https://github.com/snehil-shah/multimodal-image-search-engine
Text to Image & Reverse Image Search Engine built upon Vector Similarity Search utilizing CLIP VL-Transformer for Semantic Embeddings & Qdrant as the Vector-Store
https://github.com/snehil-shah/multimodal-image-search-engine
computer-vision multimodal-transformer nlp openai-clip qdrant qdrant-vector-database vector-embeddings
Last synced: 8 months ago
JSON representation
Text to Image & Reverse Image Search Engine built upon Vector Similarity Search utilizing CLIP VL-Transformer for Semantic Embeddings & Qdrant as the Vector-Store
- Host: GitHub
- URL: https://github.com/snehil-shah/multimodal-image-search-engine
- Owner: Snehil-Shah
- License: mit
- Created: 2024-01-01T18:55:31.000Z (almost 2 years ago)
- Default Branch: main
- Last Pushed: 2024-01-10T17:57:56.000Z (almost 2 years ago)
- Last Synced: 2025-02-15T04:41:33.387Z (8 months ago)
- Topics: computer-vision, multimodal-transformer, nlp, openai-clip, qdrant, qdrant-vector-database, vector-embeddings
- Language: Jupyter Notebook
- Homepage: https://huggingface.co/spaces/Snehil-Shah/Multimodal-Image-Search-Engine
- Size: 10.9 MB
- Stars: 11
- Watchers: 2
- Forks: 3
- Open Issues: 0
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
---
title: Multimodal Image Search Engine
emoji: 🔍
colorFrom: yellow
colorTo: yellow
sdk: gradio
sdk_version: 4.13.0
app_file: app.py
pinned: false
license: mit
---
Multi-Modal Image Search Engine
A Semantic Search Engine that understands the Content & Context of your Queries.
Use Multi-Modal inputs like Text-Image or a Reverse Image Search to Query a Vector Database of over 15k Images. Try it Out!

• About The Project
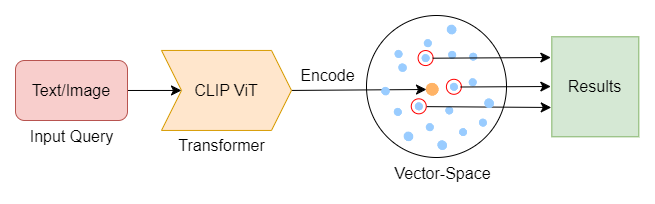
At its core, the Search Engine is built upon the concept of **Vector Similarity Search**.
All the Images are encoded into vector embeddings based on their semantic meaning using a Transformer Model, which are then stored in a vector space.
When searched with a query, it returns the nearest neighbors to the input query which are the relevant search results.

We use the Contrastive Language-Image Pre-Training (CLIP) Model by OpenAI which is a Pre-trained Multi-Modal Vision Transformer that can semantically encode Words, Sentences & Images into a 512 Dimensional Vector. This Vector encapsulates the meaning & context of the entity into a *Mathematically Measurable* format.
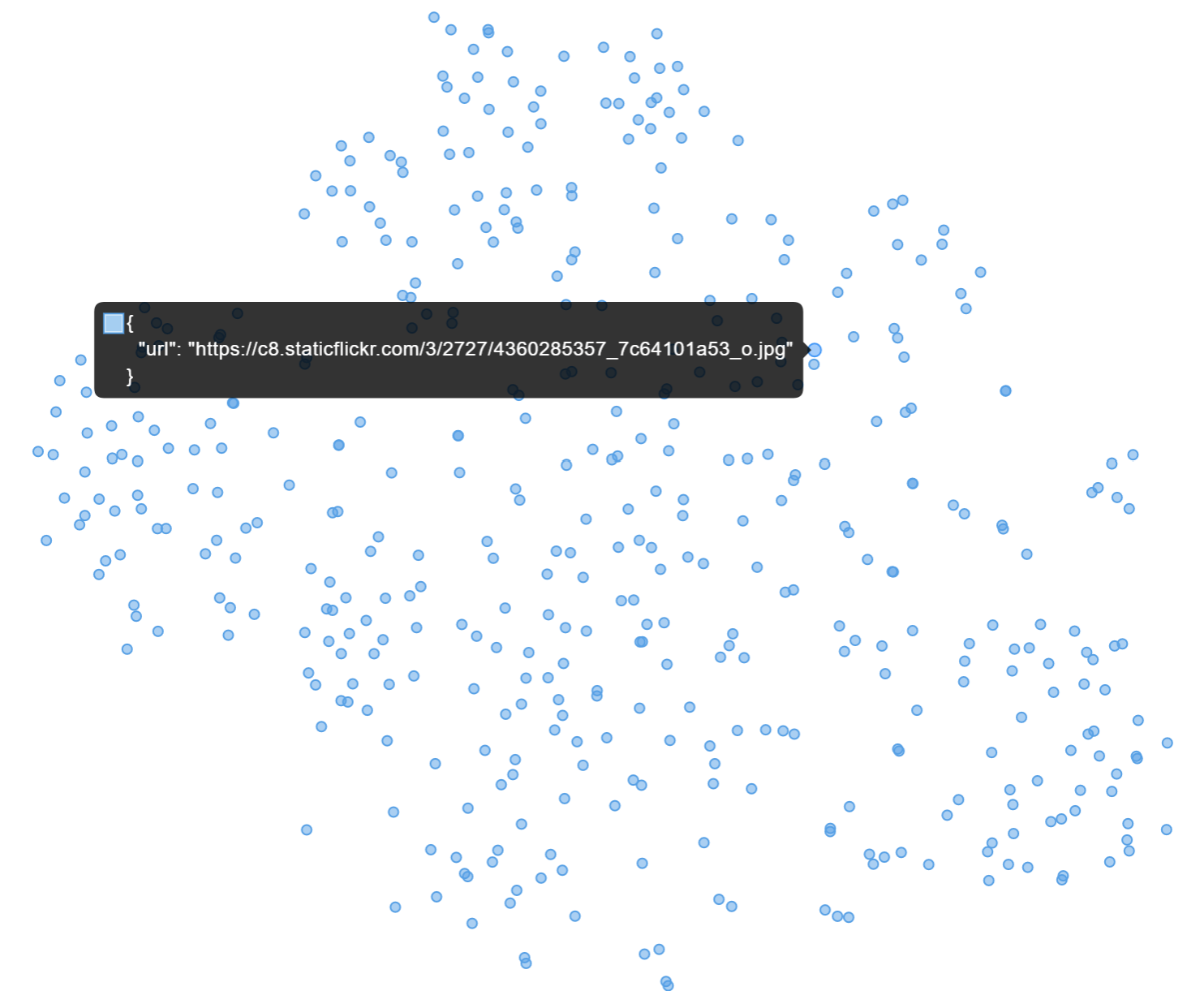
2-D Visualization of 500 Images in a 512-D Vector Space
The Images are stored as vector embeddings in a Qdrant Collection which is a Vector Database. The Search Term is encoded and run as a query to Qdrant, which returns the Nearest Neighbors based on their Cosine-Similarity to the Search Query.
**The Dataset**: All images are sourced from the [Open Images Dataset](https://github.com/cvdfoundation/open-images-dataset) by Common Visual Data Foundation.
• Technologies Used
- Python
- Jupyter Notebooks
- Qdrant - Vector Database
- Sentence-Transformers - Library
- CLIP by OpenAI - ViT Model
- Gradio - UI
- HuggingFace Spaces - Deployment