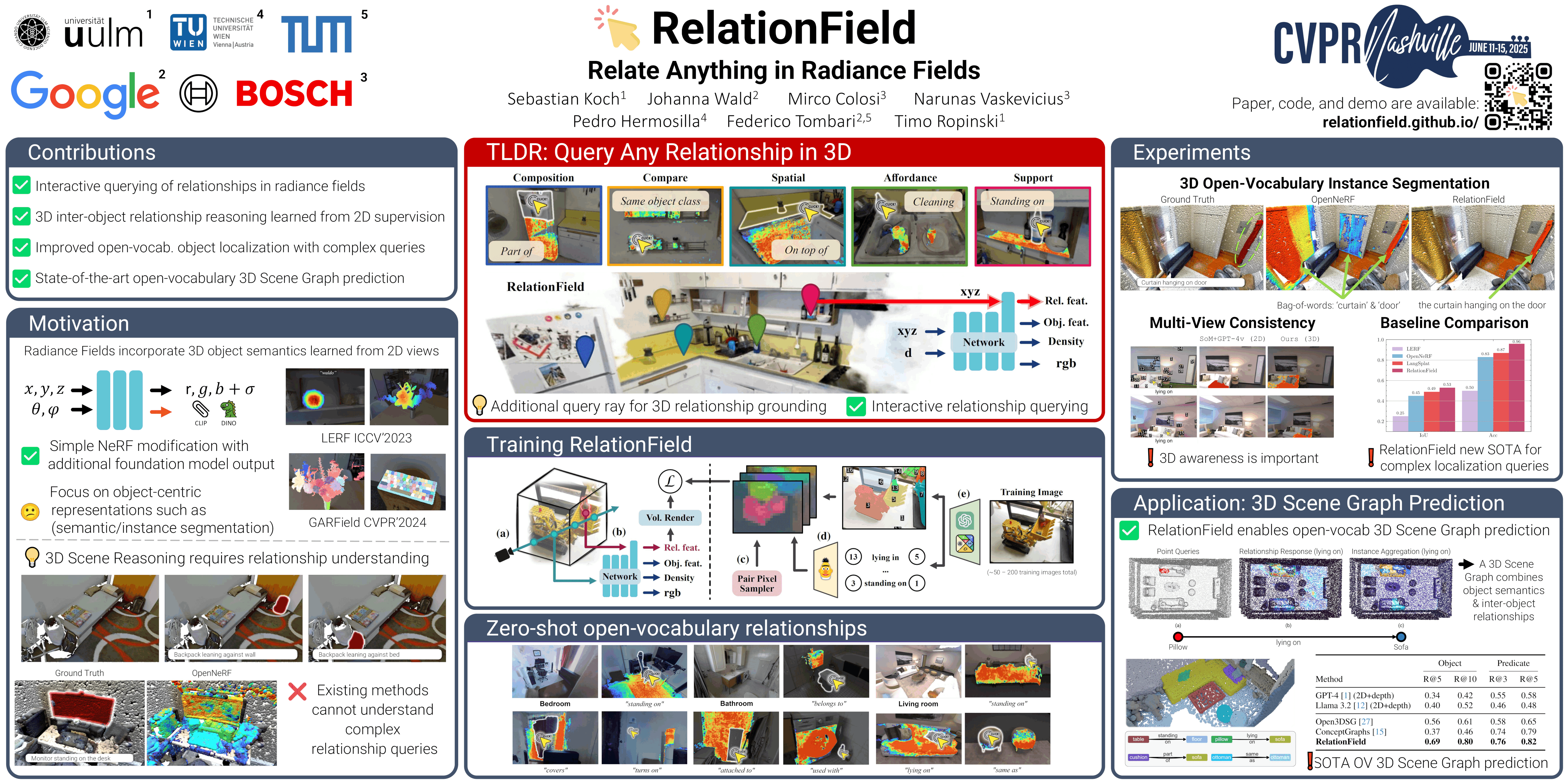
RelationField: Relate Anything in Radiance Fields
Sebastian Koch, Johanna Wald, Mirco Colosi, Narunas Vaskevicius, Pedro Hermosilla, Federico Tombari, Timo Ropinski
[paper] [code] [video]
Topic: 3D Vision
Session: Sun 15 Jun 8:30 a.m. PDT — 10:30 a.m. PDT Poster Session 5 #190
### depth estimation

UniK3D: Universal Camera Monocular 3D Estimation
Luigi Piccinelli, Christos Sakaridis, Mattia Segu, Yung-Hsu Yang, Siyuan Li, Wim Abbeloos, Luc Van Gool
[paper] [code] [demo]
Topic: Depth Estimation
Session: Fri 13 Jun 8:30 a.m. PDT — 10:30 a.m. PDT Poster Session 1 #80

🔥 DepthCrafter: Generating Consistent Long Depth Sequences for Open-world Videos
Wenbo Hu, Xiangjun Gao, Xiaoyu Li, Sijie Zhao, Xiaodong Cun, Yong Zhang, Long Quan, Ying Shan
[paper] [code] [demo]
Topic: Depth Estimation
Session: Fri 13 Jun 8:30 a.m. PDT — 10:30 a.m. PDT Poster Session 1 #171

Video Depth Anything: Consistent Depth Estimation for Super-Long Videos
Sili Chen, Hengkai Guo, Shengnan Zhu, Feihu Zhang, Zilong Huang, Jiashi Feng, Bingyi Kang
[paper] [code] [demo]
Topic: Depth Estimation
Session: Sun 15 Jun 8:30 a.m. PDT — 10:30 a.m. PDT Poster Session 5 #169
### explainability and interpretability

🔥 Interpreting Object-level Foundation Models via Visual Precision Search
Ruoyu Chen, Siyuan Liang, Jingzhi Li, Shiming Liu, Maosen Li, Zhen Huang, Hua Zhang, Xiaochun Cao
[paper] [code] [colab]
Topic: Explainability and Interpretability
Session: Sun 15 Jun 2 p.m. PDT — 4 p.m. PDT Poster Session 6 #372
### gaze target estimation

🔥 Gaze-LLE: Gaze Target Estimation via Large-Scale Learned Encoders
Fiona Ryan, Ajay Bati, Sangmin Lee, Daniel Bolya, Judy Hoffman, James M. Rehg
[paper] [code] [demo] [colab]
Topic: Gaze Target Estimation
Session: Sun 15 Jun 2 p.m. PDT — 4 p.m. PDT Poster Session 6 #98
### generative models

MMAudio: Taming Multimodal Joint Training for High-Quality Video-to-Audio Synthesis
Ho Kei Cheng, Masato Ishii, Akio Hayakawa, Takashi Shibuya, Alexander Schwing, Yuki Mitsufuji
[paper] [code] [video] [demo] [colab]
Topic: Generative Models
Session: Sun 15 Jun 2 p.m. PDT — 4 p.m. PDT Poster Session 6 #260

SemanticDraw: Towards Real-Time Interactive Content Creation from Image Diffusion Models
Jaerin Lee, Daniel Sungho Jung, Kanggeon Lee, Kyoung Mu Lee
[paper] [code] [video] [demo] [colab]
Topic: Generative Models
Session: Sat 14 Jun 8:30 a.m. PDT — 10:30 a.m. PDT Poster Session 3 #226
### image matching

MINIMA: Modality Invariant Image Matching
Jiangwei Ren, Xingyu Jiang, Zizhuo Li, Dingkang Liang, Xin Zhou, Xiang Bai
[paper] [code] [demo]
Topic: Image Matching
Session: Sun 15 Jun 8:30 a.m. PDT — 10:30 a.m. PDT Poster Session 5 #190
### image vectorization

Layered Image Vectorization via Semantic Simplification
Zhenyu Wang, Jianxi Huang, Zhida Sun, Yuanhao Gong, Daniel Cohen-Or, Min Lu
[paper] [code] [video]
Topic: Image Vectorization
Session: Fri 13 Jun 2 p.m. PDT — 4 p.m. PDT Poster Session 2 #226
### object tracking

🔥 MITracker: Multi-View Integration for Visual Object Tracking
Mengjie Xu, Yitao Zhu, Haotian Jiang, Jiaming Li, Zhenrong Shen, Sheng Wang, Haolin Huang, Xinyu Wang, Qing Yang, Han Zhang, Qian Wang
[paper] [code]
Topic: Object Tracking
Session: Sun 15 Jun 2 p.m. PDT — 4 p.m. PDT Poster Session 6 #98

Multiple Object Tracking as ID Prediction
Ruopeng Gao, Ji Qi, Limin Wang
[paper] [code]
Topic: Object Tracking
Session: Sun 15 Jun 2 p.m. PDT — 4 p.m. PDT Poster Session 6 #163
EdgeTAM: On-Device Track Anything Model
Chong Zhou, Chenchen Zhu, Yunyang Xiong, Saksham Suri, Fanyi Xiao, Lemeng Wu, Raghuraman Krishnamoorthi, Bo Dai, Chen Change Loy, Vikas Chandra, Bilge Soran
[paper] [code] [demo]
Topic: Object Tracking
Session: Sat 14 Jun 8:30 a.m. PDT — 10:30 a.m. PDT Poster Session 3 #304

A Distractor-Aware Memory for Visual Object Tracking with SAM2
Jovana Videnovic, Alan Lukezic, Matej Kristan
[paper] [code]
Topic: Object Tracking
Session: Sun 15 Jun 8:30 a.m. PDT — 10:30 a.m. PDT Poster Session 5 #309

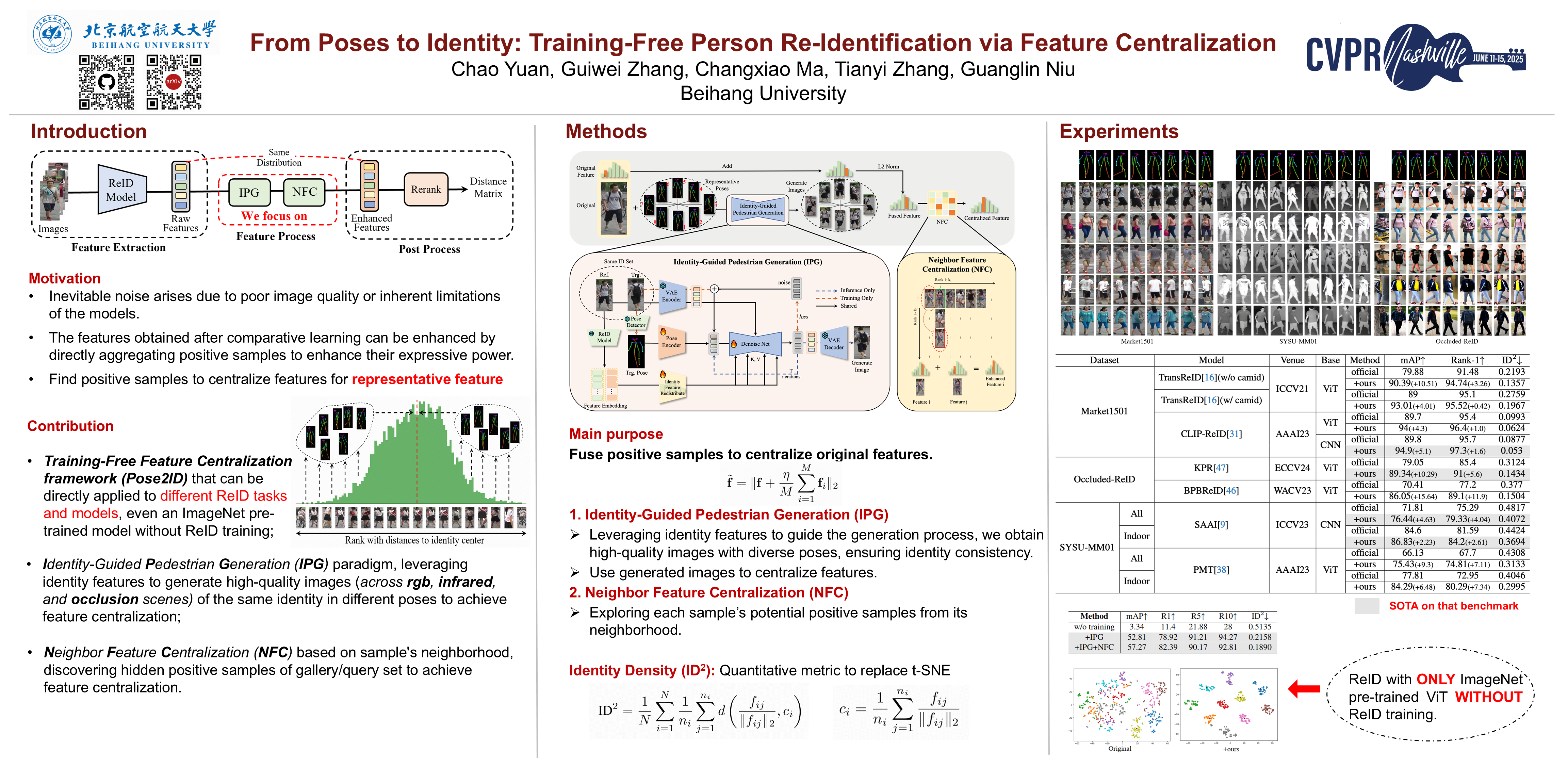
From Poses to Identity: Training-Free Person Re-Identification via Feature Centralization
Chao Yuan, Guiwei Zhang, Changxiao Ma, Tianyi Zhang, Guanglin Niu
[paper] [code]
Topic: Object Tracking
Session: Sun 15 Jun 8:30 a.m. PDT — 10:30 a.m. PDT Poster Session 5 #190
### open-world detection

🔥 Towards Zero-Shot Anomaly Detection and Reasoning with Multimodal Large Language Models
Jiacong Xu, Shao-Yuan Lo, Bardia Safaei, Vishal M. Patel, Isht Dwivedi
[paper] [code] [video]
Topic: Open-World Detection
Session: Sat 14 Jun 3 p.m. PDT — 5 p.m. PDT Poster Session 4 #435

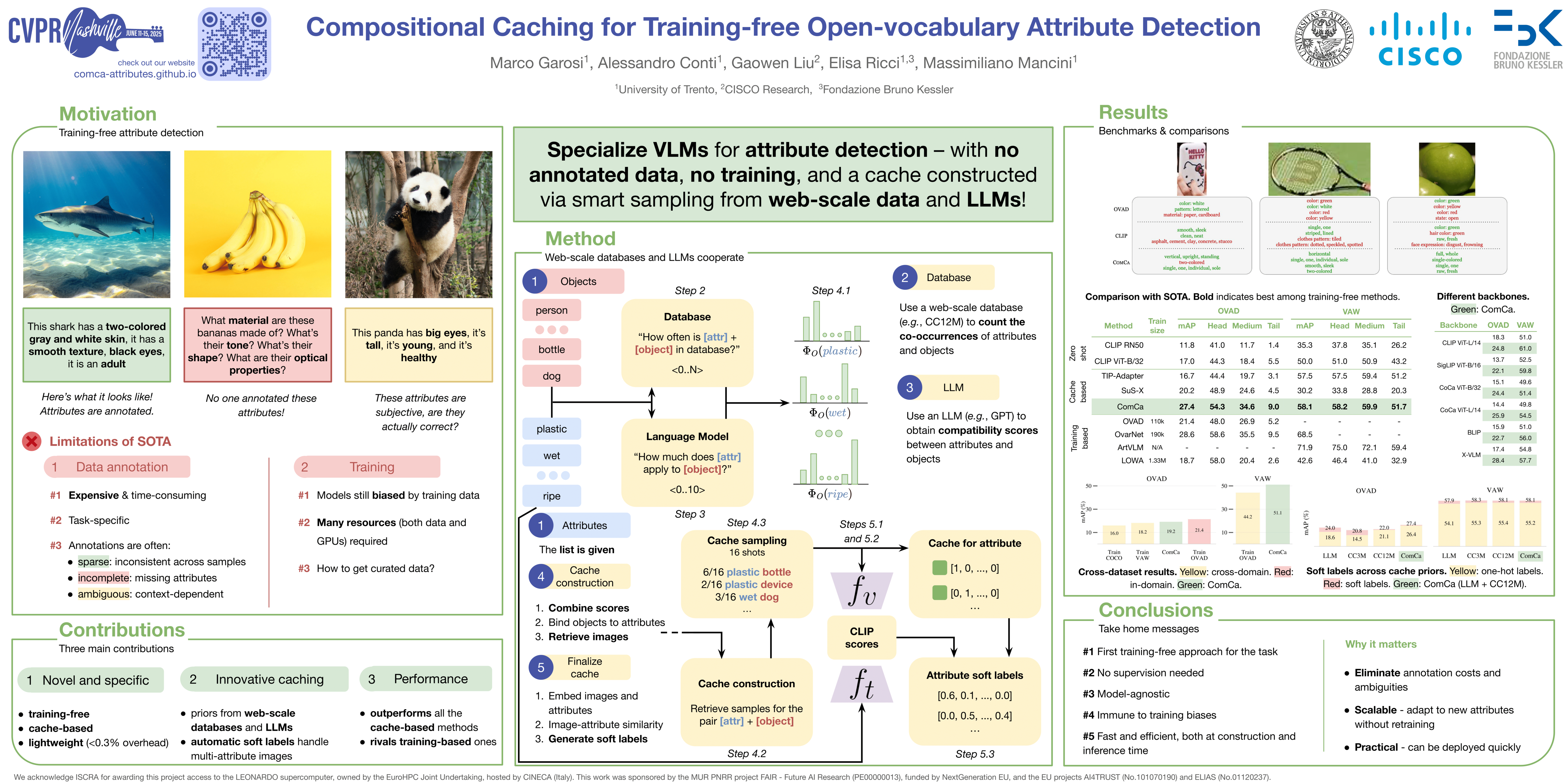
🔥 Compositional Caching for Training-free Open-vocabulary Attribute Detection
Marco Garosi, Alessandro Conti, Gaowen Liu, Elisa Ricci, Massimiliano Mancini
[paper] [code] [video]
Topic: Open-World Detection
Session: Sat 14 Jun 8:30 a.m. PDT — 10:30 a.m. PDT Poster Session 3 #426
### pose estimation

🔥 Reconstructing Humans with a Biomechanically Accurate Skeleton
Yan Xia, Xiaowei Zhou, Etienne Vouga, Qixing Huang, Georgios Pavlakos
[paper] [code] [demo] [colab]
Topic: Pose Estimation
Session: Fri 13 Jun 2 p.m. PDT — 4 p.m. PDT Poster Session 2 #91
### segmentation
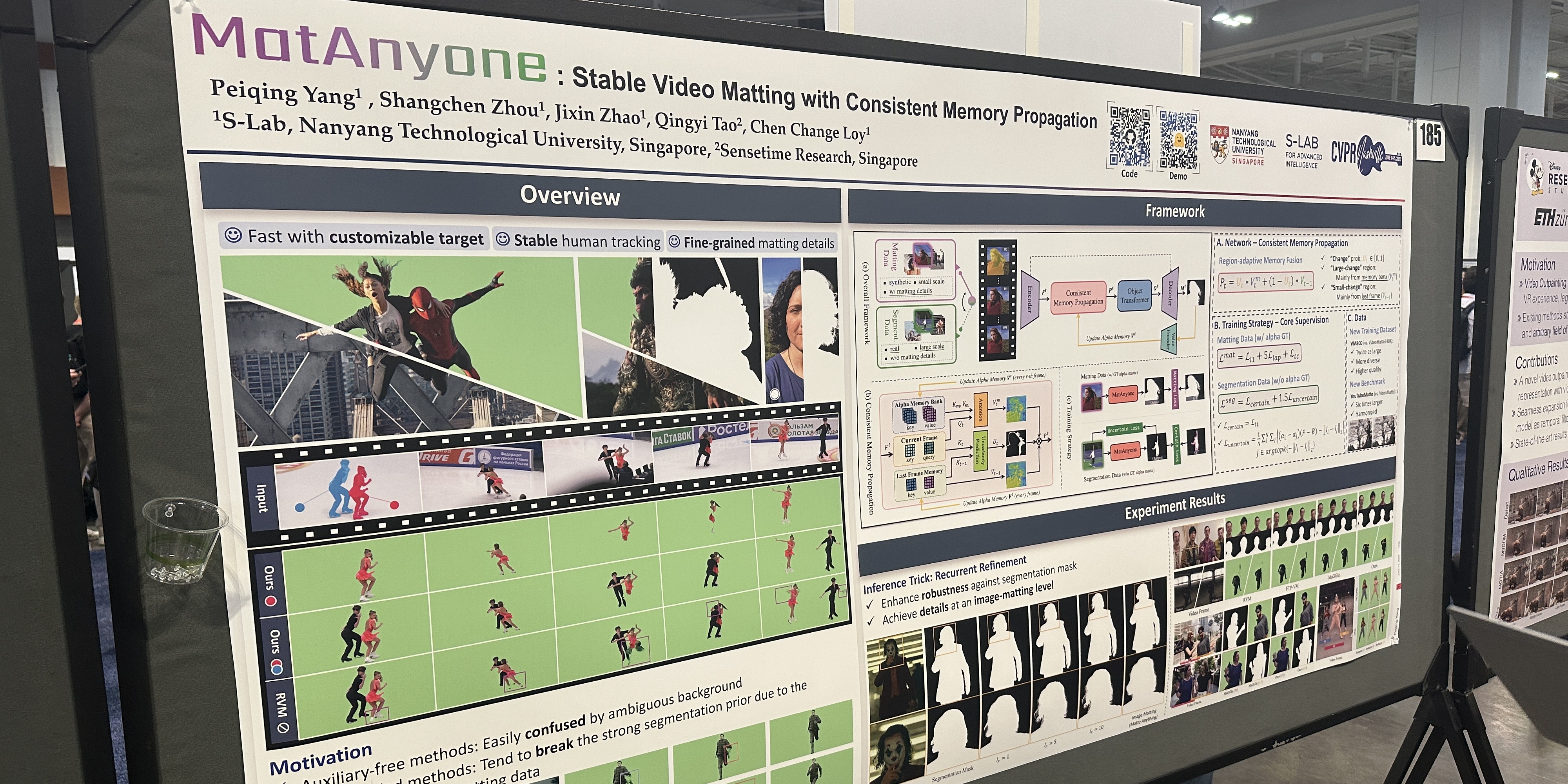
MatAnyone: Stable Video Matting with Consistent Memory Propagation
Peiqing Yang, Shangchen Zhou, Jixin Zhao, Qingyi Tao, Chen Change Loy
[paper] [code] [video] [demo]
Topic: Segmentation
Session: Fri 13 Jun 2 p.m. PDT — 4 p.m. PDT Poster Session 2 #185
### stereo matching

🔥 FoundationStereo: Zero-Shot Stereo Matching
Bowen Wen, Matthew Trepte, Joseph Aribido, Jan Kautz, Orazio Gallo, Stan Birchfield
[paper] [code] [video]
Topic: Stereo Matching
Session: Fri 13 Jun 2 p.m. PDT — 4 p.m. PDT Poster Session 2 #81
### video understanding

Towards Universal Soccer Video Understanding
Jiayuan Rao, Haoning Wu, Hao Jiang, Ya Zhang, Yanfeng Wang, Weidi Xie
[paper] [code]
Topic: Video Understanding
Session: Fri 13 Jun 2 p.m. PDT — 4 p.m. PDT Poster Session 2 #185
### vision-language models

FastVLM: Efficient Vision Encoding for Vision Language Models
Pavan Kumar Anasosalu Vasu, Fartash Faghri, Chun-Liang Li, Cem Koc, Nate True, Albert Antony, Gokul Santhanam, James Gabriel, Peter Grasch, Oncel Tuzel, Hadi Pouransari
[paper] [code]
Topic: Vision-Language Models
Session: Sat 14 Jun 3 p.m. PDT — 5 p.m. PDT Poster Session 4 #378

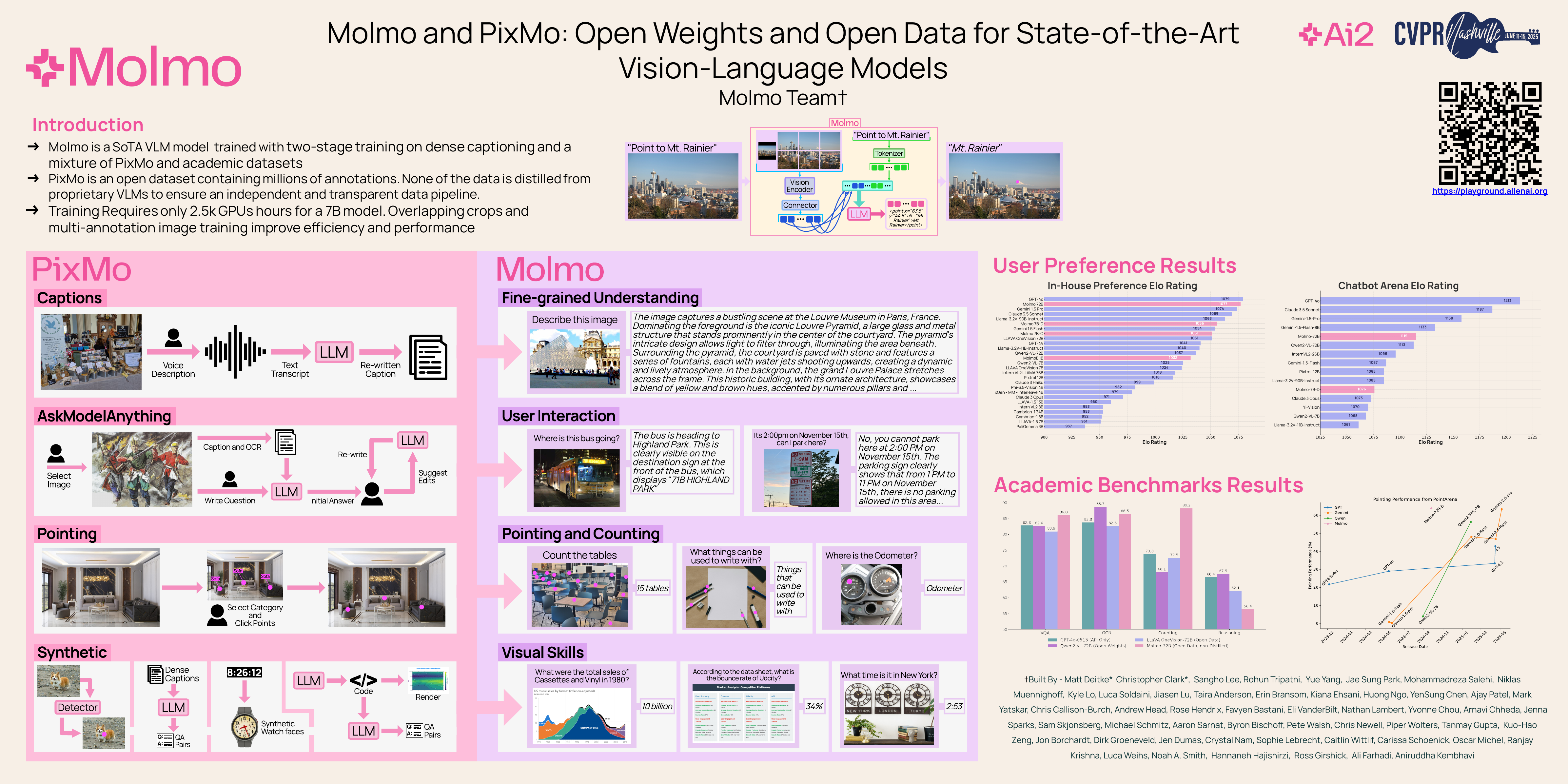
🔥 Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Vision-Language Models
Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tripathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi, Niklas Muennighoff, Kyle Lo, Luca Soldaini, Jiasen Lu, Taira Anderson, Erin Bransom, Kiana Ehsani, Huong Ngo, YenSung Chen, Ajay Patel, Mark Yatskar, Chris Callison-Burch, Andrew Head, Rose Hendrix, Favyen Bastani, Eli VanderBilt, Nathan Lambert, Yvonne Chou, Arnavi Chheda, Jenna Sparks, Sam Skjonsberg, Michael Schmitz, Aaron Sarnat, Byron Bischoff, Pete Walsh, Chris Newell, Piper Wolters, Tanmay Gupta, Kuo-Hao Zeng, Jon Borchardt, Dirk Groeneveld, Crystal Nam, Sophie Lebrecht, Caitlin Wittlif, Carissa Schoenick, Oscar Michel, Ranjay Krishna, Luca Weihs, Noah A. Smith, Hannaneh Hajishirzi, Ross Girshick, Ali Farhadi, Aniruddha Kembhavi
[paper] [demo]
Topic: Vision-Language Models
Session: Fri 13 Jun 8:30 a.m. PDT — 10:30 a.m. PDT Poster Session 1 #80

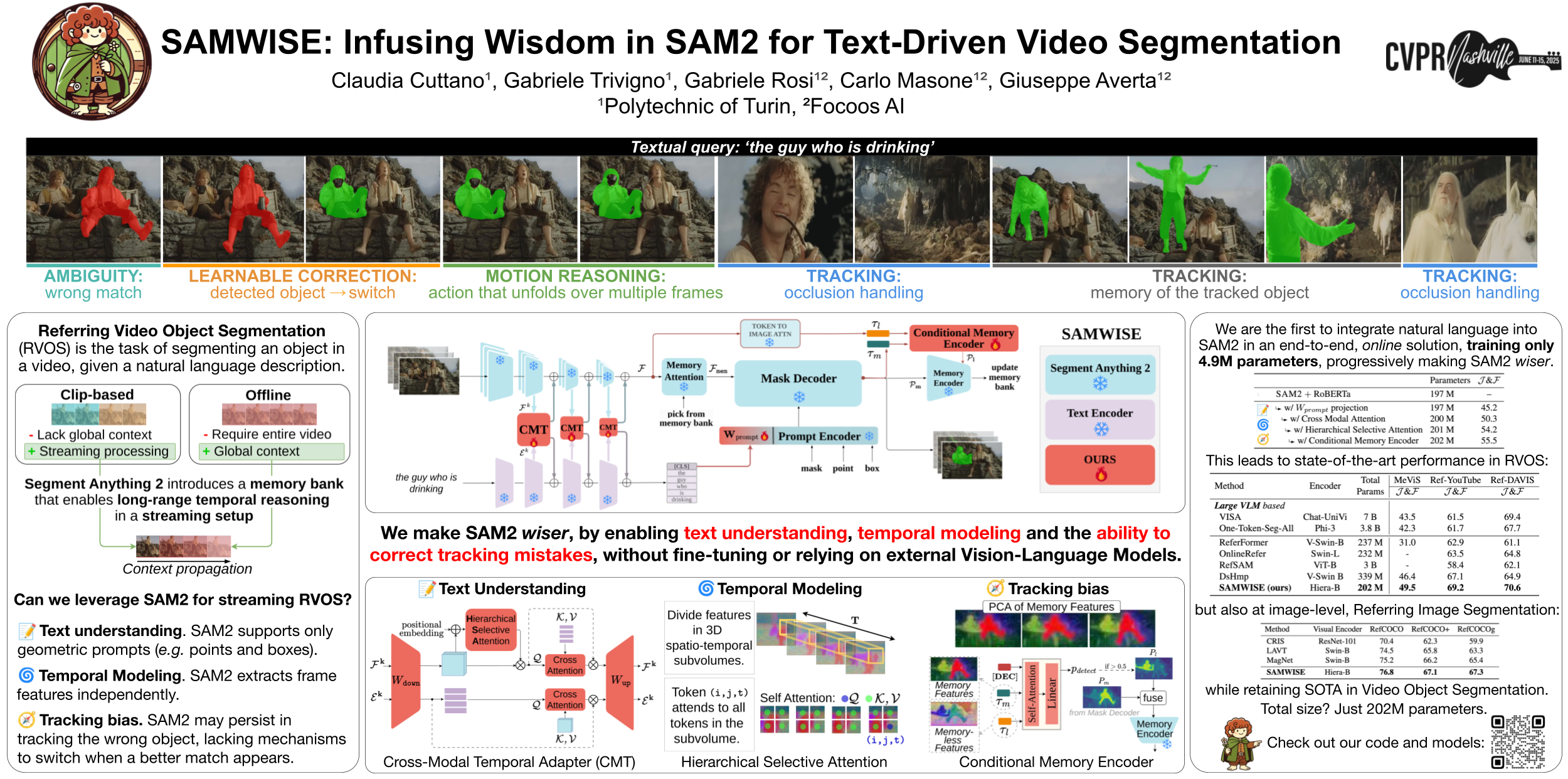
🔥 SAMWISE: Infusing Wisdom in SAM2 for Text-Driven Video Segmentation
Claudia Cuttano, Gabriele Trivigno, Gabriele Rosi, Carlo Masone, Giuseppe Averta
[paper] [code] [video]
Topic: Vision-Language Models
Session: Fri 13 Jun 8:30 a.m. PDT — 10:30 a.m. PDT Poster Session 1 #308

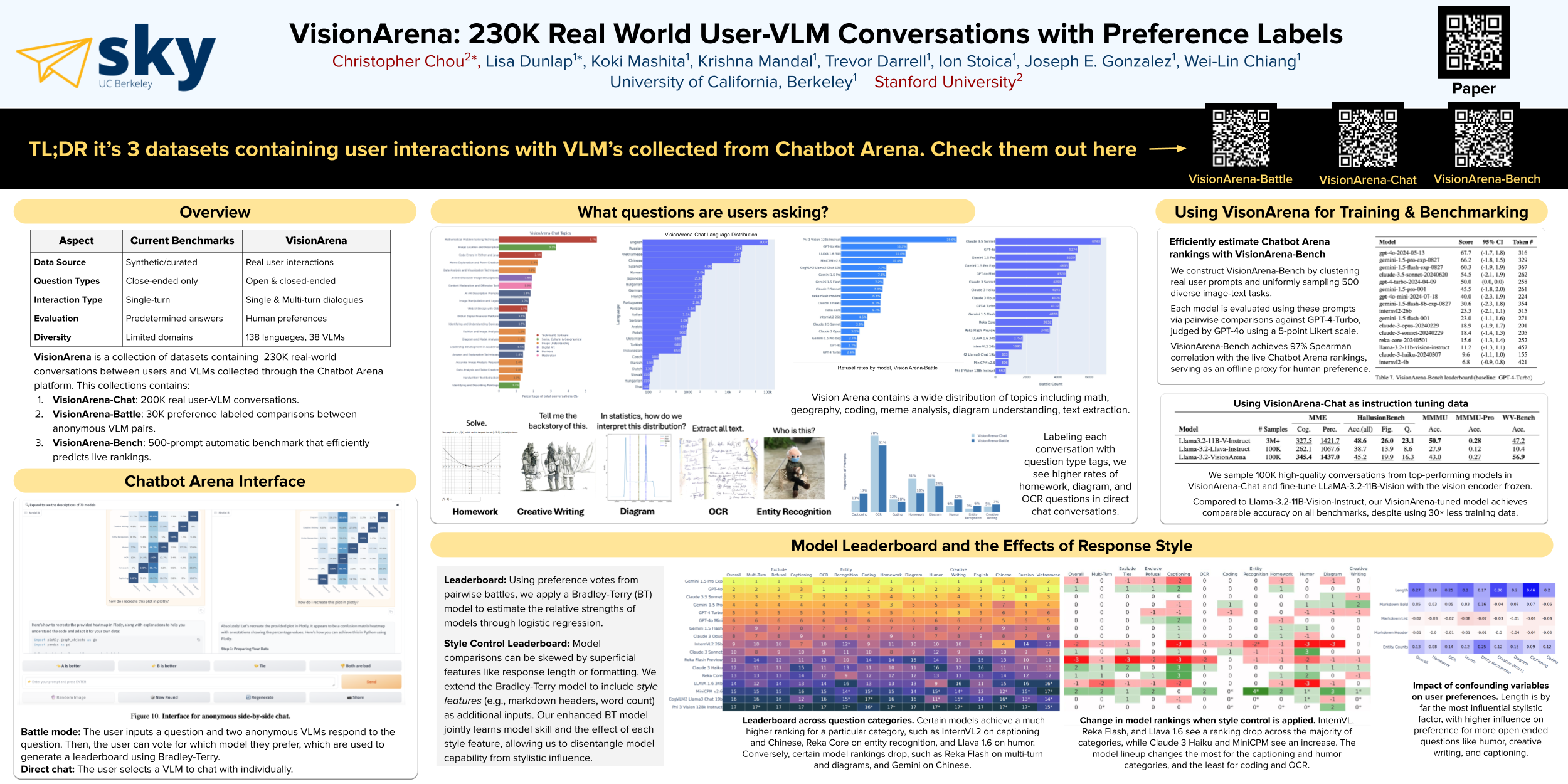
VisionArena: 230K Real World User-VLM Conversations with Preference Labels
Christopher Chou, Lisa Dunlap, Koki Mashita, Krishna Mandal, Trevor Darrell, Ion Stoica, Joseph E. Gonzalez, Wei-Lin Chiang
[paper] [demo]
Topic: Vision-Language Models
Session: Fri 13 Jun 8:30 a.m. PDT — 10:30 a.m. PDT Poster Session 1 #353

DINOv2 Meets Text: A Unified Framework for Image- and Pixel-Level Vision-Language Alignment
Cijo Jose, Théo Moutakanni, Dahyun Kang, Federico Baldassarre, Timothée Darcet, Hu Xu, Daniel Li, Marc Szafraniec, Michaël Ramamonjisoa, Maxime Oquab, Oriane Siméoni, Huy V. Vo, Patrick Labatut, Piotr Bojanowski
[paper] [code] [video] [colab]
Topic: Vision-Language Models
Session: Sun 15 Jun 8:30 a.m. PDT — 10:30 a.m. PDT Poster Session 5 #169
### visual agents

Magma: A Foundation Model for Multimodal AI Agents
Jianwei Yang, Reuben Tan, Qianhui Wu, Ruijie Zheng, Baolin Peng, Yongyuan Liang, Yu Gu, Mu Cai, Seonghyeon Ye, Joel Jang, Yuquan Deng, Lars Liden, Jianfeng Gao
[paper] [code] [video] [demo]
Topic: Visual Agents
Session: Sat 14 Jun 8:30 a.m. PDT — 10:30 a.m. PDT Poster Session 3 #340

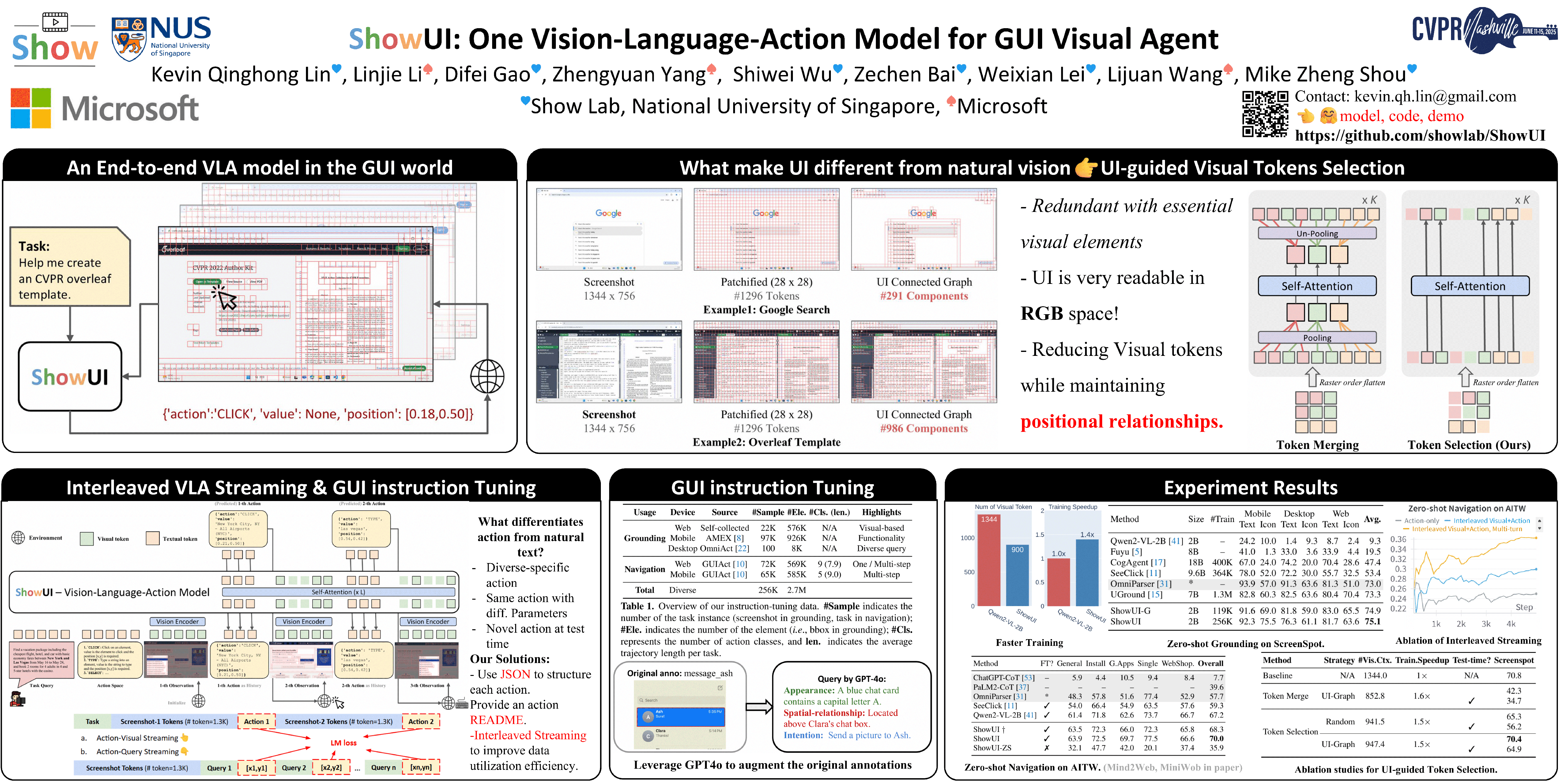
ShowUI: One Vision-Language-Action Model for GUI Visual Agent
Kevin Qinghong Lin, Linjie Li, Difei Gao, Zhengyuan Yang, Shiwei Wu, Zechen Bai, Weixian Lei, Lijuan Wang, Mike Zheng Shou
[paper] [code] [demo]
Topic: Visual Agents
Session: Sat 14 Jun 3 p.m. PDT — 5 p.m. PDT Poster Session 4 #352

Visual Agentic AI for Spatial Reasoning with a Dynamic API
Damiano Marsili, Rohun Agrawal, Yisong Yue, Georgia Gkioxari
[paper] [code] [video]
Topic: Visual Agents
Session: Sat 14 Jun 3 p.m. PDT — 5 p.m. PDT Poster Session 4 #352
## 🦸 contribution
We would love your help in making this repository even better! If you know of an amazing
paper that isn't listed here, or if you have any suggestions for improvement, feel free
to open an
[issue](https://github.com/SkalskiP/top-cvpr-2025-papers/issues)
or submit a
[pull request](https://github.com/SkalskiP/top-cvpr-2025-papers/pulls).