https://github.com/softwaremill/kmq
Kafka-based message queue
https://github.com/softwaremill/kmq
cats-effect java kafka message-queue reactive-streams scala
Last synced: about 1 year ago
JSON representation
Kafka-based message queue
- Host: GitHub
- URL: https://github.com/softwaremill/kmq
- Owner: softwaremill
- License: apache-2.0
- Created: 2017-02-11T13:18:12.000Z (over 9 years ago)
- Default Branch: master
- Last Pushed: 2025-03-25T00:07:37.000Z (over 1 year ago)
- Last Synced: 2025-04-08T14:08:33.421Z (over 1 year ago)
- Topics: cats-effect, java, kafka, message-queue, reactive-streams, scala
- Language: Scala
- Homepage: https://softwaremill.com/open-source/
- Size: 451 KB
- Stars: 337
- Watchers: 40
- Forks: 45
- Open Issues: 28
-
Metadata Files:
- Readme: README.md
- License: LICENSE
Awesome Lists containing this project
README
# Kafka Message Queue
[](https://gitter.im/softwaremill/kmq?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
[](https://maven-badges.herokuapp.com/maven-central/com.softwaremill.kmq/core_2.12)
Using `kmq` you can acknowledge processing of individual messages in Kafka, and have unacknowledged messages
re-delivered after a timeout.
This is in contrast to the usual Kafka offset-committing mechanism, using which you can acknowledge all messages
up to a given offset only.
If you are familiar with [Amazon SQS](https://aws.amazon.com/sqs/), `kmq` implements a similar message processing
model.
# How does this work?
For a more in-depth overview see the blog: [Using Kafka as a message queue](https://softwaremill.com/using-kafka-as-a-message-queue/),
and for performance benchmarks: [Kafka with selective acknowledgments (kmq) performance & latency benchmark](https://softwaremill.com/kafka-with-selective-acknowledgments-performance/)
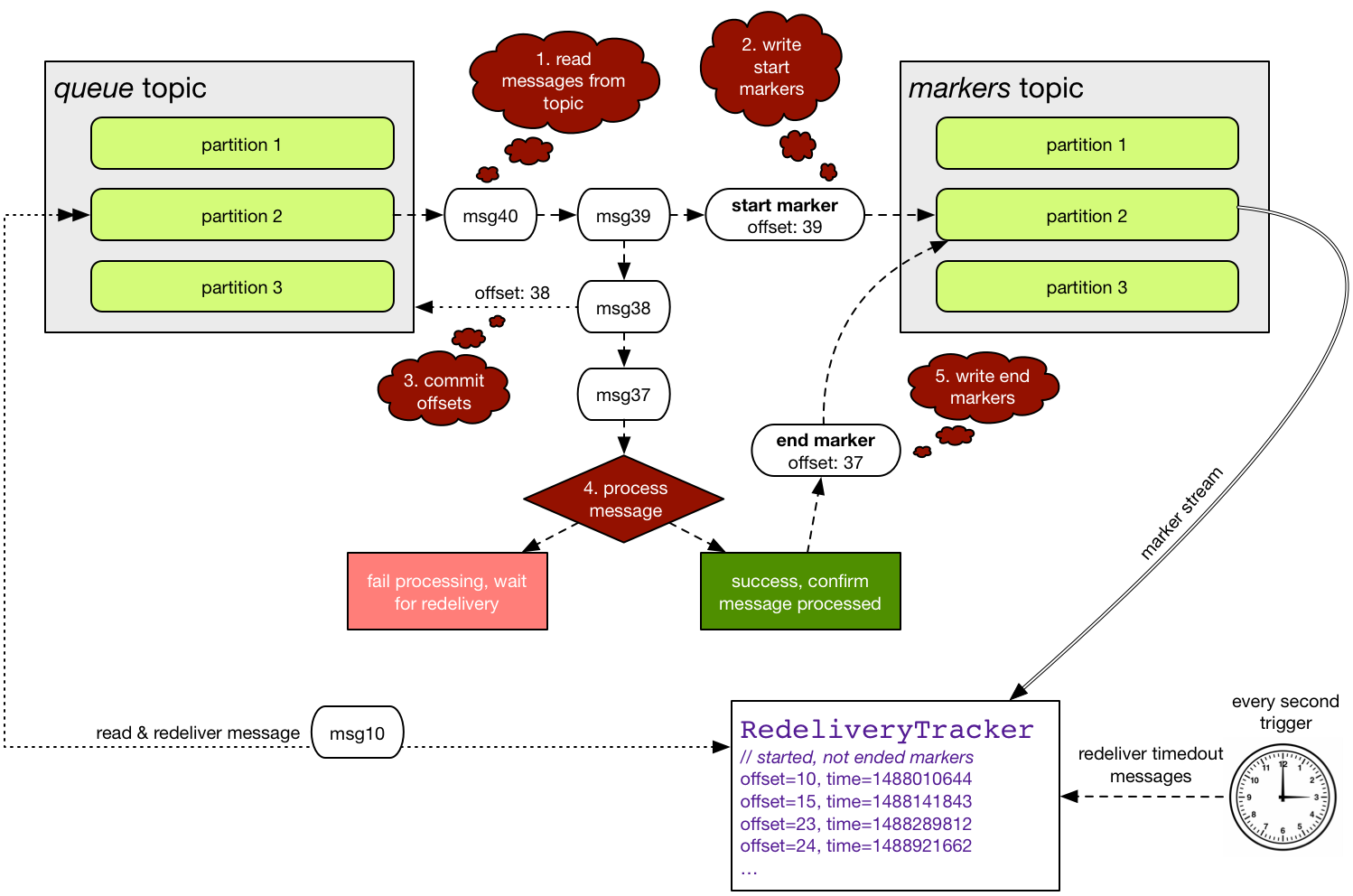
The acknowledgment mechanism uses a `marker` topic, which should have the same number of partitions as the "main"
data topic (called the `queue` topic). The marker topic is used to track which messages have been processed, by
writing start/end markers for every message.
# Using kmq
An application using `kmq` should consist of the following components:
* a number of `RedeliveryTracker`s. This components consumes the `marker` topic and redelivers messages if appropriate.
Multiple copies should be started in a cluster for fail-over. Uses automatic partition assignment.
* components which send data to the `queue` topic to be processed
* queue clients, either custom or using the `KmqClient`
# Maven/SBT dependency
SBT:
"com.softwaremill.kmq" %% "core" % "0.3.1"
Maven:
com.softwaremill.kmq
core_2.13
0.3.1
Note: The supported Scala versions are: 2.12, 2.13.
# Client flow
The flow of processing a message is as follows:
1. read messages from the `queue` topic, in batches
2. write a `start` marker to the `markers` topic for each message, wait until the markers are written
3. commit the biggest message offset to the `queue` topic
4. process messages
5. for each message, write an `end` marker. No need to wait until the markers are written.
This ensures at-least-once processing of each message. Note that the acknowledgment of each message (writing the
`end` marker) can be done for each message separately, out-of-order, from a different thread, server or application.
# Example code
There are three example applications:
* `example-java/embedded`: a single java application that starts all three components (sender, client, redelivery tracker)
* `example-java/standalone`: three separate runnable classes to start the different components
* `example-scala`: an implementation of the client using [reactive-kafka](https://github.com/akka/reactive-kafka)
# Time & timestamps
How time is handled is crucial for message redelivery, as messages are redelivered after a given amount of time passes
since the `start` marker was sent.
To track what was sent when, `kmq` uses Kafka's message timestamp. By default, this is messages create time
(`message.timestamp.type=CreateTime`), but for the `markers` topic, it is advisable to switch this to `LogAppendTime`.
That way, the timestamps more closely reflect when the markers are really written to the log, and are guaranteed to be
monotonic in each partition (which is important for redelivery - see below).
To calculate which messages should be redelivered, we need to know the value of "now", to check which `start` markers
have been sent later than the configured timeout. When a marker has been received from a partition recently, the
maximum such timestamp is used as the value of "now" - as it indicates exactly how far we are in processing the
partition. What "recently" means depends on the `useNowForRedeliverDespiteNoMarkerSeenForMs` config setting. Otherwise,
the current system time is used, as we assume that all markers from the partition have been processed.
# Dead letter queue (DMQ)
The redelivery of the message is attempted only a configured number of times. By default, it's 3. You can change that number by setting `maxRedeliveryCount` value in `KmqConfig`.
After that number is exceeded messages will be forwarded to a topic working as a *dead letter queue*. By default, the name of that topic is name of the message topic concatenated with the suffix `__undelivered`. You can configure the name by setting `deadLetterTopic` in `KmqConfig`.
The number of redeliveries is tracked by `kmq` with a special header. The default the name of that header is `kmq-redelivery-count`. You can change it by setting `redeliveryCountHeader` in `KmqConfig`.